NFS Azure 파일 공유 성능 향상
이 문서에서는 NFS Azure 파일 공유의 성능을 개선하는 방법을 설명합니다.
적용 대상
| 파일 공유 유형 | SMB | NFS |
|---|---|---|
| 표준 파일 공유(GPv2), LRS/ZRS | ||
| 표준 파일 공유(GPv2), GRS/GZRS | ||
| 프리미엄 파일 공유(FileStorage), LRS/ZRS |
읽기 처리량을 향상시키기 위해 미리 읽기 크기 늘리기
Linux의 read_ahead_kb 커널 매개 변수는 순차적 읽기 작업 중에 "미리 읽기" 또는 프리페치해야 하는 데이터의 양을 나타냅니다. 5.4 이전의 Linux 커널 버전은 미리 읽기 값을 탑재된 파일 시스템의 rsize(읽기 버퍼 크기의 클라이언트 쪽 탑재 옵션)의 15배에 해당하는 값으로 설정합니다. 이렇게 하면 대부분의 경우 클라이언트 순차 읽기 처리량을 향상시킬 수 있을 만큼 미리 읽기 값이 높게 설정됩니다.
그러나 Linux 커널 버전 5.4부터 Linux NFS 클라이언트는 기본 read_ahead_kb 값인 128KiB를 사용합니다. 이 작은 값은 대용량 파일의 읽기 처리량을 줄일 수 있습니다. 읽기 전 값이 더 큰 Linux 릴리스에서 128KiB 기본값을 사용하는 릴리스로 업그레이드하는 고객은 순차적 읽기 성능이 저하될 수 있습니다.
Linux 커널 5.4 이상의 경우 성능 향상을 위해 read_ahead_kb를 15MiB로 영구적으로 설정하는 것이 좋습니다.
이 값을 변경하려면 Linux 커널 디바이스 관리자인 udev에 규칙을 추가하여 미리 읽기 크기를 설정합니다. 다음 단계를 수행합니다.
텍스트 편집기에서 다음 텍스트를 입력하고 저장하여 /etc/udev/rules.d/99-nfs.rules 파일을 만듭니다.
SUBSYSTEM=="bdi" \ , ACTION=="add" \ , PROGRAM="/usr/bin/awk -v bdi=$kernel 'BEGIN{ret=1} {if ($4 == bdi) {ret=0}} END{exit ret}' /proc/fs/nfsfs/volumes" \ , ATTR{read_ahead_kb}="15360"콘솔에서 udevadm 명령을 슈퍼 사용자로 실행하고 규칙 파일 및 기타 데이터베이스를 다시 로드하여 udev 규칙을 적용합니다. udev가 새 파일을 인식하도록 하려면 이 명령을 한 번만 실행하면 됩니다.
sudo udevadm control --reload
Nconnect
Nconnect는 PaaS(Platform as a Service)의 복원력을 유지하면서 클라이언트와 NFSv4.1용 Azure Premium Files 서비스 간의 더 많은 TCP 연결을 사용할 수 있도록 하여 성능을 크게 개선하는 클라이언트 쪽 Linux 탑재 옵션입니다.
nconnect의 이점
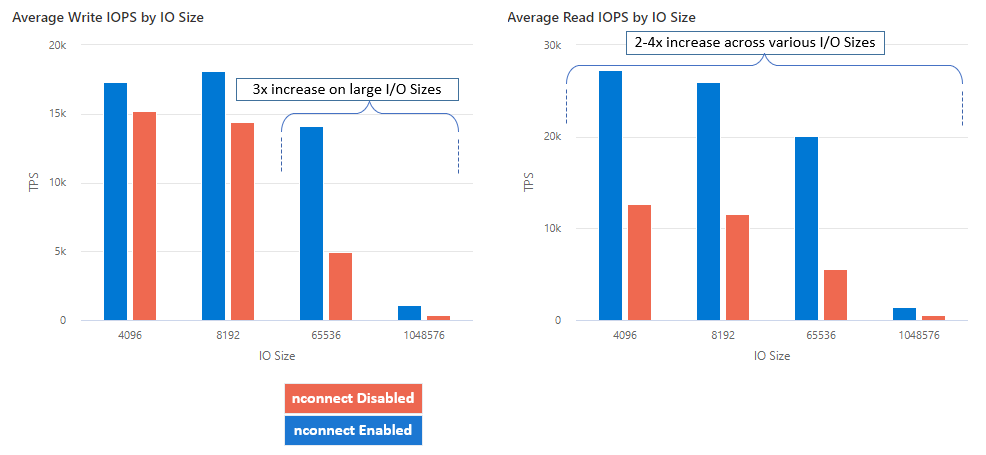
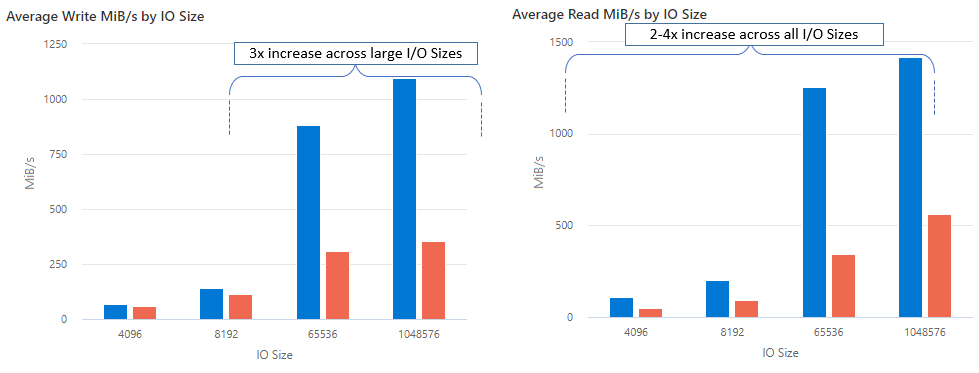
nconnect를 사용하면 더 적은 수의 클라이언트 머신을 사용하여 성능을 크게 개선함으로써 총 소유 비용(TCO)을 줄일 수 있습니다. Nconnect는 단일 또는 여러 클라이언트를 사용하고 하나 이상의 NIC에서 여러 TCP 채널을 사용하여 성능을 향상합니다. nconnect를 사용하지 않을 경우 가장 큰 프리미엄 Azure 파일 공유 프로비전 크기에서 제공하는 대역폭 스케일링 제한(10GiB/s)을 달성하려면 약 20대의 클라이언트 머신이 필요합니다. nconnect를 사용하면 6~7개 클라이언트만 사용하여 이러한 제한을 달성할 수 있습니다. 이는 IOPS 및 처리량을 대규모로 크게 개선하면서 컴퓨팅 비용을 거의 70% 절감하는 것입니다(표 참조).
| 메트릭(작업) | I/O 크기 | 성능 향상 |
|---|---|---|
| IOPS(쓰기) | 64K, 1024K | 3x |
| IOPS(읽기) | 모든 I/O 크기 | 2~4배 |
| 처리량(쓰기) | 64K, 1024K | 3x |
| 처리량(읽기) | 모든 I/O 크기 | 2~4배 |
필수 조건
- 최신 Linux 배포판은
nconnect를 완벽하게 지원합니다. 이전 Linux 배포의 경우 Linux 커널 버전이 5.3 이상인지 확인합니다. - 탑재당 구성은 프라이빗 엔드포인트를 통해 스토리지 계정당 단일 파일 공유를 사용하는 경우에만 지원됩니다.
nconnect의 성능 영향
대규모 Linux 클라이언트에서 NFS Azure 파일 공유와 함께 nconnect 탑재 옵션을 사용할 때 다음과 같은 성능 결과를 달성했습니다. 이러한 결과를 달성하는 방법에 대한 자세한 내용은 성능 테스트 구성을 참조하세요.
nconnect에 대한 권장 사항
nconnect에서 최상의 결과를 얻으려면 다음 권장 사항을 따르세요.
nconnect=4 설정
Azure Files는 최대 설정인 16까지 nconnect 설정을 지원하지만 최적의 설정인 nconnect=4로 탑재 옵션을 구성하는 것이 좋습니다. 현재 nconnect의 Azure Files 구현을 위한 채널을 4개 이상 설정하는 것은 이득은 없습니다. 실제로 단일 클라이언트에서 단일 Azure 파일 공유 채널이 4개를 초과하면 TCP 네트워크 포화로 인해 성능에 부정적인 영향을 줄 수 있습니다.
신중하게 가상 머신 크기 조정
워크로드 요구 사항에 따라 클라이언트 머신의 크기를 올바르게 조정하여 예상 네트워크 대역폭에 의해 제한되지 않도록 하는 것이 중요합니다. 예상되는 네트워크 처리량을 달성하기 위해 여러 NIC가 필요하지 않습니다. Azure Files에서 범용 VM을 사용하는 것이 일반적이지만 워크로드 요구 사항 및 지역 가용성에 따라 다양한 VM 유형을 사용할 수 있습니다. 자세한 내용은 Azure VM 선택기를 참조하세요.
큐 깊이를 64보다 작거나 같게 유지
큐 깊이는 스토리지 리소스가 서비스할 수 있는 보류 중인 I/O 요청 수입니다. 최적의 큐 깊이인 64를 초과하지 않는 것이 좋습니다. 64를 초과하면 더 이상 성능이 향상되지 않습니다. 자세한 내용은 큐 깊이를 참조하세요.
Nconnect 탑재당 구성
워크로드에서 단일 클라이언트와 다른 nconnect 설정이 포함된 하나 이상의 스토리지 계정으로 여러 공유를 탑재해야 하는 경우 퍼블릭 엔드포인트를 통해 탑재할 때 이러한 설정이 유지된다고 보장할 수 없습니다. 탑재당 구성은 시나리오 1에 설명된 대로 프라이빗 엔드포인트를 통해 스토리지 계정당 단일 Azure 파일 공유를 사용하는 경우에만 지원됩니다.
시나리오 1: (지원됨) 여러 스토리지 계정이 있는 프라이빗 엔드포인트를 통해 nconnect 탑재당 구성
- StorageAccount.file.core.windows.net = 10.10.10.10
- StorageAccount2.file.core.windows.net = 10.10.10.11
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount2.file.core.windows.net:/StorageAccount2/FileShare1
시나리오 2: (지원되지 않음) 퍼블릭 엔드포인트를 통해 nconnect 탑재당 구성
- StorageAccount.file.core.windows.net = 52.239.238.8
- StorageAccount2.file.core.windows.net = 52.239.238.7
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare2Mount StorageAccount2.file.core.windows.net:/StorageAccount2/FileShare1
참고 항목
스토리지 계정이 다른 IP 주소로 확인되더라도 퍼블릭 엔드포인트가 정적 주소가 아니므로 해당 주소가 유지된다고 보장할 수 없습니다.
시나리오 3: (지원되지 않음) 단일 스토리지 계정에 여러 공유가 있는 프라이빗 엔드포인트를 통해 nconnect 탑재당 구성
- StorageAccount.file.core.windows.net = 10.10.10.10
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare2Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare3
성능 테스트 구성
다음 리소스 및 벤치마킹 도구를 사용하여 이 문서에 설명된 결과를 달성하고 측정했습니다.
- 단일 클라이언트: 단일 NIC를 사용하는 Azure Virtual Machine(DSv4 시리즈)
- OS: Linux(Ubuntu 20.40)
- NFS 스토리지: Azure Files 프리미엄 파일 공유(프로비전된 30TiB,
nconnect=4설정)
| 크기 | vCPU | 메모리 | 임시 스토리지(SSD) | 최대 데이터 디스크 수 | 최대 NIC 수 | 예상 네트워크 대역폭 |
|---|---|---|---|---|---|---|
| Standard_D16_v4 | 16 | 64GiB | 원격 스토리지 전용 | 32 | 8 | 12,500Mbps |
벤치마킹 도구 및 테스트
FIO(Flexible I/O Tester) 벤치마크 및 스트레스/하드웨어 검증에 사용되는 무료 오픈 소스 디스크 I/O 도구를 사용했습니다. FIO를 설치하려면 FIO 추가 정보 파일의 이진 파일 패키지 섹션을 따라 선택한 플랫폼용으로 설치합니다.
이러한 테스트는 임의 I/O 액세스 패턴에 중점을 두지만 순차 I/O를 사용할 때도 비슷한 결과를 얻을 수 있습니다.
높은 IOPS: 100% 읽기
4k I/O 크기 - 임의 읽기 - 64 큐 깊이
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=4k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
8k I/O 크기 - 임의 읽기 - 64 큐 깊이
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=8k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
높은 처리량: 100% 읽기
64k I/O 크기 - 임의 읽기 - 64 큐 깊이
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=64k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
1024k I/O 크기 - 100% 임의 읽기 - 64 큐 깊이
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=1024k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
높은 IOPS: 100% 쓰기
4k I/O 크기 - 100% 임의 쓰기 - 64 큐 깊이
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=4k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
8k I/O 크기 - 100% 임의 쓰기 - 64 큐 깊이
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=8k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
높은 처리량: 100% 쓰기
64k I/O 크기 - 100% 임의 쓰기 - 64 큐 깊이
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=64k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
1024k I/O 크기 - 100% 임의 쓰기 - 64 큐 깊이
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=1024k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
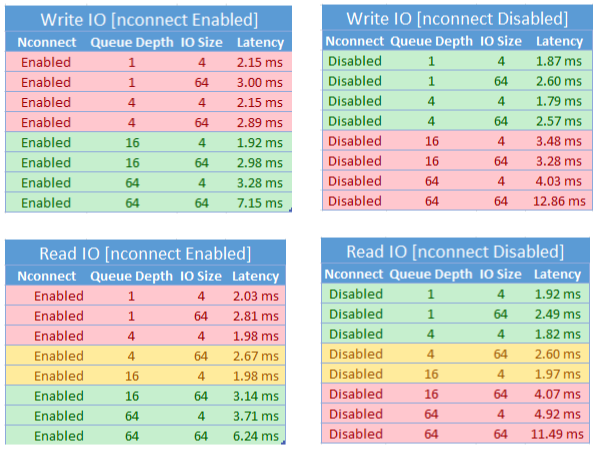
nconnect에 대한 성능 고려 사항
nconnect 탑재 옵션을 사용하는 경우 다음과 같은 특징이 있는 워크로드를 면밀히 평가해야 합니다.
- 단일 스레드이거나 낮은 큐 깊이(16 미만)를 사용하는 대기 시간이 중요한 쓰기 워크로드
- 작은 I/O 크기와 함께 단일 스레드이거나 낮은 큐 깊이를 사용하는 대기 시간 중요한 읽기 워크로드
모든 워크로드에 대규모 IOPS 또는 전체 성능이 필요한 것은 아닙니다. 소규모 워크로드의 경우 nconnect는 의미가 없을 수 있습니다. 다음 표를 사용하여 nconnect가 워크로드에 유리한지 여부를 결정합니다. 녹색으로 강조 표시된 시나리오는 권장되지만 빨간색으로 강조 표시된 시나리오는 권장되지 않습니다. 노란색으로 강조 표시된 항목은 중립입니다.
참고 항목
- 탑재 지침은 Linux에 NFS 파일 공유 탑재를 참조하세요.
- 종합적인 탑재 옵션 목록은 Linux NFS man 페이지를 참조하세요.
- 대기 시간, IOPS, 처리량, 기타 성능 개념에 대한 자세한 내용은 Azure Files 성능 이해를 참조하세요.