벡터 인덱스 크기 및 제한 미만 유지
각 벡터 필드에 대해 Azure AI 검색은 필드에 지정된 알고리즘 매개 변수를 사용하여 내부 벡터 인덱스를 구성합니다. Azure AI 검색은 벡터 인덱스 크기에 할당량을 부과하므로 제한을 초과하지 않도록 벡터 크기를 예상하고 모니터링하는 방법을 알아야 합니다.
참고 항목
용어에 대한 참고 사항입니다. 내부적으로 검색 인덱스의 실제 데이터 구조에는 원시 콘텐츠(토큰화되지 않은 콘텐츠가 필요한 검색 패턴에 사용됨), 반전된 인덱스(검색 가능한 텍스트 필드에 사용됨) 및 벡터 인덱스(검색 가능한 벡터 필드에 사용됨)가 포함됩니다. 이 문서에서는 각 벡터 필드를 뒷받침하는 내부 벡터 인덱스의 제한에 대해 설명합니다.
팁
벡터 양자화 및 스토리지 구성이 현재 미리 보기 상태입니다. 좁은 데이터 형식, 스칼라 양자화, 중복 스토리지 제거와 같은 기능을 사용하여 벡터 할당량과 스토리지 할당량 이하로 유지하세요.
할당량 및 벡터 인덱스 크기에 대한 주요 사항
벡터 인덱스 크기는 바이트 단위로 측정됩니다.
벡터 할당량은 메모리 제약 조건을 기반으로 합니다. 검색 가능한 모든 벡터 인덱스는 메모리에 로드되어야 합니다. 동시에 다른 런타임 작업을 위한 메모리도 충분해야 합니다. 벡터 할당량은 전체 시스템이 모든 워크로드에 대해 안정적이고 균형있게 유지되도록 보장하기 위해 존재합니다.
벡터 인덱스는 모든 인덱스, 벡터와 비벡터라는 점에서 디스크 할당량의 적용을 받습니다. 벡터 인덱스에 대한 별도의 디스크 할당량은 없습니다.
벡터 할당량은 파티션당 전체적으로 검색 서비스에 적용됩니다. 즉, 파티션을 추가하면 벡터 할당량이 늘어나게 됩니다. 파티션당 벡터 할당량은 최신 서비스에서 더 높습니다.
파티션 크기와 수량을 확인하는 방법
검색 서비스 제한이 무엇인지 확실하지 않은 경우 해당 정보를 가져올 수 있는 두 가지 방법은 다음과 같습니다.
Azure Portal의 검색 서비스 개요 페이지에 있는 속성 탭과 사용량 탭 모두 파티션 크기와 스토리지는 물론 벡터 할당량과 벡터 인덱스 크기도 표시합니다.
Azure Portal의 크기 조정 페이지에서 파티션 수와 크기를 검토할 수 있습니다.
서비스를 만든 날짜 확인 방법
2024년 4월 3일 이후에 만들어진 최신 서비스는 동일한 계층 청구 요금으로 이전 서비스보다 5~10배 더 많은 벡터 스토리지를 제공합니다. 서비스가 오래된 경우 새 서비스를 만들고 콘텐츠를 마이그레이션하는 것이 좋습니다.
Azure Portal에서 검색 서비스가 포함된 리소스 그룹을 엽니다.
가장 왼쪽 창의 설정에서 배포를 선택합니다.
검색 서비스 배포를 찾습니다. 배포가 많은 경우 필터를 사용하여 "검색"을 찾습니다.
배포를 선택합니다. 둘 이상이면 클릭하여 검색 서비스로 해결되는지 확인합니다.
배포 세부 정보를 확장합니다. 만들어짐과 만든 날짜가 표시되어야 합니다.
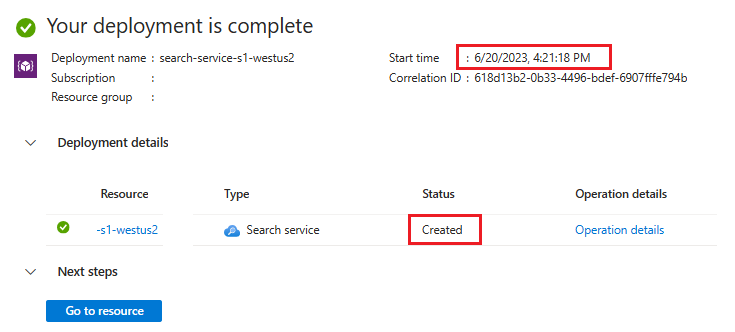
이제 검색 서비스의 수명을 알았으므로 서비스 만들기에 따른 벡터 할당량 한도를 검토합니다.
벡터 인덱스 크기를 가져오는 방법
벡터 메트릭에 대한 요청은 데이터 평면 작업입니다. Azure Portal, REST API 또는 Azure SDK를 사용하여 서비스 통계를 통해 서비스 수준에서 개별 인덱스에 대한 벡터 사용량을 가져올 수 있습니다.
사용 정보는 개요 페이지의 사용 탭에서 확인할 수 있습니다. 포털 페이지는 몇 분마다 새로 고쳐지므로 최근에 인덱스를 업데이트한 경우 결과를 확인하기 전에 잠시 기다립니다.
다음 스크린샷은 하나의 파티션과 하나의 복제본에 대해 구성된 이전 표준 1(S1) 검색 서비스에 대한 것입니다.
- 스토리지 할당량은 디스크 제약 조건이며 검색 서비스의 모든 인덱스(벡터 및 비벡터)를 포함합니다.
- 벡터 인덱스 크기 할당량은 메모리 제약 조건입니다. 검색 서비스의 각 벡터 필드에 대해 생성된 모든 내부 벡터 인덱스를 로드하는 데 필요한 메모리 양입니다.
스크린샷은 인덱스(벡터 및 비벡터)가 거의 460MB의 사용 가능한 디스크 스토리지를 사용한다는 것을 나타냅니다. 벡터 인덱스는 서비스 수준에서 거의 93MB의 메모리를 사용합니다.

파티션을 추가하거나 제거하면 스토리지와 벡터 인덱스 크기 모두에 대한 할당량이 증가하거나 감소합니다. 파티션 수를 변경하면 타일에 스토리지와 벡터 할당량의 해당 변경 내용이 표시됩니다.
참고 항목
디스크에서 벡터 인덱스는 93MB가 아닙니다. 디스크의 벡터 인덱스는 메모리의 벡터 인덱스보다 약 3배 더 많은 공간을 차지합니다. 자세한 내용은 벡터 필드가 디스크 스토리지에 미치는 영향을 참조하세요.
벡터 인덱스 크기에 영향을 주는 요소
내부 벡터 인덱스의 크기에 영향을 주는 세 가지 주요 구성 요소가 있습니다.
- 데이터의 원시 크기
- 선택한 알고리즘의 오버헤드
- 인덱스 내에서 문서 삭제 또는 업데이트로 인한 오버헤드
데이터의 원시 크기
각 벡터는 일반적으로 Collection(Edm.Single) 형식의 필드에 있는 단정밀도 부동 소수점 숫자의 배열입니다.
벡터 데이터 구조에는 다음 계산에서 데이터의 "원시 크기"로 표시되는 스토리지가 필요합니다. 이 원시 크기를 사용하여 벡터 필드의 벡터 인덱스 크기 요구 사항을 예측합니다.
한 벡터의 스토리지 크기는 차원에 따라 결정됩니다. 한 벡터의 크기를 해당 벡터 필드가 포함된 문서 수와 곱하여 원시 크기를 구합니다.
raw size = (number of documents) * (dimensions of vector field) * (size of data type)
| EDM 데이터 형식 | 데이터 형식의 크기 |
|---|---|
Collection(Edm.Single) |
4바이트 |
Collection(Edm.Half) |
2바이트 |
Collection(Edm.Int16) |
2바이트 |
Collection(Edm.SByte) |
1바이트 |
선택한 알고리즘의 메모리 오버헤드
모든 ANN(Approximous Nearest Neighbor) 알고리즘은 메모리에 추가 데이터 구조를 생성하여 효율적인 검색을 가능하게 합니다. 이러한 구조는 메모리 내에서 추가 공간을 소비합니다.
HNSW 알고리즘의 경우 메모리 오버헤드 범위는 1%에서 20%입니다.
메모리 오버헤드는 차원이 높을수록 벡터의 원시 크기가 증가하기 때문에 더 낮습니다. 추가 데이터 구조는 그래프 내 연결에 대한 정보를 저장하기 때문에 고정된 크기로 유지됩니다. 따라서 추가 데이터 구조의 기여는 전체 크기의 작은 부분을 구성합니다.
인덱스 구성 중에 모든 새 벡터에 대해 생성되는 양방향 링크 수를 결정하는 HNSW 매개 변수 m의 값이 클수록 메모리 오버헤드가 더 높아집니다. 이는 m이 문서당 약 8바이트에서 10바이트에 m을 곱하여 기여하기 때문입니다.
다음 표에는 내부 테스트에서 관찰된 오버헤드 백분율이 요약되어 있습니다.
| 차원 | HNSW 매개 변수(m) | 오버헤드 백분율 |
|---|---|---|
| 96 | 4 | 20% |
| 200 | 4 | 8% |
| 768 | 4 | %2 |
| 1536 | 4 | %1 |
이러한 결과는 HNSW 알고리즘에 대한 차원, HNSW 매개 변수 m 및 메모리 오버헤드 간의 관계를 보여줍니다.
인덱스 내에서 문서 삭제 또는 업데이트로 인한 오버헤드
벡터 필드가 있는 문서가 삭제되거나 업데이트되면(업데이트는 내부적으로 삭제 및 삽입 작업으로 표시됨) 기본 문서가 삭제된 것으로 표시되고 후속 쿼리 중에 건너뜁니다. 새 문서가 인덱싱되고 내부 벡터 인덱스가 증가함에 따라 시스템은 이러한 삭제된 문서를 정리하고 리소스를 회수합니다. 즉, 문서 삭제와 기본 리소스가 해제되는 사이에 지연이 발생할 가능성이 있습니다.
이를 삭제된 문서 비율이라고 지칭합니다. 문서 비율은 서비스의 인덱싱 특성에 따라 달라지므로 이 매개 변수를 추정하는 보편적인 경험적 방법이 없으며 서비스에 적용되는 비율을 반환하는 API 또는 스크립트가 없습니다. 고객 중 절반이 삭제된 문서 비율이 10% 미만인 것으로 나타났습니다. 삭제나 업데이트를 자주 수행하는 경향이 있는 경우 삭제된 문서 비율이 더 높은 것을 볼 수 있습니다.
이는 벡터 인덱스의 크기에 영향을 미치는 또 다른 요소입니다. 아쉽게도 현재 삭제된 문서 비율을 노출하는 메커니즘은 없습니다.
메모리 내 데이터의 총 크기 추정
이전에 설명한 요소를 고려하여 벡터 인덱스의 전체 크기를 예상하려면 다음 계산을 사용합니다.
(raw_size) * (1 + algorithm_overhead (in percent)) * (1 + deleted_docs_ratio (in percent))
예를 들어, raw_size를 계산하기 위해 널리 사용되는 Azure OpenAI 모델인 text-embedding-ada-002(차원 1,536개)을 사용한다고 가정해 보겠습니다. 이는 하나의 문서가 1,536Edm.Single(float) 또는 6,144바이트를 소비한다는 것을 의미합니다. 각 Edm.Single은 4바이트이기 때문입니다. 단일 1,536차원 벡터 필드가 있는 문서 1,000개는 총 1,000개 문서 x 1536개 float/doc = 1,536,000 float 또는 6,144,000바이트를 소비합니다.
여러 벡터 필드가 있는 경우 인덱스 내의 각 벡터 필드에 대해 이 계산을 수행하고 모두 합산해야 합니다. 예를 들어, 1,536차원 벡터 필드가 2개 있는 1,000개의 문서는 1000개의 문서 x 2개 필드 x 1536 float/doc x 4바이트/float = 12,288,000바이트를 소비합니다.
벡터 인덱스 크기를 구하려면 이 raw_size에 알고리즘 오버헤드 및 삭제된 문서 비율을 곱합니다. 선택한 HNSW 매개 변수에 대한 알고리즘 오버헤드가 10%이고 삭제된 문서 비율이 10%이면 6.144 MB * (1 + 0.10) * (1 + 0.10) = 7.434 MB를 얻습니다.
벡터 필드가 디스크 스토리지에 미치는 영향
이 문서의 대부분은 메모리의 벡터 크기에 관한 정보를 제공합니다. 디스크의 벡터 크기에 관해 알고 싶은 경우 벡터 데이터의 디스크 사용량은 메모리의 벡터 인덱스 크기의 약 3배입니다. 예를 들어 vectorIndexSize 사용량이 100메가바이트(1,000만 바이트)인 경우 벡터 인덱스를 수용하기 위해 300메가바이트 이상의 storageSize 할당량을 사용했을 것입니다.