REST 자습서: 기술 세트를 사용하여 Azure AI Search에서 검색 가능한 콘텐츠 생성
이 자습서에서는 인덱싱 중에 콘텐츠 추출 및 변환을 위한 AI 보강 파이프라인을 만드는 REST API를 호출하는 방법을 알아봅니다.
기술 세트는 원시 콘텐츠에 AI 처리를 추가하여 해당 콘텐츠를 보다 균일하고 검색 가능하게 만듭니다. 기술 세트의 작동 방식을 알고 나면 이미지 분석에서 자연어 처리, 외부에서 제공하는 사용자 지정 처리에 이르기까지 광범위한 변환을 지원할 수 있습니다.
이 자습서는 다음 방법을 배우는 데 도움이 됩니다.
- 보강 파이프라인에서 개체를 정의합니다.
- 기술 세트를 빌드합니다. OCR, 언어 감지, 엔터티 인식 및 핵심 구 추출을 호출합니다.
- 파이프라인을 실행합니다. 검색 인덱스 만들기 및 로드
- 전체 텍스트 검색을 사용하여 결과를 확인합니다.
Azure 구독이 없는 경우 시작하기 전에 체험 계정을 엽니다.
개요
이 자습서에서는 REST 클라이언트 및 Azure AI Search REST API 를 사용하여 데이터 원본, 인덱스, 인덱서 및 기술 세트를 만듭니다.
인 덱서는 Azure Storage의 Blob 컨테이너에서 샘플 데이터(구조화되지 않은 텍스트 및 이미지)의 콘텐츠 추출부터 시작하여 파이프라인의 각 단계를 구동합니다.
콘텐츠가 추출되면 기술 세트 는 Microsoft에서 기본 제공 기술을 실행하여 정보를 찾고 추출합니다. 이러한 기술에는 이미지에 대한 OCR(광학 인식), 텍스트에 대한 언어 감지, 핵심 구 추출 및 엔터티 인식(조직)이 포함됩니다. 기술 집합에서 만든 새 정보는 인덱스 필드로 전송됩니다. 인덱스가 채워지면 쿼리, 패싯 및 필터의 필드를 사용할 수 있습니다.
필수 조건
참고 항목
이 자습서에서는 무료 검색 서비스를 사용할 수 있습니다. 무료 계층은 인덱스 3개, 인덱서 3개, 데이터 원본 3개로 제한됩니다. 이 자습서에서는 각각을 하나씩 만듭니다. 시작하기 전에 새 리소스를 수용할 수 있는 공간이 서비스에 있는지 확인하세요.
파일 다운로드
샘플 데이터 리포지토리의 zip 파일을 다운로드하고 콘텐츠를 추출합니다. 방법을 알아보세요.
Azure Storage에 샘플 데이터 업로드
Azure Storage에서 새 컨테이너를 만들고 이름을 cog-search-demo로 지정합니다.
Azure AI Search에서 연결을 공식화할 수 있도록 스토리지 연결 문자열 가져옵니다.
왼쪽에서 액세스 키를 선택합니다.
키 1 또는 키 2에 대한 연결 문자열 복사합니다. 연결 문자열 다음 예제와 유사합니다.
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Azure AI 서비스
기본 제공 AI 보강은 자연어 및 이미지 처리를 위한 언어 서비스 및 Azure AI Vision을 비롯한 Azure AI 서비스에서 지원됩니다. 이 자습서와 같은 소규모 워크로드의 경우 인덱서당 20개의 트랜잭션을 무료로 할당할 수 있습니다. 더 큰 워크로드의 경우 Azure AI Services 다중 지역 리소스를 종량제 가격 책정을 위한 기술 세트 에 연결합니다.
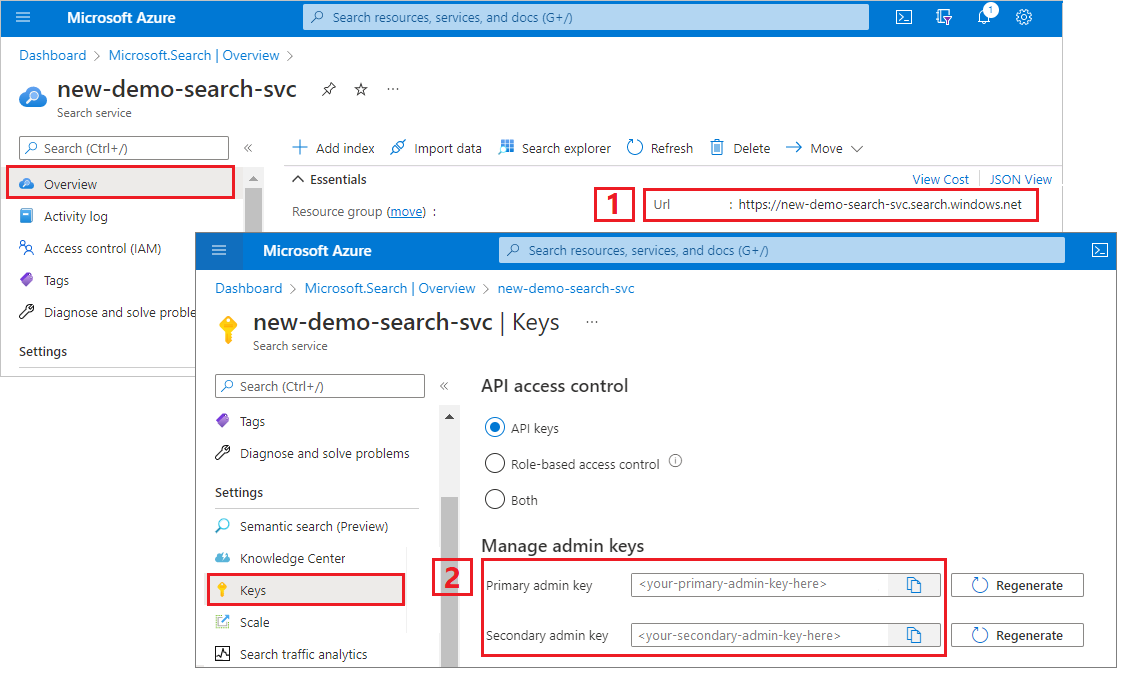
검색 서비스 URL 및 API 키 복사
이 자습서에서는 Azure AI Search에 연결하려면 엔드포인트와 API 키가 필요합니다. Azure Portal에서 이러한 값을 가져올 수 있습니다.
Azure Portal에 로그인하고, 검색 서비스 개요 페이지로 이동하고, URL을 복사합니다. 엔드포인트의 예는 다음과 같습니다.
https://mydemo.search.windows.net설정>키에서 관리자 키를 복사합니다. 관리자 키는 개체를 추가, 수정, 삭제하는 데 사용됩니다. 교환 가능한 관리자 키는 2개입니다. 둘 중 하나를 복사합니다.
REST 파일 설정
Visual Studio Code를 시작하고 skillset-tutorial.rest 파일을 엽니다. REST 클라이언트에 대한 도움이 필요한 경우 REST를 사용하여 텍스트 검색 빠른 시작을 참조하세요.
검색 서비스 엔드포인트, 검색 서비스 관리자 API 키, 인덱스 이름, Azure Storage 계정에 대한 연결 문자열 및 Blob 컨테이너 이름 등 변수에 대한 값을 제공합니다.
파이프라인 만들기
AI 보강은 인덱서 기반입니다. 이 연습 부분에서는 데이터 원본, 인덱스 정의, 기술 세트, 인덱서의 네 가지 개체를 만듭니다.
1단계: 데이터 소스 만들기
데이터 원본 만들기를 호출하여 연결 문자열을 샘플 데이터 파일이 포함된 Blob 컨테이너로 설정합니다.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
2단계: 기술 세트 만들기
기술 세트 만들기를 호출하여 콘텐츠에 적용되는 보강 단계를 지정합니다. 종속성이 없는 한 기술은 병렬로 실행됩니다.
### Create a skillset
POST {{baseUrl}}/skillsets?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ss",
"description": "Apply OCR, detect language, extract entities, and extract key-phrases.",
"cognitiveServices": null,
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field. This is useful for PDF and other file formats that supported embedded images.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text",
"source": "/document/content"
},
{
"name": "itemsToInsert",
"source": "/document/normalized_images/*/text"
},
{
"name":"offsets",
"source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText",
"targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"textSplitMode": "pages",
"maximumPageLength": 4000,
"defaultLanguageCode": "en",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.LanguageDetectionSkill",
"description": "If you have multilingual content, adding a language code is useful for filtering",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "languageName",
"targetName": "language"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.KeyPhraseExtractionSkill",
"context": "/document/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/pages/*"
}
],
"outputs": [
{
"name": "keyPhrases",
"targetName": "keyPhrases"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Organization"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "organizations",
"targetName": "organizations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Location"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "locations",
"targetName": "locations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Person"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons",
"targetName": "persons"
}
]
}
]
}
주요 정보:
요청 본문은 다음과 같은 기본 제공 기술을 지정합니다.
기술 설명 광학 문자 인식 이미지 파일에서 텍스트와 숫자를 인식합니다. 텍스트 병합 이전에 구분된 콘텐츠를 다시 조합하는 "병합된 콘텐츠"를 만듭니다. 포함된 이미지(PDF, DOCX 등)가 있는 문서에 유용합니다. 이미지와 텍스트는 문서 크래킹 단계에서 구분됩니다. 병합 기술은 보강 중에 생성된 인식된 텍스트, 이미지 캡션 또는 태그를 문서에서 이미지가 추출된 동일한 위치에 삽입하여 다시 결합합니다. 기술 세트에서 병합된 콘텐츠를 사용하는 경우 이 노드는 OCR 또는 이미지 분석을 거치지 않는 텍스트 전용 문서를 포함하여 문서의 모든 텍스트를 포함합니다. 언어 감지 언어를 검색하고 언어 이름 또는 코드를 출력합니다. 다국어 데이터 집합에서 언어 필드는 필터에 유용할 수 있습니다. 엔터티 인식 병합된 콘텐츠에서 사람, 조직 및 위치의 이름을 추출합니다. 텍스트 분할 핵심 구 추출 기술을 호출하기 전에 대량 병합된 콘텐츠를 더 작은 청크로 분할합니다. 핵심 구 추출은 50,000자 이하의 입력을 허용합니다. 일부 샘플 파일은 이 제한에 맞게 분할해야 합니다. 핵심 구 추출 상위 핵심 구를 가져옵니다. 각 기술은 문서의 콘텐츠에서 실행됩니다. 처리하는 동안 Azure AI 검색은 각 문서를 해독하여 다른 파일 형식의 콘텐츠를 읽습니다. 원본 파일에서 발생하는 텍스트는 각 문서에 대해 생성되는
content필드에 배치됩니다. 따라서 입력은"/document/content"가 됩니다.핵심 구 추출의 경우 텍스트 분할기 기술을 사용하여 더 큰 파일을 페이지로 분할하므로 핵심 구 추출 기술의 컨텍스트는
"/document/content"대신"document/pages/*"(문서의 각 페이지에 대해)입니다.
참고 항목
출력을 인덱스에 매핑할 수도 있고, 다운스트림 기술의 입력으로 사용할 수도 있고, 언어 코드처럼 둘 다 할 수도 있습니다. 인덱스에서 언어 코드는 필터링에 유용합니다. 기술 집합 기본에 대한 자세한 내용은 기술 집합을 정의하는 방법을 참조하세요.
3단계: 인덱스 만들기
인덱스 만들기를 호출하여 Azure AI 검색의 반전된 인덱스 및 기타 구문을 만드는 데 사용되는 스키마를 제공합니다.
인덱스의 가장 큰 구성 요소는 필드 컬렉션입니다. 여기서 데이터 형식과 특성은 Azure AI 검색의 콘텐츠와 동작을 결정합니다. 새로 생성된 출력에 대한 필드가 있는지 확인합니다.
### Create an index
POST {{baseUrl}}/indexes?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idx",
"defaultScoringProfile": "",
"fields": [
{
"name": "content",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "text",
"type": "Collection(Edm.String)",
"facetable": false,
"filterable": true,
"searchable": true,
"sortable": false
},
{
"name": "language",
"type": "Edm.String",
"searchable": false,
"sortable": true,
"filterable": true,
"facetable": false
},
{
"name": "keyPhrases",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "organizations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "persons",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "locations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "metadata_storage_path",
"type": "Edm.String",
"key": true,
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "metadata_storage_name",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
}
]
}
4단계: 인덱서 만들기 및 실행
인덱서 만들기를 호출하여 파이프라인을 구동합니다. 지금까지 만든 세 가지 구성 요소(데이터 원본, 기술 세트, 인덱스)는 인덱서에 대한 입력입니다. Azure AI 검색에서 인덱서를 만드는 것은 전체 파이프라인을 이동시키는 이벤트입니다.
이 단계를 완료하는 데는 몇 분 정도 걸릴 수 있습니다. 데이터 집합이 작아도 분석 기술은 계산을 많이 수행합니다.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idxr",
"description": "",
"dataSourceName" : "cog-search-demo-ds",
"targetIndexName" : "cog-search-demo-idx",
"skillsetName" : "cog-search-demo-ss",
"fieldMappings" : [
{
"sourceFieldName" : "metadata_storage_path",
"targetFieldName" : "metadata_storage_path",
"mappingFunction" : { "name" : "base64Encode" }
},
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "metadata_storage_name"
}
],
"outputFieldMappings" :
[
{
"sourceFieldName": "/document/merged_text",
"targetFieldName": "content"
},
{
"sourceFieldName" : "/document/normalized_images/*/text",
"targetFieldName" : "text"
},
{
"sourceFieldName" : "/document/organizations",
"targetFieldName" : "organizations"
},
{
"sourceFieldName": "/document/language",
"targetFieldName": "language"
},
{
"sourceFieldName" : "/document/persons",
"targetFieldName" : "persons"
},
{
"sourceFieldName" : "/document/locations",
"targetFieldName" : "locations"
},
{
"sourceFieldName" : "/document/pages/*/keyPhrases/*",
"targetFieldName" : "keyPhrases"
}
],
"parameters":
{
"batchSize": 1,
"maxFailedItems":-1,
"maxFailedItemsPerBatch":-1,
"configuration":
{
"dataToExtract": "contentAndMetadata",
"imageAction": "generateNormalizedImages"
}
}
}
주요 정보:
요청 본문에는 이전 개체에 대한 참조, 이미지 처리에 필요한 구성 속성 및 두 가지 유형의 필드 매핑이 포함됩니다.
"fieldMappings"는 기술 세트보다 먼저 처리되어 콘텐츠를 데이터 원본에서 인덱스의 대상 필드로 보냅니다. 필드 매핑을 사용하여 수정되지 않은 기존 콘텐츠를 인덱스로 보냅니다. 필드 이름과 유형이 양쪽 끝에서 동일하면 매핑이 필요 없습니다."outputFieldMappings"는 기술 세트 실행 후 스킬에 의해 생성되는 필드입니다.outputFieldMappings의sourceFieldName에 대한 참조는 문서 크래킹 또는 보강에서 만들 때까지 존재하지 않습니다.targetFieldName은 인덱스 스키마에 정의된 인덱스의 필드입니다."maxFailedItems"매개 변수는 -1로 설정됩니다. 이 매개 변수는 데이터를 가져오는 동안 오류를 무시하도록 인덱싱 엔진에 지시합니다. 데모 데이터 원본에는 몇 개의 문서만 있으므로 이는 허용됩니다. 데이터 원본의 크기가 큰 경우에는 0보다 큰 값으로 설정해야 합니다."dataToExtract":"contentAndMetadata"문은 Blob의 콘텐츠 속성 및 각 개체의 메타데이터에서 값을 자동으로 추출하도록 인덱서에 지시합니다.매개 변수는
imageAction데이터 원본에 있는 이미지에서 텍스트를 추출하도록 인덱서에 지시합니다."imageAction":"generateNormalizedImages"구성은 OCR 기술 및 텍스트 병합 기술과 결합되어 이미지에서 텍스트(예: 트래픽 중지 신호의 "중지"라는 단어)를 추출하고 해당 텍스트를 콘텐츠 필드의 일부로 포함시키도록 인덱서에 지시합니다. 이 동작은 임베드된 이미지(PDF 내부의 이미지 등)와 독립형 이미지 파일(예: JPG 파일)에 모두 적용됩니다.
참고 항목
인덱서를 만들면 파이프라인이 호출됩니다. 데이터 도달, 입력 및 출력 매핑 또는 작업 순서에 문제가 있으면 이 단계에 나타납니다. 코드 또는 스크립트를 변경하고 파이프라인을 다시 실행하려면 먼저 개체를 삭제해야 합니다. 자세한 내용은 다시 설정하고 다시 실행을 참조하세요.
인덱싱 모니터링
인덱싱 및 보강은 인덱서 만들기 요청을 제출하는 즉시 시작됩니다. 기술 세트 복잡성 및 작업에 따라 인덱싱에 다소 시간이 걸릴 수 있습니다.
인덱서가 여전히 실행 중인지 확인하려면 인덱서 상태 가져오기를 호출하여 인덱서 상태를 확인합니다.
### Get Indexer Status (wait several minutes for the indexer to complete)
GET {{baseUrl}}/indexers/cog-search-demo-idxr/status?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
주요 정보:
경고는 일부 시나리오에서 일반적이며 항상 문제를 나타내는 것은 아닙니다. 예를 들어 Blob 컨테이너에 이미지 파일이 포함되어 있고 파이프라인이 이미지를 처리하지 않는 경우 이미지가 처리되지 않았다는 경고가 표시됩니다.
이 샘플에는 텍스트가 없는 PNG 파일이 있습니다. 5가지 텍스트 기반 기술(언어 감지, 위치의 엔터티 인식, 조직, 사람 및 핵심 구 추출)은 모두 이 파일에서 실행되지 않습니다. 결과 알림이 실행 기록에 표시됩니다.
결과 확인
이제 AI 생성 콘텐츠가 포함된 인덱스를 만들었으므로 문서 검색을 호출하여 일부 쿼리를 실행하여 결과를 확인합니다.
### Query the index\
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"select": "metadata_storage_name,language,organizations",
"count": true
}
필터를 사용하면 결과를 관심 있는 항목으로 좁힐 수 있습니다.
### Filter by organization
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"filter": "organizations/any(organizations: organizations eq 'Microsoft')",
"select": "metadata_storage_name,organizations",
"count": true
}
이러한 쿼리는 Azure AI 검색을 통해 생성되는 새 필드에 대해 쿼리 구문과 필터를 사용할 수 있는 몇 가지 방법을 보여 줍니다. 자세한 쿼리 예제는 문서 검색 REST API 예제, 단순 구문 쿼리 예제 및 전체 Lucene 쿼리 예제를 참조하세요.
다시 설정하고 다시 실행
개발 초기 단계에서는 디자인을 반복하는 것이 일반적입니다. 다시 설정하고 다시 실행 하면 반복에 도움이 됩니다.
핵심 내용
이 자습서에서는 REST API를 사용하여 AI 보강 파이프라인을 만들기 위한 기본 단계인 데이터 원본, 기술 세트, 인덱스 및 인덱서를 보여 줍니다.
입력 및 출력을 통해 기술을 연결하는 메커니즘을 보여주는 기술 세트 정의와 함께 기본 제공 기술이 도입되었습니다. 인덱서 정의의 outputFieldMappings는 보강된 값을 Azure AI 검색 서비스의 파이프라인에서 검색 가능한 인덱스로 라우팅하는 데 필요하다는 것도 배웠습니다.
마지막으로, 결과를 테스트하고 추가 반복을 위해 시스템을 다시 설정하는 방법을 배웠습니다. 인덱스에 대한 쿼리를 실행하면 보강된 인덱싱 파이프라인에서 만든 출력이 반환된다는 것을 배웠습니다.
리소스 정리
사용자 고유의 구독에서 작업하는 경우 프로젝트의 끝에서 더 이상 필요하지 않은 리소스를 제거하는 것이 좋습니다. 계속 실행되는 리소스에는 요금이 부과될 수 있습니다. 리소스를 개별적으로 삭제하거나 리소스 그룹을 삭제하여 전체 리소스 세트를 삭제할 수 있습니다.
왼쪽 탐색 창의 모든 리소스 또는 리소스 그룹 링크를 사용하여 포털에서 리소스를 찾고 관리할 수 있습니다.
다음 단계
이제 AI 보강 파이프라인의 모든 개체에 익숙해졌으므로 기술 세트 정의 및 개별 기술을 자세히 살펴보세요.