데이터 자산 만들기 및 관리
적용 대상: Azure CLI ml 확장 v2(현재)Python SDK azure-ai-ml v2(현재)
Azure CLI ml 확장 v2(현재)Python SDK azure-ai-ml v2(현재)
이 문서에서는 Azure Machine Learning에서 데이터 자산을 만들고 관리하는 방법을 보여 줍니다.
데이터 자산은 다음과 같은 기능이 필요할 때 도움이 될 수 있습니다.
- 버전 관리: 데이터 자산은 데이터 버전 관리를 지원합니다.
- 재현성: 일단 만들어진 데이터 자산 버전은 변경할 수 없습니다. 수정하거나 삭제할 수 없습니다. 따라서 데이터 자산을 소비하는 학습 작업이나 파이프라인을 재현할 수 있습니다.
- 감사 가능성: 데이터 자산 버전은 변경할 수 없으므로 자산 버전, 버전을 업데이트한 사람, 버전 업데이트가 발생한 시기를 추적할 수 있습니다.
- 계보: 특정 데이터 자산에 대해 어떤 작업이나 파이프라인이 데이터를 소비하는지 확인할 수 있습니다.
- 사용 편의성: Azure Machine Learning 데이터 자산은 웹 브라우저 책갈피(즐겨찾기)와 유사합니다. Azure Storage에서 자주 사용하는 데이터를 참조하는 긴 스토리지 경로(URI)를 기억하는 대신 데이터 자산 버전을 만든 다음 식별 이름(예:
azureml:<my_data_asset_name>:<version>)을 사용하여 해당 버전의 자산에 액세스할 수 있습니다.
팁
대화형 세션(예: Notebook) 또는 작업에서 데이터에 액세스하기 위해 먼저 데이터 자산을 만들 필요는 없습니다. 데이터 저장소 URI를 사용하여 데이터에 액세스할 수 있습니다. 데이터 저장소 URI는 Azure Machine Learning을 시작하는 사용자가 데이터에 액세스할 수 있는 간단한 방법을 제공합니다.
필수 조건
데이터 자산을 만들고 작업하려면 다음이 필요합니다.
Azure 구독 구독이 없으면 시작하기 전에 계정을 만드세요. Azure Machine Learning 평가판 또는 유료 버전을 사용해 보세요.
Azure Machine Learning 작업 영역 작업 영역 리소스 만들기
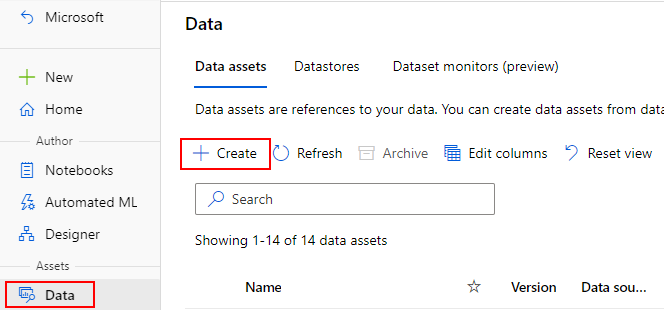
데이터 자산 만들기
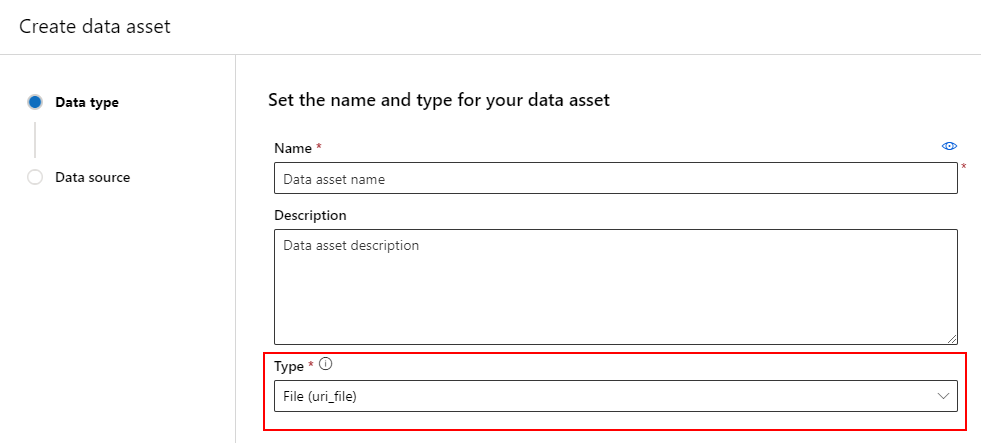
데이터 자산을 만들 때 데이터 자산 형식을 설정해야 합니다. Azure Machine Learning은 세 가지 데이터 자산 형식을 지원합니다.
| Type | API | 정식 시나리오 |
|---|---|---|
| 파일 단일 파일 참조 |
uri_file |
Azure Storage에서 단일 파일을 읽습니다(파일 형식은 무엇이든 가능). |
| 폴더 폴더 참조 |
uri_folder |
Parquet/CSV 파일 폴더를 Pandas/Spark로 읽습니다. 폴더에 있는 구조화되지 않은 데이터(이미지, 텍스트, 오디오 등)를 읽습니다. |
| 테이블 데이터 테이블 참조 |
mltable |
자주 변경되는 복잡한 스키마가 있거나 큰 표 형식 데이터의 하위 집합이 필요합니다. 테이블을 사용한 AutoML 여러 스토리지 위치에 분산되어 있는 구조화되지 않은 데이터(이미지, 텍스트, 오디오 등)를 읽습니다. |
참고 항목
데이터를 MLTable로 등록하지 않는 한 csv 파일에 포함된 줄 바꿈을 사용하지 마세요. csv 파일에 포함된 줄 바꿈으로 인해 데이터를 읽을 때 필드 값이 잘못 정렬될 수 있습니다. MLTable에는 인용된 줄 바꿈을 하나의 레코드로 해석하기 위해 read_delimited 변환에 이 매개 변수 support_multi_line이 있습니다.
Azure Machine Learning 작업에서 데이터 자산을 사용할 때 자산을 컴퓨팅 노드에 탑재하거나 다운로드할 수 있습니다. 자세한 내용은 모드를 참조하세요.
또한 데이터 자산 위치를 가리키는 path 매개 변수를 지정해야 합니다. 지원되는 경로는 다음과 같습니다.
| 위치 | 예제 |
|---|---|
| 로컬 컴퓨터의 경로 | ./home/username/data/my_data |
| 데이터 저장소의 경로 | azureml://datastores/<data_store_name>/paths/<path> |
| 퍼블릭 http(s) 서버의 경로 | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Azure Storage의 경로 | (Blob) wasbs://<containername>@<accountname>.blob.core.windows.net/<path_to_data>/(ADLS gen2) abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> (ADLS gen1) adl://<accountname>.azuredatalakestore.net/<path_to_data>/ |
참고 항목
로컬 경로에서 데이터 자산을 만들면 기본 Azure Machine Learning 클라우드 데이터 저장소에 자동으로 업로드됩니다.
데이터 자산 만들기: 파일 형식
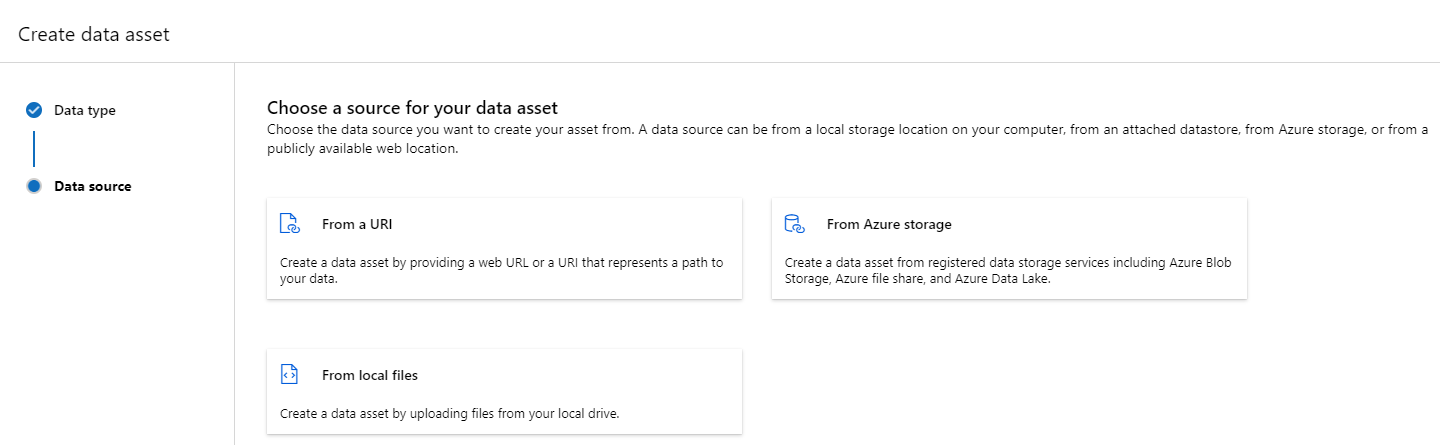
파일(uri_file) 형식인 데이터 자산은 스토리지의 단일 파일(예: CSV 파일)을 가리킵니다. 다음을 사용하여 파일 형식의 데이터 자산을 만들 수 있습니다.
YAML 파일을 만들고 다음 코드를 복사하여 붙여넣습니다. 데이터 자산의 이름, 버전, 설명 및 지원되는 위치에 있는 단일 파일의 경로로 <> 자리 표시자를 업데이트해야 합니다.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
그런 다음 CLI에서 다음 명령을 실행합니다(<filename> 자리 표시자를 YAML 파일 이름으로 업데이트).
az ml data create -f <filename>.yml
데이터 자산 만들기: 폴더 형식
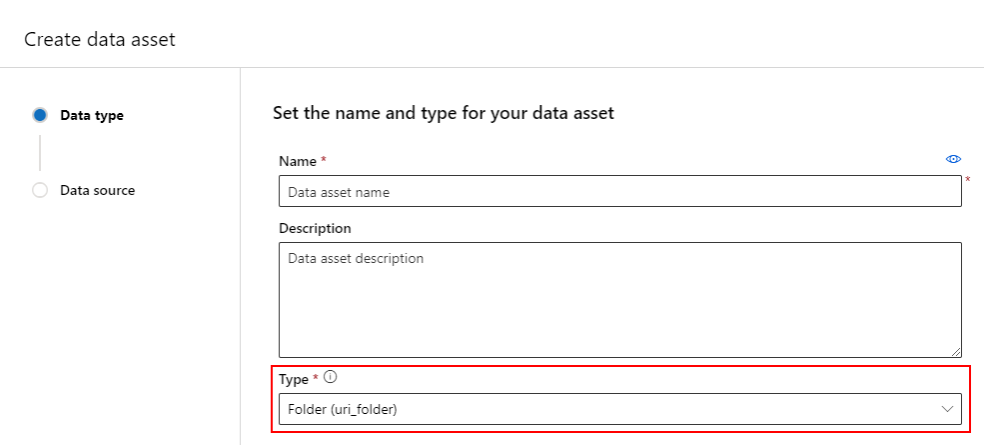
폴더(uri_folder) 형식의 데이터 자산은 스토리지의 폴더(예: 이미지의 여러 하위 폴더가 포함된 폴더)를 가리키는 자산입니다. 다음을 사용하여 폴더 형식의 데이터 자산을 만들 수 있습니다.
YAML 파일을 만들고 다음 코드를 복사하여 붙여넣습니다. 데이터 자산의 이름, 버전, 설명 및 지원되는 위치의 폴더 경로로 <> 자리 표시자를 업데이트해야 합니다.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<folder>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<folder>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<folder>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<folder>'
type: uri_folder
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
그런 다음 CLI에서 다음 명령을 실행합니다(파일 이름에 대한 <filename> 자리 표시자를 YAML 파일 이름으로 업데이트).
az ml data create -f <filename>.yml
데이터 자산 만들기: 테이블 형식
Azure Machine Learning 테이블(MLTable)에는 풍부한 기능이 있으며, 자세한 내용은 Azure Machine Learning에서 테이블 작업을 참조하세요. 여기서 해당 설명서를 반복하는 대신 공개적으로 사용 가능한 Azure Blob Storage 계정에 있는 Titanic 데이터를 사용하여 테이블 형식 데이터 자산을 만드는 예를 제공합니다.
먼저 data라는 새 디렉터리를 만들고 MLTable이라는 파일을 만듭니다.
mkdir data
touch MLTable
그런 후 다음 YAML을 복사하여 이전 단계에서 만든 MLTable 파일에 붙여넣습니다.
주의
MLTable 파일 이름을 MLTable.yaml 또는 MLTable.yml로 바꾸지 마세요. Azure Machine Learning에는 MLTable 파일이 필요합니다.
paths:
- file: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
transformations:
- read_delimited:
delimiter: ','
empty_as_string: false
encoding: utf8
header: all_files_same_headers
include_path_column: false
infer_column_types: true
partition_size: 20971520
path_column: Path
support_multi_line: false
- filter: col('Age') > 0
- drop_columns:
- PassengerId
- convert_column_types:
- column_type:
boolean:
false_values:
- 'False'
- 'false'
- '0'
mismatch_as: error
true_values:
- 'True'
- 'true'
- '1'
columns: Survived
type: mltable
그런 다음 CLI에서 다음 명령을 실행합니다. 데이터 자산 이름 및 버전 값으로 <> 자리 표시자를 업데이트해야 합니다.
az ml data create --path ./data --name <DATA ASSET NAME> --version <VERSION> --type mltable
Important
path는 유효한 MLTable 파일이 포함된 폴더여야 합니다.
작업 출력에서 데이터 자산 만들기
출력에서 name 매개 변수를 설정하여 Azure Machine Learning 작업에서 데이터 자산을 만들 수 있습니다. 이 예에서는 공용 Blob 저장소의 데이터를 기본 Azure Machine Learning 데이터 저장소에 복사하는 작업을 제출하고 job_output_titanic_asset라는 데이터 자산을 만듭니다.
작업 사양 YAML 파일(<file-name>.yml)을 만듭니다.
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
# path: Set the URI path for the data. Supported paths include
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# type: What type of data are you pointing to?
# uri_file (a specific file)
# uri_folder (a folder)
# mltable (a table)
# mode: Set INPUT mode:
# ro_mount (read-only mount)
# download (download from storage to node)
# mode: Set the OUTPUT mode
# rw_mount (read-write mount)
# upload (upload data from node to storage)
type: command
command: cp ${{inputs.input_data}} ${{outputs.output_data}}
compute: azureml:cpu-cluster
environment: azureml://registries/azureml/environments/sklearn-1.1/versions/4
inputs:
input_data:
mode: ro_mount
path: azureml:wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
type: uri_file
outputs:
output_data:
mode: rw_mount
path: azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv
type: uri_file
name: job_output_titanic_asset
다음으로 CLI를 사용하여 작업을 제출합니다.
az ml job create --file <file-name>.yml
데이터 자산 관리
데이터 자산 삭제
Important
기본적으로 데이터 자산 삭제는 지원되지 않습니다.
Azure Machine Learning에서 데이터 자산 삭제를 허용하는 경우 다음과 같은 부작용이 발생합니다.
- 나중에 삭제된 데이터 자산을 사용하는 프로덕션 작업은 실패합니다.
- ML 실험을 재현하는 것이 더 어려워집니다.
- 삭제된 데이터 자산 버전을 볼 수 없게 되므로 작업 계보가 중단됩니다.
- 버전이 누락될 수 있으므로 올바르게 추적 및 감사할 수 없습니다.
따라서 데이터 자산의 불변성은 프로덕션 워크로드를 만드는 팀에서 작업할 때 일정 수준의 보호를 제공합니다.
데이터 자산이 잘못 만들어진 경우(예: 잘못된 이름, 형식 또는 경로 사용) Azure Machine Learning은 삭제로 인한 부정적인 결과 없이 상황을 처리할 수 있는 솔루션을 제공합니다.
| 이 데이터 자산을 삭제하고 싶은 이유는... | 솔루션 |
|---|---|
| 이름이 잘못되었습니다. | 데이터 자산 보관 |
| 팀은 데이터 자산을 더 이상 사용하지 않습니다. | 데이터 자산 보관 |
| 데이터 자산 목록이 복잡해집니다. | 데이터 자산 보관 |
| 경로가 잘못되었습니다. | 올바른 경로를 사용하여 데이터 자산(동일한 이름)의 새 버전을 만듭니다. 자세한 내용은 데이터 자산 만들기를 참조하세요. |
| 잘못된 형식이 있습니다. | 현재 Azure Machine Learning에서는 초기 버전과 다른 형식의 새 버전 만들기를 허용하지 않습니다. (1) 데이터 자산 보관 (2) 올바른 형식의 다른 이름으로 새 데이터 자산을 만듭니다. |
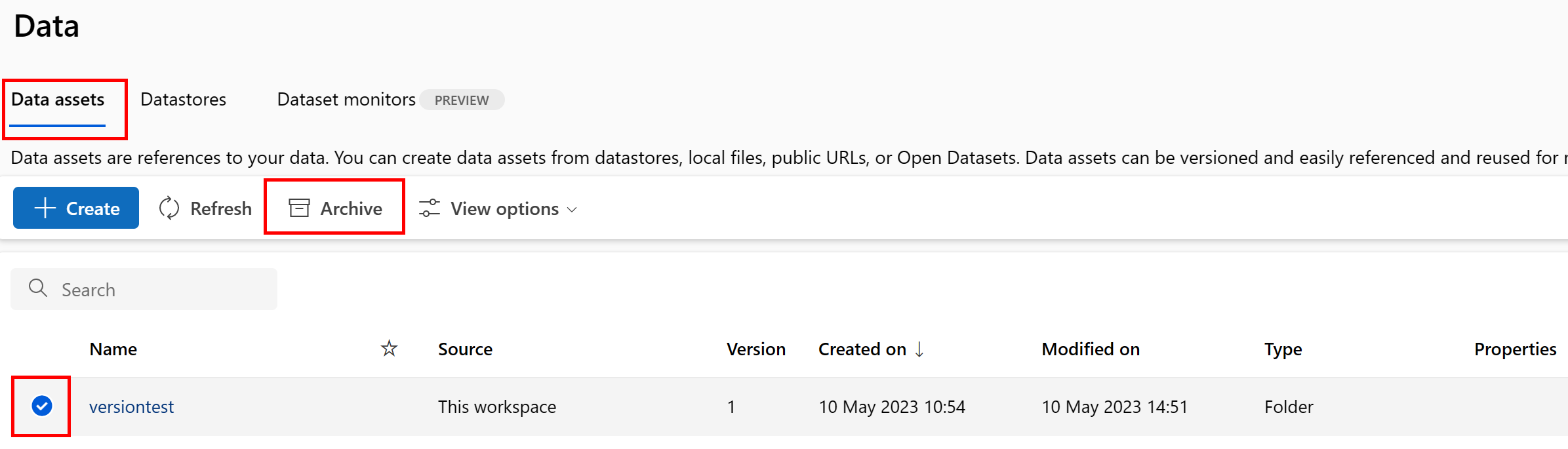
데이터 자산 보관
데이터 자산을 보관하면 기본적으로 목록 쿼리(예: CLI az ml data list)와 스튜디오 UI의 데이터 자산 목록 모두에서 숨겨집니다. 워크플로에서 보관된 데이터 자산을 계속 참조하고 사용할 수 있습니다. 다음 중 하나를 보관할 수 있습니다.
- 특정 이름의 데이터 자산의 모든 버전 또는
- 특정 데이터 자산 버전
데이터 자산의 모든 버전 보관
특정 이름으로 데이터 자산의 모든 버전을 보관하려면 다음을 사용합니다.
다음 명령을 실행합니다(데이터 자산 이름으로 <> 자리 표시자 업데이트).
az ml data archive --name <NAME OF DATA ASSET>
특정 데이터 자산 버전 보관
특정 데이터 자산 버전을 보관하려면 다음을 사용합니다.
다음 명령을 실행합니다(데이터 자산 이름 및 버전으로 <> 자리 표시자 업데이트).
az ml data archive --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
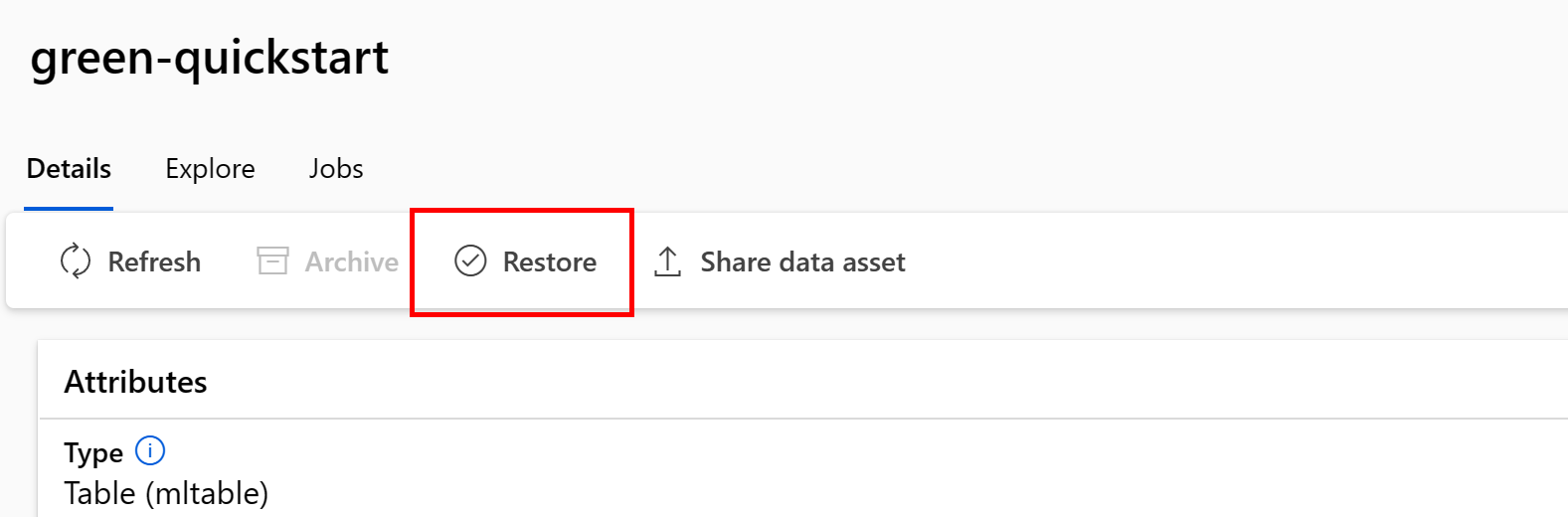
보관된 데이터 자산 복원
보관된 데이터 자산을 복원할 수 있습니다. 데이터 자산의 모든 버전이 보관된 경우 데이터 자산의 개별 버전을 복원할 수 없습니다. 모든 버전을 복원해야 합니다.
데이터 자산의 모든 버전 복원
특정 이름으로 데이터 자산의 모든 버전을 복원하려면 다음을 사용합니다.
다음 명령을 실행합니다(데이터 자산 이름으로 <> 자리 표시자 업데이트).
az ml data restore --name <NAME OF DATA ASSET>

특정 데이터 자산 버전 복원
Important
모든 데이터 자산 버전이 보관된 경우 데이터 자산의 개별 버전을 복원할 수 없습니다. 모든 버전을 복원해야 합니다.
특정 데이터 자산 버전을 복원하려면 다음을 사용합니다.
다음 명령을 실행합니다(데이터 자산 이름 및 버전으로 <> 자리 표시자 업데이트).
az ml data restore --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
데이터 계보
데이터 계보는 데이터 원본에 걸쳐 있고 시간이 지남에 따라 스토리지 전체에서 이동하는 수명 주기로 광범위하게 이해됩니다. 문제 해결, ML 파이프라인의 근본 원인 추적, 디버깅 등 다양한 종류의 과거 지향적 시나리오에서 이를 사용합니다. 데이터 품질 분석, 규정 준수 및 "가상" 시나리오에서도 계보를 사용합니다. 계보는 원본에서 대상으로 이동하는 데이터를 시각적으로 표시하고 추가로 데이터 변환을 포함합니다. 대부분의 기업 데이터 환경이 복잡하기 때문에 주변 데이터 포인트를 통합하거나 마스킹하지 않으면 이러한 보기를 이해하기 어려울 수 있습니다.
Azure Machine Learning 파이프라인에서 데이터 자산은 데이터의 원본과 데이터 처리 방법을 보여 줍니다. 예를 들면 다음과 같습니다.
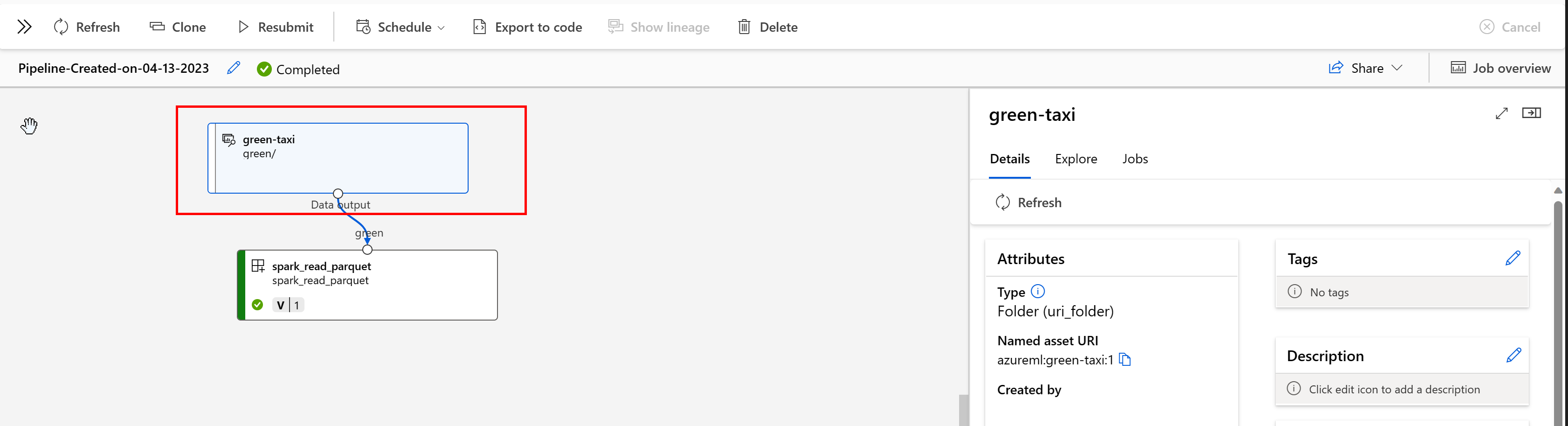
스튜디오 UI에서 데이터 자산을 사용하는 작업을 볼 수 있습니다. 먼저 왼쪽 메뉴에서 데이터를 선택한 다음 데이터 자산 이름을 선택합니다. 데이터 자산을 사용하는 작업을 확인할 수 있습니다.
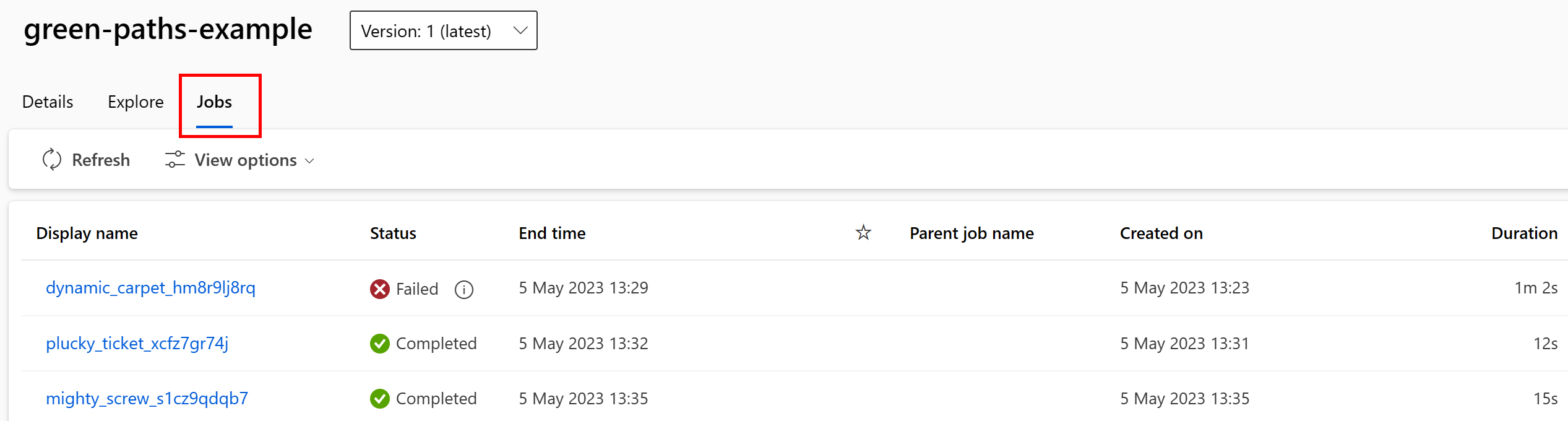
데이터 자산의 작업 보기를 사용하면 작업 실패를 더 쉽게 찾고 ML 파이프라인 및 디버깅에서 경로 원인 분석을 수행할 수 있습니다.
데이터 자산 태그 지정
데이터 자산은 키-값 쌍의 형태로 데이터 자산에 적용되는 추가 메타데이터인 태그 지정을 지원합니다. 데이터 태그 지정은 다음과 같은 많은 이점을 제공합니다.
- 데이터 품질 설명. 예를 들어, 조직에서 medallion 레이크하우스 아키텍처를 사용하는 경우
medallion:bronze(원시),medallion:silver(유효성 검사됨) 및medallion:gold(보강)를 사용하여 자산에 태그를 지정할 수 있습니다. - 효율적인 데이터 검색 및 필터링을 제공하여 데이터 검색을 돕습니다.
- 중요한 개인 데이터를 식별하고 데이터 액세스를 적절하게 관리 및 통제하는 데 도움이 됩니다. 예:
sensitivity:PII/sensitivity:nonPII. - RAI(책임 있는 AI) 감사를 통해 데이터가 승인되었는지 확인합니다. 예:
RAI_audit:approved/RAI_audit:todo.
만들기 흐름의 일부로 데이터 자산에 태그를 추가하거나 기존 데이터 자산에 태그를 추가할 수 있습니다. 이 섹션에서는 두 가지를 모두 보여 줍니다.
데이터 자산 만들기 흐름의 일부로 태그 추가
YAML 파일을 만들고 다음 코드를 복사하여 붙여넣습니다. 데이터 자산 이름, 버전, 설명, 태그(키-값 쌍) 및 지원되는 위치의 단일 파일 경로로 <> 자리 표시자를 업데이트해야 합니다.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
# Data asset types, use one of:
# uri_file, uri_folder, mltable
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
tags:
<KEY1>: <VALUE>
<KEY2>: <VALUE>
path: <SUPPORTED PATH>
그런 다음 CLI에서 다음 명령을 실행합니다(<filename> 자리 표시자를 YAML 파일 이름으로 업데이트).
az ml data create -f <filename>.yml
기존 데이터 자산에 태그 추가
Azure CLI에서 다음 명령을 실행하고 태그의 데이터 자산 이름, 버전 및 키-값 쌍으로 <> 자리 표시자를 업데이트합니다.
az ml data update --name <DATA ASSET NAME> --version <VERSION> --set tags.<KEY>=<VALUE>

버전 관리 모범 사례
일반적으로 ETL 프로세스는 Azure Storage의 폴더 구조를 시간별로 구성합니다. 예를 들면 다음과 같습니다.
/
└── 📁 mydata
├── 📁 year=2022
│ ├── 📁 month=11
│ │ └── 📄 file1
│ │ └── 📄 file2
│ └── 📁 month=12
│ └── 📄 file1
│ │ └── 📄 file2
└── 📁 year=2023
└── 📁 month=1
└── 📄 file1
│ │ └── 📄 file2
시간/버전 구문의 폴더 및 Azure Machine Learning 테이블(MLTable)을 조합하면 버전이 지정된 데이터 세트를 구성할 수 있습니다. Azure Machine Learning Tables를 사용하여 버전이 지정된 데이터를 얻는 방법을 보여 주기 위해 가상의 예를 사용합니다. 다음과 같은 구조로 카메라 이미지를 매주 Azure Blob Storage에 업로드하는 프로세스가 있다고 가정합니다.
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
참고 항목
이미지(jpeg) 데이터 버전을 지정하는 방법을 시연하는 동안 모든 파일 형식(예: Parquet, CSV)에 동일한 방법을 적용할 수 있습니다.
Azure Machine Learning 테이블(mltable)을 사용하여 2023년 첫 번째 주가 끝날 때까지의 데이터를 포함하는 경로 테이블을 구성한 후 데이터 자산을 만듭니다.
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
]
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-08.",
name="myimages",
version="20230108",
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
다음 주가 끝날 때 ETL은 더 많은 데이터를 포함하도록 데이터를 업데이트했습니다.
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
├── 📁 week2
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
첫 번째 버전(20230108)은 경로가 MLTable 파일에 선언되어 있기 때문에 계속해서 year=2022/week=52 및 year=2023/week=1에서만 파일을 탑재/다운로드합니다. 이렇게 하면 실험의 재현성이 보장됩니다. year=2023/week2를 포함하는 데이터 자산의 새 버전을 만들려면 다음을 사용합니다.
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=2/**/*.jpeg"
},
]
# Save to an MLTable file on local storage
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Next, you create a data asset - the MLTable file will automatically be uploaded
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-15.",
name="myimages",
version="20230115", # update version to the date
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
이제 두 가지 버전의 데이터가 있습니다. 버전 이름은 이미지가 스토리지에 업로드된 날짜에 해당합니다.
- 20230108: 2023년 1월 8일까지의 이미지입니다.
- 20230115: 2023년 1월 15일까지의 이미지입니다.
두 경우 모두 MLTable은 해당 날짜까지의 이미지만 포함하는 경로 테이블을 구성합니다.
Azure Machine Learning 작업에서는 eval_download 또는 eval_mount 모드를 사용하여 버전이 지정된 MLTable의 해당 경로를 컴퓨팅 대상에 탑재하거나 다운로드할 수 있습니다.
from azure.ai.ml import MLClient, command, Input
from azure.ai.ml.entities import Environment
from azure.identity import DefaultAzureCredential
from azure.ai.ml.constants import InputOutputModes
# connect to the AzureML workspace
ml_client = MLClient.from_config(
DefaultAzureCredential()
)
# Get the 20230115 version of the data
data_asset = ml_client.data.get(name="myimages", version="20230115")
input = {
"images": Input(type="mltable",
path=data_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
cmd = """
ls ${{inputs.images}}/**
"""
job = command(
command=cmd,
inputs=input,
compute="cpu-cluster",
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4"
)
ml_client.jobs.create_or_update(job)
참고 항목
eval_mount 및 eval_download 모드는 MLTable에 고유합니다. 이 경우 AzureML 데이터 런타임 기능은 MLTable 파일을 평가하고 컴퓨팅 대상에 경로를 탑재합니다.