붐비는 프런트 엔드 안태패턴
많은 수의 백그라운드 스레드에서 비동기 작업을 수행하면 리소스의 다른 동시 포그라운드 작업을 굶어 죽여 응답 시간을 허용할 수 없는 수준으로 줄일 수 있습니다.
문제 설명
리소스를 많이 사용하는 작업은 사용자 요청에 대한 응답 시간을 늘리고 대기 시간이 높아질 수 있습니다. 응답 시간을 개선하는 한 가지 방법은 리소스 집약적 작업을 별도의 스레드로 오프로드하는 것입니다. 이 방법을 사용하면 백그라운드에서 처리가 수행되는 동안 애플리케이션의 응답성을 유지할 수 있습니다. 하지만 백그라운드 스레드에서 실행되는 작업은 리소스를 여전히 소비합니다. 너무 많은 경우 요청을 처리하는 스레드를 굶어 버리면 됩니다.
참고 항목
리소스라는 용어는 CPU 사용률, 메모리 점유율 및 네트워크나 디스크 I/O와 같은 많은 요소를 포함합니다.
이 문제는 일반적으로 애플리케이션이 모놀리식 코드 조각으로 개발될 때 발생하며, 모든 비즈니스 논리가 프레젠테이션 계층과 공유되는 단일 계층으로 결합됩니다.
다음은 문제를 보여 주는 ASP.NET 사용하는 예제입니다. 전체 샘플은 여기에서 찾을 수 있습니다.
public class WorkInFrontEndController : ApiController
{
[HttpPost]
[Route("api/workinfrontend")]
public HttpResponseMessage Post()
{
new Thread(() =>
{
//Simulate processing
Thread.SpinWait(Int32.MaxValue / 100);
}).Start();
return Request.CreateResponse(HttpStatusCode.Accepted);
}
}
public class UserProfileController : ApiController
{
[HttpGet]
[Route("api/userprofile/{id}")]
public UserProfile Get(int id)
{
//Simulate processing
return new UserProfile() { FirstName = "Alton", LastName = "Hudgens" };
}
}
컨트롤러의 메서드는
PostWorkInFrontEndHTTP POST 작업을 구현합니다. 이 작업은 오래 실행되는 CPU 집약적 작업을 시뮬레이션합니다. 작업은 POST 작업을 신속하게 완료할 수 있도록 하기 위해 별도의 스레드에서 수행됩니다.UserProfile컨트롤러의Get메서드는 HTTP GET 작업을 구현합니다. 이 메서드는 훨씬 적은 CPU를 사용합니다.
주요 관심사는 메서드의 리소스 요구 사항입니다 Post . 작업을 백그라운드 스레드에 배치하지만 작업은 여전히 상당한 CPU 리소스를 사용할 수 있습니다. 리소스는 다른 동시 사용자가 수행하는 다른 작업과 공유됩니다. 중간 수의 사용자가 동시에 이 요청을 보내면 전체 성능이 저하되어 모든 작업이 느려질 수 있습니다. 예를 들면, Get 메서드에서 상당한 대기 시간이 발생할 수 있습니다.
문제를 해결하는 방법
중요한 리소스를 사용하는 프로세스를 별도의 백 엔드로 이동합니다.
이 방법을 사용하면 프런트 엔드는 리소스 집약적 작업을 메시지 큐에 배치합니다. 백 엔드는 비동기 처리를 위한 작업을 선택합니다. 큐는 백 엔드에 대한 요청을 버퍼링하는 부하 평준화자 역할을 합니다. 큐 길이가 너무 길어지면 자동 크기 조정을 구성하여 백 엔드 규모를 확장할 수 있습니다.
다음은 이전 코드의 수정된 버전입니다. 이 버전에서 메서드는 Post Service Bus 큐에 메시지를 배치합니다.
public class WorkInBackgroundController : ApiController
{
private static readonly QueueClient QueueClient;
private static readonly string QueueName;
private static readonly ServiceBusQueueHandler ServiceBusQueueHandler;
public WorkInBackgroundController()
{
var serviceBusConnectionString = ...;
QueueName = ...;
ServiceBusQueueHandler = new ServiceBusQueueHandler(serviceBusConnectionString);
QueueClient = ServiceBusQueueHandler.GetQueueClientAsync(QueueName).Result;
}
[HttpPost]
[Route("api/workinbackground")]
public async Task<long> Post()
{
return await ServiceBusQueueHandler.AddWorkLoadToQueueAsync(QueueClient, QueueName, 0);
}
}
백 엔드는 Service Bus 큐에서 메시지를 끌어와 처리를 수행합니다.
public async Task RunAsync(CancellationToken cancellationToken)
{
this._queueClient.OnMessageAsync(
// This lambda is invoked for each message received.
async (receivedMessage) =>
{
try
{
// Simulate processing of message
Thread.SpinWait(Int32.MaxValue / 1000);
await receivedMessage.CompleteAsync();
}
catch
{
receivedMessage.Abandon();
}
});
}
고려 사항
- 이 방법은 애플리케이션에 몇 가지 복잡성을 더합니다. 오류 발생 시 요청이 손실되지 않도록 큐 및 큐에서 안전하게 큐를 처리해야 합니다.
- 애플리케이션은 메시지 큐에 대한 추가 서비스에 종속됩니다.
- 처리 환경은 예상된 워크로드를 처리하고 필요한 처리량 목표를 충족하기에 충분한 확장성이 있어야 합니다.
- 이 방법은 전반적인 응답성을 향상시켜야 하지만 백 엔드로 이동하는 작업을 완료하는 데 시간이 더 오래 걸릴 수 있습니다.
문제를 감지하는 방법
사용량이 많은 프런트 엔드의 증상에는 리소스 집약적 작업이 수행될 때 높은 대기 시간이 포함됩니다. 최종 사용자는 서비스 시간 초과로 인한 확장된 응답 시간 또는 실패를 보고할 가능성이 높습니다. 이러한 오류는 HTTP 500(내부 서버) 오류 또는 HTTP 503(서비스를 사용할 수 없음) 오류를 반환할 수도 있습니다. 웹 서버의 이벤트 로그를 검사하세요. 오류의 원인과 상황에 대한 자세한 정보가 포함되어 있을 수 있습니다.
다음 단계를 수행하면 문제를 식별하는 데 도움이 될 수 있습니다.
- 프로덕션 시스템의 프로세스 모니터링을 수행하여 응답 시간이 느려지는 시점을 파악합니다.
- 이러한 지점에서 캡처된 원격 분석 데이터를 검사하여 수행 중인 작업과 사용 중인 리소스의 혼합을 확인합니다.
- 잘못된 응답 시간과 해당 시간에 발생한 볼륨 및 작업 조합 간의 상관 관계를 찾습니다.
- 의심되는 각 작업을 부하 테스트하여 리소스를 소비하고 다른 작업이 부족한 작업을 식별합니다.
- 이러한 작업에 대한 소스 코드를 검토하여 과도한 리소스 소비를 유발할 수 있는 이유를 확인합니다.
예제 진단
다음 섹션에서는 이러한 단계를 앞에서 설명한 애플리케이션 예제에 적용합니다.
속도 저하 지점 식별
각 요청이 소비하는 기간 및 자원을 추적하기 위해 각 메서드를 계측합니다. 그런 다음, 프로덕션 환경에서 애플리케이션을 모니터링합니다. 요청이 서로 경쟁하는 방식을 전반적으로 볼 수 있습니다. 스트레스가 많은 기간 동안 리소스가 부족한 느린 요청은 다른 작업에 영향을 줄 수 있으며, 시스템을 모니터링하고 성능 저하를 확인하여 이 동작을 관찰할 수 있습니다.
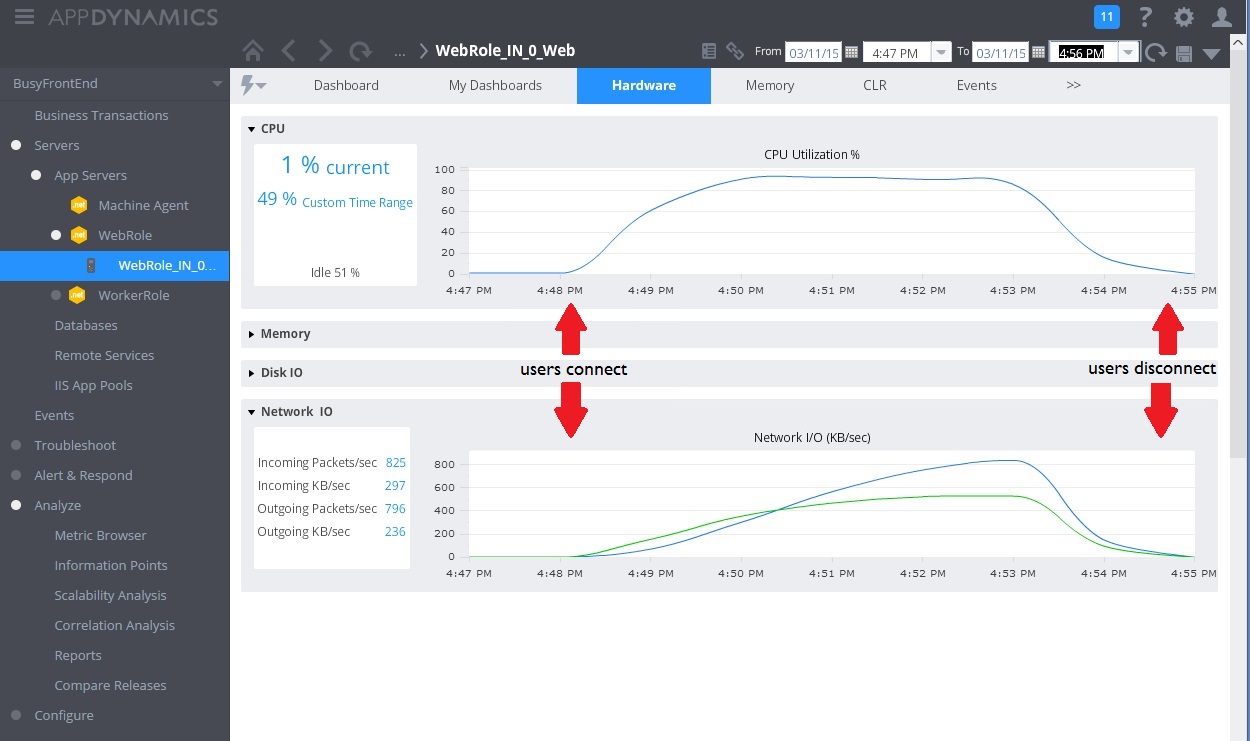
다음 이미지는 모니터링 대시보드입니다. (사용했습니다. 테스트에 대한 AppDynamics 입니다.) 처음에는 시스템에 가벼운 부하가 있습니다. 그런 다음 사용자가 GET 메서드를 요청하기 UserProfile 시작합니다. 다른 사용자가 POST 메서드에 대한 요청 발급을 시작할 때까지 성능이 WorkInFrontEnd 상당히 좋습니다. 이때 응답 시간이 크게 증가합니다(첫 번째 화살표). 응답 시간은 컨트롤러에 대한 요청 WorkInFrontEnd 볼륨이 감소한 후에만 향상됩니다(두 번째 화살표).
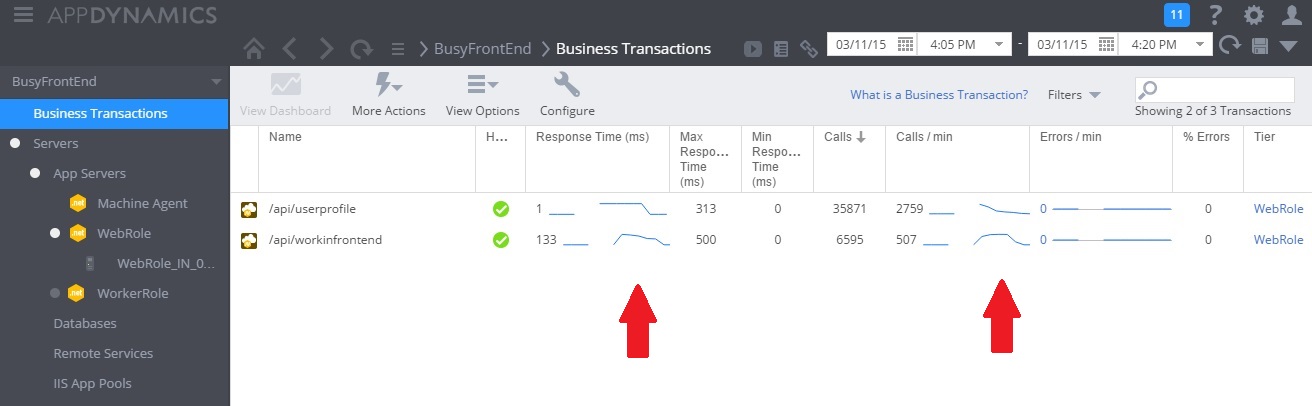
원격 분석 데이터 검사 및 상관 관계 찾기
다음 이미지는 동일한 간격 동안 리소스 사용률을 모니터링하기 위해 수집된 일부 메트릭을 보여 줍니다. 처음에는 시스템에 액세스하는 사용자가 거의 없습니다. 연결하는 사용자가 많아지면서 CPU 사용률이 매우 높아집니다(100 %). 또한 CPU 사용량이 증가함에 따라 처음에는 네트워크 I/O 속도가 증가합니다. 하지만 CPU 사용량이 최고가 되면 네트워크 I/O가 실제로 내려갑니다. CPU가 용량에 도달하면 시스템이 비교적 적은 수의 요청만 처리할 수 있기 때문입니다. 사용자가 연결을 끊으면 CPU 로드가 끝납니다.
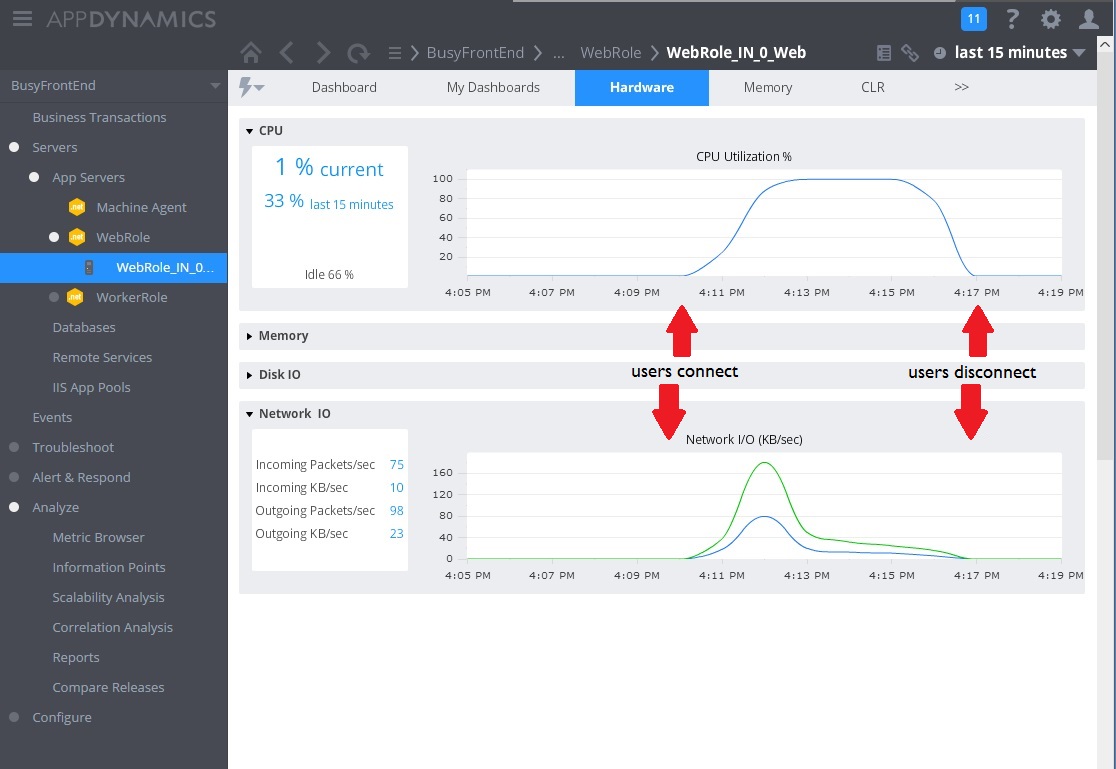
이 시점에서 컨트롤러의 Post 방법이 WorkInFrontEnd 면밀한 조사를 위한 유력한 후보인 것으로 보입니다. 가설을 확인하려면 통제된 환경에서 추가 작업이 필요합니다.
부하 테스트 수행
다음 단계는 제어된 환경에서 테스트를 수행하는 것입니다. 예를 들어, 요청을 포함하는 일련의 부하 테스트를 실행한 다음 각 요청을 차례로 생략하면서 영향을 확인합니다.
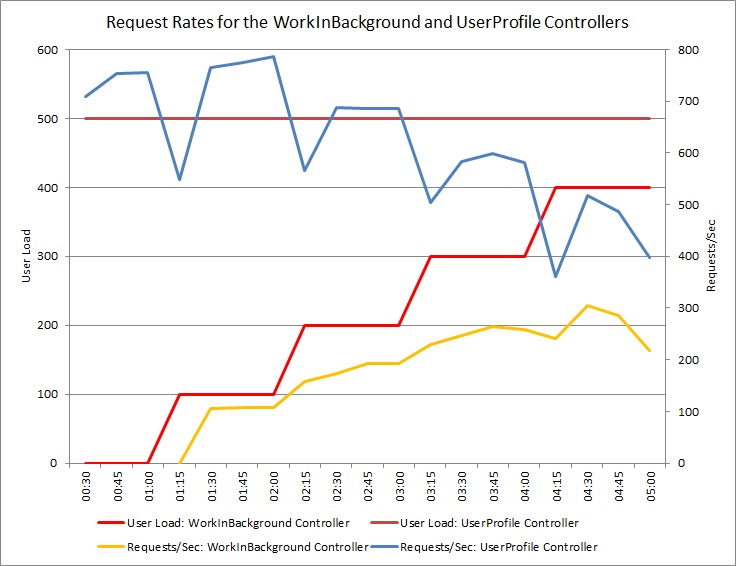
아래 그래프는 이전 테스트에서 사용된 클라우드 서비스의 동일한 배포에 대해 수행된 부하 테스트의 결과를 보여 줍니다. 테스트는 컨트롤러에서 작업을 수행하는 사용자의 단계 부하와 함께 컨트롤러에서 UserProfile 작업을 수행하는 GetPost 500명의 사용자의 일정한 부하를 WorkInFrontEnd 사용했습니다.
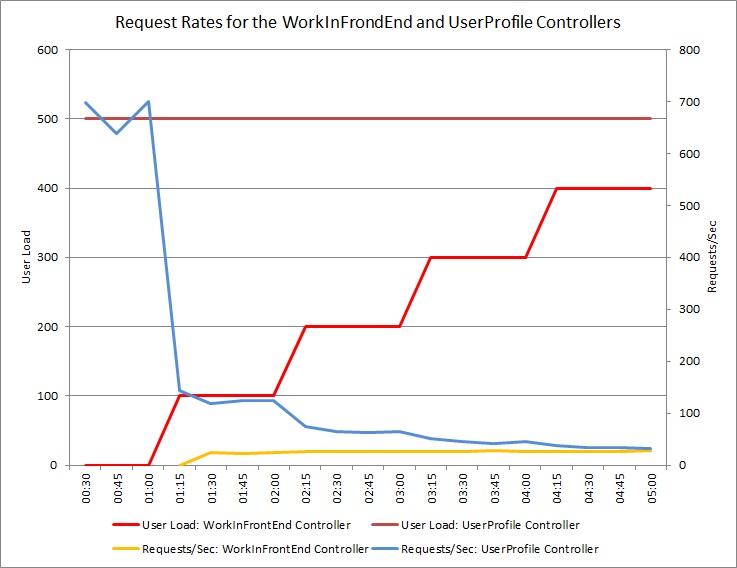
처음에는 단계 로드가 0이므로 활성 사용자만 요청을 수행 UserProfile 합니다. 시스템은 초당 약 500개의 요청에 응답할 수 있습니다. 60초 후에 100명의 추가 사용자가 컨트롤러에 POST 요청을 보내기 시작합니다 WorkInFrontEnd . 거의 즉시, UserProfile 컨트롤러에 전송된 워크로드가 초당 약 150개 요청으로 떨어집니다. 이는 부하 테스트 실행기가 작동하는 방식 때문입니다. 다음 요청을 보내기 전에 응답을 대기하므로 응답을 받는 데 걸리는 시간이 길어질수록 요청 속도가 낮아질 수 있습니다.
더 많은 사용자가 컨트롤러에 WorkInFrontEnd POST 요청을 보내면 컨트롤러의 UserProfile 응답 속도가 계속 감소합니다. 하지만 WorkInFrontEnd 컨트롤러가 처리하는 요청의 볼륨은 비교적 일정하게 유지됩니다. 두 요청의 전반적인 속도가 꾸준히 낮은 한도로 향하기 때문에 시스템의 포화 상태가 명백해집니다.
소스 코드 검토
마지막 단계에서는 소스 코드를 확인합니다. 개발 팀은 이 메서드에 Post 상당한 시간이 걸릴 수 있다는 것을 알고 있었기 때문에 원래 구현에서 별도의 스레드를 사용했습니다. 메서드가 장기 실행 작업이 완료될 때까지 기다리는 것을 차단하지 않았기 때문에 Post 즉각적인 문제가 해결되었습니다.
그러나 이 메서드에서 수행하는 작업은 여전히 CPU, 메모리 및 기타 리소스를 사용합니다. 이 프로세스를 비동기적으로 실행하도록 설정하면 사용자가 제어되지 않는 방식으로 많은 수의 작업을 동시에 트리거할 수 있으므로 실제로 성능이 손상될 수 있습니다. 서버가 실행할 수 있는 스레드의 수는 한도가 있습니다. 이 제한을 초과하면 애플리케이션이 새 스레드를 시작하려고 할 때 예외가 발생할 수 있습니다.
참고 항목
그렇다고 비동기 작업을 피해야 한다는 의미는 아닙니다. 네트워크 호출에서 비동기 대기를 수행하는 것이 좋습니다. (다음을 참조하세요. 동기 I/O 안티패턴.) 여기서 문제는 CPU 집약적 작업이 다른 스레드에서 생성되었다는 것입니다.
솔루션 구현 및 결과 확인
다음 이미지는 솔루션이 구현된 후의 성능 모니터링을 보여 줍니다. 부하는 이전에 표시된 것과 유사하지만 컨트롤러에 대한 UserProfile 응답 시간이 훨씬 더 빠릅니다. 요청 볼륨은 같은 기간 동안 2,759개에서 23,565건으로 증가했습니다.
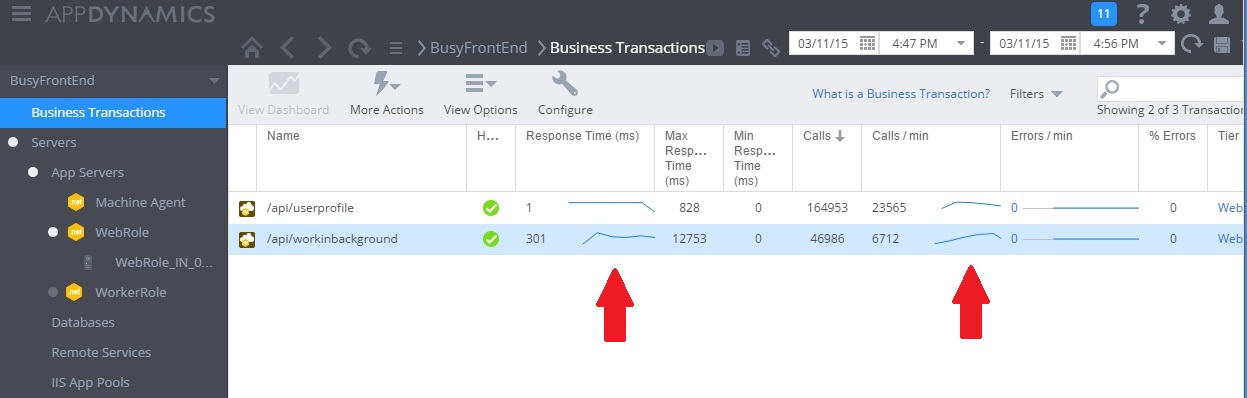
WorkInBackground 컨트롤러 역시 훨씬 더 많은 요청 볼륨을 처리했습니다. 그러나 이 경우 이 컨트롤러에서 수행되는 작업이 원래 코드와 매우 다르므로 직접 비교할 수는 없습니다. 새 버전에서는 시간이 오래 걸리는 계산을 수행하는 것이 아니라 요청을 큐에 넣기만 합니다. 기본 점은 이 메서드가 더 이상 로드 중인 전체 시스템을 아래로 끌지 않는다는 것입니다.
CPU 및 네트워크 사용률 역시 향상된 성능을 보여줍니다. CPU 사용률이 100%에 도달하지 않았고 처리된 네트워크 요청 볼륨이 이전보다 훨씬 컸으며 워크로드가 떨어질 때까지 중단되지 않았습니다.
다음 그래프는 부하 테스트의 결과를 보여줍니다. 서비스된 요청의 전체 볼륨은 이전 테스트에 비해 크게 향상되었습니다.
관련 지침
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기