자습서: Notebook을 사용하여 Azure Monitor 로그의 데이터 분석
Notebook은 라이브 코드, 수식, 시각화 및 텍스트로 문서를 만들고 공유할 수 있는 통합 환경입니다. Notebook을 Log Analytics 작업 영역과 통합하면 이전 단계의 결과에 따라 각 단계에서 코드를 실행하는 다단계 프로세스를 만들 수 있습니다. 이러한 간소화된 프로세스를 사용하여 기계 학습 파이프라인, 고급 분석 도구, 지원 요구 사항에 대한 TSG(문제 해결 가이드) 등을 빌드할 수 있습니다.
Notebook을 Log Analytics 작업 영역과 통합하면 다음을 수행할 수도 있습니다.
- 원하는 언어로 KQL 쿼리 및 사용자 지정 코드를 실행합니다.
- 새 기계 학습 모델, 사용자 지정 타임라인 및 프로세스 트리와 같은 새로운 분석 및 시각화 기능을 소개합니다.
- 온-프레미스 데이터 세트와 같은 Azure Monitor 로그 외부의 데이터 세트를 통합합니다.
- Azure Portal에 비해 쿼리 API 제한을 사용하여 향상된 서비스 제한을 활용합니다.
이 자습서에서는 다음을 하는 방법을 알아볼 수 있습니다.
- Azure Monitor 쿼리 클라이언트 라이브러리 및 Azure ID 클라이언트 라이브러리를 사용하여 Log Analytics 작업 영역과 Notebook 통합
- Notebook의 Log Analytics 작업 영역에서 데이터 탐색 및 시각화
- Notebook에서 Log Analytics 작업 영역의 사용자 지정 테이블로 데이터 수집(선택 사항)
Notebook을 사용하여 Azure Monitor 로그의 데이터를 분석하는 기계 학습 파이프라인을 빌드하는 방법의 예는 이 샘플 Notebook: 기계 학습 기술을 사용하여 Azure Monitor 로그에서 변칙 검색을 참조하세요.
팁
필수 조건
이 자습서에서는 다음이 필요합니다.
다음을 포함하는 CPU 컴퓨팅 인스턴스가 있는 Azure Machine Learning 작업 영역:
- Notebook
- Python 3.8 이상으로 설정된 커널.
다음 역할 및 권한:
Azure Monitor 로그에서: Logs Analytics 작업 영역에서 데이터를 읽고 데이터를 보내는 Logs Analytics 기여자 자세한 내용은 Log Analytics 작업 영역에 대한 액세스 관리를 참조하세요.
Azure Machine Learning에서:
- 필요한 경우 새 Azure Machine Learning 작업 영역을 만들기 위한 리소스 그룹 수준 소유자 또는 기여자 역할.
- Notebook을 실행하는 Azure Machine Learning 작업 영역의 기여자 역할.
자세한 내용은 Azure Machine Learning 작업 영역 액세스 관리를 참조하세요.
도구 및 Notebook
이 자습서에서는 다음 도구를 사용합니다.
| 도구 | 설명 |
|---|---|
| Azure Monitor 쿼리 클라이언트 라이브러리 | Azure Monitor 로그의 데이터에 대한 읽기 전용 쿼리를 실행할 수 있습니다. |
| Azure ID 클라이언트 라이브러리 | Azure SDK 클라이언트가 Microsoft Entra ID로 인증할 수 있도록 합니다. |
| Azure Monitor 수집 클라이언트 라이브러리 | 로그 수집 API를 사용하여 Azure Monitor에 사용자 지정 로그를 보낼 수 있습니다. 분석된 데이터를 Log Analytics 작업 영역의 사용자 지정 테이블로 수집(선택 사항)하는 데 필요합니다. |
| 데이터 수집 규칙, 데이터 수집 엔드포인트 및 등록된 애플리케이션 | 분석된 데이터를 Log Analytics 작업 영역의 사용자 지정 테이블로 수집(선택 사항)하는 데 필요합니다. |
사용할 수 있는 다른 쿼리 라이브러리는 다음과 같습니다.
- Kqlmagic 라이브러리를 사용하면 Log Analytics 도구에서 KQL 쿼리를 실행하는 것과 동일한 방식으로 Notebook 내에서 직접 KQL 쿼리를 실행할 수 있습니다.
- MSTICPY 라이브러리는 기본 제공 KQL 시계열 및 기계 학습 기능을 호출하는 템플릿 쿼리를 제공하고 Log Analytics 작업 영역에서 고급 시각화 도구 및 데이터 분석을 제공합니다.
고급 분석을 위한 기타 Microsoft Notebook 환경은 다음과 같습니다.
1. Log Analytics 작업 영역을 Notebook과 통합
Log Analytics 작업 영역을 쿼리하도록 Notebook을 설정합니다.
Azure Monitor 쿼리, Azure ID 및 Azure Monitor 수집 클라이언트 라이브러리(Pandas 데이터 분석 라이브러리, Plotly 시각화 라이브러리 포함)를 설치합니다.
import sys !{sys.executable} -m pip install --upgrade azure-monitor-query azure-identity azure-monitor-ingestion !{sys.executable} -m pip install --upgrade pandas plotly아래
LOGS_WORKSPACE_ID변수를 Log Analytics 작업 영역의 ID로 설정합니다. 이 변수는 현재 Notebook을 예시하는 데 사용할 수 있는 Azure Monitor 데모 작업 영역을 사용하도록 설정되어 있습니다.LOGS_WORKSPACE_ID = "DEMO_WORKSPACE"Azure Monitor 로그를 인증하고 쿼리하도록
LogsQueryClient를 설정합니다.이 코드는
DefaultAzureCredential을 사용하여 인증하도록LogsQueryClient를 설정합니다.from azure.core.credentials import AzureKeyCredential from azure.core.pipeline.policies import AzureKeyCredentialPolicy from azure.identity import DefaultAzureCredential from azure.monitor.query import LogsQueryClient if LOGS_WORKSPACE_ID == "DEMO_WORKSPACE": credential = AzureKeyCredential("DEMO_KEY") authentication_policy = AzureKeyCredentialPolicy(name="X-Api-Key", credential=credential) else: credential = DefaultAzureCredential() authentication_policy = None logs_query_client = LogsQueryClient(credential, authentication_policy=authentication_policy)LogsQueryClient는 일반적으로 Microsoft Entra 토큰 자격 증명을 사용한 인증만 지원합니다. 그러나 사용자 지정 인증 정책을 전달하여 API 키를 사용하도록 설정할 수 있습니다. 이렇게 하면 클라이언트가 데모 작업 영역을 쿼리할 수 있습니다. 이 데모 작업 영역에 대한 가용성 및 액세스는 변경될 수 있으므로 고유한 Log Analytics 작업 영역을 사용하는 것이 좋습니다.Log Analytics 작업 영역에서 지정된 쿼리를 실행하고 결과를 Pandas DataFrame으로 반환하는
query_logs_workspace라는 도우미 함수를 정의합니다.import pandas as pd import plotly.express as px from azure.monitor.query import LogsQueryStatus from azure.core.exceptions import HttpResponseError def query_logs_workspace(query): try: response = logs_query_client.query_workspace(LOGS_WORKSPACE_ID, query, timespan=None) if response.status == LogsQueryStatus.PARTIAL: error = response.partial_error data = response.partial_data print(error.message) elif response.status == LogsQueryStatus.SUCCESS: data = response.tables for table in data: my_data = pd.DataFrame(data=table.rows, columns=table.columns) except HttpResponseError as err: print("something fatal happened") print (err) return my_data
2. Notebook의 Log Analytics 작업 영역에서 데이터 탐색 및 시각화
Notebook에서 쿼리를 실행하여 작업 영역의 일부 데이터를 살펴보겠습니다.
이 쿼리는 지난 주 동안 매시간 Log Analytics 작업 영역의 각 테이블(데이터 형식)에 수집한 데이터의 양(메가바이트)을 확인합니다.
TABLE = "Usage" QUERY = f""" let starttime = 7d; // Start date for the time series, counting back from the current date let endtime = 0d; // today {TABLE} | project TimeGenerated, DataType, Quantity | where TimeGenerated between (ago(starttime)..ago(endtime)) | summarize ActualUsage=sum(Quantity) by TimeGenerated=bin(TimeGenerated, 1h), DataType """ df = query_logs_workspace(QUERY) display(df)결과 DataFrame은 Log Analytics 작업 영역의 각 테이블에 시간별 수집을 보여 줍니다.
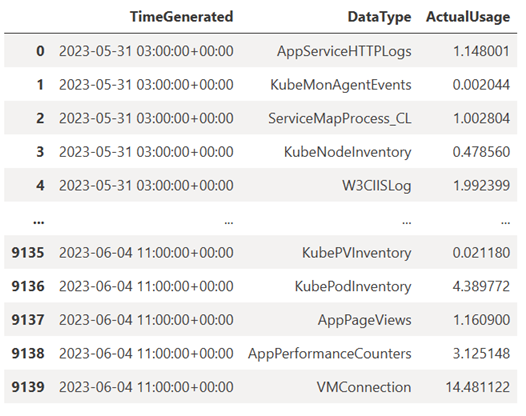
이제 Pandas DataFrame을 기준으로 시간이 지남에 따라 다양한 데이터 형식에 대한 시간별 사용량을 보여 주는 그래프 형태로 데이터를 살펴보겠습니다.
df = df.sort_values(by="TimeGenerated") graph = px.line(df, x='TimeGenerated', y="ActualUsage", color='DataType', title="Usage in the last week - All data types") graph.show()결과 그래프는 다음과 같습니다.
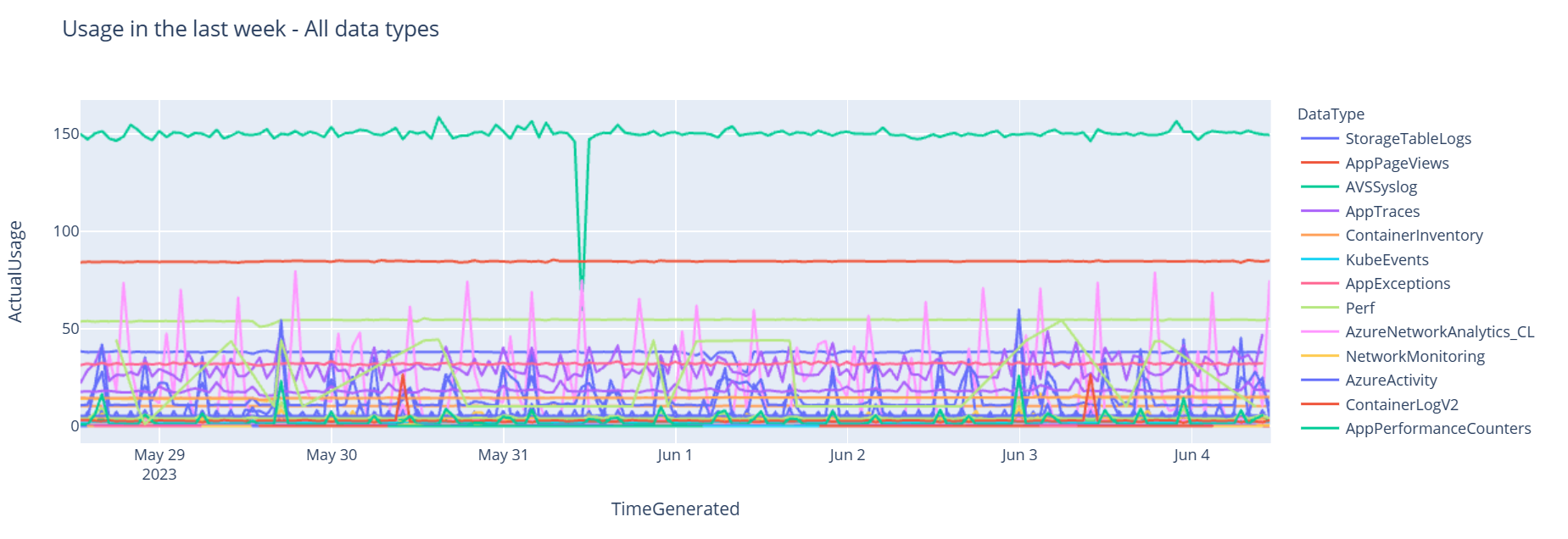
Notebook의 Log Analytics 작업 영역에서 로그 데이터를 쿼리하고 시각화했습니다.

3. 데이터 분석
간단한 예제로 처음 5개 행을 살펴보겠습니다.
analyzed_df = df.head(5)
Azure Monitor 로그의 데이터를 분석하는 기계 학습 기술을 구현하는 방법의 예는 이 샘플 Notebook: 기계 학습 기술을 사용하여 Azure Monitor 로그에서 변칙 검색을 참조하세요.
4. 분석된 데이터를 Log Analytics 작업 영역의 사용자 지정 테이블로 수집(선택 사항)
Log Analytics 작업 영역의 사용자 지정 테이블에 분석 결과를 보내 경고를 트리거하거나 추가 분석을 사용할 수 있도록 합니다.
Log Analytics 작업 영역으로 데이터를 보내려면 자습서: 로그 수집 API(Azure Portal)를 사용하여 Azure Monitor 로그에 데이터 보내기에 설명된 대로 데이터 수집 규칙을 사용할 수 있는 권한이 있는 사용자 지정 테이블, 데이터 수집 엔드포인트, 데이터 수집 규칙 및 등록된 Microsoft Entra 애플리케이션이 필요합니다.
사용자 지정 테이블을 만드는 경우:
이 샘플 파일을 업로드하여 테이블 스키마를 정의합니다.
[ { "TimeGenerated": "2023-03-19T19:56:43.7447391Z", "ActualUsage": 40.1, "DataType": "AzureDiagnostics" } ]
로그 수집 API에 필요한 상수를 정의합니다.
os.environ['AZURE_TENANT_ID'] = "<Tenant ID>"; #ID of the tenant where the data collection endpoint resides os.environ['AZURE_CLIENT_ID'] = "<Application ID>"; #Application ID to which you granted permissions to your data collection rule os.environ['AZURE_CLIENT_SECRET'] = "<Client secret>"; #Secret created for the application os.environ['LOGS_DCR_STREAM_NAME'] = "<Custom stream name>" ##Name of the custom stream from the data collection rule os.environ['LOGS_DCR_RULE_ID'] = "<Data collection rule immutableId>" # immutableId of your data collection rule os.environ['DATA_COLLECTION_ENDPOINT'] = "<Logs ingestion URL of your endpoint>" # URL that looks like this: https://xxxx.ingest.monitor.azure.comLog Analytics 작업 영역의 사용자 지정 테이블에 데이터를 수집합니다.
from azure.core.exceptions import HttpResponseError from azure.identity import ClientSecretCredential from azure.monitor.ingestion import LogsIngestionClient import json credential = ClientSecretCredential( tenant_id=AZURE_TENANT_ID, client_id=AZURE_CLIENT_ID, client_secret=AZURE_CLIENT_SECRET ) client = LogsIngestionClient(endpoint=DATA_COLLECTION_ENDPOINT, credential=credential, logging_enable=True) body = json.loads(analyzed_df.to_json(orient='records', date_format='iso')) try: response = client.upload(rule_id=LOGS_DCR_RULE_ID, stream_name=LOGS_DCR_STREAM_NAME, logs=body) print("Upload request accepted") except HttpResponseError as e: print(f"Upload failed: {e}")참고 항목
Log Analytics 작업 영역에서 테이블을 만들 때 수집된 데이터가 테이블에 표시되는 데 최대 15분이 걸릴 수 있습니다.
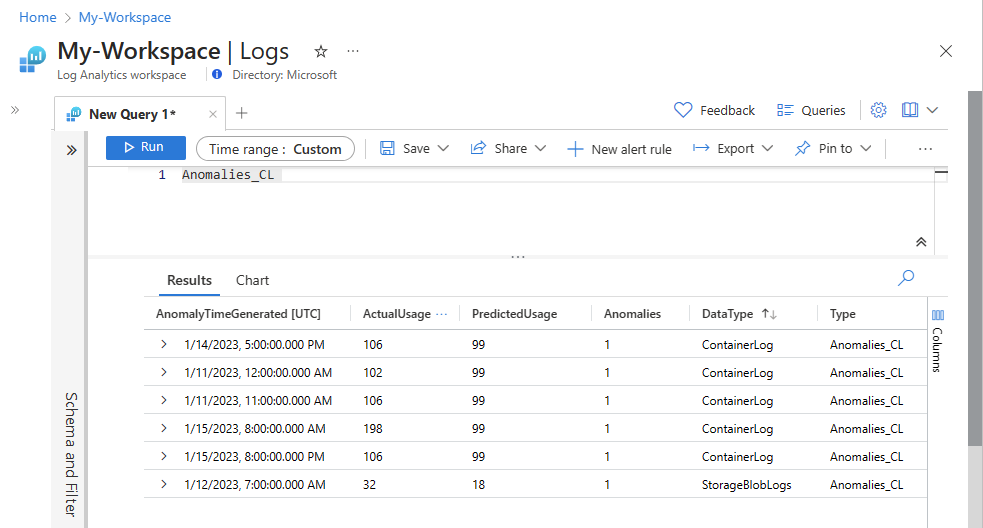
이제 데이터가 사용자 지정 테이블에 표시되는지 확인합니다.

다음 단계
다음을 수행하는 방법을 자세히 알아봅니다.