매핑 데이터 흐름 성능 및 조정 가이드
적용 대상: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
Azure Data Factory 및 Synapse 파이프라인의 매핑 데이터 흐름은 대규모로 데이터 변환을 설계하고 실행할 수 있는 코드 없는 인터페이스를 제공합니다. 매핑 데이터 흐름을 잘 모르는 경우 매핑 데이터 흐름 개요를 참조하세요. 이 문서에서는 성능 벤치마크를 충족하도록 데이터 흐름을 튜닝하고 최적화하는 다양한 방법을 중점적으로 설명합니다.
다음 비디오는 데이터 흐름을 사용하여 데이터를 변환하는 몇 가지 샘플 타이밍을 보여줍니다.
데이터 흐름 성능 모니터링
디버그 모드를 사용하여 변환 논리를 확인한 후에는 데이터 흐름을 파이프라인의 작업으로써 처음부터 끝까지 테스트합니다. 데이터 흐름은 데이터 흐름 작업 실행을 사용하여 파이프라인에서 작동합니다. 데이터 흐름 작업에는 다른 작업과 달리 변환 논리의 자세한 실행 계획 및 성능 프로필을 표시하는 고유한 모니터링 환경이 있습니다. 데이터 흐름의 자세한 모니터링 정보를 보려면 파이프라인의 활동 실행 출력에서 안경 아이콘을 선택합니다. 자세한 내용은 매핑 데이터 흐름 모니터링을 참조하세요.

데이터 흐름 성능을 모니터링할 때 다음과 같은 네 가지 병목 현상을 살펴봐야 합니다.
- 클러스터 시작 시간
- 원본에서 읽기
- 변환 시간
- 싱크에 쓰기
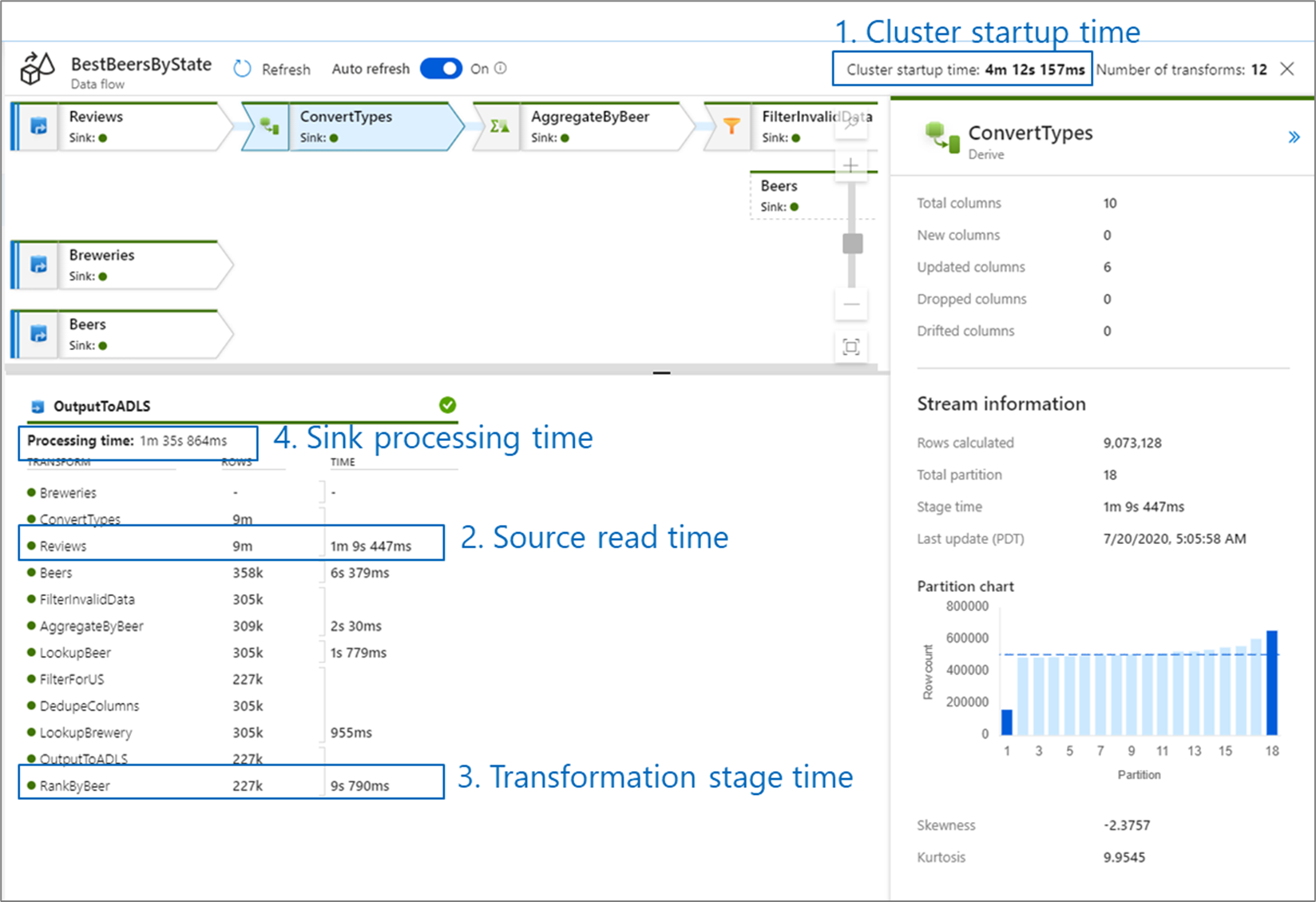
클러스터 시작 시간은 Apache Spark 클러스터를 가동하는 데 걸리는 시간입니다. 이 값은 모니터링 화면의 오른쪽 위 모서리에 있습니다. 데이터 흐름은 각 작업이 격리된 클러스터를 사용하는 Just-In-Time 모델에서 실행됩니다. 이 시작 시간은 일반적으로 3-5입니다. 순차적 작업의 경우 Time to Live 값을 사용하여 시작 시간을 줄일 수 있습니다. 자세한 내용은 통합 런타임 성능의 TTL(Time to live) 섹션을 참조하세요.
데이터 흐름은 '스테이지'의 비즈니스 논리를 다시 정렬하고 실행하여 최대한 수행하는 Spark 최적화 프로그램을 활용합니다. 데이터 흐름에서 기록하는 각 싱크의 경우 모니터링 출력에는 싱크에 데이터를 쓰는 데 걸리는 시간과 함께 각 변환 단계의 기간이 나열됩니다. 가장 긴 시간은 데이터 흐름의 병목 상태를 의미할 수 있습니다. 가장 오래 걸리는 변환 단계에 원본이 포함된 경우 좀 더 자세히 살펴보고 읽기 시간을 최적화할 수 있습니다. 변환이 오래 걸리는 경우 통합 런타임을 다시 분할하거나 크기를 늘려야 할 수 있습니다. 싱크 처리가 오래 걸리는 경우 데이터베이스를 스케일 업하거나 단일 파일에 출력하고 있지는 않은지 확인해야 할 수 있습니다.
데이터 흐름의 병목 상태를 확인한 후에는 아래 최적화 전략을 사용하여 성능을 향상합니다.
데이터 흐름 논리 테스트
UI에서 데이터 흐름을 디자인하고 테스트하는 경우 디버그 모드를 사용하면 라이브 Spark 클러스터에 대해 대화형으로 테스트할 수 있으므로 클러스터가 준비되는 것을 기다리지 않고 데이터를 미리 보고 데이터 흐름을 실행할 수 있습니다. 자세한 내용은 디버그 모드를 참조하세요.
최적화 탭
최적화 탭에는 Spark 클러스터의 파티션 구성표를 구성하는 설정이 포함되어 있습니다. 이 탭은 데이터 흐름의 모든 변환에 있으며 변환이 완료된 후 데이터를 다시 분할할 것인지 여부를 지정합니다. 데이터 분할을 조정하면 전반적인 데이터 흐름 성능에 긍정적인 영향과 부정적인 영향을 모두 줄 수 있는 컴퓨팅 노드 간의 데이터 분산 및 데이터 위치 최적화를 제어할 수 있습니다.
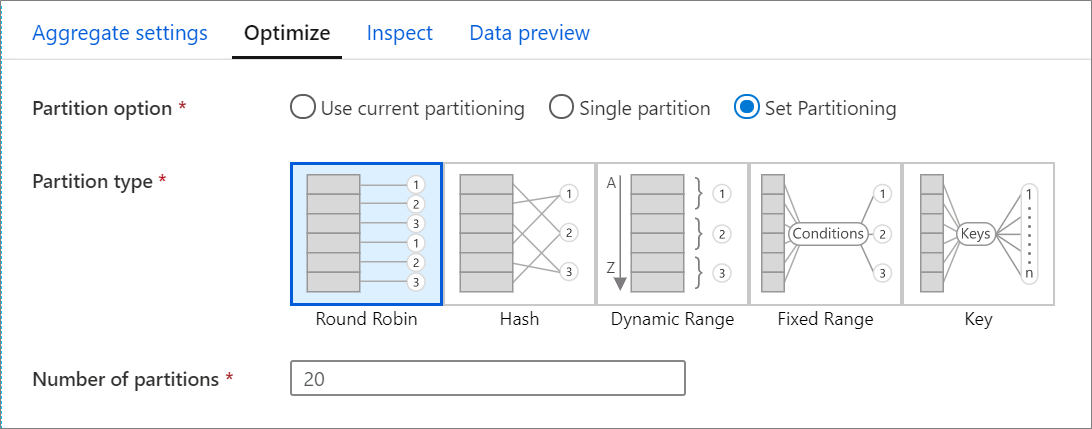
변환의 현재 출력 분할을 유지하도록 서비스에 지시하는 현재 분할 사용이 기본적으로 선택됩니다. 데이터를 다시 분할하는 데 시간이 걸리므로 대부분의 시나리오에서는 현재 분할 사용을 선택하는 것이 좋습니다. 데이터를 상당히 왜곡하는 집계 및 조인 이후 또는 SQL 데이터베이스에서 원본 분할을 사용하는 경우 데이터를 다시 분할해야 할 수도 있습니다.
변환의 분할을 변경하려면 최적화 탭을 클릭하고 분할 설정 라디오 단추를 선택합니다. 그러면 일련의 분할 옵션이 표시됩니다. 최상의 분할 방법은 데이터 볼륨, 후보 키, null 값 및 카디널리티에 따라 다릅니다.
Important
단일 파티션은 모든 분산 데이터를 단일 파티션에 결합합니다. 이 작업은 모든 다운스트림 변환과 쓰기에 상당한 영향을 주는 매우 느린 작업입니다. 이 옵션은 이 옵션을 사용하는 것이 명시적인 비즈니스 이유가 없으면 사용하지 않는 것이 좋습니다.
다음 분할 옵션은 모든 변환에 사용할 수 있습니다.
라운드 로빈
라운드 로빈은 파티션 간에 데이터를 균등하게 분산 합니다. 견고하고 스마트한 분할 전략을 구현하기 위한 적절한 키 후보가 없는 경우 라운드 로빈을 사용합니다. 물리적 파티션 수를 설정할 수 있습니다.
해시
이 서비스는 유사한 값을 가진 행이 동일한 파티션에 속하도록 균일한 파티션을 생성하기 위해 열 해시를 생성합니다. 해시 옵션을 사용하는 경우 가능한 파티션 기울이기를 테스트합니다. 물리적 파티션 수를 설정할 수 있습니다.
동적 범위
동적 범위는 사용자가 제공하는 열 또는 식을 기반으로 하는 Spark 동적 범위를 사용합니다. 물리적 파티션 수를 설정할 수 있습니다.
고정 범위
분할된 데이터 열의 값에 대한 고정 범위를 제공하는 식을 작성합니다. 파티션 기울이기를 방지하기 위해 이 옵션을 사용하기 전에 데이터를 잘 파악해야 합니다. 식에 대해 입력한 값이 파티션 함수의 일부로 사용됩니다. 물리적 파티션 수를 설정할 수 있습니다.
키
데이터의 카디널리티를 잘 알고 있는 경우 키 분할은 좋은 전략이 될 수 있습니다. 키 분할은 열의 각 고유 값에 대한 파티션을 만듭니다. 숫자가 데이터의 고유 값을 기반으로 하기 때문에 파티션 수를 설정할 수 없습니다.
팁
파티션 구성표를 수동으로 설정하면 데이터가 다시 섞여서 Spark 최적화 프로그램의 이점이 상쇄될 수 있습니다. 꼭 필요한 경우를 제외하고 분할을 수동으로 설정하지 않는 것이 가장 좋습니다.
로깅 수준
데이터 흐름 활동의 모든 파이프라인 실행에서 모든 자세한 원격 분석 로그를 완전히 기록할 필요가 없는 경우 필요에 따라 로깅 수준을 '기본' 또는 '없음'으로 설정할 수 있습니다. '자세한 정보' 모드(기본값)에서 데이터 흐름을 실행하는 경우 서비스에 데이터 변환 중 각 개별 파티션 수준에서 작업을 완전히 기록하도록 요청하는 것입니다. 이 작업은 비용이 많이 들 수 있으므로 문제를 해결하는 경우에만 자세한 정보를 사용하면 전체 데이터 흐름 및 파이프라인 성능을 향상시킬 수 있습니다. '기본' 모드에서는 변환 기간만 기록하고, '없음'의 경우 기간 요약만 제공합니다.

관련 콘텐츠
성능과 관련된 다음과 같은 다른 데이터 흐름 문서를 참조하세요.