Azure HDInsight의 Apache Spark에 대한 OutOfMemoryError 예외
이 문서에서는 Azure HDInsight 클러스터에서 Apache Spark 구성 요소를 사용할 때 발생하는 문제 해결 단계와 가능한 문제 해결 방법을 설명합니다.
시나리오: Apache Spark에 대한 OutOfMemoryError 예외
문제
OutOfMemoryError 처리되지 않은 예외가 발생하여 Apache Spark 애플리케이션이 실패했습니다. 다음과 유사한 오류 메시지가 표시될 경우:
ERROR Executor: Exception in task 7.0 in stage 6.0 (TID 439)
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.grow(Unknown Source)
at java.io.ByteArrayOutputStream.ensureCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.write(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.drain(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.setBlockDataMode(Unknown Source)
at java.io.ObjectOutputStream.writeObject0(Unknown Source)
at java.io.ObjectOutputStream.writeObject(Unknown Source)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:44)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:239)
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.lang.Thread.run(Unknown Source)
ERROR SparkUncaughtExceptionHandler: Uncaught exception in thread Thread[Executor task launch worker-0,5,main]
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
...
원인
이 예외의 가장 가능성 높은 원인은 JVM(Java Virtual Machine)에 할당된 힙 메모리가 충분하지 않다는 것입니다. 이러한 JVM은 Apache Spark 애플리케이션의 일부로 실행기 또는 드라이버로서 시작됩니다.
해결
Spark 애플리케이션에서 처리하는 데이터의 최대 크기를 결정합니다. 입력 데이터 크기의 최대값, 입력 데이터 변환을 통해 생성된 중간 데이터와 중간 데이터의 추가적인 변환을 통해 생성된 출력 데이터에 따라 이러한 크기를 추측합니다. 초기 예상이 충분하지 않다면, 크기를 약간 늘리세요. 메모리 오류가 사라질 때까지 반복하세요.
사용할 HDInsight 클러스터가 Spark 애플리케이션을 수용할 수 있는 메모리와 코어 등 충분한 리소스를 갖추고 있는지 확인하세요. 이는 클러스터의 YARN UI에서 Cluster Metrics 섹션에 있는 Memory Used 값과 Memory Total 값, VCores Used 값과 Memory Total 값, VCores Used 값과 VCores Total 값을 검토하여 이를 확인할 수 있습니다.

다음 Spark 구성을 적절한 값으로 설정합니다. 애플리케이션 요구 사항과 클러스터에서 사용 가능한 리소스의 균형을 맞춥니다. 이러한 값은 YARN에 표시되는 사용 가능한 메모리 및 코어의 90%를 초과할 수 없으며 Spark 애플리케이션의 최소 메모리 요구 사항도 충족해야 합니다.
spark.executor.instances (Example: 8 for 8 executor count) spark.executor.memory (Example: 4g for 4 GB) spark.yarn.executor.memoryOverhead (Example: 384m for 384 MB) spark.executor.cores (Example: 2 for 2 cores per executor) spark.driver.memory (Example: 8g for 8GB) spark.driver.cores (Example: 4 for 4 cores) spark.yarn.driver.memoryOverhead (Example: 384m for 384MB)다음 구성은 모든 실행기에서 사용하는 총 메모리 양입니다.
spark.executor.instances * (spark.executor.memory + spark.yarn.executor.memoryOverhead)다음 구성은 드라이버에서 사용하는 총 메모리 양입니다.
spark.driver.memory + spark.yarn.driver.memoryOverhead
시나리오: Apache Spark 기록 서버를 열려고 할 때의Java 힙 공간 오류
문제
Spark 기록 서버에서 이벤트를 열면 다음과 같은 오류가 표시됩니다.
scala.MatchError: java.lang.OutOfMemoryError: Java heap space (of class java.lang.OutOfMemoryError)
원인
이 문제는 큰 Spark 이벤트 파일을 열 때 리소스가 부족하여 발생하는 경우가 많습니다. Spark 힙 크기는 기본적으로 1GB로 설정되지만 큰 Spark 이벤트 파일은 이보다 큰 힙이 필요할 수도 있습니다.
로드하려는 파일의 크기를 확인하려는 경우 다음 명령을 수행할 수 있습니다.
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0274_1/
**576.5 M** wasb:///hdp/spark2-events/application_1503957839788_0274_1
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0264_1/
**2.1 G** wasb:///hdp/spark2-events/application_1503957839788_0264_1
해결
Spark 구성에서 SPARK_DAEMON_MEMORY 속성을 편집하고 모든 서비스를 다시 시작하여 Spark 기록 서버 메모리를 늘릴 수 있습니다.
Spark2/Config/Advanced spark2-env 섹션을 선택하여 Ambari 브라우저 UI 내에서 이 작업을 수행할 수 있습니다.
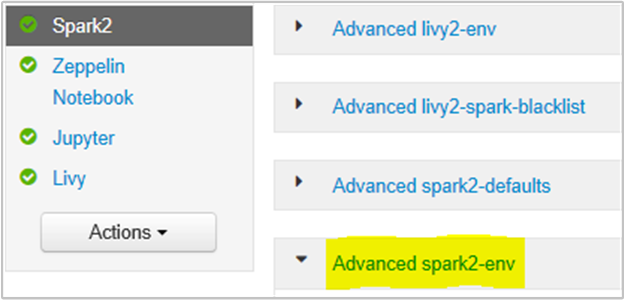
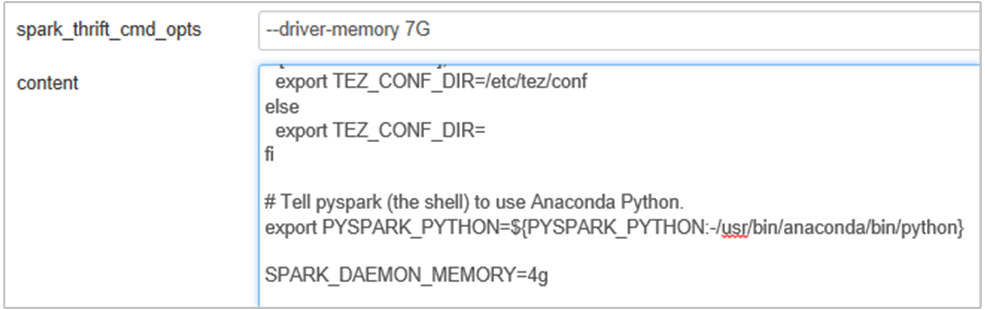
다음 속성을 추가하여 Spark 기록 서버 메모리를 1G에서 4G로 변경합니다. SPARK_DAEMON_MEMORY=4g.
Ambari에서 영향을 받는 모든 서비스를 다시 시작해야 합니다.
시나리오: Apache Spark 클러스터에서 Livy 서버를 시작하지 못함
문제
Livy 서버는 Apache Spark[Linux의 Spark 2.1(HDI 3.6)]에서 시작할 수 없습니다. 다시 시작을 시도하면 Livy 로그에서 다음 오류 스택이 생성됩니다.
17/07/27 17:52:50 INFO CuratorFrameworkImpl: Starting
17/07/27 17:52:50 INFO ZooKeeper: Client environment:zookeeper.version=3.4.6-29--1, built on 05/15/2017 17:55 GMT
17/07/27 17:52:50 INFO ZooKeeper: Client environment:host.name=10.0.0.66
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.version=1.8.0_131
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.vendor=Oracle Corporation
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.home=/usr/lib/jvm/java-8-openjdk-amd64/jre
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.class.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.library.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.io.tmpdir=/tmp
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.compiler=<NA>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.name=Linux
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.arch=amd64
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.version=4.4.0-81-generic
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.name=livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.home=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.dir=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Initiating client connection, connectString=<zookeepername1>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername2>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername3>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181 sessionTimeout=60000 watcher=org.apache.curator.ConnectionState@25fb8912
17/07/27 17:52:50 INFO StateStore$: Using ZooKeeperStateStore for recovery.
17/07/27 17:52:50 INFO ClientCnxn: Opening socket connection to server 10.0.0.61/10.0.0.61:2181. Will not attempt to authenticate using SASL (unknown error)
17/07/27 17:52:50 INFO ClientCnxn: Socket connection established to 10.0.0.61/10.0.0.61:2181, initiating session
17/07/27 17:52:50 INFO ClientCnxn: Session establishment complete on server 10.0.0.61/10.0.0.61:2181, sessionid = 0x25d666f311d00b3, negotiated timeout = 60000
17/07/27 17:52:50 INFO ConnectionStateManager: State change: CONNECTED
17/07/27 17:52:50 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/07/27 17:52:50 INFO AHSProxy: Connecting to Application History server at headnodehost/10.0.0.67:10200
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:717)
at com.cloudera.livy.Utils$.startDaemonThread(Utils.scala:98)
at com.cloudera.livy.utils.SparkYarnApp.<init>(SparkYarnApp.scala:232)
at com.cloudera.livy.utils.SparkApp$.create(SparkApp.scala:93)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:117)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:116)
at com.cloudera.livy.server.batch.BatchSession.<init>(BatchSession.scala:137)
at com.cloudera.livy.server.batch.BatchSession$.recover(BatchSession.scala:108)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:244)
at scala.collection.AbstractTraversable.map(Traversable.scala:105)
at com.cloudera.livy.sessions.SessionManager.com$cloudera$livy$sessions$SessionManager$$recover(SessionManager.scala:150)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at scala.Option.getOrElse(Option.scala:120)
at com.cloudera.livy.sessions.SessionManager.<init>(SessionManager.scala:82)
at com.cloudera.livy.sessions.BatchSessionManager.<init>(SessionManager.scala:42)
at com.cloudera.livy.server.LivyServer.start(LivyServer.scala:99)
at com.cloudera.livy.server.LivyServer$.main(LivyServer.scala:302)
at com.cloudera.livy.server.LivyServer.main(LivyServer.scala)
## using "vmstat" found we had enough free memory
원인
java.lang.OutOfMemoryError: unable to create new native thread가 OS에서 JVM에 더 많은 네이티브 스레드를 할당할 수 없는 경우를 강조 표시합니다. 프로세스별 스레드 수 제한 위반으로 인해 이 예외가 발생한 것으로 확인되었습니다.
Livy 서버가 예기치 않게 종료되면 Spark 클러스터에 대한 모든 연결이 종료됩니다. 즉, 모든 작업 및 관련 데이터가 손실됩니다. HDP 2.6 세션 복구 메커니즘이 도입됨에 따라 Livy는 Livy 서버를 다시 시작한 후에 복구될 수 있도록 세션 세부 정보를 Zookeeper에 저장합니다.
Livy를 통해 많은 수의 작업을 제출하는 경우 Livy 서버의 고가용성의 일부로 ZK(HDInsight 클러스터의)에 이러한 세션 상태를 저장하고 Livy 서비스가 다시 시작될 때 해당 세션을 복구합니다. 예기치 않게 종료된 후 다시 시작 시 Livy는 세션당 스레드를 하나씩 만들며, 이로 인해 복구될 일부 세션이 누적되어 너무 많은 스레드가 생성됩니다.
해결
다음 단계를 사용하여 모든 항목을 삭제합니다.
다음을 사용하는 Zookeeper 노드의 IP 주소를 가져옵니다.
grep -R zk /etc/hadoop/conf위 명령은 클러스터에 대한 모든 zookeeper를 나열했습니다.
/etc/hadoop/conf/core-site.xml: <value><zookeepername1>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername2>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername3>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181</value>ping을 사용하여 zookeeper 노드의 모든 IP 주소를 가져오거나, zookeeper 이름을 사용하여 헤드 노드에서 zookeeper에 연결할 수도 있습니다.
/usr/hdp/current/zookeeper-client/bin/zkCli.sh -server <zookeepername1>:2181연결되면 zookeeper에 다음 명령을 실행하여 다시 시작하려는 모든 세션을 나열합니다.
대부분의 경우 8000개 이상의 세션을 나열할 수 있습니다. ####
ls /livy/v1/batch다음 명령은 복구 가능한 모든 세션을 제거하는 명령입니다. #####
rmr /livy/v1/batch
위의 명령이 완료될 때까지 기다리거나 커서를 통해 프롬프트가 반환되면 성공해야 하는 Ambari에서 Livy service를 다시 시작합니다.
참고 항목
Livy 세션 실행이 완료되면 DELETE합니다. Livy 일괄 처리 세션은 설계상 Spark 앱이 완료되는 대로 자동으로 삭제되지 않습니다. Livy 세션은 Livy REST 서버에 대한 POST 요청에 의해 생성된 엔터티입니다. 해당 엔터티를 삭제하려면 DELETE 호출이 필요합니다. 아니면 GC가 시작될 때까지 기다려야 합니다.
다음 단계
문제가 표시되지 않거나 문제를 해결할 수 없는 경우 다음 채널 중 하나를 방문하여 추가 지원을 받으세요.
Azure 커뮤니티 지원을 통해 Azure 전문가로부터 답변을 얻습니다.
사용자 환경을 개선하기 위한 공식 Microsoft Azure 계정인 @AzureSupport와 연결합니다. Azure 커뮤니티를 적절한 리소스(답변, 지원 및 전문가)에 연결합니다.
도움이 더 필요한 경우 Azure Portal에서 지원 요청을 제출할 수 있습니다. 메뉴 모음에서 지원을 선택하거나 도움말 + 지원 허브를 엽니다. 자세한 내용은 Azure 지원 요청을 만드는 방법을 참조하세요. 구독 관리 및 청구 지원에 대한 액세스 권한은 Microsoft Azure 구독에 포함되어 있으며, Azure 지원 플랜 중 하나를 통해 기술 지원이 제공됩니다.