Ескертпе
Бұл бетке кіру үшін қатынас шегін айқындау қажет. Жүйеге кіруді немесе каталогтарды өзгертуді байқап көруге болады.
Бұл бетке кіру үшін қатынас шегін айқындау қажет. Каталогтарды өзгертуді байқап көруге болады.
Применимо к:![]() SQL Server 2016 (13.x)
SQL Server 2016 (13.x) ![]() SQL Server 2017 (14.x) SQL Server 2019 (15.x)
SQL Server 2017 (14.x) SQL Server 2019 (15.x) ![]() в Linux
в Linux
Интеграция Python доступна в SQL Server 2017 и более поздних версиях, если включить параметр для Python во время установки служб машинного обучения (в базе данных).
Примечание.
В настоящее время эта статья относится только к SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) и SQL Server 2019 (15.x) и только для Linux.
Чтобы разрабатывать и развертывать решения Python для SQL Server, установите библиотеку Майкрософт revoscalepy и другие библиотеки Python для рабочей станции разработки. Библиотека revoscalepy, которая также находится на удаленном экземпляре SQL Server, координирует вычислительные запросы между обеими системами.
Из этой статьи вы узнаете, как настроить рабочую станцию разработки на Python, чтобы вы могли взаимодействовать с удаленным сервером SQL Server, на котором включены машинное обучение и интеграция Python. После выполнения действий, описанных в этой статье, у вас будут те же библиотеки Python, что и на сервере SQL Server. Вы также узнаете, как отправлять вычисления из локального сеанса Python в удаленный сеанс Python на сервере SQL Server.
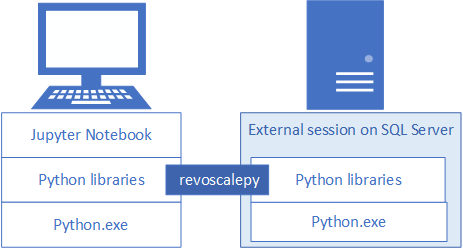
Чтобы проверить установку, можно использовать встроенное приложение Jupyter Notebook, как описано в этой статье, или связать библиотеки с PyCharm или любой другой интегрированной средой разработки, которой вы обычно пользуетесь.
Совет
Видеодемонстрацию этих упражнений см. в статье Удаленный запуск R и Python в SQL Server с помощью Jupyter Notebook.
Часто используемые инструменты
Независимо от того, являетесь ли вы разработчиком Python, который мало знаком с SQL, или разработчиком SQL, который мало знаком с Python и анализом данных в базе данных, для использования всех возможностей анализа баз данных вам потребуется как средство разработки Python, так и редактор запросов T-SQL, например SQL Server Management Studio (SSMS).
Для разработки на Python можно использовать приложение Jupyter Notebook, которое входит в дистрибутив Anaconda, устанавливаемый SQL Server. В этой статье объясняется, как запустить Jupyter Notebook, чтобы можно было выполнять код Python локально и удаленно на SQL Server.
Набор средств SSMS необходимо скачать отдельно. Он подходит для создания и выполнения хранимых процедур в SQL Server, в том числе процедур, содержащих код Python. Практически любой код Python, написанный в Jupyter Notebook, можно внедрять в хранимые процедуры. Вы можете ознакомиться с другими пошаговыми руководствами, чтобы получить дополнительные сведения об SSMS и внедрении кода Python.
1. Установка пакетов Python
На локальных рабочих станциях должны быть установлены те же версии пакетов Python, что и в SQL Server, включая базовый дистрибутив Anaconda 4.2.0 с Python 3.5.2, а также пакеты Майкрософт.
Сценарий установки добавляет в клиент Python три библиотеки Майкрософт в клиент Python. Скрипт устанавливает:
- revoscalepy используется для определения объектов источника данных и контекста вычислений.
- microsoftml, предоставляющую алгоритмы машинного обучения.
- Azureml применяется к задачам эксплуатации, связанным с автономным контекстом сервера, и может быть ограниченным использованием для аналитики в базе данных.
Скачайте сценарий установки. На соответствующей странице GitHub выберите "Скачать необработанный файл".
Install-PyForMLS.ps1 устанавливает версию 9.2.1 пакетов Microsoft Python. Эта версия соответствует экземпляру SQL Server по умолчанию.
Install-PyForMLS.ps1 устанавливает версию 9.3 пакетов Microsoft Python.
Откройте окно PowerShell с повышенными правами администратора (щелкните правой кнопкой мыши Запуск от имени администратора).
Перейдите в папку, в которую был скачан установщик, и запустите сценарий. Добавьте аргумент командной строки
-InstallFolder, чтобы указать расположение папки для библиотек. Например:cd {{download-directory}} .\Install-PyForMLS.ps1 -InstallFolder "C:\path-to-python-for-mls"
Если вы не указали папку установки, по умолчанию используется %ProgramFiles%\Microsoft\PyForMLS.
Для выполнения установки требуется некоторое время. Ход выполнения можно отслеживать в окне PowerShell. После завершения установки вы получите полный набор пакетов.
Совет
Общие сведения о запуске программ Python в Windows см. в разделе Часто задаваемые вопросы по Python для Windows.
2. Обнаружение исполняемых файлов
Оставаясь в окне PowerShell, выведите список файлов в папке установки, чтобы убедиться, что файл Python.exe, сценарии и другие пакеты установлены.
Введите
cd \, чтобы перейти к корневому каталогу диска, а затем введите путь, указанный для-InstallFolderна предыдущем шаге. Если этот параметр не был указан во время установки, по умолчанию используетсяcd %ProgramFiles%\Microsoft\PyForMLS.Введите
dir *.exe, чтобы получить список исполняемых файлов. Вы должны увидеть исполняемые файлы python.exe, pythonw.exe и uninstall-anaconda.exe.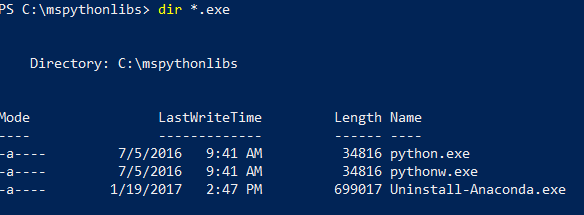
В системах с несколькими версиями Python не забывайте использовать этот конкретный файл Python.exe, если необходимо загрузить revoscalepy и другие пакеты Майкрософт.
Примечание.
Сценарий установки не изменяет переменную среды PATH на компьютере. Это означает, что новые интерпретаторы Python и модули, которые вы только что установили, не будут автоматически доступны для других инструментов. Справку по связыванию интерпретатора Python и библиотек с инструментами см. в разделе Установка интегрированной среды разработки.
3. Открытие Jupyter Notebook
Приложение Jupyter Notebook входит в состав дистрибутива Anaconda. В качестве следующего шага создайте записную книжку и выполните какой-нибудь код Python, в котором используются только что установленные библиотеки.
В командной строке PowerShell, по-прежнему находясь в каталоге
%ProgramFiles%\Microsoft\PyForMLS, откройте приложение Jupyter Notebook из папки Scripts:.\Scripts\jupyter-notebookДолжна открыться записная книжка в браузере по умолчанию по адресу
https://localhost:8889/tree.Другой способ запуска — дважды щелкнуть файл jupyter-notebook.exe.
Выберите Создать, а затем выберите Python 3.
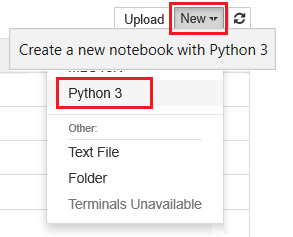
Введите и выполните команду
import revoscalepy, чтобы загрузить одну из библиотек Майкрософт.Введите и выполните команду
print(revoscalepy.__version__), чтобы получить сведения о версии. Вы должны увидеть версию 9.2.1 или 9.3.0. Вы можете использовать любую из этих версий с библиотекой revoscalepy на сервере.Введите более сложную последовательность инструкций. В этом примере формируется сводная статистика для локального набора данных с помощью метода rx_summary. Другие функции получают расположение демонстрационных данных и создают объект источника данных для локального XDF-файла.
import os from revoscalepy import rx_summary from revoscalepy import RxXdfData from revoscalepy import RxOptions sample_data_path = RxOptions.get_option("sampleDataDir") print(sample_data_path) ds = RxXdfData(os.path.join(sample_data_path, "AirlineDemoSmall.xdf")) summary = rx_summary("ArrDelay+DayOfWeek", ds) print(summary)
На следующем снимке экрана показаны входные и выходные данные (выходные данные обрезаны для краткости).

4. Получение разрешений SQL
Чтобы подключиться к экземпляру SQL Server для выполнения сценариев и передачи данных, необходимо иметь допустимое имя входа на сервере базы данных. Можно использовать либо имя входа SQL, либо встроенную проверку подлинности Windows. Обычно рекомендуется использовать встроенную проверку подлинности Windows, но в некоторых случаях проще использовать имя входа SQL, особенно если сценарий содержит строки подключения к внешним данным.
У учетной записи, используемой для выполнения кода, должно быть разрешение на чтение для баз данных, с которыми вы работаете, а также специальное разрешение EXECUTE ANY EXTERNAL SCRIPT. Большинству разработчиков также требуются разрешения на создание хранимых процедур и на запись данных в таблицы, содержащие данные обучения или данные оценки.
Попросите администратора базы данных настроить следующие разрешения для учетной записи в базе данных, в которой используется Python:
- EXECUTE ANY EXTERNAL SCRIPT для запуска Python на сервере.
- Привилегии db_datareader для выполнения запросов, используемых для обучения модели.
- db_datawriter для записи данных обучения и данных оценки.
- db_owner для создания таких объектов, как хранимые процедуры, таблицы и функции. Разрешение db_owner также потребуется для создания примеров баз данных и тестовых баз данных.
Если для кода требуются пакеты, которые по умолчанию не установлены в SQL Server, обратитесь к администратору базы данных, чтобы установить необходимые пакеты. SQL Server представляет собой защищенную среду, и существуют ограничения на места установки пакетов. Нерегламентированная установка пакетов в составе вашего кода не рекомендуется, даже если у вас есть необходимые разрешения. Также тщательно оцените влияние на безопасность сервера перед установкой новых пакетов в библиотеку сервера.
5. Создание тестовых данных
Если у вас есть разрешения на создание базы данных на удаленном сервере, можно выполнить следующий код, чтобы создать демонстрационную базу данных "Ирисы Фишера", которая будет использоваться для выполнения оставшихся действий в этой статье.
5-1. Удаленное создание базы данных irissql
from mssql_python import connect
# creating a new db to load Iris sample in
new_db_name = "irissql"
connection_string = "Server=localhost;Database={0};Trusted_Connection=Yes;"
# you can also swap Trusted_Connection for UID={your username};PWD={your password}
conn = connect(connection_string.format("master"))
conn.setautocommit(True)
conn.cursor().execute("IF EXISTS(SELECT * FROM sys.databases WHERE [name] = '{0}') DROP DATABASE {0}".format(new_db_name))
conn.cursor().execute("CREATE DATABASE " + new_db_name)
conn.close()
print("Database created")
5-2. Импорт примера "Ирисы Фишера" из SkLearn
from sklearn import datasets
import pandas as pd
# SkLearn has the Iris sample dataset built in to the package
iris = datasets.load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
5-3. Использование API-интерфейсов Revoscalepy для создания таблицы и загрузки данных "Ирисы Фишера"
from revoscalepy import RxSqlServerData, rx_data_step
# Example of using RX APIs to load data into SQL table. You can also do this with mssql-python
table_ref = RxSqlServerData(connection_string=connection_string.format(new_db_name), table="iris_data")
rx_data_step(input_data = df, output_file = table_ref, overwrite = True)
print("New Table Created: Iris")
print("Sklearn Iris sample loaded into Iris table")
6. Проверка удаленного подключения
Перед выполнением следующего шага убедитесь, что у вас есть разрешения на экземпляр SQL Server и строка подключения к демонстрационной базе данных "Ирисы Фишера". Если база данных не существует и у вас есть необходимые разрешения, можно создать базу данных, используя следующие встроенные инструкции.
Замените значения параметров в строке подключения на соответствующие значения параметров для вашей среды. В примере кода используется строка подключения "Server=localhost;Database=irissql;Trusted_Connection=Yes;", но в вашем коде необходимо указать удаленный сервер, возможно, с именем экземпляра и параметр учетных данных, который сопоставляется с именем входа базы данных.
6-1. Определение функции
В следующем коде определяется функция, которая будет отправлена на сервер SQL Server на более позднем шаге. При выполнении этого кода он использует данные и библиотеки (revoscalepy, pandas, matplotlib) на удаленном сервере для создания точечных диаграмм для набора данных "Ирисы Фишера". Этот код возвращает байтовый поток из файла PNG обратно в Jupyter Notebook для отображения в браузере.
def send_this_func_to_sql():
from revoscalepy import RxSqlServerData, rx_import
from pandas.tools.plotting import scatter_matrix
import matplotlib.pyplot as plt
import io
# remember the scope of the variables in this func are within our SQL Server Python Runtime
connection_string = "Driver=SQL Server;Server=localhost;Database=irissql;Trusted_Connection=Yes;"
# specify a query and load into pandas dataframe df
sql_query = RxSqlServerData(connection_string=connection_string, sql_query = "select * from iris_data")
df = rx_import(sql_query)
scatter_matrix(df)
# return bytestream of image created by scatter_matrix
buf = io.BytesIO()
plt.savefig(buf, format="png")
buf.seek(0)
return buf.getvalue()
6-2. Отправка функции в SQL Server
В этом примере создается удаленный контекст вычислений, и выполнение функции отправляется на сервер SQL Server с помощью rx_exec. Функция rx_exec удобна, так как она принимает контекст вычислений в качестве аргумента. Любая функция, которую требуется выполнить удаленно, должна принимать контекст вычислений в качестве аргумента. Некоторые функции, например rx_lin_mod, поддерживают этот аргумент напрямую. Для операций, которые не принимают этот аргумент, можно использовать rx_exec для доставки кода в удаленный контекст вычислений.
В этом примере необработанные данные из SQL Server в Jupyter Notebook не передаются. Все вычисления выполняются в базе данных "Ирисы Фишера", и клиенту возвращается только файл изображения.
from IPython import display
import matplotlib.pyplot as plt
from revoscalepy import RxInSqlServer, rx_exec
# create a remote compute context with connection to SQL Server
sql_compute_context = RxInSqlServer(connection_string=connection_string.format(new_db_name))
# use rx_exec to send the function execution to SQL Server
image = rx_exec(send_this_func_to_sql, compute_context=sql_compute_context)[0]
# only an image was returned to my jupyter client. All data remained secure and was manipulated in my db.
display.Image(data=image)
На следующем снимке экрана показаны входные данные и выходные данные в виде точечной диаграммы.

7. Запуск Python
Поскольку разработчики часто работают с несколькими версиями Python, программа установки не добавляет путь к Python в переменную PATH. Чтобы использовать исполняемый файл и библиотеки Python, установленные программой установки, свяжите интегрированную среду разработки с файлом Python.exe по пути, по которому также находятся библиотеки revoscalepy и microsoftml.
Командная строка
При запуске файла Python.exe из папки %ProgramFiles%\Microsoft\PyForMLS (или из любого другого расположения, указанного при установке клиентской библиотеки Python) у вас есть доступ ко всему дистрибутиву Anaconda и к модулям Python Майкрософт revoscalepy и microsoftml.
- Перейдите в
%ProgramFiles%\Microsoft\PyForMLSи выполните Python.exe. - Откройте интерактивную справку:
help(). - Введите имя модуля в командной строке справки:
help> revoscalepy. Справка возвращает имя, содержимое пакета, версию и расположение файла. - Получите сведения о версии и пакете в командной строке help>:
revoscalepy. Нажмите клавишу ВВОД несколько раз, чтобы выйти из справки. - Импортируйте модуль:
import revoscalepy.
Jupyter Notebook
В этой статье для демонстрации вызовов функций revoscalepy используется встроенное приложение Jupyter Notebook. Если вы не знакомы с этим средством, на следующем снимке экрана показаны его компоненты и механизм их работы.
Родительская папка %ProgramFiles%\Microsoft\PyForMLS содержит дистрибутив Anaconda и пакеты Майкрософт. Записные книжки Jupyter включены в Anaconda в папке "Скрипты", а исполняемые файлы Python автоматически зарегистрированы с помощью Jupyter Notebook. Пакеты в каталоге site-packages можно импортировать в записную книжку. К этим пакетам относятся три пакета Майкрософт, которые используются для обработки и анализа данных и машинного обучения.
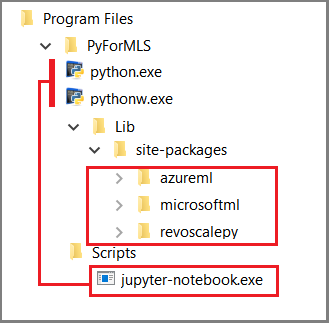
При использовании другой интегрированной среды разработки необходимо связать исполняемые файлы и библиотеки функций Python с вашим инструментом. В следующих разделах приводятся инструкции по часто используемым инструментам.
Visual Studio
Если вы используете Python в Visual Studio, воспользуйтесь следующими параметрами конфигурации, чтобы создать среду Python, включающую пакеты Python Майкрософт.
| Параметр конфигурации | значение |
|---|---|
| Путь префикса | %ProgramFiles%\Microsoft\PyForMLS |
| Путь к интерпретатору | %ProgramFiles%\Microsoft\PyForMLS\python.exe |
| Оконный интерпретатор | %ProgramFiles%\Microsoft\PyForMLS\pythonw.exe |
Сведения о настройке среды Python см. в разделе Управление средами Python в Visual Studio.
PyCharm
В PyCharm задайте в качестве интерпретатора установленный исполняемый файл Python.
В новом проекте в окне "Параметры" выберите Добавить локальный путь.
Введите
%ProgramFiles%\Microsoft\PyForMLS\.
Теперь можно импортировать модули revoscalepy, microsoftml или azureml. Также можно открыть интерактивное окно, выбрав Инструменты>Консоль Python.