자습서: Azure Machine Learning에서 모델 학습
적용 대상:  Python SDK azure-ai-ml v2(현재)
Python SDK azure-ai-ml v2(현재)
데이터 과학자가 Azure Machine Learning을 사용하여 모델을 학습하는 방법을 알아봅니다. 이 예에서는 연결된 신용 카드 데이터 세트를 사용하여 분류 문제에 Azure Machine Learning을 사용할 수 있는 방법을 보여 줍니다. 목표는 고객이 신용 카드 결제를 불이행할 가능성이 높은지 예측하는 것입니다.
학습 스크립트는 데이터 준비를 처리한 다음, 모델을 학습시키고 등록합니다. 이 자습서에서는 클라우드 기반 학습 작업(명령 작업)을 제출하는 단계를 안내합니다. Azure에 데이터를 로드하는 방법에 대해 자세히 알아보려면 자습서: Azure Machine Learning에서 데이터 업로드, 액세스 및 탐색을 참조하세요. 수행하는 단계는 다음과 같습니다.
- Azure Machine Learning 작업 영역에 대한 핸들 가져오기
- 컴퓨팅 리소스 및 작업 환경 만들기
- 학습 스크립트 만들기
- 적절한 작업 환경과 데이터 원본으로 구성된 컴퓨팅 리소스에서 학습 스크립트를 실행하는 명령 작업을 만들고 실행합니다.
- 학습 스크립트의 출력 보기
- 새로 학습된 모델을 엔드포인트로 배포
- 유추를 위해 Azure Machine Learning 엔드포인트 호출
이 동영상에서는 자습서의 단계를 따를 수 있도록 Azure Machine Learning 스튜디오를 시작하는 방법을 보여 줍니다. 동영상에서는 Notebook을 만들고, 컴퓨팅 인스턴스를 만들고, Notebook을 복제하는 방법을 보여 줍니다. 해당 단계는 다음 섹션에서도 설명됩니다.
필수 조건
-
Azure Machine Learning을 사용하려면 먼저 작업 영역이 필요합니다. 작업 영역이 없으면 시작하는 데 필요한 리소스 만들기를 완료하여 작업 영역을 만들고 사용 방법에 대해 자세히 알아봅니다.
-
스튜디오에 로그인하고 아직 열려 있지 않은 경우 작업 영역을 선택합니다.
-
작업 영역에서 Notebook을 열거나 만듭니다.
커널 설정
아직 컴퓨팅 인스턴스가 없는 경우 열린 Notebook 위 상단 표시줄에서 컴퓨팅 인스턴스를 만듭니다.

컴퓨팅 인스턴스가 중지된 경우 컴퓨팅 시작을 선택하고 실행될 때까지 기다립니다.

오른쪽 위에 있는 커널이
Python 3.10 - SDK v2인지 확인합니다. 그렇지 않은 경우 드롭다운을 사용하여 이 커널을 선택합니다.
인증이 필요하다는 배너가 표시되면 인증을 선택합니다.



Important
이 자습서의 나머지 부분에는 자습서 Notebook의 셀이 포함되어 있습니다. 새 Notebook을 복사/붙여넣거나, 복제한 경우 지금 Notebook으로 전환합니다.
명령 작업을 사용하여 Azure Machine Learning에서 모델 학습
모델을 학습하려면 작업을 제출해야 합니다. 이 자습서에서 제출할 작업 형식은 명령 작업입니다. Azure Machine Learning은 모델 학습을 위한 여러 가지 형식의 작업을 제공합니다. 사용자는 모델의 복잡성, 데이터 크기 및 학습 속도 요구 사항을 기반으로 학습 방법을 선택할 수 있습니다. 이 자습서에서는 명령 작업을 제출하여 학습 스크립트를 실행하는 방법을 알아봅니다.
명령 작업은 모델을 학습하기 위해 사용자 지정 학습 스크립트를 제출할 수 있는 기능입니다. 이는 사용자 지정 학습 작업으로 정의될 수도 있습니다. Azure Machine Learning의 명령 작업은 지정된 환경에서 스크립트 또는 명령을 실행하는 작업 형식입니다. 명령 작업을 사용하여 모델 학습, 데이터 처리 또는 클라우드에서 실행하려는 기타 사용자 지정 코드를 사용할 수 있습니다.
이 자습서에서는 명령 작업을 사용하여 모델 학습에 사용할 사용자 지정 학습 작업을 만드는 방법을 중점적으로 다룹니다. 사용자 지정 학습 작업의 경우 아래 항목이 필요합니다.
- environment
- 데이터
- 명령 작업
- 학습 스크립트
이 자습서에서는 신용 카드 결제를 불이행할 가능성이 높은 고객을 예측하기 위한 분류자를 만드는 예에 대한 모든 항목을 제공합니다.
작업 영역에 대한 핸들 만들기
코드를 살펴보기 전에 작업 영역을 참조할 수 있는 방법이 필요합니다. 작업 영역 핸들에 대해 ml_client를 만듭니다. 그런 다음 ml_client를 사용하여 리소스와 작업을 관리하게 됩니다.
다음 셀에 구독 ID, 리소스 그룹 이름 및 작업 영역 이름을 입력합니다. 이러한 값을 찾으려면 다음을 수행합니다.
- 오른쪽 위 Azure Machine Learning 스튜디오 도구 모음에서 작업 영역 이름을 선택합니다.
- 작업 영역, 리소스 그룹 및 구독 ID의 값을 코드에 복사합니다.
- 하나의 값을 복사하고 해당 영역을 닫고 붙여넣은 후 다음 값으로 돌아와야 합니다.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION="<SUBSCRIPTION_ID>"
RESOURCE_GROUP="<RESOURCE_GROUP>"
WS_NAME="<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
참고 항목
MLClient를 만들면 작업 영역에 연결되지 않습니다. 클라이언트 초기화는 지연되어 처음 호출이 필요할 때까지 기다립니다(이는 다음 코드 셀에서 발생합니다).
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location,":", ws.resource_group)
작업 환경 만들기
컴퓨팅 리소스에서 Azure Machine Learning 작업을 실행하려면 환경이 필요합니다. 환경에는 학습할 컴퓨팅에 설치하려는 소프트웨어 런타임 및 라이브러리가 나열됩니다. 로컬 컴퓨터의 Python 환경과 비슷합니다.
Azure Machine Learning은 일반적인 교육 및 유추 시나리오에 유용한 많은 큐레이팅된 환경 또는 바로 사용 가능한 환경을 제공합니다.
이 예제에서는 conda yaml 파일을 사용하여 작업에 대한 사용자 지정 conda 환경을 만듭니다.
먼저 파일을 저장할 디렉터리를 만듭니다.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
아래 셀은 IPython 매직을 사용하여 방금 만든 디렉터리에 conda 파일을 씁니다.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.8
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=1.0.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- mlflow==2.8.0
- mlflow-skinny==2.8.0
- azureml-mlflow==1.51.0
- psutil>=5.8,<5.9
- tqdm>=4.59,<4.60
- ipykernel~=6.0
- matplotlib
사양에는 작업(numpy, pip)에 사용할 몇 가지 일반적인 패키지가 포함됩니다.
이 yaml 파일을 참조하여 작업 영역에서 이 사용자 지정 환경을 만들고 등록합니다.
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
custom_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults job",
tags={"scikit-learn": "1.0.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
custom_job_env = ml_client.environments.create_or_update(custom_job_env)
print(
f"Environment with name {custom_job_env.name} is registered to workspace, the environment version is {custom_job_env.version}"
)
명령 함수를 사용하여 학습 작업 구성
Azure Machine Learning 명령 작업을 만들어 크레딧 기본 예측을 위한 모델을 학습시킵니다. 명령 작업은 지정된 컴퓨팅 리소스의 지정된 환경에서 학습 스크립트를 실행합니다. 환경과 컴퓨팅 클러스터는 이미 만들어졌습니다. 다음으로 학습 스크립트를 만듭니다. 특정한 경우에는 GradientBoostingClassifier 모델을 사용하여 분류자를 생성하도록 데이터 세트를 학습하고 있습니다.
학습 스크립트는 학습된 모델의 데이터 준비, 학습 및 등록을 처리합니다. train_test_split 메서드는 데이터 세트를 테스트 데이터와 학습 데이터로 분할하는 작업을 처리합니다. 이 자습서에서는 Python 학습 스크립트를 만듭니다.
명령 작업은 CLI, Python SDK 또는 스튜디오 인터페이스에서 실행할 수 있습니다. 이 자습서에서는 Azure Machine Learning Python SDK v2를 사용하여 명령 작업을 만들고 실행합니다.
학습 스크립트 만들기
먼저 학습 스크립트인 main.py python 파일을 만들어 보겠습니다.
우선 스크립트의 원본 폴더를 만듭니다.
import os
train_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
이 스크립트는 데이터의 전처리를 처리하여 테스트 및 학습 데이터로 분할합니다. 그런 다음, 이 데이터를 사용하여 트리 기반 모델을 학습시키고 출력 모델을 반환합니다.
MLFlow는 작업 중에 매개 변수와 메트릭을 기록하는 데 사용됩니다. MLFlow 패키지를 사용하면 각 모델 Azure 학습에 대한 메트릭과 결과를 추적할 수 있습니다. 먼저 MLFlow를 사용하여 데이터에 가장 적합한 모델을 가져오는 다음 Azure 스튜디오에서 모델의 메트릭을 확인합니다.
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
###################
#<prepare the data>
###################
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
#Split train and test datasets
train_df, test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
####################
#</prepare the data>
####################
##################
#<train the model>
##################
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
###################
#</train the model>
###################
##########################
#<save and register model>
##########################
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.registered_model_name, "trained_model"),
)
###########################
#</save and register model>
###########################
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
이 스크립트에서는 모델이 학습되면 모델 파일이 저장되고 작업 영역에 등록됩니다. 모델을 등록하면 작업 영역의 Azure 클라우드에 모델을 저장하고 버전을 지정할 수 있습니다. 모델을 등록하면 모델 레지스트리라는 Azure Studio의 한 위치에서 등록된 다른 모든 모델을 찾을 수 있습니다. 모델 레지스트리에서는 학습된 모델을 구성하고 추적할 수 있습니다.
명령 구성
이제 분류 작업을 수행할 수 있는 스크립트가 있으므로 명령줄 작업을 실행할 수 있는 범용 명령를 사용합니다. 이 명령줄 작업은 시스템 명령을 직접 호출하거나 스크립트를 실행할 수 있습니다.
여기서는 입력 데이터, 분할 비율, 학습 속도 및 등록된 모델 이름을 지정하기 위한 입력 변수를 만듭니다. 명령 스크립트는 다음을 수행합니다.
- 이전에 만든 환경 사용 -
@latest표기법을 사용하여 명령이 실행될 때 환경의 최신 버전을 나타낼 수 있습니다. - 명령줄 작업 자체를 구성합니다. 이 경우에는
python main.py입니다. 입력/출력은${{ ... }}표기법을 통해 명령에서 액세스할 수 있습니다. - 컴퓨팅 리소스가 지정되지 않았으므로 자동으로 만들어진 서버리스 컴퓨팅 클러스터에서 스크립트가 실행됩니다.
from azure.ai.ml import command
from azure.ai.ml import Input
registered_model_name = "credit_defaults_model"
job = command(
inputs=dict(
data=Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",
),
test_train_ratio=0.2,
learning_rate=0.25,
registered_model_name=registered_model_name,
),
code="./src/", # location of source code
command="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",
environment="aml-scikit-learn@latest",
display_name="credit_default_prediction",
)
작업 제출
이제 Azure Machine Learning 스튜디오에서 실행할 작업을 제출할 차례입니다. 이번에는 ml_client에서 create_or_update를 사용합니다. ml_client는 Python을 사용하여 Azure 구독에 연결하고 Azure Machine Learning Services와 상호 작용할 수 있게 해주는 클라이언트 클래스입니다. ml_client를 사용하면 Python을 사용하여 작업을 제출할 수 있습니다.
ml_client.create_or_update(job)
작업 출력 보기 및 작업 완료 대기
이전 셀의 출력에서 링크를 선택하여 Azure Machine Learning 스튜디오에서 작업을 봅니다. 이 작업의 출력은 Azure Machine Learning 스튜디오에서 다음과 같이 표시됩니다. 메트릭, 출력 등과 같은 다양한 세부 정보에 대한 탭을 살펴봅니다. 작업이 완료되면 학습 결과로 작업 영역에 모델이 등록됩니다.
Important
계속하려면 이 Notebook으로 돌아가기 전에 작업 상태가 완료될 때까지 기다립니다. 이 작업을 실행하는 데 2~3분이 걸립니다. 컴퓨팅 클러스터가 0개 노드로 축소되었고 사용자 지정 환경이 아직 빌드 중인 경우 더 오래 걸릴 수 있습니다(최대 10분).
셀을 실행하면 Notebook 출력에 Azure Studio의 작업 세부 정보 페이지에 대한 링크가 표시됩니다. 또는 왼쪽 탐색 메뉴에서 작업을 선택할 수도 있습니다. 작업은 지정된 스크립트 또는 코드 조각에서 많은 실행을 그룹화한 것입니다. 실행에 대한 정보는 해당 작업 아래에 저장됩니다. 세부 정보 페이지에는 작업 개요, 실행하는 데 걸린 시간, 작업이 만들어진 시기 등이 제공됩니다. 이 페이지에는 메트릭, 출력 + 로그, 코드 등 작업에 대한 기타 정보에 대한 탭도 있습니다. 작업 세부 정보 페이지에서 사용할 수 있는 탭은 다음과 같습니다.
- 개요: 개요 섹션에서는 상태, 시작 및 종료 시간, 실행된 작업 형식 등 작업에 대한 기본 정보를 제공합니다.
- 입력: 입력 섹션에는 작업의 입력으로 사용된 데이터와 코드가 나열됩니다. 이 섹션에는 학습 중에 사용된 데이터 세트, 스크립트, 환경 구성 및 기타 리소스가 포함될 수 있습니다.
- 출력 + 로그: 출력 + 로그 탭에는 작업이 실행되는 동안 생성된 로그가 포함됩니다. 이 탭은 학습 스크립트 또는 모델 만들기에 문제가 있는 경우 문제를 해결하는 데 도움이 됩니다.
- 메트릭: 메트릭 탭에는 학습 점수, f1 점수, 정밀도 점수 등 모델의 주요 성능 메트릭이 표시됩니다.
리소스 정리
지금 다른 자습서를 계속 진행하려면 다음 단계로 건너뛰세요.
컴퓨팅 인스턴스 중지
지금 사용하지 않으려면 컴퓨팅 인스턴스를 중지합니다.
- 스튜디오의 왼쪽 탐색 영역에서 컴퓨팅을 선택합니다.
- 맨 위 탭에서 컴퓨팅 인스턴스를 선택합니다.
- 목록에서 컴퓨팅 인스턴스를 선택합니다.
- 맨 위의 도구 모음에서 중지를 선택합니다.
모든 리소스 삭제
Important
사용자가 만든 리소스는 다른 Azure Machine Learning 자습서 및 방법 문서의 필수 구성 요소로 사용할 수 있습니다.
사용자가 만든 리소스를 사용하지 않으려면 요금이 발생하지 않도록 해당 리소스를 삭제합니다.
Azure Portal 맨 왼쪽에서 리소스 그룹을 선택합니다.
목록에서 만든 리소스 그룹을 선택합니다.
리소스 그룹 삭제를 선택합니다.
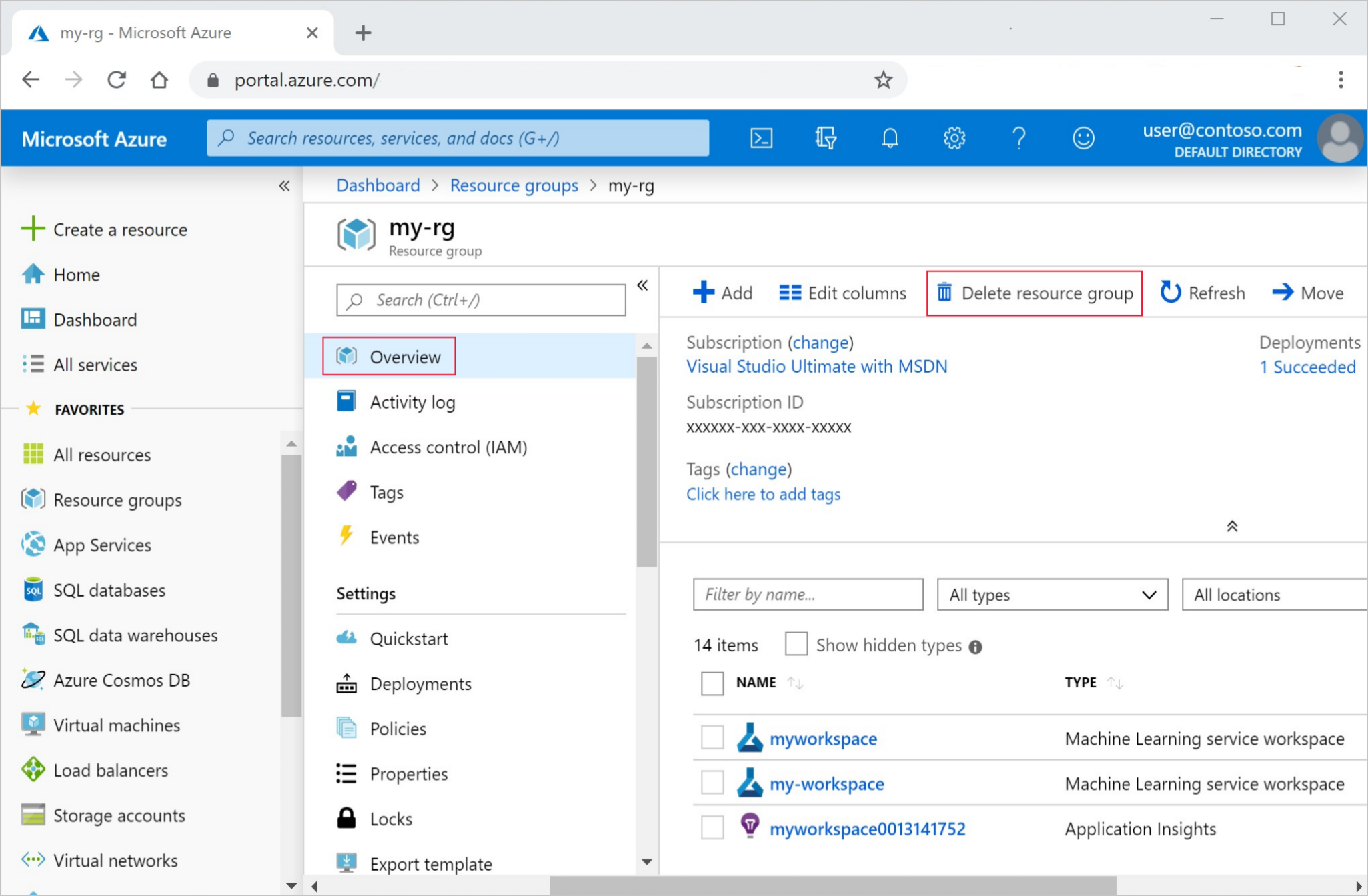
리소스 그룹 이름을 입력합니다. 그런 다음 삭제를 선택합니다.
다음 단계
모델 배포에 대해 알아보기
이 자습서에서는 온라인 데이터 파일을 사용했습니다. 데이터에 액세스하는 다른 방법에 대해 자세히 알아보려면 자습서: Azure Machine Learning에서 데이터 업로드, 액세스 및 탐색을 참조하세요.
Azure Machine Learning에서 모델을 학습시키는 다양한 방법에 대해 자세히 알아보려면 AutoML(자동화된 Machine Learning)이란?를 참조하세요. 자동화된 ML은 데이터 과학자가 데이터에 가장 적합한 모델을 찾는 데 소요되는 시간을 줄이는 보완 도구입니다.
이 자습서와 유사한 예를 더 보려면 스튜디오의 샘플 섹션을 참조하세요. 동일한 샘플을 GitHub 예 페이지에서 사용할 수 있습니다. 다음 예에는 코드를 실행하고 모델 학습 방법을 알아볼 수 있는 완전한 Python Notebooks가 포함되어 있습니다. 분류, 자연어 처리, 변칙 검색 등의 시나리오가 포함된 샘플의 기존 스크립트를 수정하고 실행할 수 있습니다.