Microsoft Syntex 구조화된 문서 처리 모델 학습
Syntex에서 모델 만들기의 지침에 따라 콘텐츠 센터에서 구조화되거나 자유형 문서 처리 모델을 만듭니다. 또는 로컬 SharePoint 사이트에서 모델 만들기의 지침에 따라 로컬 사이트에 모델을 만듭니다. 그런 다음 이 문서를 사용하여 모델을 학습합니다.

구조화되거나 자유형 문서 처리 모델을 학습하려면 다음 단계를 수행합니다.
1단계: 문서 추가 및 분석
구조화된 문서 처리 모델 또는 자유형 문서 처리 모델을 만든 후 추출할 정보 선택 페이지가 열립니다. 여기서는 AI 모델이 문서에서 추출할 정보(예: 이름, 주소 또는 금액)를 나열 합니다.
참고
사용할 예제 파일을 찾으면 문서 처리 모델 입력 문서 요구 사항 및 최적화 팁을 참조하세요.
먼저 추출할 정보 선택 페이지에서 모델이 추출하도록 가르칠 필드와 테이블을 정의합니다. 자세한 단계는 추출할 필드 및 테이블 정의를 참조하세요.
모델에서 처리할 문서 레이아웃 컬렉션을 원하는 만큼 만들 수 있습니다. 자세한 단계는 컬렉션별로 문서 그룹화를 참조하세요.
컬렉션을 만들고 각각에 대해 5개 이상의 예제 파일을 추가한 후 Syntex의 AI Builder는 업로드된 문서를 검사하여 필드와 테이블을 검색합니다. 이 프로세스는 일반적으로 몇 초 정도 걸립니다. 분석이 완료되면 문서에 태그를 지정할 수 있습니다.
2단계: 필드 및 테이블 태그 지정
모델이 추출하려는 필드와 테이블 데이터를 이해하도록 가르치려면 문서에 태그를 지정해야 합니다. 자세한 단계는 문서에 태그 지정을 참조하세요.
3단계: 모델 학습 및 게시
모델을 만들고 교육한 후에는 이를 게시하고 SharePoint에서 사용할 수 있습니다. 모델을 게시하려면 게시를 선택합니다. 자세한 단계는 문서 처리 모델 학습 및 게시를 참조하세요.
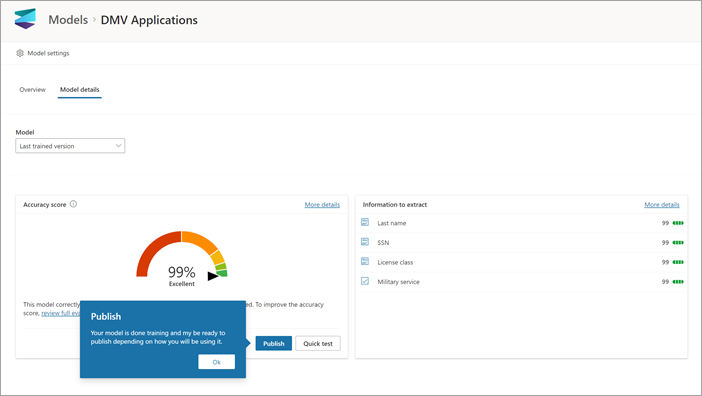
모델이 게시되면 모델 홈페이지로 이동합니다. 그런 다음 문서 라이브러리에 모델을 적용하는 옵션이 있습니다.
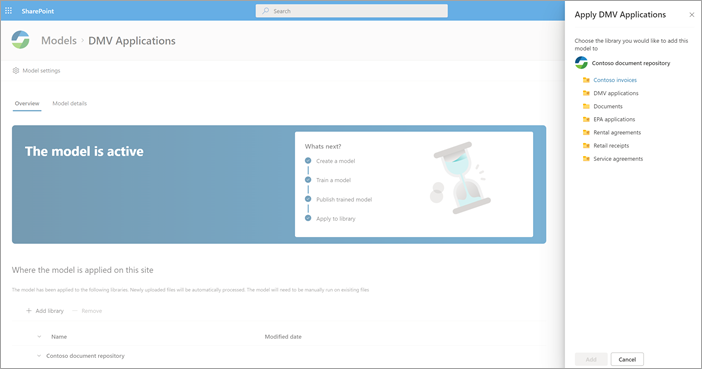
4단계: 모델 사용
문서 라이브러리 모델 보기에서 선택한 필드가 열로 표시된 것을 확인합니다.
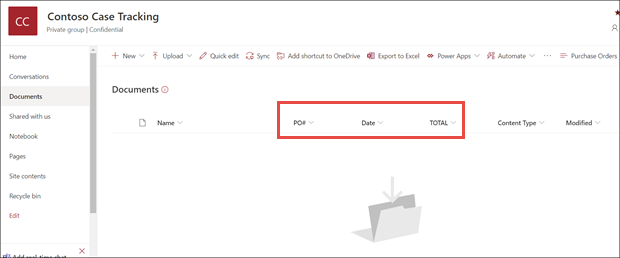
문서 옆에 있는 정보 링크는 양식 처리 모델이 문서 라이브러리에 적용되었음을 나타냅니다.
문서 라이브러리에 파일 업로드 모델이 콘텐츠 유형으로 식별하는 모든 파일은 보기에 있는 파일을 나열하고 추출한 데이터를 열에 표시합니다.
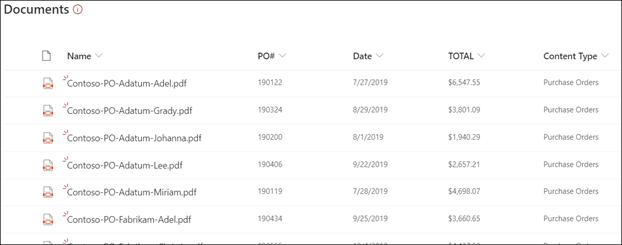
참고
구조화된 문서 처리 모델 또는 자유형 문서 처리 모델과 비정형 문서 처리 모델이 동일한 라이브러리에 적용되는 경우 파일은 비정형 문서 처리 모델 및 해당 모델에 대해 학습된 추출기를 사용하여 분류됩니다. 문서 처리 모델과 일치하는 빈 열이 있는 경우 추출된 값을 사용하여 열이 채워집니다.
분류 날짜 필드
사용자 지정 모델이 문서 라이브러리에 적용되면 분류 날짜 필드가 라이브러리 스키마에 포함됩니다. 기본적으로 이 필드는 비어 있습니다. 그러나 문서가 모델에 의해 처리되고 분류되면 이 필드는 완료 날짜 타임스탬프로 업데이트됩니다.
모델이 분류 날짜로 스탬프를 찍으면 Syntex가 파일 흐름을 처리한 후 전자 메일 보내기를 사용하여 SharePoint 문서 라이브러리의 모델에 의해 새 파일이 처리되고 분류되었음을 사용자에게 알릴 수 있습니다.
흐름을 실행하려면 다음을 수행합니다.
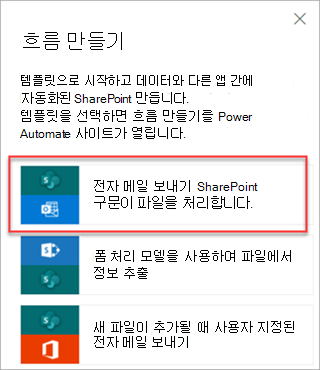
파일을 선택한 다음Power Automate>흐름 만들기통합>을 선택합니다.
흐름 만들기 패널에서 Syntex에서 파일을 처리한 후 이메일 보내기를 선택합니다.
흐름을 사용하여 정보 추출
중요
이 섹션의 정보는 최신 Syntex 릴리스에는 적용되지 않습니다. 이전 릴리스에서 만든 양식 처리 모델에 대해서만 참조로 남아 있습니다. 최신 릴리스에서는 더 이상 기존 파일을 처리하도록 흐름을 구성할 필요가 없습니다.
구조화된 문서 처리 모델 또는 자유형 문서 처리 모델이 적용된 라이브러리에서 선택한 파일 또는 파일 일괄 처리를 처리하는 데 두 가지 흐름을 사용할 수 있습니다.
문서 처리 모델을 사용하여 이미지 또는 PDF 파일에서 정보 추출 - 문서 처리 모델을 실행하여 선택한 이미지 또는 PDF 파일에서 텍스트를 추출하는 데 사용합니다. 선택한 파일을 한 번에 하나만 지원하고 PDF 파일 및 이미지 파일(.png, .jpg 및 .jpeg)만 지원합니다. 흐름을 실행하려면 파일을 선택한 다음 정보추출자동화를> 선택합니다.
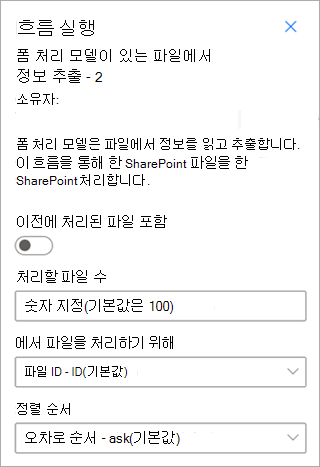
문서 처리 모델을 사용하여 파일에서 정보 추출 - 문서 처리 모델과 함께 사용하여 파일 일괄 처리에서 정보를 읽고 추출합니다. 한 번에 최대 5,000개 SharePoint 파일을 처리합니다. 이 흐름을 실행할 때 설정할 수 있는 특정 매개 변수가 있습니다. 다음을 수행할 수 있습니다.
- 이전에 처리된 파일을 포함할지 여부를 선택합니다(기본값은 이전에 처리된 파일을 포함하지 않음).
- 처리할 파일 수를 선택합니다(기본값은 100개 파일).
- 파일을 처리할 순서를 지정합니다(파일 ID, 파일 이름, 파일 생성 시간 또는 마지막으로 수정한 시간별 선택 사항).
- 순서를 정렬할 방법을 지정합니다(오름차순 또는 내림차순).
참고
문서 처리 모델 흐름이 있는 이미지 또는 PDF 파일에서 정보 추출은 문서 처리 모델이 연결된 라이브러리에서 자동으로 사용할 수 있습니다. 문서 처리 모델 흐름이 있는 파일에서 정보 추출은 필요한 경우 라이브러리에 추가해야 하는 템플릿입니다.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기