쿼리 기반 문서 요약
이 가이드에서는 Azure OpenAI GPT-3 모델을 사용하여 문서 요약을 수행하는 방법을 보여줍니다. 문서 요약 프로세스와 관련된 개념, 프로세스에 대한 접근 방식 및 특정 사용 사례에 사용할 모델에 대한 권장 사항을 설명합니다. 마지막으로, 주요 개념을 이해하는 데 도움이 되는 샘플 코드 조각과 함께 두 가지 사용 사례를 제공합니다.
아키텍처
다음 다이어그램은 사용자 쿼리가 관련 데이터를 가져오는 방법을 보여줍니다. 요약 작성기는 GPT-3을 사용하여 가장 관련성이 큰 문서의 텍스트에 대한 요약을 생성합니다. 이 아키텍처에서 GPT-3 엔드포인트는 텍스트를 요약하는 데 사용됩니다.

이 아키텍처의 PowerPoint 파일을 다운로드합니다.
워크플로
이 워크플로는 거의 실시간으로 발생합니다.
- 사용자가 쿼리를 보냅니다. 예를 들어 제조 회사의 직원은 회사 포털에서 컴퓨터 파트에 대한 특정 정보를 검색합니다. 쿼리는 먼저 대화형 언어 이해와 같은 의도 인식기에서 처리됩니다. 사용자 쿼리의 관련 엔터티 또는 개념은 오프라인으로 채워진 기술 자료 문서의 하위 집합을 선택하고 표시하는 데 사용됩니다(이 경우 회사의 기술 자료 데이터베이스). 출력은 Azure Elastic Search와 같은 검색 및 분석 엔진에 공급되며, 관련 문서를 필터링하여 수천 또는 수만 개 대신 수백 개의 문서 집합을 반환합니다.
- 사용자 쿼리는 Azure Cognitive Search와 같은 검색 엔드포인트에 다시 적용되어 검색된 문서 집합의 순위를 관련성 순서(페이지 순위)로 지정합니다. 가장 높은 순위의 문서가 선택됩니다.
- 선택한 문서에서 관련 문장을 검사합니다. 이 검사 프로세스는 사용자 쿼리를 포함하는 모든 문장을 추출하는 것과 같은 거친 메서드 또는 GPT-3 포함과 같은 보다 정교한 메서드를 사용하여 문서에서 의미상 유사한 자료를 찾습니다.
- 관련 텍스트를 추출한 후 요약 도우미가 있는 GPT-3 완료 엔드포인트는 추출된 콘텐츠를 요약합니다. 이 예제에서는 쿼리에서 직원이 지정한 부분에 대한 중요한 세부 정보의 요약이 반환됩니다.
이 문서에서는 아키텍처의 요약 구성 요소에 중점을 둡니다.
시나리오 정보
기업은 비즈니스 프로세스, 고객, 제품 및 정보에 대한 기술 자료 자주 만들고 기본. 그러나 대용량 데이터 세트의 사용자 쿼리를 기반으로 관련 콘텐츠를 반환하는 것은 종종 어려운 일입니다. 사용자는 페이지 순위와 같은 메서드를 사용하여 기술 자료 쿼리하고 해당 문서를 찾을 수 있지만 관련 정보를 검색하기 위해 문서를 자세히 살펴보는 것은 일반적으로 시간이 걸리는 수동 작업이 됩니다. 그러나 OpenAI에서 개발한 것과 같은 기초 변환기 모델의 최근 발전과 함께 쿼리 메커니즘은 포함과 같은 인코딩 정보를 사용하여 관련 정보를 찾는 의미 체계 검색 방법을 통해 구체화되었습니다. 이러한 개발을 통해 간결하고 간결한 방식으로 콘텐츠를 요약하고 사용자에게 제공할 수 있습니다.
문서 요약은 중요한 정보 요소 및 콘텐츠 값을 기본 동안 대량의 데이터에서 요약을 만드는 프로세스입니다. 이 문서에서는 특정 사용 사례에 Azure OpenAI Service GPT-3 기능을 사용하는 방법을 보여 줍니다. GPT-3은 언어 번역, 챗봇, 텍스트 요약 및 콘텐츠 생성을 비롯한 다양한 자연어 처리 작업에 사용할 수 있는 강력한 도구입니다. 여기에 설명된 메서드와 아키텍처는 사용자 지정할 수 있으며 많은 데이터 세트에 적용할 수 있습니다.
잠재적인 사용 사례
문서 요약은 사용자가 대량의 참조 데이터를 검색하고 관련 정보를 간결하게 설명하는 요약을 생성해야 하는 모든 조직 기본 적용됩니다. 일반적인 do기본에는 법률, 재무, 뉴스, 의료 및 학술 조직이 포함됩니다. 요약의 잠재적 사용 사례는 다음과 같습니다.
- 요약을 생성하여 뉴스, 재무 보고 등에 대한 주요 인사이트를 강조 표시합니다.
- 예를 들어 법적 절차에서 인수를 지원하기 위한 빠른 참조를 만듭니다.
- 학술 설정에서와 같이 논문의 논문에 대한 컨텍스트를 제공합니다.
- 문학 리뷰 작성.
- 참고 문헌에 주석을 추가합니다.
모든 사용 사례에 요약 서비스를 사용할 경우의 몇 가지 이점은 다음과 같습니다.
- 읽기 시간이 단축되었습니다.
- 대량의 서로 다른 데이터를 보다 효과적으로 검색할 수 있습니다.
- 인간의 요약 기술에서 편견의 기회를 감소. (이 이점은 학습 데이터가 얼마나 편견이 없는지에 따라 달라집니다.)
- 직원과 사용자가 보다 심층적인 분석에 집중할 수 있도록 합니다.
컨텍스트 내 학습
Azure OpenAI Service는 생성 완성 모델을 사용합니다. 이 모델은 자연어 지침을 사용하여 요청된 작업과 필요한 기술(프롬프트 엔지니어링이라고 함)을 식별합니다. 이 방법을 사용하는 경우 프롬프트의 첫 번째 부분에는 자연어 지침 또는 원하는 작업의 예제가 포함됩니다. 모델은 가장 가능성이 큰 다음 텍스트를 예측하여 작업을 완료합니다. 이 기술을 컨텍스트 내 학습이라고 합니다.
컨텍스트 내 학습을 통해 언어 모델은 몇 가지 예제에서 작업을 학습할 수 있습니다. 언어 모델에는 작업을 보여 주는 입력 출력 쌍 목록이 포함된 프롬프트와 테스트 입력이 함께 제공됩니다. 모델은 프롬프트를 컨디셔닝하고 다음 토큰을 예측하여 예측을 합니다.
컨텍스트 내 학습에 대한 세 가지 기본 방법이 있습니다. 즉, 제로샷 학습, 몇 번의 학습 및 출력을 변경하고 개선하는 미세 조정 방법입니다. 이러한 접근 방식은 모델에 제공되는 작업별 데이터의 양에 따라 달라집니다.
제로샷: 이 접근 방식에서는 모델에 예제가 제공되지 않습니다. 작업 요청만 입력으로 제공됩니다. 제로샷 학습에서 모델은 이전에 학습된 개념에 따라 달라집니다. 학습된 데이터에만 응답합니다. 의미 체계적 의미를 반드시 이해하지는 못하지만, 다음에 생성해야 할 사항에 대해 인터넷에서 배운 모든 것을 기반으로 하는 통계적 이해가 있습니다. 모델은 지정된 작업을 이미 학습한 기존 범주와 연결하려고 시도하고 그에 따라 응답합니다.
몇 번 실행: 이 방법에서는 예상 응답 형식 및 콘텐츠를 보여 주는 몇 가지 예제가 호출 프롬프트에 포함됩니다. 모델은 예측을 안내하는 매우 작은 학습 데이터 세트와 함께 제공됩니다. 작은 예제 집합을 사용하여 학습하면 모델이 관련이 없지만 이전에는 볼 수 없었던 작업을 일반화하고 이해할 수 있습니다. 모델에서 수행할 작업을 정확하게 설명해야 하므로 몇 번의 예제를 만드는 것이 어려울 수 있습니다. 일반적으로 관찰되는 문제 중 하나는 모델이 학습 예제, 특히 작은 모델에 사용되는 쓰기 스타일에 민감하다는 것입니다.
미세 조정: 미세 조정은 모델을 사용자 고유의 데이터 세트에 맞게 조정하는 프로세스입니다. 이 사용자 지정 단계에서는 다음을 통해 프로세스를 개선할 수 있습니다.
- 더 큰 데이터 집합 포함(최소 500개 예제).
- 백프로포지션과 함께 기존의 최적화 기술을 사용하여 모델의 가중치를 다시 조정합니다. 이러한 기술은 자체에서 제공하는 제로 샷 또는 몇 샷 접근 방식보다 더 높은 품질의 결과를 가능하게합니다.
- 특정 프롬프트 및 특정 구조로 모델 가중치를 학습시켜 몇 샷 접근 방식을 개선합니다. 이 기술을 사용하면 프롬프트에 예제를 제공할 필요 없이 더 많은 수의 작업에서 더 나은 결과를 얻을 수 있습니다. 그 결과 전송된 텍스트가 줄어들고 토큰이 줄어듭니다.
GPT-3 솔루션을 만들 때 기본 작업은 학습 프롬프트의 디자인 및 콘텐츠에 있습니다.
신속한 엔지니어링
프롬프트 엔지니어링 은 바람직하거나 유용한 출력을 생성하는 입력을 검색하는 자연어 처리 분야입니다. 사용자가 시스템에 프롬프트를 표시하면 콘텐츠가 표현되는 방식이 출력을 크게 변경할 수 있습니다. 프롬프트 디자인 은 GPT-3 모델이 바람직하고 상황에 맞는 응답을 제공하는 가장 중요한 프로세스입니다.
이 문서에 설명된 아키텍처는 완성 엔드포인트를 요약에 사용합니다. 완성 엔드포인트는 부분 프롬프트 또는 컨텍스트를 입력으로 수락하고 입력 텍스트를 계속하거나 완료하는 하나 이상의 출력을 반환하는 Azure AI 서비스 API 입니다. 사용자는 입력 텍스트를 프롬프트로 제공하고, 모델은 제공된 컨텍스트 또는 패턴과 일치시키려는 텍스트를 생성합니다. 프롬프트 디자인은 작업 및 데이터에 크게 의존합니다. 프롬프트 엔지니어링을 미세 조정 데이터 세트에 통합하고 프로덕션 환경에서 시스템을 사용하기 전에 가장 적합한 작업을 조사하려면 상당한 시간과 노력이 필요합니다.
프롬프트 디자인
GPT-3 모델은 여러 작업을 수행할 수 있으므로 디자인의 목표에 명시적이어야 합니다. 모델은 제공된 프롬프트에 따라 원하는 출력을 예측합니다.
예를 들어 "고양이 품종 목록 제공"이라는 단어를 입력하는 경우 모델은 고양이 품종 목록을 요청한다고 자동으로 가정하지 않습니다. 모델에 첫 번째 단어가 "고양이 품종 목록을 주세요"라는 대화를 계속하도록 요청할 수 있으며, 다음 단어는 "내가 좋아하는 것을 알려드리겠습니다."입니다. 모델에서 고양이 목록을 원한다고 가정한 경우 콘텐츠 만들기, 분류 또는 기타 작업에는 적합하지 않습니다.
텍스트를 생성하거나 조작하는 방법 알아보기에서 설명한 대로 프롬프트를 만들기 위한 세 가지 기본 지침이 있습니다.
- 표시하고 설명합니다. 지침, 예제 또는 둘의 조합을 제공하여 원하는 항목에 대한 명확성을 향상시킵니다. 모델에서 항목 목록의 순위를 사전순으로 지정하거나 감정별로 단락을 분류하려는 경우 원하는 대로 표시합니다.
- 품질 데이터를 제공합니다. 분류자를 빌드하거나 모델이 패턴을 따르도록 하려면 충분한 예제를 제공해야 합니다. 또한 예제를 교정해야 합니다. 모델은 일반적으로 맞춤법 오류를 인식하고 응답을 반환할 수 있지만 맞춤법 오류는 의도적인 것으로 간주하여 응답에 영향을 줄 수 있습니다.
- 설정을 확인합니다. 및
top_p설정은temperature모델이 응답을 생성하는 데 얼마나 결정적인지를 제어합니다. 정답이 하나뿐인 응답을 요청하는 경우 낮은 수준에서 이러한 설정을 구성합니다. 더 다양한 응답을 원하는 경우 더 높은 수준에서 설정을 구성할 수 있습니다. 일반적인 오류는 이러한 설정이 "영리함" 또는 "창의성" 컨트롤이라고 가정하는 것입니다.
대안
Azure 대화형 언어 이해 는 여기에 사용되는 요약 작성기에 대한 대안입니다. 대화형 언어 이해의 기본 목적은 들어오는 발화의 전반적인 의도를 예측하고, 중요한 정보를 추출하고, 토픽에 맞는 응답을 생성하는 모델을 빌드하는 것입니다. 기존 기술 자료 참조하여 들어오는 발화에 가장 적합한 제안을 찾을 수 있는 경우 챗봇 애플리케이션에서 유용합니다. 입력 텍스트에 응답이 필요하지 않은 경우에는 별로 도움이 되지 않습니다. 이 아키텍처의 의도는 긴 텍스트 콘텐츠에 대한 짧은 요약을 생성하는 것입니다. 콘텐츠의 본질은 간결한 방식으로 설명되며 모든 중요한 정보가 표시됩니다.
예제 시나리오
사용 사례: 법률 문서 요약
이 사용 사례에서는 의회를 통과한 입법 법안의 컬렉션이 요약되어 있습니다. 요약은 기본 진리 요약이라고 하는 사람이 생성한 요약에 더 가까워지도록 미세 조정됩니다.
제로 샷 프롬프트 엔지니어링은 청구서를 요약하는 데 사용됩니다. 그런 다음 프롬프트 및 설정이 수정되어 다른 요약 출력을 생성합니다.
데이터 세트
첫 번째 데이터 세트는 미국 의회 및 캘리포니아 주 법안을 요약하기 위한 BillSum 데이터 세트입니다. 이 예제에서는 의회 법안만 사용합니다. 데이터는 학습에 사용할 18,949개의 청구서와 테스트에 사용할 3,269개의 청구서로 분할됩니다. BillSum은 5,000자에서 20,000자 사이의 중간 길이의 법안에 중점을 둡니다. 클린 전처리됩니다.
데이터 세트 및 다운로드 지침에 대한 자세한 내용은 GitHub의 FiscalNote/BillSum을 참조하세요.
BillSum 스키마
BillSum 데이터 세트의 스키마에는 다음이 포함됩니다.
bill_id. 청구서의 식별자입니다.text. 청구서 텍스트입니다.summary. 이 법안의 인간이 작성한 요약입니다.title. 청구서 제목입니다.text_len. 청구서의 문자 길이입니다.sum_len. 청구서 요약의 문자 길이입니다.
이 사용 사례에서는 text 요소와 summary 요소가 사용됩니다.
Zero-shot
여기서 목표는 GPT-3 모델을 학습하여 대화 스타일 입력을 학습하는 것입니다. 완성 엔드포인트는 Azure OpenAI API 및 청구서의 최상의 요약을 생성하는 프롬프트를 만드는 데 사용됩니다. 관련 정보를 추출하도록 프롬프트를 신중하게 만드는 것이 중요합니다. 지정된 청구서에서 일반 요약을 추출하기 위해 다음 형식이 사용됩니다.
- 접두사: 원하는 작업을 수행합니다.
- 컨텍스트 입문서: 컨텍스트입니다.
- 컨텍스트: 응답을 제공하는 데 필요한 정보입니다. 이 경우 요약할 텍스트입니다.
- 접미사: 원하는 형식의 답변입니다. 예를 들어 답변, 완성 또는 요약입니다.
API_KEY = # SET YOUR OWN API KEY HERE
RESOURCE_ENDPOINT = " -- # SET A LINK TO YOUR RESOURCE ENDPOINT -- "
openai.api_type = "azure"
openai.api_key = API_KEY
openai.api_base = RESOURCE_ENDPOINT
openai.api_version = "2022-12-01-preview"
prompt_i = 'Summarize the legislative bill given the title and the text.\n\nTitle:\n'+" ".join([normalize_text(bill_title_1)])+ '\n\nText:\n'+ " ".join([normalize_text(bill_text_1)])+'\n\nSummary:\n'
response = openai.Completion.create(
engine=TEXT_DAVINCI_001
prompt=prompt_i,
temperature=0.4,
max_tokens=500,
top_p=1.0,
frequency_penalty=0.5,
presence_penalty=0.5,
stop=['\n\n###\n\n'], # The ending token used during inference. Once it reaches this token, GPT-3 knows the completion is over.
best_of=1
)
= 1
지상 진실: 2007 년 기업을위한 국립 과학 교육 세금 인센티브 법 - 초등학교와 중등 학교에 재산이나 서비스의 기여 및 과학, 기술, 공학 또는 수학 교육을 촉진하기 위해 교사 교육에 대한 일반 비즈니스 세금 공제를 허용하도록 국세청법을 개정합니다.
제로 샷 모델 요약 : 2007 년 국가 과학 교육 세금 인센티브는 초등 및 중등 학교 수준에서 과학, 기술, 공학 및 수학 (STEM) 교육에 기여 기업에 대한 새로운 세금 공제를 만들 것입니다. 크레딧은 과세 연도에 대한 납세자의 적격 STEM 기여 100 %에 해당합니다. 자격을 갖춘 STEM 기여 STEM 학교 기여, STEM 교사 externship 비용 및 STEM 교사 교육 비용을 포함합니다.
관찰: 제로샷 모델은 문서의 간결하고 일반화된 요약을 생성합니다. 그것은 인간이 쓴 지상 진실과 유사하고 동일한 핵심 포인트를 캡처합니다. 그것은 사람이 쓴 요약처럼 구성하고 점에 초점을 맞춘 다시 기본.
미세 조정
미세 조정은 프롬프트에 포함할 수 있는 것보다 더 많은 예제를 학습하여 제로샷 학습 시 개선되므로 더 많은 수의 작업에서 더 나은 결과를 얻을 수 있습니다. 모델을 미세 조정한 후에는 프롬프트에 예제를 제공할 필요가 없습니다. 미세 조정을 사용하면 필요한 토큰 수를 줄여 비용을 절감하고 대기 시간 요청을 줄일 수 있습니다.
개략적으로 미세 조정에는 다음 단계가 포함됩니다.
- 학습 데이터를 준비하고 업로드합니다.
- 새 미세 조정된 모델을 학습합니다.
- 미세 조정된 모델을 사용합니다.
자세한 내용은 Azure OpenAI Service를 사용하여 모델을 사용자 지정하는 방법을 참조 하세요.
미세 조정을 위한 데이터 준비
이 단계를 사용하면 프롬프트 엔지니어링을 미세 조정에 사용되는 프롬프트에 통합하여 제로샷 모델을 개선할 수 있습니다. 이렇게 하면 프롬프트/완료 쌍에 접근하는 방법에 대한 모델을 안내할 수 있습니다. 미세 조정 모델에서 프롬프트는 모델에서 학습하고 예측을 만드는 데 사용할 수 있는 시작점을 제공합니다. 이 프로세스를 통해 모델은 데이터에 대한 기본적인 이해로 시작하여 모델이 더 많은 데이터에 노출될 때 점진적으로 개선할 수 있습니다. 또한 프롬프트는 모델이 데이터에서 누락될 수 있는 패턴을 식별하는 데 도움이 될 수 있습니다.
모델이 학습을 완료한 후 유추 중에도 동일한 프롬프트 엔지니어링 구조가 사용되므로 모델은 학습 중에 학습한 동작을 인식하고 지시에 따라 완성을 생성할 수 있습니다.
#Adding variables used to design prompts consistently across all examples
#You can learn more here: https://learn.microsoft.com/azure/cognitive-services/openai/how-to/prepare-dataset
LINE_SEP = " \n "
PROMPT_END = " [end] "
#Injecting the zero-shot prompt into the fine-tune dataset
def stage_examples(proc_df):
proc_df['prompt'] = proc_df.apply(lambda x:"Summarize the legislative bill. Do not make up facts.\n\nText:\n"+" ".join([normalize_text(x['prompt'])])+'\n\nSummary:', axis=1)
proc_df['completion'] = proc_df.apply(lambda x:" "+normalize_text(x['completion'])+PROMPT_END, axis=1)
return proc_df
df_staged_full_train = stage_examples(df_prompt_completion_train)
df_staged_full_val = stage_examples(df_prompt_completion_val)
이제 데이터가 적절한 형식으로 미세 조정을 위해 준비되었으므로 미세 조정 명령 실행을 시작할 수 있습니다.
다음으로 OpenAI CLI를 사용하여 일부 데이터 준비 단계를 도울 수 있습니다. OpenAI 도구는 데이터의 유효성을 검사하고, 제안을 제공하고, 데이터를 다시 포맷합니다.
openai tools fine_tunes.prepare_data -f data/billsum_v4_1/prompt_completion_staged_train.csv
openai tools fine_tunes.prepare_data -f data/billsum_v4_1/prompt_completion_staged_val.csv
데이터 세트 미세 조정
payload = {
"model": "curie",
"training_file": " -- INSERT TRAINING FILE ID -- ",
"validation_file": "-- INSERT VALIDATION FILE ID --",
"hyperparams": {
"n_epochs": 1,
"batch_size": 200,
"learning_rate_multiplier": 0.1,
"prompt_loss_weight": 0.0001
}
}
url = RESOURCE_ENDPOINT + "openai/fine-tunes?api-version=2022-12-01-preview"
r = requests.post(url,
headers={
"api-key": API_KEY,
"Content-Type": "application/json"
},
json = payload
)
data = r.json()
print(data)
fine_tune_id = data['id']
print('Endpoint Called: {endpoint}'.format(endpoint = url))
print('Status Code: {status}'.format(status= r.status_code))
print('Fine tuning job ID: {id}'.format(id=fine_tune_id))
print('Response Information \n\n {text}'.format(text=r.text))
미세 조정된 모델 평가
이 섹션에서는 미세 조정된 모델을 평가하는 방법을 보여 줍니다.
#Run this cell to check status
url = RESOURCE_ENDPOINT + "openai/fine-tunes/<--insert fine-tune id-->?api-version=2022-12-01-preview"
r = requests.get(url,
headers={
"api-key": API_KEY,
"Content-Type": "application/json"
}
)
data = r.json()
print('Endpoint Called: {endpoint}'.format(endpoint = url))
print('Status Code: {status}'.format(status= r.status_code))
print('Fine tuning ID: {id}'.format(id=fine_tune_id))
print('Status: {status}'.format(status = data['status']))
print('Response Information \n\n {text}'.format(text=r.text))
지상 진실: 2007 년 기업을위한 국립 과학 교육 세금 인센티브 법 - 초등학교와 중등 학교에 재산이나 서비스의 기여 및 과학, 기술, 공학 또는 수학 교육을 촉진하기 위해 교사 교육에 대한 일반 비즈니스 세금 공제를 허용하도록 국세청법을 개정합니다.
미세 조정된 모델 요약: 이 법안은 과학, 기술, 공학 및 수학 교육에 도움이 되는 초등학교와 중등학교에 기여 대한 세금 공제를 제공합니다. 크레딧은 과세 연도 동안 납세자가 만든 자격을 갖춘 STEM 기여 100%에 해당합니다. 자격을 갖춘 STEM 기여 포함: (1) STEM 학교 기여, (2) STEM 교사 externship 비용, 그리고 (3) STEM 교사 교육 비용. 이 법안은 또한 과학, 기술, 공학 또는 수학 교육에 혜택을 주는 초등 및 중등 학교에 기여 대한 세금 공제를 제공합니다. 크레딧은 과세 연도 동안 납세자가 기여 자격을 갖춘 STEM 서비스의 100%에 해당합니다. 자격을 갖춘 STEM 서비스 기여 포함: (1) STEM 서비스는 기여 미국 또는 미국 외부의 군사 기지에서 제공되는 서비스에 대해 과세 연도 동안 지불되거나 발생하며, (2) 미국 있는 교육 조직이나 외부의 군사 기지에서 사용되는 과세 연도 동안 기여한 STEM 재고 재산입니다. 미국 과학, 기술, 공학 또는 수학 분야에서 K-12 등급의 교육을 제공합니다.
관찰: 전반적으로 미세 조정된 모델은 법안을 요약하는 훌륭한 작업을 수행합니다. 그것은 할기본 특정 전문 용어와 표현하지만 인간이 쓴 지상 진리에 설명되지 않은 핵심 포인트를 캡처합니다. 보다 상세하고 포괄적인 요약을 제공하여 제로샷 모델과 차별화됩니다.
사용 사례: 재무 보고서
이 사용 사례에서는 제로샷 프롬프트 엔지니어링을 사용하여 재무 보고서의 요약을 만듭니다. 그런 다음 요약 방법의 요약을 사용하여 결과를 생성합니다.
요약 방법 요약
프롬프트를 작성할 때 프롬프트 및 결과 완료의 GPT-3 합계에는 4,000개 미만의 토큰이 포함되어야 하므로 요약 텍스트의 몇 페이지로 제한됩니다. 일반적으로 4,000개 이상의 토큰(약 3,000개 단어)이 포함된 문서의 경우 요약 방법의 요약을 사용할 수 있습니다. 이 방법을 사용하면 토큰 제약 조건을 충족하기 위해 전체 텍스트가 먼저 분할됩니다. 그러면 짧은 텍스트의 요약이 파생됩니다. 다음 단계에서는 요약 요약이 만들어집니다. 이 사용 사례는 제로샷 모델을 사용한 요약 방법의 요약을 보여 줍니다. 이 솔루션은 긴 문서에 유용합니다. 또한 이 섹션에서는 다양한 프롬프트 엔지니어링 관행이 결과를 어떻게 변화할 수 있는지 설명합니다.
참고 항목
해당 단계를 완료하는 데 사용할 수 있는 데이터가 충분하지 않기 때문에 재무 사용 사례에는 미세 조정이 적용되지 않습니다.
데이터 세트
이 사용 사례의 데이터 세트는 기술적이며 회사의 성과를 평가하기 위한 주요 양적 메트릭을 포함합니다.
재무 데이터 세트에는 다음이 포함됩니다.
url: 재무 보고서의 URL입니다.pages: 요약할 키 정보가 포함된 보고서의 페이지입니다(1-인덱싱됨).completion: 보고서의 기본 진리 요약입니다.comments: 필요한 추가 정보입니다.
이 사용 사례 에서는 데이터 세트에서 Rathbone의 재무 보고서가 요약됩니다. Rathbone's는 개인 고객을 위한 개별 투자 및 자산 관리 회사입니다. 이 보고서는 2020년 Rathbone의 성과를 강조하고 수익, FUMA 및 수입과 같은 성능 메트릭을 멘션. 요약할 주요 정보는 PDF의 1페이지에 있습니다.
API_KEY = # SET YOUR OWN API KEY HERE
RESOURCE_ENDPOINT = "# SET A LINK TO YOUR RESOURCE ENDPOINT"
openai.api_type = "azure"
openai.api_key = API_KEY
openai.api_base = RESOURCE_ENDPOINT
openai.api_version = "2022-12-01-preview"
name = os.path.abspath(os.path.join(os.getcwd(), '---INSERT PATH OF LOCALLY DOWNLOADED RATHBONES_2020_PRELIM_RESULTS---')).replace('\\', '/')
pages_to_summarize = [0]
# Using pdfminer.six to extract the text
# !pip install pdfminer.six
from pdfminer.high_level import extract_text
t = extract_text(name
, page_numbers=pages_to_summarize
)
print("Text extracted from " + name)
t
제로샷 접근 방식
제로샷 방법을 사용하는 경우 해결된 예제를 제공하지 않습니다. 명령과 해결되지 않은 입력만 제공합니다. 이 예제에서는 지시 모델이 사용됩니다. 이 모델은 특히 명령을 받아서 추가 컨텍스트 없이 답변을 기록하기 위한 것이며, 이는 제로샷 접근 방식에 적합합니다.
텍스트를 추출한 후 다양한 프롬프트를 사용하여 요약 품질에 미치는 영향을 확인할 수 있습니다.
#Using the text from the Rathbone's report, you can try different prompts to see how they affect the summary
prompt_i = 'Summarize the key financial information in the report using qualitative metrics.\n\nText:\n'+" ".join([normalize_text(t)])+'\n\nKey metrics:\n'
response = openai.Completion.create(
engine="davinci-instruct",
prompt=prompt_i,
temperature=0,
max_tokens=2048-int(len(prompt_i.split())*1.5),
top_p=1.0,
frequency_penalty=0.5,
presence_penalty=0.5,
best_of=1
)
print(response.choices[0].text)
>>>
- Funds under management and administration (FUMA) reached £54.7 billion at 31 December 2020, up 8.5% from £50.4 billion at 31 December 2019
- Operating income totalled £366.1 million, 5.2% ahead of the prior year (2019: £348.1 million)
- Underlying1 profit before tax totalled £92.5 million, an increase of 4.3% (2019: £88.7 million); underlying operating margin of 25.3% (2019: 25.5%)
# Different prompt
prompt_i = 'Extract most significant money related values of financial performance of the business like revenue, profit, etc. from the below text in about two hundred words.\n\nText:\n'+" ".join([normalize_text(t)])+'\n\nKey metrics:\n'
response = openai.Completion.create(
engine="davinci-instruct",
prompt=prompt_i,
temperature=0,
max_tokens=2048-int(len(prompt_i.split())*1.5),
top_p=1.0,
frequency_penalty=0.5,
presence_penalty=0.5,
best_of=1
)
print(response.choices[0].text)
>>>
- Funds under management and administration (FUMA) grew by 8.5% to reach £54.7 billion at 31 December 2020
- Underlying profit before tax increased by 4.3% to £92.5 million, delivering an underlying operating margin of 25.3%
- The board is announcing a final 2020 dividend of 47 pence per share, which brings the total dividend to 72 pence per share, an increase of 2.9% over 2019
과제
보듯이 모델은 원래 텍스트에 멘션 않은 메트릭을 생성할 수 있습니다.
제안된 해결 방법: 프롬프트를 변경하여 이 문제를 해결할 수 있습니다.
요약은 문서의 한 섹션에 초점을 맞추고 다른 중요한 정보를 소홀히 할 수 있습니다.
제안된 솔루션: 요약 방법의 요약을 사용해 볼 수 있습니다. 보고서를 섹션으로 나누고 요약할 수 있는 더 작은 요약을 만들어 출력 요약을 만듭니다.
이 코드는 제안된 솔루션을 구현합니다.
# Body of function
from pdfminer.high_level import extract_text
text = extract_text(name
, page_numbers=pages_to_summarize
)
r = splitter(200, text)
tok_l = int(2000/len(r))
tok_l_w = num2words(tok_l)
res_lis = []
# Stage 1: Summaries
for i in range(len(r)):
prompt_i = f'Extract and summarize the key financial numbers and percentages mentioned in the Text in less than {tok_l_w}
words.\n\nText:\n'+normalize_text(r[i])+'\n\nSummary in one paragraph:'
response = openai.Completion.create(
engine=TEXT_DAVINCI_001,
prompt=prompt_i,
temperature=0,
max_tokens=tok_l,
top_p=1.0,
frequency_penalty=0.5,
presence_penalty=0.5,
best_of=1
)
t = trim_incomplete(response.choices[0].text)
res_lis.append(t)
# Stage 2: Summary of summaries
prompt_i = 'Summarize the financial performance of the business like revenue, profit, etc. in less than one hundred words. Do not make up values that are not mentioned in the Text.\n\nText:\n'+" ".join([normalize_text(res) for res in res_lis])+'\n\nSummary:\n'
response = openai.Completion.create(
engine=TEXT_DAVINCI_001,
prompt=prompt_i,
temperature=0,
max_tokens=200,
top_p=1.0,
frequency_penalty=0.5,
presence_penalty=0.5,
best_of=1
)
print(trim_incomplete(response.choices[0].text))
입력 프롬프트에는 특정 연도에 대한 Rathbone 재무 보고서의 원본 텍스트가 포함됩니다.
지상 진실: Rathbones는 2020년에 £366.1m의 수익을 보고했으며, 2019년에는 £348.1m에서 증가했으며, 세금 이전의 기본 이익은 £88.7m에서 £92.5m로 증가했습니다. 관리 중인 자산은 504억 파운드에서 547억 파운드로 8.5% 증가했으며 자산 관리 자산은 4.4% 증가한 449억 파운드를 기록했다. 순 유입은 2020년에 전년의 £600m에 비해 21억 파운드였으며, 주로 자금 사업에 15억 파운드의 유입과 바클레이 웰스의 자산 이전으로 인한 £400m에 의해 주도되었습니다.
요약 출력의 제로 샷 요약 : Rathbones는 2020 년에 강력한 성과를 거두었으며, 관리 및 관리 (FUMA)의 자금은 8.5 % 성장하여 연말에 547 억 파운드에 도달했습니다. 세전 기본 이익은 4.3% 증가한 9,250만 파운드로 25.3%의 기본 영업이익을 달성했습니다. 그룹 전체의 총 순 유입액은 21억 파운드로 4.2%의 성장률을 나타냅니다. 올해 세전 이익은 4,380만 파운드였으며 주당 기본 수익은 총 49.6p였습니다. 올해 영업이익은 전년 대비 5.2% 증가한 3억 6,610만 파운드를 기록했다.
관찰: 요약 방법의 요약은 보다 상세하고 포괄적인 요약이 제공되었을 때 처음에 발생한 문제를 해결하는 훌륭한 결과 집합을 생성합니다. 그것은 할 일기본 특정 전문 용어와 핵심 포인트를 캡처의 좋은 일을, 이는 지상 진실에 표현하지만 잘 설명되지 않습니다.
제로샷 모델은 기본stream 문서를 요약하는 데 적합합니다. 데이터가 산업별 또는 토픽별이거나, 산업별 전문 용어를 포함하거나, 업계별 지식이 필요한 경우 미세 조정이 가장 잘 수행됩니다. 예를 들어 이 방법은 의학 저널, 법적 양식 및 재무제표에 적합합니다. 제로샷 대신 몇 개의 샷 접근 방식을 사용하여 제공된 요약을 모방하는 방법을 배울 수 있도록 요약을 작성하는 방법의 예제를 모델에 제공할 수 있습니다. 제로샷 방식의 경우 이 솔루션은 모델을 다시 학습하지 않습니다. 모델의 지식은 GPT-3 학습을 기반으로 합니다. GPT-3은 인터넷에서 사용 가능한 거의 모든 데이터를 사용하여 학습됩니다. 특정 지식이 필요하지 않은 작업에 대해 잘 수행됩니다.
권장 사항
GPT-3을 사용하여 요약에 접근하는 방법에는 제로샷, 몇 샷 및 미세 조정을 비롯한 여러 가지 방법이 있습니다. 이 방법은 다양한 품질에 대한 요약을 생성합니다. 의도한 사용 사례에 가장 적합한 결과를 생성하는 방법을 탐색할 수 있습니다.
이 문서에 제시된 테스트에 대한 관찰에 따라 다음과 같은 몇 가지 권장 사항이 있습니다.
- 제로샷은 특정 기본 지식이 필요하지 않은 기본스트림 문서에 가장 적합합니다. 이 방법은 모든 높은 수준의 정보를 간결하고 인간과 유사한 방식으로 캡처하려고 시도하며 고품질 기준 요약을 제공합니다. 제로샷은 이 문서의 테스트에 사용되는 법적 데이터 세트에 대한 고품질 요약을 만듭니다.
- 예제 텍스트가 제공될 때 토큰 제한이 초과되므로 긴 문서를 요약하는 데는 몇 번의 샷 만 사용하기가 어렵습니다. 대신 긴 문서에 대한 요약 방법의 제로샷 요약을 사용하거나 데이터 세트를 늘려 성공적인 미세 조정을 가능하게 할 수 있습니다. 요약 방법의 요약은 이러한 테스트에 사용되는 재무 데이터 세트에 대한 우수한 결과를 생성합니다.
- 세부 조정은 정보를 쉽게 사용할 수 없는 경우 기술 또는 기본 관련 사용 사례에 가장 유용합니다. 이 방법을 사용하여 최상의 결과를 얻으려면 몇 천 개의 샘플이 포함된 데이터 세트가 필요합니다. 미세 조정은 데이터 세트가 요약을 표시하는 방법을 준수하기 위해 몇 가지 템플릿 방식으로 요약을 캡처합니다. 법적 데이터 세트의 경우 이 방법은 제로샷 접근 방식에서 만든 것보다 더 높은 수준의 요약을 생성합니다.
요약 평가
요약 모델의 성능을 평가하기 위한 여러 가지 기술이 있습니다.
몇 가지 예를 들면 다음과 같습니다.
ROUGE(게이팅 평가를 위한 리콜 지향 언더스터디). 이 기술에는 요약을 사용자가 만든 이상적인 요약과 비교하여 요약의 품질을 자동으로 결정하는 측정값이 포함되어 있습니다. 측정값은 계산 중인 컴퓨터에서 생성된 요약과 이상적인 요약 사이에 n-gram, 단어 시퀀스 및 단어 쌍과 같은 겹치는 단위 수를 계산합니다.
예를 들면 다음과 같습니다.
reference_summary = "The cat ison porch by the tree"
generated_summary = "The cat is by the tree on the porch"
rouge = Rouge()
rouge.get_scores(generated_summary, reference_summary)
[{'rouge-1': {'r':1.0, 'p': 1.0, 'f': 0.999999995},
'rouge-2': {'r': 0.5714285714285714, 'p': 0.5, 'f': 0.5333333283555556},
'rouge-1': {'r': 0.75, 'p': 0.75, 'f': 0.749999995}}]
BERTScore. 이 기술은 토큰 수준에서 생성된 요약 및 참조 요약을 정렬하여 유사성 점수를 계산합니다. 토큰 맞춤은 BERT에서 컨텍스트화된 토큰 포함 간의 코사인 유사성을 최대화하기 위해 탐욕적으로 계산됩니다.
예를 들면 다음과 같습니다.
import torchmetrics
from torchmetrics.text.bert import BERTScore
preds = "You should have ice cream in the summer"
target = "Ice creams are great when the weather is hot"
bertscore = BERTScore()
score = bertscore(preds, target)
print(score)
유사성 행렬입니다. 유사성 행렬은 요약 평가에서 서로 다른 엔터티 간의 유사성을 나타내는 것입니다. 이를 사용하여 동일한 텍스트의 다른 요약을 비교하고 유사성을 측정할 수 있습니다. 각 셀에 두 요약 간의 유사성 측정값이 포함된 2차원 표로 표시됩니다. 코사인 유사성, Jac카드 유사성 및 편집 거리와 같은 다양한 방법을 사용하여 유사성을 측정할 수 있습니다. 그런 다음 행렬을 사용하여 요약을 비교하고 원래 텍스트의 가장 정확한 표현을 결정합니다.
다음은 두 개의 유사한 문장에 대한 BERTScore 비교의 유사성 행렬을 가져오는 샘플 명령입니다.
bert-score-show --lang en -r "The cat is on the porch by the tree"
-c "The cat is by the tree on the porch"
-f out.png
첫 번째 문장인 "고양이가 나무의 현관에 있다"는 문장을 후보자라고 합니다. 두 번째 문장을 참조라고 합니다. 이 명령은 BERTScore를 사용하여 문장을 비교하고 행렬을 생성합니다.
다음 행렬은 이전 명령에서 생성된 출력을 표시합니다.
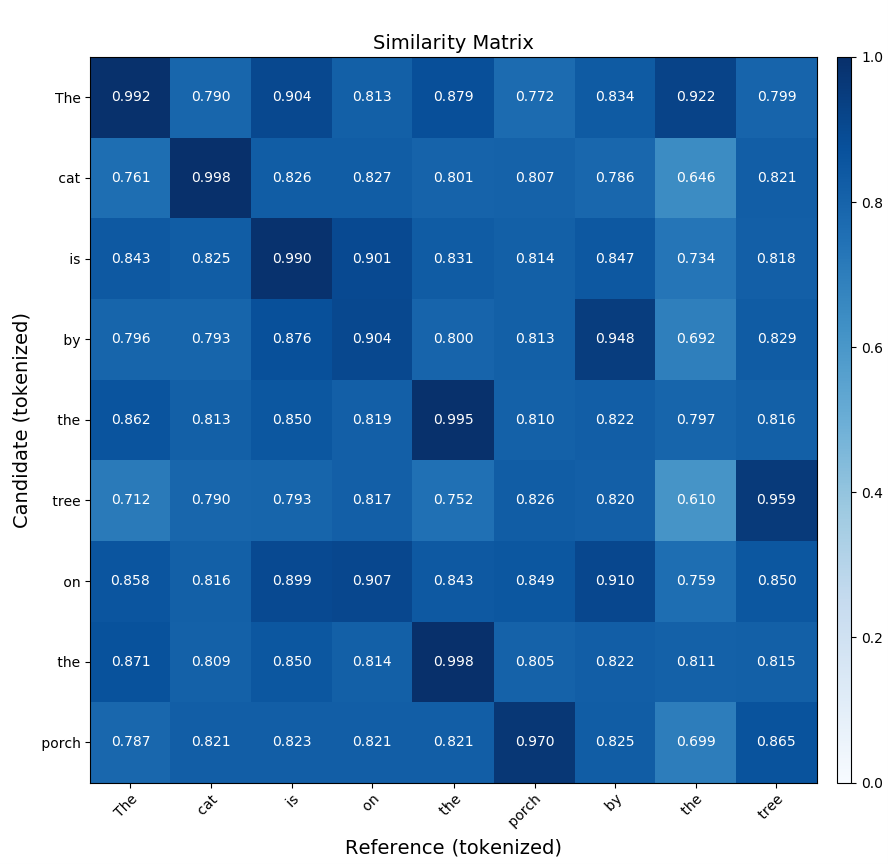
자세한 내용은 SummEval: 요약 평가 재평가를 참조하세요. 요약을 위한 PyPI 도구 키트는 Summ-eval 0.892를 참조하세요.
참가자
Microsoft에서 이 문서를 유지 관리합니다. 원래 다음 기여자가 작성했습니다.
보안 주체 작성자:
- Noa Ben-Efraim | 데이터 및 적용된 과학자
기타 기여자:
비공개 LinkedIn 프로필을 보려면 LinkedIn에 로그인합니다.
다음 단계
관련 참고 자료
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기