Руководство по Python. Развертывание модели линейной регрессии с помощью машинного обучения SQL
Область применения: ![]() SQL Server 2017 (14.x) и более поздних
SQL Server 2017 (14.x) и более поздних ![]() версий Управляемый экземпляр SQL Azure
версий Управляемый экземпляр SQL Azure
В четвертой части этого цикла учебников вы развернете модель линейной регрессии, разработанную в Python, в базе данных SQL Server с помощью Служб машинного обучения или в Кластерах больших данных.
В четвертой части этой серии руководств будет выполняться развертывание модели линейной регрессии, разработанной на Python, в базе данных SQL Server с помощью Служб машинного обучения.
В четвертой части этой серии руководств будет выполняться развертывание модели линейной регрессии, разработанной на Python, в базе данных Управляемого экземпляра SQL Azure с помощью Служб машинного обучения.
В этой статье вы узнаете, как выполнять следующие задачи.
- Создание хранимой процедуры, которая формирует модель машинного обучения
- Сохранение модели в таблице базы данных
- Создание хранимой процедуры, которая делает прогнозы с помощью модели
- Выполнение модели с новыми данными
В первой части вы узнали, как восстановить учебную базу данных.
Во второй части вы узнали, как загрузить данные из базы данных в кадр данных Python, а также подготовить данные в Python.
В третьей части вы узнали, как обучить модель машинного обучения линейной регрессии в Python.
Необходимые компоненты
- В четвертой части этого учебника предполагается, что вы уже выполнили первую часть и описанные в ней предварительные требования.
Создание хранимой процедуры, которая формирует модель
Теперь, используя разработанные вами скрипты Python, создайте хранимую процедуру generate_rental_py_model, которая обучает и создает модель линейной регрессии с помощью LinearRegression из scikit-learn.
Выполните следующую инструкцию T-SQL в Azure Data Studio, чтобы создать хранимую процедуру для обучения модели.
-- Stored procedure that trains and generates a Python model using the rental_data and a linear regression algorithm
DROP PROCEDURE IF EXISTS generate_rental_py_model;
go
CREATE PROCEDURE generate_rental_py_model (@trained_model varbinary(max) OUTPUT)
AS
BEGIN
EXECUTE sp_execute_external_script
@language = N'Python'
, @script = N'
from sklearn.linear_model import LinearRegression
import pickle
df = rental_train_data
# Get all the columns from the dataframe.
columns = df.columns.tolist()
# Store the variable well be predicting on.
target = "RentalCount"
# Initialize the model class.
lin_model = LinearRegression()
# Fit the model to the training data.
lin_model.fit(df[columns], df[target])
# Before saving the model to the DB table, convert it to a binary object
trained_model = pickle.dumps(lin_model)'
, @input_data_1 = N'select "RentalCount", "Year", "Month", "Day", "WeekDay", "Snow", "Holiday" from dbo.rental_data where Year < 2015'
, @input_data_1_name = N'rental_train_data'
, @params = N'@trained_model varbinary(max) OUTPUT'
, @trained_model = @trained_model OUTPUT;
END;
GO
Сохранение модели в таблице базы данных
Создайте таблицу в базе данных TutorialDB, а затем сохраните модель в таблице.
Выполните следующую инструкцию T-SQL в Azure Data Studio, чтобы создать таблицу с именем dbo.rental_py_models, которая используется для хранения модели.
USE TutorialDB; DROP TABLE IF EXISTS dbo.rental_py_models; GO CREATE TABLE dbo.rental_py_models ( model_name VARCHAR(30) NOT NULL DEFAULT('default model') PRIMARY KEY, model VARBINARY(MAX) NOT NULL ); GOСохраните модель в таблице в виде двоичного объекта с именем модели linear_model.
DECLARE @model VARBINARY(MAX); EXECUTE generate_rental_py_model @model OUTPUT; INSERT INTO rental_py_models (model_name, model) VALUES('linear_model', @model);
Создание хранимой процедуры, которая делает прогнозы
Создайте хранимую процедуру py_predict_rentalcount, которая делает прогнозы с помощью обученной модели и набора новых данных. Запустите T-SQL ниже в Azure Data Studio.
DROP PROCEDURE IF EXISTS py_predict_rentalcount; GO CREATE PROCEDURE py_predict_rentalcount (@model varchar(100)) AS BEGIN DECLARE @py_model varbinary(max) = (select model from rental_py_models where model_name = @model); EXECUTE sp_execute_external_script @language = N'Python', @script = N' # Import the scikit-learn function to compute error. from sklearn.metrics import mean_squared_error import pickle import pandas rental_model = pickle.loads(py_model) df = rental_score_data # Get all the columns from the dataframe. columns = df.columns.tolist() # Variable you will be predicting on. target = "RentalCount" # Generate the predictions for the test set. lin_predictions = rental_model.predict(df[columns]) print(lin_predictions) # Compute error between the test predictions and the actual values. lin_mse = mean_squared_error(lin_predictions, df[target]) #print(lin_mse) predictions_df = pandas.DataFrame(lin_predictions) OutputDataSet = pandas.concat([predictions_df, df["RentalCount"], df["Month"], df["Day"], df["WeekDay"], df["Snow"], df["Holiday"], df["Year"]], axis=1) ' , @input_data_1 = N'Select "RentalCount", "Year" ,"Month", "Day", "WeekDay", "Snow", "Holiday" from rental_data where Year = 2015' , @input_data_1_name = N'rental_score_data' , @params = N'@py_model varbinary(max)' , @py_model = @py_model with result sets (("RentalCount_Predicted" float, "RentalCount" float, "Month" float,"Day" float,"WeekDay" float,"Snow" float,"Holiday" float, "Year" float)); END; GOСоздайте таблицу для хранения прогнозов.
DROP TABLE IF EXISTS [dbo].[py_rental_predictions]; GO CREATE TABLE [dbo].[py_rental_predictions]( [RentalCount_Predicted] [int] NULL, [RentalCount_Actual] [int] NULL, [Month] [int] NULL, [Day] [int] NULL, [WeekDay] [int] NULL, [Snow] [int] NULL, [Holiday] [int] NULL, [Year] [int] NULL ) ON [PRIMARY] GOВыполните хранимую процедуру для прогнозирования значений счетчиков
--Insert the results of the predictions for test set into a table INSERT INTO py_rental_predictions EXEC py_predict_rentalcount 'linear_model'; -- Select contents of the table SELECT * FROM py_rental_predictions;Результат должен иметь следующий вид.
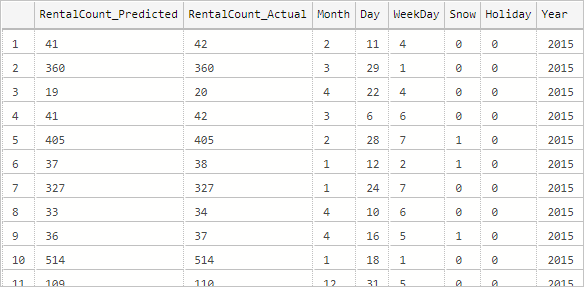
Вы успешно создали, обучили и развернули модель. Затем вы использовали ее в хранимой процедуре для прогнозирования значений на основе новых данных.
Следующие шаги
В четвертой части этого учебника вы выполнили следующие действия.
- Создание хранимой процедуры, которая формирует модель машинного обучения
- Сохранение модели в таблице базы данных
- Создание хранимой процедуры, которая делает прогнозы с помощью модели
- Выполнение модели с новыми данными
Дополнительные сведения об использовании Python в машинном обучении SQL: