Модели большого языка GitHub Copilot (LLMs)
GitHub Copilot работает с большими языковыми моделями (LLMs), чтобы упростить написание кода. В этом уроке мы сосредоточимся на понимании интеграции и влияния LLM в GitHub Copilot. Рассмотрим следующие разделы:
- Что такое LLM?
- Роль LLM в GitHub Copilot и запрос
- Точное настройка LLM
- Точное настройка LoRA
Что такое LLM?
Крупные языковые модели (LLM) — это модели искусственного интеллекта, разработанные и обученные для понимания, создания и управления языком человека. Эти модели имеют возможность обрабатывать широкий спектр задач, связанных с текстом, благодаря обширному количеству текстовых данных, на которые они обучаются. Ниже приведены некоторые основные аспекты, которые необходимо понять о LLM:
Объем обучающих данных
LLM подвергаются огромному количеству текста из различных источников. Эта экспозиция предоставляет им широкое представление о языке, контексте и тонкостях, участвующих в различных формах коммуникации.
Контекстуальное понимание
Они преуспевают в создании контекстно релевантного и последовательного текста. Их способность понять контекст позволяет им предоставлять значимые вклады, быть ли они завершают предложения, абзацы или даже создают целые документы, которые контекстно apt.
Интеграция машинного обучения и ИИ
LLM основывается на принципах машинного обучения и искусственного интеллекта. Они нейронные сети с миллионами или даже миллиардами параметров, которые настраиваются во время обучения для эффективного понимания и прогнозирования текста.
Многосторонность
Эти модели не ограничиваются определенным типом текста или языка. Они могут быть адаптированы и точно настроены для выполнения специализированных задач, что делает их высоко универсальным и применимым для различных доменов и языков.
Роль LLM в GitHub Copilot и запрос
GitHub Copilot использует LLM для предоставления предложений кода с учетом контекста. LLM рассматривает не только текущий файл, но и другие открытые файлы и вкладки в интегрированной среде разработки для создания точных и соответствующих завершений кода. Этот динамический подход обеспечивает специализированные предложения, повышая производительность.
Точное настройка LLM
Тонкой настройкой является критически важный процесс, который позволяет нам адаптировать предварительно обученные крупные языковые модели (LLM) для конкретных задач или доменов. Она включает обучение модели на небольшом наборе данных для конкретной задачи, известном как целевой набор данных, при использовании знаний и параметров, полученных из большого предварительно обученного набора данных, называемого исходной моделью.
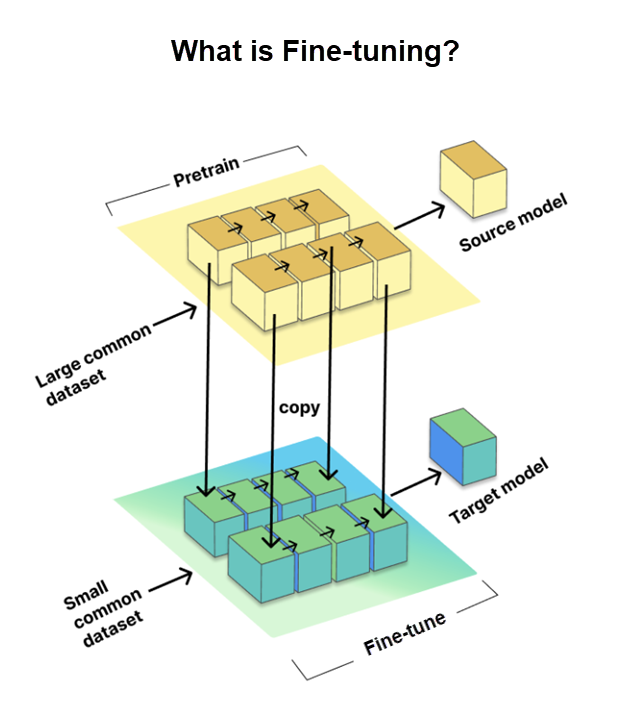
Тонкой настройке необходимо адаптировать LLM для конкретных задач, повышая их производительность. Однако GitHub сделал это шаг дальше с помощью метода тонкой настройки LoRA, который мы обсудим далее.
Точное настройка LoRA
Традиционная полная настройка означает обучение всех частей нейронной сети, которые могут быть медленными и сильно зависящими от ресурсов. Но ЛоРА (низкоранговая адаптация) является умным альтернативой. Он используется для улучшения работы больших предварительно обученных языковых моделей (LLM) для конкретных задач без повторного выполнения всех обучающих действий.
Вот как работает LoRA:
- LoRA добавляет небольшие обучаемые части к каждому уровню предварительно обученной модели, вместо изменения всего.
- Исходная модель остается той же, что экономит время и ресурсы.
Что здорово о LoRA:
- Он бьет другие методы адаптации, такие как адаптеры и префикс-настройка.
- Это похоже на получение больших результатов с меньшим количеством движущихся частей.
С простыми словами, loRA тонкой настройки заключается в работе более интеллектуальной, а не сложнее, чтобы сделать LLM лучше для конкретных требований к программированию при использовании Copilot.