Azure Data Factory에서 일괄 처리 엔드포인트 실행
적용 대상: Azure CLI ml 확장 v2(현재)Python SDK azure-ai-ml v2(현재)
Azure CLI ml 확장 v2(현재)Python SDK azure-ai-ml v2(현재)
빅 데이터는 이처럼 수많은 원시 데이터 저장소를 조치 가능한 비즈니스 인사이트로 구체화하도록 프로세스를 조율하고 운영할 수 있는 서비스가 필요합니다. Azure Data Factory는 이처럼 복잡한 하이브리드 ETL(추출-변환-로드), ELT(추출-로드-변환) 및 데이터 통합 프로젝트를 위해 만들어진 관리형 클라우드 서비스입니다.
Azure Data Factory를 사용하면 여러 데이터 변환을 오케스트레이션하고 단일 단위로 관리할 수 있는 파이프라인을 만들 수 있습니다. 일괄 처리 엔드포인트는 관련 처리 워크플로의 한 단계가 될 수 있는 훌륭한 후보입니다. 이 예제에서는 웹 호출 작업 및 REST API를 사용하여 Azure Data Factory 작업에서 일괄 처리 엔드포인트를 사용하는 방법을 알아봅니다.
필수 조건
이 예제에서는 모델이 일괄 처리 엔드포인트로 올바르게 배포되었다고 가정합니다. 특히 일괄 처리 배포에서 MLflow 모델 사용 자습서에서 만든 심장 질환 분류자를 사용하고 있습니다.
생성되고 구성된 Azure Data Factory 리소스입니다. 아직 Data Factory를 만들지 않은 경우 빠른 시작: Azure Portal 및 Azure Data Factory Studio를 사용하여 Data Factory 만들기 단계에 따라 Data Factory를 만듭니다.
리소스를 만든 후 Azure Portal에서 데이터 팩터리로 이동합니다.

Azure Data Factory Studio 열기 타일에서 열기를 선택하여 별도의 탭에서 데이터 통합 애플리케이션을 시작합니다.
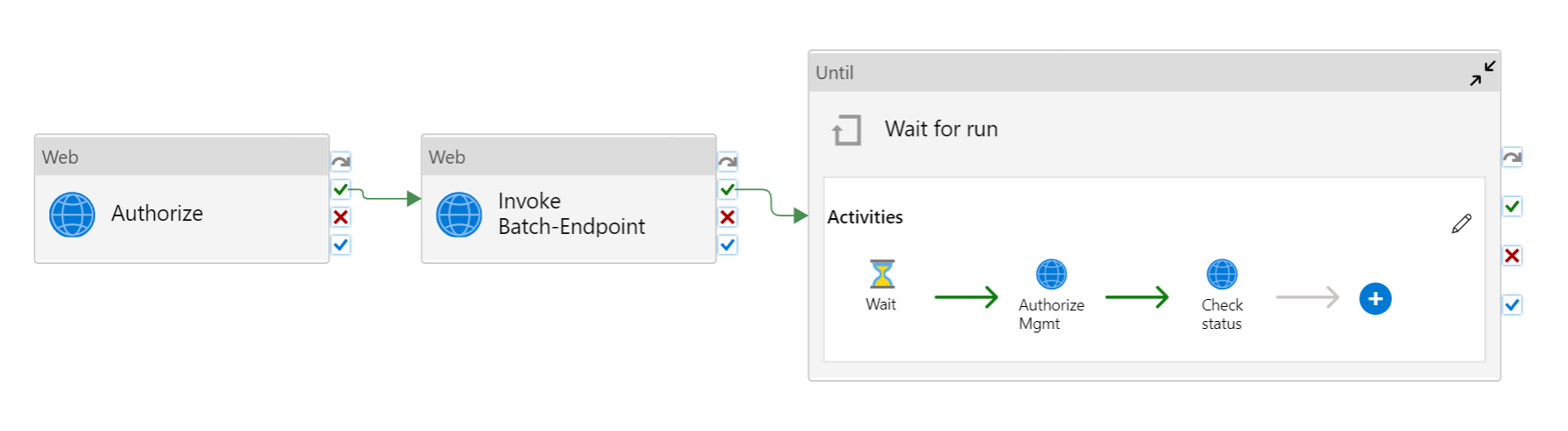
일괄 처리 엔드포인트에 대해 인증
Azure Data Factory는 웹 호출 작업을 사용하여 일괄 처리 엔드포인트의 REST API를 호출할 수 있습니다. 일괄 처리 엔드포인트는 권한 부여를 위해 Microsoft Entra ID를 지원하므로 API에 대한 요청에는 적절한 인증 처리가 필요합니다.
서비스 주체 또는 관리 ID를 사용하여 일괄 처리 엔드포인트에 대해 인증할 수 있습니다. 비밀 사용을 간소화하므로 관리 ID를 사용하는 것이 좋습니다.
Azure Data Factory 관리 ID를 사용하여 일괄 처리 엔드포인트와 통신할 수 있습니다. 이 경우 Azure Data Factory 리소스가 관리 ID를 사용하여 배포되었는지만 확인해야 합니다.
Azure Data Factory 리소스가 없거나 이미 관리 ID 없이 배포된 경우 Azure Data Factory에 대한 관리 ID 단계에 따라 리소스를 만드세요.
Warning
배포된 리소스 ID는 Azure Data Factory에서 변경할 수 없습니다. 리소스가 만들어진 후에는 해당 리소스의 ID를 변경해야 하는 경우 리소스를 다시 만들어야 합니다.
배포된 후 액세스 권한 부여에 설명된 대로 직접 만든 리소스의 관리 ID에 대한 액세스 권한을 Azure Machine Learning 작업 영역에 부여합니다. 이 예제에서 서비스 주체는 다음을 요구합니다.
- 작업 영역에서 일괄 처리 배포를 읽고 작업을 수행할 수 있는 권한
- 데이터 저장소에서 읽고 쓸 수 있는 권한
- 데이터 입력으로 표시된 클라우드 위치(스토리지 계정)에서 읽을 수 있는 권한
파이프라인 정보
일부 데이터에 대해 지정된 일괄 처리 엔드포인트를 호출할 수 있는 파이프라인을 Azure Data Factory에 만들겠습니다. 파이프라인은 REST를 사용하여 Azure Machine Learning 일괄 처리 엔드포인트와 통신합니다. 일괄 처리 엔드포인트의 REST API를 사용하는 방법에 대해 자세히 알아보려면 일괄 처리 엔드포인트에 대한 작업 만들기 및 데이터 입력을 참조하세요.
파이프라인은 다음과 같이 표시됩니다.
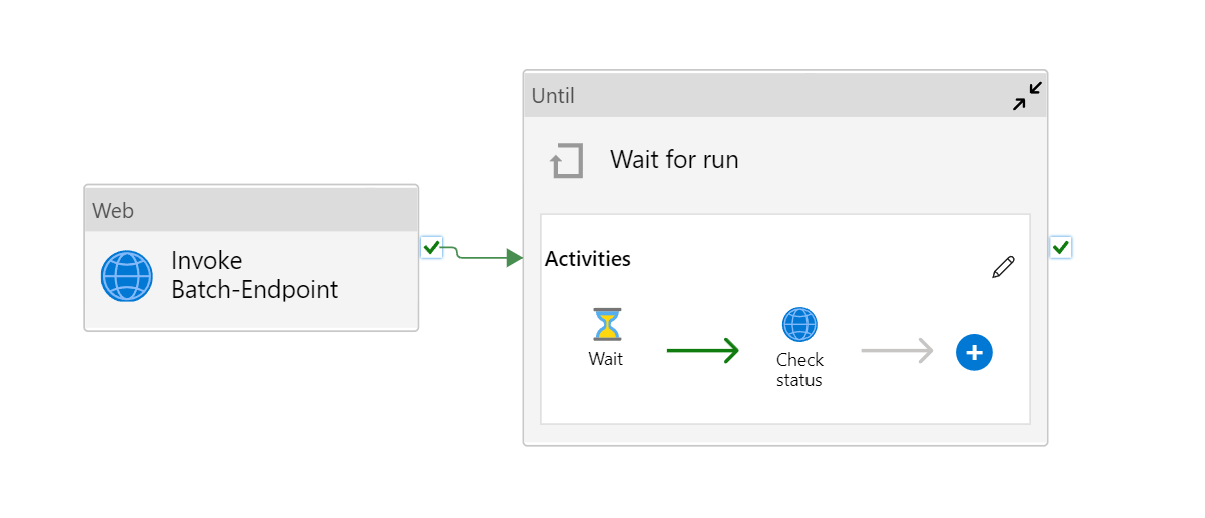
다음 작업으로 구성됩니다.
- 일괄 처리 엔드포인트 실행: 호출하는 데 일괄 처리 엔드포인트 URI를 사용하는 웹 작업입니다. 데이터가 있는 입력 데이터 URI와 예상 출력 파일을 전달합니다.
- 작업 대기: 생성된 작업의 상태를 확인하고 완료됨 또는 실패로 완료될 때까지 기다리는 루프 작업입니다. 이 작업은 차례로 다음 작업을 사용합니다.
- 상태 확인: 일괄 처리 엔드포인트 실행 작업의 응답으로 반환된 작업 리소스의 상태를 쿼리하는 웹 작업입니다.
- 대기: 작업 상태의 폴링 빈도를 제어하는 대기 작업입니다. 기본값인 120(2분)을 설정합니다.
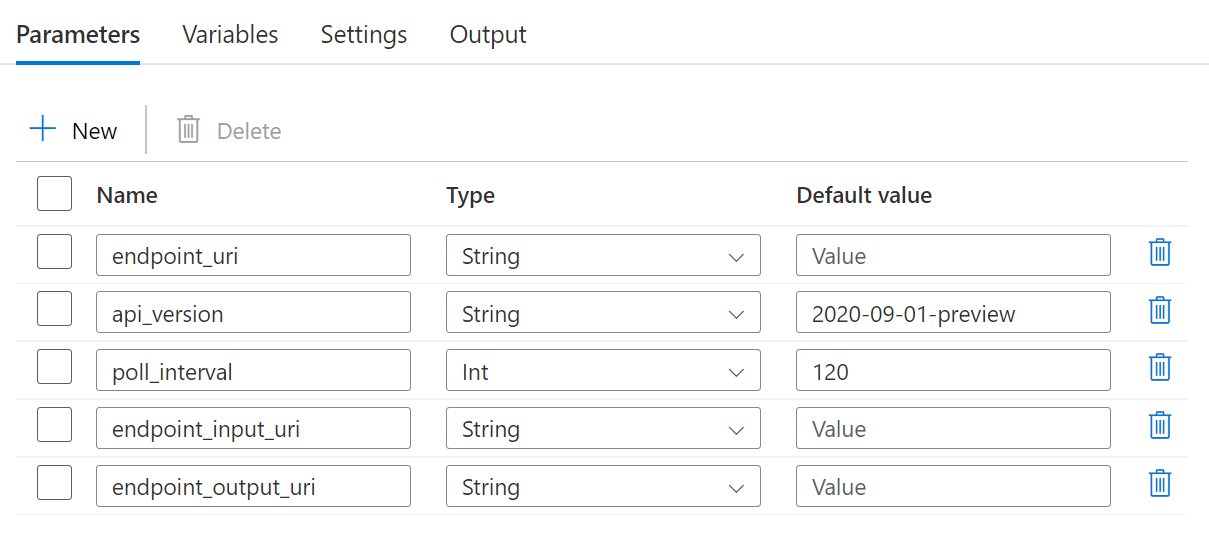
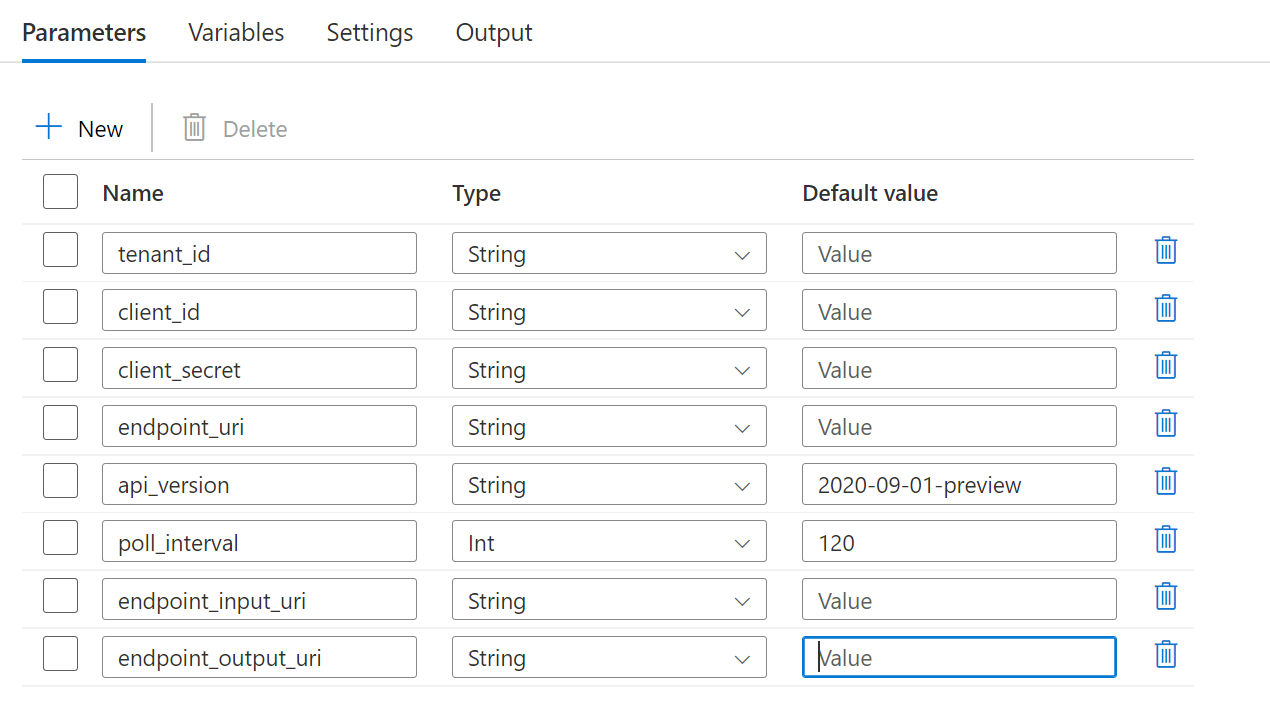
파이프라인을 사용하려면 다음 매개 변수를 구성해야 합니다.
| 매개 변수 | 설명 | 샘플 값 |
|---|---|---|
endpoint_uri |
엔드포인트 채점 URI | https://<endpoint_name>.<region>.inference.ml.azure.com/jobs |
poll_interval |
완료를 위해 작업 상태를 확인하기 전에 대기할 시간(초)입니다. 기본값은 120입니다. |
120 |
endpoint_input_uri |
엔드포인트의 입력 데이터입니다. 여러 데이터 입력 형식이 지원됩니다. 작업을 실행하는 데 사용하는 관리 ID가 기본 위치에 액세스할 수 있는지 확인합니다. 또는 데이터 저장소를 사용하는 경우 자격 증명이 표시되는지 확인합니다. | azureml://datastores/.../paths/.../data/ |
endpoint_input_type |
제공하는 입력 데이터의 형식입니다. 현재 일괄 처리 엔드포인트는 폴더(UriFolder) 및 파일(UriFile)을 지원합니다. 기본값은 UriFolder입니다. |
UriFolder |
endpoint_output_uri |
엔드포인트의 출력 데이터 파일입니다. Machine Learning 작업 영역에 연결된 데이터 저장소의 출력 파일에 대한 경로여야 합니다. 다른 유형의 URI는 지원되지 않습니다. workspaceblobstore라는 기본 Azure Machine Learning 데이터 저장소를 사용할 수 있습니다. |
azureml://datastores/workspaceblobstore/paths/batch/predictions.csv |
Warning
endpoint_output_uri는 아직 존재하지 않는 파일의 경로여야 합니다. 그렇지 않으면 경로가 이미 있음 오류와 함께 작업이 실패합니다.
단계
기존 Azure Data Factory에서 이 파이프라인을 만들고 일괄 처리 엔드포인트를 호출하려면 다음 단계를 수행합니다.
일괄 처리 엔드포인트가 실행되는 컴퓨팅에 Azure Data Factory가 입력으로 제공하는 데이터를 탑재할 수 있는 권한이 있는지 확인합니다. 엔드포인트(이 경우 Azure Data Factory)를 호출하는 ID에 의해 액세스 권한이 계속 부여됩니다. 그러나 일괄 처리 엔드포인트가 실행되는 컴퓨팅에는 Azure Data Factory가 제공하는 스토리지 계정을 탑재할 수 있는 권한이 있어야 합니다. 자세한 내용은 스토리지 서비스에 액세스를 참조하세요.
Azure Data Factory Studio를 열고 팩터리 리소스 아래에서 더하기 기호를 클릭합니다.
파이프라인>파이프라인 템플릿에서 가져오기 선택
zip파일을 선택할지 묻는 메시지가 표시됩니다. 관리 ID를 사용하는 경우 다음 템플릿을 사용하거나 서비스 주체를 사용하는 경우 다음 템플릿을 사용합니다.파이프라인의 미리 보기가 포털에 표시됩니다. 이 템플릿 사용을 클릭합니다.
이름이 Run-BatchEndpoint인 파이프라인이 만들어집니다.
사용 중인 일괄 배포의 매개 변수를 구성합니다.
Warning
일괄 처리 엔드포인트에 작업을 제출하기 전에 구성된 기본 배포가 있는지 확인합니다. 생성된 파이프라인은 엔드포인트를 호출하므로 기본 배포를 만들고 구성해야 합니다.
팁
최상의 재사용성을 위해 생성된 파이프라인을 템플릿으로 사용하고 파이프라인 실행 작업을 활용하여 다른 Azure Data Factory 파이프라인 내에서 호출합니다. 이 경우 내부 파이프라인에서 매개 변수를 구성하지 말고 다음 이미지와 같이 외부 파이프라인의 매개 변수로 전달합니다.
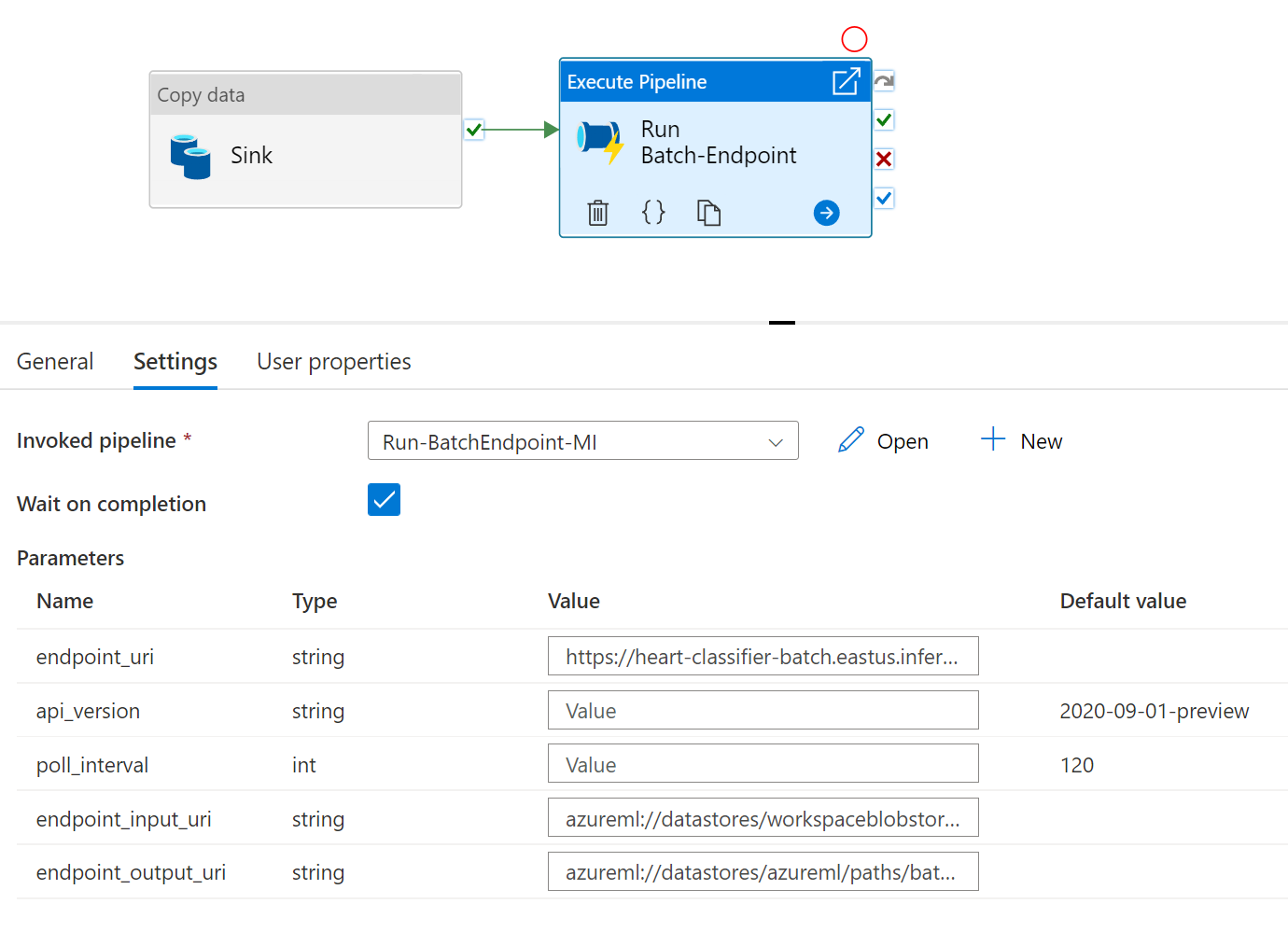
- 파이프라인을 사용할 준비가 완료되었습니다.
제한 사항
Azure Machine Learning 일괄 배포를 호출할 때는 다음과 같은 제한 사항을 고려합니다.
데이터 입력
- Azure Machine Learning 데이터 저장소 또는 Azure Storage 계정(Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2)만 입력으로 지원됩니다. 입력 데이터가 다른 원본에 있는 경우 일괄 처리 작업을 실행하기 전에 Azure Data Factory 복사 작업을 사용하여 데이터를 호환되는 저장소에 싱크합니다.
- 일괄 처리 엔드포인트 작업은 중첩 폴더를 탐색하지 않으므로 중첩 폴더 구조를 사용할 수 없습니다. 데이터가 여러 폴더에 분산된 경우 구조를 평면화해야 합니다.
- 데이터가 작업에 공급되어야 하므로 배포에 제공된 채점 스크립트가 데이터를 처리할 수 있는지 확인합니다. 모델이 MLflow인 경우 일괄 배포에서 MLflow 모델 사용에서 현재 지원되는 파일 형식 관련 제한 사항을 읽어 보세요.
데이터 출력
- 현재는 등록된 Azure Machine Learning 데이터 저장소만 지원됩니다. Azure Data Factory가 Azure Machine Learning에서 데이터 저장소로 사용하는 스토리지 계정을 등록하는 것이 좋습니다. 이렇게 하면 읽고 있는 위치부터 동일한 스토리지 계정에 다시 쓸 수 있습니다.
- 출력에는 Azure Blob Storage 계정만 지원됩니다. 예를 들어, Azure Data Lake Storage Gen2는 일괄 배포 작업의 출력으로 지원되지 않습니다. 데이터를 다른 위치/싱크로 출력해야 하는 경우 일괄 처리 작업을 실행한 후 Azure Data Factory 복사 작업을 사용합니다.