Azure AI Search에서 검색 결과 작업 방법
이 문서에서는 Azure AI Search에서 쿼리 응답을 다루는 방법을 설명합니다. 응답의 구조는 문서 검색(REST) 또는 SearchResults 클래스(.NET용 Azure)에 설명된 대로 쿼리 자체의 매개 변수에 의해 결정됩니다.
쿼리의 매개 변수는 다음을 결정합니다.
- 필드 선택
- 쿼리의 인덱스에서 찾은 일치 항목 수
- 페이징 결과
- 응답 결과 수(기본값으로 최대 50개)
- 정렬 순서
- 본문의 전체 또는 부분 용어와 일치하는 결과 내 용어 강조 표시
결과 구성
결과는 테이블 형식이거나 모든 “검색 가능한” 필드로 구성되거나 $select 매개 변수에 지정된 필드로 제한되는 방식 중 하나입니다. 행은 일치하는 문서입니다.
검색 결과에 있는 필드를 선택할 수 있습니다. 검색 문서는 대규모 필드로 구성될 수 있지만 보통 결과의 각 문서를 표시하는 데는 몇 개면 됩니다. 쿼리 요청에서 응답에 표시할 "검색 가능" 필드를 지정하기 위해 $select=<field list>를 추가합니다.
문서 간에 대비 및 차별화를 제공하는 필드를 선택하여 사용자 쪽의 클릭 메시지 응답을 유도하기에 충분한 정보를 제공합니다. 전자상거래 사이트에는 제품 이름, 설명, 브랜드, 색, 크기, 가격 및 등급이 있을 수 있습니다. hotels-sample-index 기본 제공 샘플의 경우 다음 예제의 “select” 필드가 될 수 있습니다.
POST /indexes/hotels-sample-index/docs/search?api-version=2020-06-30
{
"search": "sandy beaches",
"select": "HotelId, HotelName, Description, Rating, Address/City"
"count": true
}
참고 항목
제품 사진 또는 로고와 같은 결과 이미지의 경우 Azure AI Search 외부에 저장하지만 검색 문서에서 이미지 URL을 참조하는 필드를 인덱스에 추가합니다. 결과에서 이미지를 보여 주는 샘플 인덱스에는 realestate-sample-us 데모(데이터 가져오기 마법사에서 쉽게 빌드할 수 있는 기본 제공 샘플 데이터 세트) 및 뉴욕시 작업 데모 앱이 포함됩니다.
예기치 않은 결과 대한 팁
경우에 따라, 결과의 구조가 아닌 본질을 예상할 수 없습니다. 예를 들어 일부 결과가 중복된 것처럼 보이거나 위쪽 근처에 나타나야 하는 결과가 결과에서 아래쪽에 배치될 수 있습니다. 쿼리 결과가 예상과 다른 경우 다음과 같이 쿼리를 수정하여 결과가 개선되는지 확인할 수 있습니다.
searchMode=any(기본값)를searchMode=all로 변경하여 조건 중 하나가 아닌 모든 조건에 일치하도록 합니다. 부울 연산자가 쿼리에 포함되는 경우 특히 이렇게 합니다.다른 어휘 분석기나 사용자 지정 분석기를 시험하여 쿼리 결과가 변경되는지 확인합니다. 기본 분석기는 하이픈이 포함된 단어를 나누며 단어를 어근 형태까지 줄여 일반적으로 쿼리 응답의 견고성을 높입니다. 그러나 하이픈을 그대로 두어야 하거나 문자열에 특수 문자가 포함되었다면, 인덱스가 올바른 형식의 토큰을 포함하도록 사용자 지정 분석기를 구성해야 할 수 있습니다. 자세한 내용은 특수 문자(하이픈, 와일드카드, 정규식, 패턴)를 사용하는 부분 용어 검색 및 패턴을 참조하세요.
일치 항목 수 계산
count 매개 변수는 쿼리와 일치하는 것으로 간주되는 인덱스의 문서 수를 반환합니다. 개수를 반환하려면 쿼리 요청에 $count=true를 추가합니다. 검색 서비스에 의해 부과되는 최댓값은 없습니다. 쿼리 및 문서의 내용에 따라 개수는 인덱스의 모든 문서만큼 많을 수 있습니다.
인덱스가 안정적이면 개수가 정확합니다. 시스템에서 문서를 활성으로 추가, 업데이트 또는 삭제하는 경우 개수는 대략적으로 계산되며 완전히 인덱싱되지 않은 문서는 제외됩니다.
개수는 검색 서비스의 루틴 유지 관리 또는 기타 워크로드의 영향을 받지 않습니다. 그러나 여러 파티션과 단일 복제본이 있는 경우 파티션이 다시 시작될 때 문서 수의 단기(몇 분) 변동이 발생할 수 있습니다.
팁
인덱싱 작업을 확인하려면 빈 검색 search=* 쿼리에 $count=true를 추가하여 인덱스에 예상되는 문서 수가 포함되어 있는지 확인할 수 있습니다. 결과는 인덱스의 전체 문서 수입니다.
쿼리 구문을 테스트할 때 $count=true는 수정 사항이 더 많거나 적은 결과를 반환하는지 여부를 빠르게 알려줄 수 있으며 이는 유용한 피드백일 수 있습니다.
페이징 결과
기본값으로 검색 엔진은 처음 50개 일치 항목까지 반환합니다. 상위 50개 항목은 검색 점수에 따라 결정되며, 쿼리가 전체 텍스트 검색 또는 의미 체계라고 가정합니다. 그렇지 않으면 상위 50개는 정확한 일치 쿼리에 대한 임의 순서입니다(여기서 균일한 "@searchScore=1.0"은 임의 순위를 나타냄).
결과 집합에 반환된 모든 문서의 페이징을 제어하려면 GET 쿼리 요청에 $top 및 $skip 매개 변수를 추가하거나, POST 쿼리 요청에 top 및 skip 매개 변수를 추가합니다. 다음 목록은 논리를 설명합니다.
일치하는 처음 15개 문서의 집합과 총 일치 항목 수를 더하여 반환합니다(
GET /indexes/<INDEX-NAME>/docs?search=<QUERY STRING>&$top=15&$skip=0&$count=true).두 번째 집합을 반환하며 처음 15개를 건너뛰고 다음 15개를 가져옵니다(
$top=15&$skip=15). 세 번째 세트의 15에 대해 반복합니다.$top=15&$skip=30
기본 인덱스가 변경될 경우 페이지가 매겨진 쿼리의 결과가 안정적이지 않을 수 있습니다. 페이징은 각 페이지에 대해 $skip 값을 변경하지만, 각각의 쿼리는 독립적이며 쿼리 시점에서 인덱스에 존재하는 그대로 현재 데이터 보기에서 작동합니다(즉, 범용 데이터베이스에서와 같은 결과 캐싱이나 스냅샷 없음).
다음 예제는 중복 항목이 어떻게 얻어지는지 설명합니다. 4개의 문서에 대한 인덱스를 가정해 보겠습니다.
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
{ "id": "4", "rating": 1 }
한 번에 2개 결과를 평가에 따라 정렬하여 반환하고자 합니다. 이 쿼리를 실행하여 결과의 첫 페이지를 가져오고($top=2&$skip=0&$orderby=rating desc) 다음과 같은 결과가 생성됩니다.
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
서비스에서 쿼리 호출 사이에 5번째 문서가 인덱스에 추가되었습니다({ "id": "5", "rating": 4 }). 잠시 후 두 번째 페이지를 페치하는 쿼리를 실행하고($top=2&$skip=2&$orderby=rating desc) 다음 결과를 가져옵니다.
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
문서 2는 두 번 페치됩니다. 이것은 새 문서 5는 평가의 값이 더 크기 때문에 문서 2 앞에 정렬되고 첫 페이지에 도달하기 때문입니다. 이 동작은 예기치 않을 수 있지만 검색 엔진의 일반적인 동작 방식입니다.
많은 수의 결과를 통해 페이징
$top 및 $skip을 사용하여 검색 쿼리에서 100,000개의 결과를 통해 페이지할 수 있지만 결과가 100,000개보다 크면 어떻게 될까요? 이렇게 큰 응답을 통해 페이지하려면 $skip에 대한 해결 방법으로 정렬 순서 및 범위 필터를 사용합니다.
이 해결 방법에서 정렬 및 필터는 문서 ID 필드 또는 각 문서에서 고유한 다른 필드에 적용됩니다. 검색 인덱스에서 고유 필드에는 filterable 및 sortable 특성이 있어야 합니다.
쿼리를 실행하여 정렬된 결과의 전체 페이지를 반환합니다.
POST /indexes/good-books/docs/search?api-version=2020-06-30 { "search": "divine secrets", "top": 50, "orderby": "id asc" }검색 쿼리에서 반환된 마지막 결과를 선택합니다. "id" 값만 있는 예제 결과가 여기에 표시됩니다.
{ "id": "50" }범위 쿼리에서 해당 "id" 값을 사용하여 결과의 다음 페이지를 가져옵니다. 이 "id" 필드에는 고유한 값이 있어야 합니다. 그렇지 않으면 페이지 매김에 중복된 결과가 포함될 수 있습니다.
POST /indexes/good-books/docs/search?api-version=2020-06-30 { "search": "divine secrets", "top": 50, "orderby": "id asc", "filter": "id ge 50" }쿼리에서 0개의 결과를 반환하면 페이지 매김이 끝납니다.
참고 항목
"필터링 가능" 및 "정렬 가능" 특성은 필드가 인덱스로 처음 추가될 때만 사용하도록 설정할 수 있으며, 기존 필드에서는 사용할 수 없습니다.
결과 정렬
전체 텍스트 검색 쿼리에서 결과는 다음을 기준으로 순위를 지정할 수 있습니다.
- 검색 점수
- 의미 체계 순위 재지정 점수
- "정렬 가능" 필드의 정렬 순서
채점 프로필을 추가하여 특정 필드에 있는 일치 항목을 높일 수도 있습니다.
검색 점수별 정렬
전체 텍스트 검색 쿼리의 경우 문서의 용어 빈도 및 근접성(TF-IDF에서 파생)에 따라 계산된 검색 점수에 따라 결과의 순위를 자동으로 지정하며, 검색어와 일치 항목이 더 많거나 일치 수준이 높을수록 문서에 더 높은 점수를 부여합니다.
이전 서비스에서 "@search.score" 범위는 무제한(또는 0)~1.00(미만)입니다.
두 알고리즘 모두에서 1.00과 같은 “@search.score”는 점수가 없거나 순위가 없는 결과 집합을 나타내며, 여기서 1.0 점수는 모든 결과에서 균일합니다. 쿼리 양식이 유사 항목 검색, 와일드카드 또는 regex 쿼리, 또는 비어 있는 검색(search=*)인 경우 점수가 없는 결과가 나타납니다. 점수가 없는 결과에 순위 구조를 적용해야 하는 경우 $orderby 식을 사용하면 해당 목표를 달성하는 데 도움이 됩니다.
의미 체계 순위 재지정 기준 정렬
의미 체계 순위 지정을 사용하는 경우 “@search.rerankerScore”는 결과의 정렬 순서를 결정합니다.
“@search.rerankerScore” 범위는 1에서 4.00까지이며, 점수가 높을수록 의미 체계 일치가 더 강합니다.
$orderby를 사용하여 정렬
일관된 순서 지정이 애플리케이션 요구 사항인 경우 필드에서 $orderby 식을 정의할 수 있습니다. “정렬 가능”으로 인덱싱되는 필드만 결과 정렬에 사용할 수 있습니다.
$orderby에 일반적으로 사용되는 필드에는 등급, 날짜 및 위치가 있습니다. 위치 기준으로 필터링하려면 필터 식이 필드 이름 외에도 geo.distance() 함수를 호출해야 합니다.
숫자 필드(Edm.Double, Edm.Int32, Edm.Int64)는 숫자 순서로 정렬됩니다(예: 1, 2, 10, 11, 20).
문자열 필드(Edm.String, Edm.ComplexType 하위 필드)는 언어에 따라 ASCII 정렬 순서 또는 유니코드 정렬 순서로 정렬됩니다. 컬렉션은 어떤 형식이든 정렬할 수 없습니다.
문자열 필드의 숫자 콘텐츠는 사전순으로 정렬됩니다(1, 10, 11, 2, 20).
대문자 문자열은 소문자보다 먼저 정렬됩니다(APPLE, Apple, BANANA, Banana, apple, banana). 이 동작을 변경하기 위해 정렬하기 전에 텍스트를 전처리하도록 텍스트 노멀라이저를 할당할 수 있습니다. 필드에 소문자 토크나이저를 사용해도 Azure AI Search는 분석되지 않은 필드 복사본을 정렬하므로 정렬 동작에 영향을 주지 않습니다.
분음 부호로 시작하는 문자열은 마지막에 표시됩니다(Äpfel, Öffnen, Üben).
채점 프로필을 사용하여 관련성 향상
순서 일관성을 높이는 또 다른 방법은 사용자 지정 점수 매기기 프로필을 사용하는 것입니다. 점수 매기기 프로필을 사용하면 특정 필드에서의 일치 항목 찾기 기능을 더 강화하여 검색 결과의 항목 순위를 더 세밀하게 제어할 수 있습니다. 추가적인 점수 매기기 논리를 사용하면, 각 문서의 검색 점수가 서로 달라 발생하는 복제본 간의 미세한 차이를 무시할 수 있습니다. 이 방법에서는 순위 지정 알고리즘을 사용하는 것이 좋습니다.
적중 항목 강조 표시
적중 항목 강조 표시란 일치를 쉽게 찾을 수 있게 결과에서 일치하는 용어에 적용되는 텍스트 서식(예: 굵게, 노란색 강조 표시)을 말합니다. 강조 표시는 설명 필드 등 일치 항목이 바로 드러나지 않는 긴 콘텐츠 필드에 유용합니다.
강조 표시가 개별 용어에 적용된 것을 볼 수 있습니다. 전체 필드의 내용에 대한 강조 표시 기능은 없습니다. 구를 강조 표시하려면 따옴표로 묶인 쿼리 문자열에 일치하는 용어(또는 구)를 제공해야 합니다. 이 기술은 이 섹션에서 더 자세히 설명합니다.
적중 항목 강조 표시 지침은 쿼리 요청에서 제공합니다. 유사 항목 및 와일드카드 검색 등 엔진에서 쿼리 확장을 트리거하는 쿼리에서는 적중 항목 강조 표시를 제한적으로 지원합니다.
적중 항목 강조 표시에 대한 요구 사항
- 필드는
Edm.String또는Collection(Edm.String)이어야 합니다. - 필드는 검색 가능한 특성이 있어야 합니다.
요청에서 강조 표시 지정
강조 표시된 용어를 반환하려면 쿼리 요청에 “highlight” 매개 변수를 포함합니다. 매개 변수는 쉼표로 구분된 필드 목록으로 설정됩니다.
기본값으로 형식 태그는 <em>이지만 highlightPreTag 및 highlightPostTag 매개 변수를 사용하여 태그를 재정의할 수 있습니다. 클라이언트 코드는 응답을 처리합니다(예: 굵은 폰트 또는 노란색 배경 적용).
POST /indexes/good-books/docs/search?api-version=2020-06-30
{
"search": "divine secrets",
"highlight": "title, original_title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>"
}
기본적으로 Azure AI Search는 필드당 최대 5개의 강조 표시를 반환합니다. 대시 뒤에 정수를 추가하여 이 숫자를 조정할 수 있습니다. 예를 들어 "highlight": "description-10"은 설명 필드에서 일치하는 내용에 대해 최대 10개의 강조 표시된 용어를 반환합니다.
강조 표시된 결과
강조 표시가 쿼리에 추가되면 응답에는 각 결과에 대해 “@search.highlights”가 포함되어 애플리케이션 코드가 해당 구조를 대상으로 할 수 있도록 합니다. “강조 표시”에 지정된 필드 목록이 응답에 포함됩니다.
키워드 검색에서 각 용어는 독립적으로 검색됩니다. “divine secrets”에 대한 쿼리는 두 용어가 포함된 모든 문서에서 일치 항목을 반환합니다.
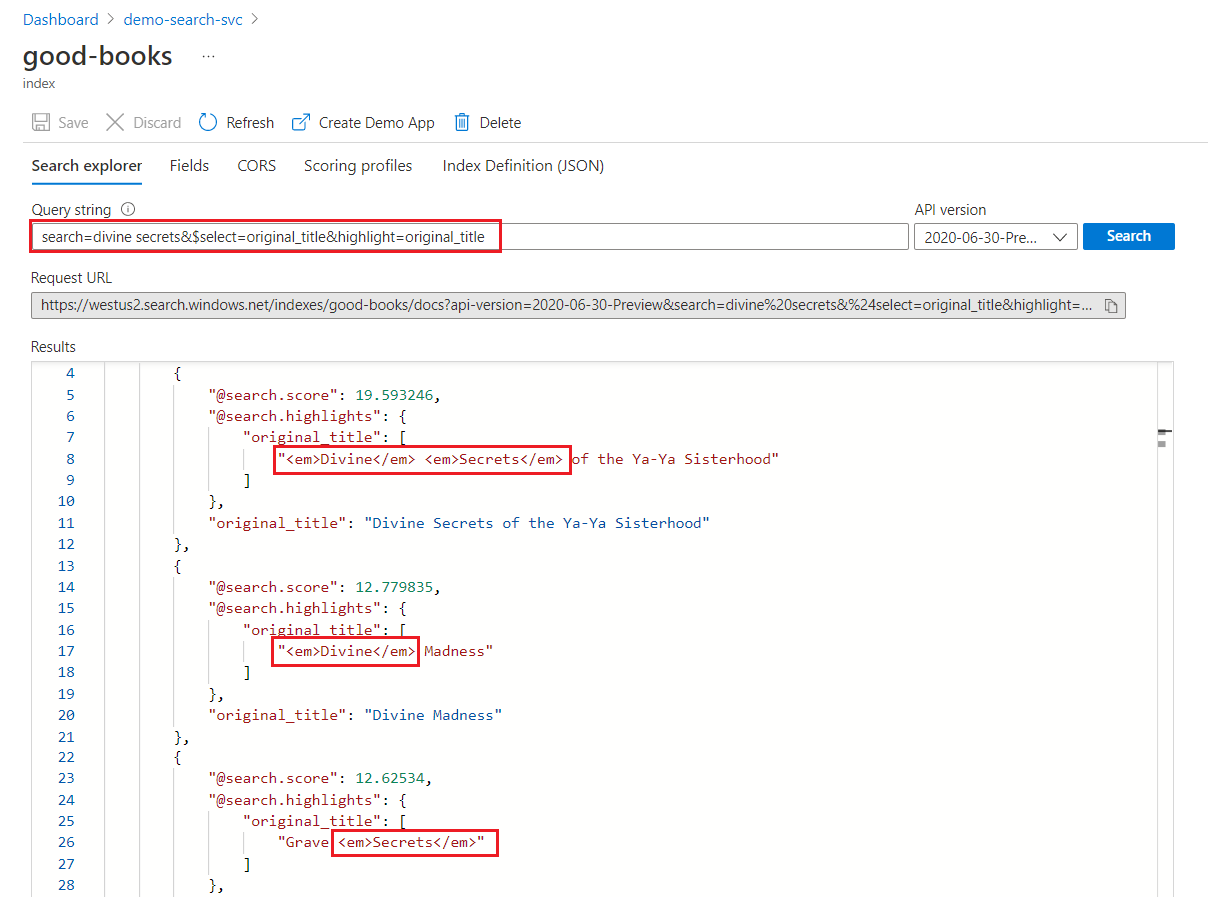
키워드 검색 강조 표시
강조 표시된 필드 내에서 서식 지정은 전체 용어에 적용됩니다. 예를 들어 “The Divine Secrets of the Ya-Ya Sisterhood”에 대한 일치에서 용어가 연속되어 있더라도 서식이 각 용어에 개별적으로 적용됩니다.
"@odata.count": 39,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"original_title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
],
"title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
},
{
"@search.score": 12.779835,
"@search.highlights": {
"original_title": [
"<em>Divine</em> Madness"
],
"title": [
"<em>Divine</em> Madness (Cherub, #5)"
]
},
"original_title": "Divine Madness",
"title": "Divine Madness (Cherub, #5)"
},
{
"@search.score": 12.62534,
"@search.highlights": {
"original_title": [
"Grave <em>Secrets</em>"
],
"title": [
"Grave <em>Secrets</em> (Temperance Brennan, #5)"
]
},
"original_title": "Grave Secrets",
"title": "Grave Secrets (Temperance Brennan, #5)"
}
]
구 검색 강조 표시
전체 용어 서식은 여러 용어가 큰따옴표로 묶인 구 검색에도 적용됩니다. 다음 예제는 "신성한 비밀"이 따옴표로 묶인 구로 제출된다는 점을 제외하고 동일한 쿼리입니다(일부 REST 클라이언트에서는 백슬래시 \"로 내부 따옴표를 이스케이프해야 함).
POST /indexes/good-books/docs/search?api-version=2020-06-30
{
"search": "\"divine secrets\"",,
"select": "title,original_title",
"highlight": "title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>",
"count": true
}
이제 조건이 두 용어를 모두 포함하므로 검색 인덱스에 일치하는 항목이 하나만 있습니다. 위 쿼리에 대한 응답은 다음과 같습니다.
{
"@odata.count": 1,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"title": [
"<b>Divine</b> <b>Secrets</b> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
}
]
}
이전 서비스에 대한 문구 강조 표시
2020년 7월 15일 이전에 만들어진 검색 서비스는 구 쿼리에 대해 다른 강조 표시 환경을 구현합니다.
다음 예제에서는 따옴표로 묶인 구 “super bowl”이 포함된 쿼리 문자열을 가정합니다. 2020년 7월 이전에는 구의 모든 용어가 강조 표시됩니다.
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is <em>super</em> awesome with a <em>bowl</em> of chips"
]
2020년 7월 이후에 만든 검색 서비스의 경우 전체 구 쿼리와 일치하는 구만 “@search.highlights”에 반환됩니다.
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is super awesome with a bowl of chips"
]
다음 단계
클라이언트에 대한 검색 페이지를 신속히 생성하려면 다음 옵션을 고려합니다.
포털에서 애플리케이션 생성기는 검색 창 및 패싯 탐색과, 이미지가 있는 결과 영역을 포함하는 HTML 페이지를 만듭니다.
ASP.NET Core(MVC) 앱에 검색 추가는 기능 클라이언트를 빌드하는 자습서 및 코드 샘플입니다.
웹앱에 검색 추가는 사용자 환경에 React JavaScript 라이브러리를 사용하는 자습서 및 코드 샘플입니다. 앱은 Azure Static Web Apps을 사용하여 배포됩니다.