중요합니다
Azure Cosmos DB for PostgreSQL은 사용 중지 경로에 있으며 새 프로젝트에는 더 이상 권장되지 않습니다. 대신 다음 두 서비스 중 하나를 사용합니다.
PostgreSQL 워크로드의 경우: Azure Database For PostgreSQL의 탄력적 클러스터 기능을 사용하여 오픈 소스 Citus 확장에 포함된 수평 스케일 아웃 및 분산 PostgreSQL 기능을 사용합니다.
NoSQL 워크로드의 경우 99.999% SLA(가용성 서비스 수준 계약), 인스턴트 자동 크기 조정 및 여러 지역에서 자동 장애 조치(failover)를 포함하는 분산 데이터베이스 솔루션에 대해 NoSQL용 Azure Cosmos DB를 사용합니다.
공동 배치는 동일한 노드에 관련 정보를 함께 저장하는 것을 의미합니다. 필요한 모든 데이터를 네트워크 트래픽 없이 사용할 수 있다면, 쿼리는 훨씬 더 빠르게 처리될 수 있습니다. 관련 데이터를 서로 다른 노드에 공동 배치함으로써 각 노드에서 쿼리를 효율적으로 병렬 실행할 수 있습니다.
해시 분산 테이블에서 데이터를 함께 배치
Azure Cosmos DB for PostgreSQL에서 배포 열의 값 해시가 분할된 데이터베이스의 해시 범위 내에 있으면 행이 분할된 데이터베이스에 저장됩니다. 동일한 해시 범위를 가진 분할 데이터베이스는 항상 같은 노드에 위치합니다. 배포 열 값이 같은 행은 항상 테이블의 동일한 노드에 있습니다. 해시 분산 테이블은 행 기반 분할 개념으로도 불립니다. 스키마 기반 분할 방식을 사용하면 분산 스키마에 속한 테이블들이 동일한 위치에 함께 배치됩니다.
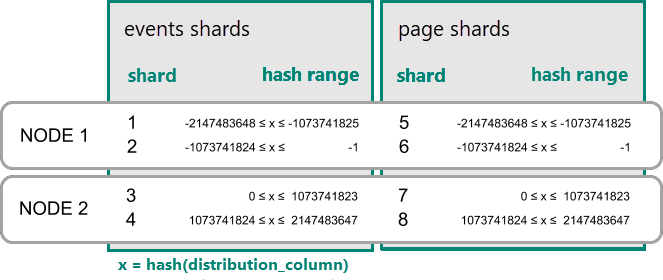
공동 배치의 실제 예제
다중 테넌트 웹 분석 SaaS 플랫폼에 포함될 수 있는 다음 테이블들을 검토해 보세요.
CREATE TABLE event (
tenant_id int,
event_id bigint,
page_id int,
payload jsonb,
primary key (tenant_id, event_id)
);
CREATE TABLE page (
tenant_id int,
page_id int,
path text,
primary key (tenant_id, page_id)
);
이제 고객 대시보드 내에서 실행되는 쿼리들에 대한 응답 처리를 진행하고자 합니다. 예제 쿼리는 ‘테넌트 6에서 ‘/blog’로 시작하는 모든 페이지에 대해 지난주 방문 횟수를 반환하라’는 요청입니다.
데이터가 단일 PostgreSQL 서버에 있는 경우 SQL에서 제공하는 다양한 관계형 작업 집합을 통해 쿼리를 쉽게 표현할 수 있습니다.
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
이 쿼리의 작업 집합 이 메모리에 적재될 수 있다면, 단일 서버 테이블이 적절한 솔루션이 될 수 있습니다. Azure Cosmos DB for PostgreSQL을 사용하여 데이터 모델을 크기 조정할 수 있는 기회를 살펴보겠습니다.
ID로 테이블 배포
테넌트의 수와 각 테넌트별 저장 데이터가 증가하면서 단일 서버 쿼리의 성능이 저하되기 시작합니다. 작업 집합이 메모리 용량을 초과하면서 CPU가 병목 현상을 일으키게 됩니다.
이 경우 Azure Cosmos DB for PostgreSQL을 사용하여 여러 노드에 데이터를 분할할 수 있습니다. 분할을 결정하기 위해 가장 먼저 고려해야 할 핵심 요소는 배포 열입니다. event 테이블의 event_id 과 page_id 테이블의 page 를 활용하여 기본적인 선택 항목부터 시작해 보겠습니다.
-- naively use event_id and page_id as distribution columns
SELECT create_distributed_table('event', 'event_id');
SELECT create_distributed_table('page', 'page_id');
여러 작업자에게 데이터가 분산되어 있을 때는 단일 PostgreSQL 노드에서처럼 조인 작업을 실행하는 것이 불가능합니다. 그 대신, 아래 두 가지 쿼리를 실행해야 합니다.
-- (Q1) get the relevant page_ids
SELECT page_id FROM page WHERE path LIKE '/blog%' AND tenant_id = 6;
-- (Q2) get the counts
SELECT page_id, count(*) AS count
FROM event
WHERE page_id IN (/*…page IDs from first query…*/)
AND tenant_id = 6
AND (payload->>'time')::date >= now() - interval '1 week'
GROUP BY page_id ORDER BY count DESC LIMIT 10;
이후 애플리케이션에서 두 단계의 결과를 통합하여 처리해야 합니다.
쿼리 실행을 위해서는 여러 노드에 분산된 데이터베이스의 데이터를 참조해야 합니다.
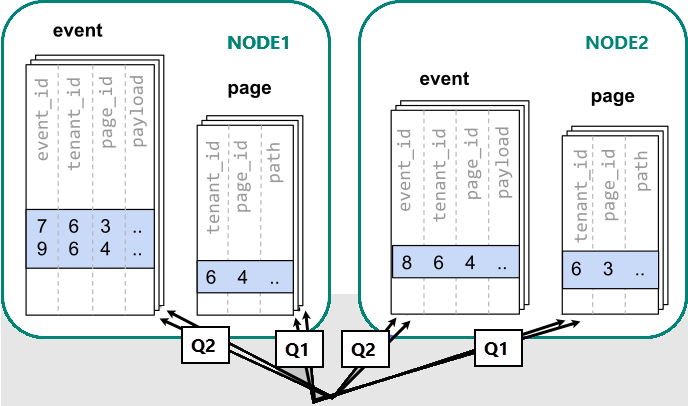
하지만 데이터를 배포하는 과정에서 다음과 같은 치명적인 한계가 드러납니다.
- 여러 쿼리를 실행하면서 각각의 분할된 데이터베이스를 쿼리해야 하는 오버헤드
- Q1이 클라이언트에 많은 행을 반환함으로 인한 오버헤드
- Q2가 커집니다.
- 여러 단계로 쿼리를 작성해야 하므로 애플리케이션을 변경해야 합니다.
데이터가 분산되어 있으므로 쿼리를 병렬 처리할 수 있습니다. 분할된 데이터베이스를 쿼리할 때의 오버헤드보다 각 쿼리에서 처리해야 할 작업량이 훨씬 클 때만 유용합니다.
테넌트별 테이블 배포
Azure Cosmos DB for PostgreSQL에서 배포 열 값이 같은 행은 동일한 노드에 배치됩니다. 테이블을 처음부터 새로 생성할 때 tenant_id 을 배포 열로 지정할 수 있습니다.
-- co-locate tables by using a common distribution column
SELECT create_distributed_table('event', 'tenant_id');
SELECT create_distributed_table('page', 'tenant_id', colocate_with => 'event');
이제 Azure Cosmos DB for PostgreSQL은 수정 없이 원래 단일 서버 쿼리에 응답할 수 있습니다(Q1).
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
tenant_id로 필터링 및 조인하기 때문에 Azure Cosmos DB for PostgreSQL에서 특정 테넌트에 대한 데이터가 포함된 공동 배치된 분할된 데이터베이스 집합을 사용하여 전체 쿼리에 응답할 수 있음을 알고 있습니다. 단일 PostgreSQL 노드만으로도 쿼리에 대한 응답을 한 번에 처리할 수 있습니다.
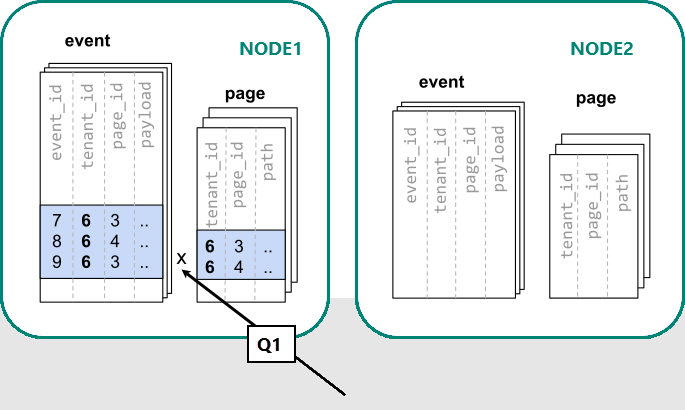
쿼리와 테이블 스키마를 수정하여 고유 제약 조건 및 조인 조건에 테넌트 ID를 포함시켜야 할 때가 있습니다. 이러한 변경 작업은 대체로 복잡하지 않은 편입니다.
다음 단계
- 다중 테넌트 튜토리얼을 참고하여 테넌트 데이터를 공동 배치하는 방법을 알아보세요.