Visual Studio Code용 Spark & Hive Tools 사용
Visual Studio Code용 Apache Spark & Hive Tools를 사용하는 방법을 알아봅니다. 도구를 사용하여 Apache Hive 일괄 작업, 대화형 Hive 쿼리 및 Apache Spark용 PySpark 스크립트를 만들고 제출합니다. 먼저 Visual Studio Code에서 Spark & Hive Tools를 설치하는 방법을 설명합니다. 그런 다음 Spark & Hive Tools에 작업을 제출하는 방법을 살펴보겠습니다.
Spark & Hive Tools는 Visual Studio Code가 지원하는 플랫폼에 설치할 수 있습니다. 다른 플랫폼의 사전 요구 사항은 다음과 같습니다.
필수 조건
이 문서의 단계를 완료하려면 다음 항목이 필요합니다.
- Azure HDInsight 클러스터를 만듭니다. 클러스터를 만들려면 HDInsight 시작을 참조하세요. 또는 Apache Livy 엔드포인트를 지원하는 Spark 및 Hive 클러스터를 사용합니다.
- Visual Studio Code
- Mono. Mono는 Linux 및 macOS에만 필요합니다.
- Visual Studio Code용 PySpark 대화형 환경
- 로컬 디렉터리. 이 문서에서는 C:\HD\HDexample을 사용합니다.
Spark & Hive Tools 설치
사전 요구 사항을 충족하면 다음 단계에 따라 Visual Studio Code용 Spark & Hive Tools를 설치할 수 있습니다.
Visual Studio Code를 엽니다.
메뉴 모음에서 보기>확장으로 이동합니다.
검색 상자에 Spark & Hive를 입력합니다.
검색 결과에서 Spark & Hive Tools를 선택하고 설치를 선택합니다.

필요한 경우 다시 로드를 선택합니다.
작업 폴더 열기
작업 폴더를 열고 Visual Studio Code에서 파일을 만들려면 다음 단계를 수행합니다.
메뉴 모음에서 파일>폴더 열기...>C:\HD\HDexample로 이동한 다음, 폴더 선택 단추를 선택합니다. 왼쪽 탐색기 뷰에 폴더가 표시됩니다.
탐색기 보기에서 HDexample 폴더를 선택한 다음, 작업 폴더 옆에 있는 새 파일 아이콘을 선택합니다.
.hql(Hive 쿼리) 또는.py(Spark 스크립트) 파일 확장명을 사용하여 새 파일의 이름을 지정합니다. 이 예제에서는 HelloWorld.hql을 사용합니다.
Azure 환경 설정
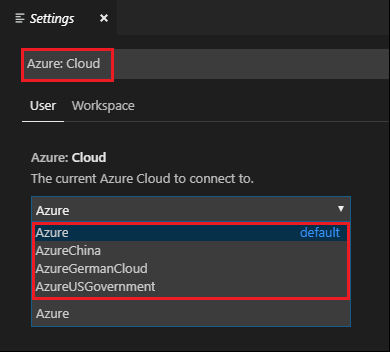
국가 클라우드 사용자의 경우 다음 단계에 따라 먼저 Azure 환경을 설정하고 Azure: Sign In 명령을 사용하여 Azure에 로그인합니다.
파일 > 기본 설정 > 설정으로 이동합니다.
다음 문자열을 검색합니다. Azure: Cloud.
목록에서 국가 클라우드를 선택합니다.
Azure 계정에 연결
Visual Studio Code에서 클러스터에 스크립트를 제출하기 전에 사용자는 Azure 구독에 로그인하거나 HDInsight 클러스터에 연결할 수 있습니다. Ambari 사용자 이름/암호 또는 ESP 클러스터용 도메인 조인 자격 증명을 사용하여 HDInsight 클러스터에 연결합니다. 다음 단계에 따라 Azure에 연결합니다.
메뉴 모음에서 보기>명령 팔레트...로 이동한 다음, Azure: Sign In을 입력합니다.
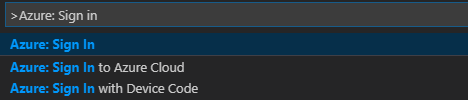
로그인 지침에 따라 Azure에 로그인합니다. 연결되면 Visual Studio Code 창 아래쪽의 상태 표시줄에 Azure 계정 이름이 표시됩니다.
클러스터 연결
연결: Azure HDInsight
Apache Ambari 관리형 사용자 이름을 사용하여 정상적인 클러스터를 연결하거나, 도메인 사용자 이름(예: user1@contoso.com)을 사용하여 Enterprise Security Pack 보안 Hadoop 클러스터를 연결할 수 있습니다.
메뉴 모음에서 보기>명령 팔레트...로 이동한 다음, Spark / Hive: Link a Cluster를 입력합니다.

연결된 클러스터 유형 Azure HDInsight를 선택합니다.
HDInsight 클러스터 URL을 입력합니다.
Ambari 사용자 이름을 입력합니다. 기본값은 admin입니다.
Ambari 암호를 입력합니다.
클러스터 유형 선택
클러스터의 표시 이름을 설정합니다(선택 사항).
확인을 위해 출력 뷰를 검토합니다.
참고 항목
클러스터가 Azure 구독 및 연결된 클러스터 모두에 로그인되어 있으면, 연결된 사용자 이름 및 암호가 사용됩니다.
연결: 일반 Livy 엔드포인트
메뉴 모음에서 보기>명령 팔레트...로 이동한 다음, Spark / Hive: Link a Cluster를 입력합니다.
연결된 클러스터 유형 일반 Livy 엔드포인트를 선택합니다.
일반 Livy 엔드포인트를 입력합니다. 예: http://10.172.41.42:18080.
인증 형식 기본 또는 없음을 선택합니다. 기본을 선택하는 경우:
Ambari 사용자 이름을 입력합니다. 기본값은 admin입니다.
Ambari 암호를 입력합니다.
확인을 위해 출력 뷰를 검토합니다.
클러스터 나열
메뉴 모음에서 보기>명령 팔레트...로 이동한 다음, Spark / Hive: List Cluster를 입력합니다.
원하는 구독을 선택합니다.
출력 뷰를 검토합니다. 이 뷰에는 연결된 클러스터(또는 클러스터)와 더불어 Azure 구독을 사용하는 모든 클러스터가 표시됩니다.

기본 클러스터를 설정합니다.
이전에 설명한 HDexample 폴더를 닫은 경우 다시 엽니다.
이전에 만든 HelloWorld.hql 파일을 선택합니다. 스크립트 편집기에서 열립니다.
스크립트 편집기를 마우스 오른쪽 단추로 클릭한 다음 Spark / Hive: Set Default Cluster를 선택합니다.
아직 Azure 계정에 연결하거나 클러스터를 연결하지 않은 경우 연결합니다.
현재 스크립트 파일의 기본 클러스터로 사용할 클러스터를 선택합니다. 도구에서 .VSCode\settings.json 구성 파일이 자동으로 업데이트됩니다.

대화형 Hive 쿼리, Hive 일괄 처리 스크립트 제출
Spark & Hive Tools for Visual Studio Code를 사용하면 대화형 Hive 쿼리 및 Hive 일괄 처리 스크립트를 클러스터에 제출할 수 있습니다.
이전에 설명한 HDexample 폴더를 닫은 경우 다시 엽니다.
이전에 만든 HelloWorld.hql 파일을 선택합니다. 스크립트 편집기에서 열립니다.
다음 코드를 복사하여 Hive 파일에 붙여넣은 후 파일을 저장합니다.
SELECT * FROM hivesampletable;아직 Azure 계정에 연결하거나 클러스터를 연결하지 않은 경우 연결합니다.
스크립트 편집기를 마우스 오른쪽 단추로 클릭하고 Hive: Interactive를 선택하여 쿼리를 제출하거나, Ctrl + Alt + I 바로 가기 키를 사용합니다. Hive: Batch를 선택하여 스크립트를 제출하거나 Ctrl + Alt + H 바로 가기 키를 사용합니다.
기본 클러스터를 지정하지 않은 경우 클러스터를 선택합니다. 도구를 사용하면 바로 가기 메뉴를 사용하여 전체 스크립트 파일 대신 코드 블록을 제출할 수도 있습니다. 잠시 후 새 탭에 쿼리 결과가 표시됩니다.

결과 패널: 전체 결과를 CSV, JSON 또는 Excel 파일로 로컬 경로에 저장하거나 여러 줄을 선택할 수 있습니다.
메시지 패널: 줄 번호를 선택하면 실행 중인 스크립트의 첫 번째 줄로 이동합니다.
대화형 PySpark 쿼리 제출
Pyspark 대화형의 필수 구성 요소
여기서 Jupyter 확장 버전(ms-jupyter): v2022.1.1001614873 및 Python 확장 버전(ms-python): v2021.12.1559732655, python 3.6.x 및 3.7.x는 HDInsight 대화형 PySpark 쿼리에 필요합니다.
사용자가 PySpark 대화형 작업을 수행할 수 있는 방법은 다음과 같습니다.
PY 파일에서 PySpark 대화형 명령 사용
PySpark 대화형 명령을 사용하여 쿼리를 제출하려면 다음 단계를 수행합니다.
이전에 설명한 HDexample 폴더를 닫은 경우 다시 엽니다.
이전 단계에 따라 새 HelloWorld.py 파일을 만듭니다.
다음 코드를 복사하여 스크립트 파일에 붙여넣습니다.
from operator import add from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName('hdisample') \ .getOrCreate() lines = spark.read.text("/HdiSamples/HdiSamples/FoodInspectionData/README").rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) coll = counters.collect() sortedCollection = sorted(coll, key = lambda r: r[1], reverse = True) for i in range(0, 5): print(sortedCollection[i])PySpark/Synapse Pyspark 커널을 설치하라는 메시지가 창의 오른쪽 아래 모서리에 표시됩니다. 설치 단추를 클릭하여 PySpark/Synapse Pyspark 설치를 진행하거나 건너뛰기 단추를 클릭하여 이 단계를 건너뜁니다.

나중에 설치해야 하는 경우 파일>기본 설정>설정으로 이동한 다음, 설정에서 HDInsight: Pyspark 설치 건너뛰기 사용을 선택 취소합니다.

4단계에서 설치에 성공하면 창 오른쪽 아래 모서리에 “PySpark Pyspark가 설치되었습니다”라는 메시지 상자가 표시됩니다. 다시 로드 단추를 클릭하여 창을 다시 로드합니다.

메뉴 모음에서 보기>명령 팔레트...로 이동하거나 Shift + Ctrl + P 바로 가기 키를 사용하여 Python: Select Interpreter to start Jupyter Server를 입력합니다.

아래 Python 옵션을 선택합니다.

메뉴 모음에서 보기>명령 팔레트...로 이동하거나 Shift + Ctrl + P 바로 가기 키를 사용하여 Developer: Reload Window를 입력합니다.

아직 Azure 계정에 연결하거나 클러스터를 연결하지 않은 경우 연결합니다.
모든 코드를 선택하고 스크립트 편집기를 마우스 오른쪽 단추로 클릭한 다음, Spark: PySpark Interactive / Synapse: Pyspark Interactive를 선택하여 쿼리를 제출합니다.

기본 클러스터를 지정하지 않은 경우 클러스터를 선택합니다. 몇 분 후에 Python 대화형 결과가 새 탭에 나타납니다. PySpark를 클릭하여 커널을 PySpark / Synapse Pyspark로 전환하고 코드가 성공적으로 실행됩니다. Synapse Pyspark 커널로 전환하려는 경우 Azure Portal에서 자동 설정을 사용하지 않도록 설정하는 것이 좋습니다. 그렇지 않으면 클러스터의 절전 모드를 해제하고 처음 사용할 때 synapse 커널을 설정하는 데 시간이 오래 걸릴 수 있습니다. 도구를 사용하면 바로 가기 메뉴를 사용하여 전체 스크립트 파일 대신 코드 블록을 제출할 수도 있습니다.

%%Info를 입력한 다음 Shift+Enter를 눌러 작업 정보를 봅니다(선택 사항).

이 도구는 Spark SQL 쿼리도 지원합니다.

#%% 주석을 사용하여 PY 파일에서 대화형 쿼리 수행
Py 코드 앞에 #%%를 추가하여 Notebook 환경을 가져옵니다.

셀 실행을 클릭합니다. 몇 분 후에 Python 대화형 결과가 새 탭에 나타납니다. PySpark를 클릭하여 커널을 PySpark/Synapse PySpark로 전환한 다음, 셀 실행을 다시 클릭하면 코드가 성공적으로 실행됩니다.

Python 확장의 IPYNB 지원 활용
명령 팔레트의 명령을 사용하거나 작업 영역에서 새 .ipynb 파일을 생성하여 Jupyter Notebook을 만들 수 있습니다. 자세한 내용은 Visual Studio Code에서 Jupyter Notebook 작업을 참조하세요.
셀 실행 단추를 클릭하고 프롬프트에 따라 기본 Spark 풀을 설정한(Notebook을 열기 전에 매번 기본 클러스터/풀을 설정하는 것이 좋음) 다음, 창을 다시 로드합니다.

PySpark를 클릭하여 커널을 PySpark / Synapse Pyspark로 전환한 다음, 셀 실행을 클릭하면 잠시 후 결과가 표시됩니다.

참고 항목
Synapse Pyspark 설치 오류의 경우 다른 팀에서 종속성을 더 이상 유지 관리하지 않으므로 이 오류도 더 이상 유지 관리되지 않습니다. 대화형 Synapse Pyspark를 사용하려는 경우 대신 Azure Synapse Analytics를 사용하도록 전환하세요. 그리고 그것은 장기적인 변화입니다.
PySpark 일괄 작업 제출
이전에 설명한 HDexample 폴더를 닫은 경우 다시 엽니다.
이전 단계에 따라 새 BatchFile.py 파일을 만듭니다.
다음 코드를 복사하여 스크립트 파일에 붙여넣습니다.
from __future__ import print_function import sys from operator import add from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv').rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' '))\ .map(lambda x: (x, 1))\ .reduceByKey(add) output = counts.collect() for (word, count) in output: print("%s: %i" % (word, count)) spark.stop()아직 Azure 계정에 연결하거나 클러스터를 연결하지 않은 경우 연결합니다.
스크립트 편집기를 마우스 오른쪽 단추로 클릭한 다음, Spark: PySpark Batch 또는 Synapse: PySpark Batch*를 선택합니다.
PySpark 작업을 제출할 클러스터/spark 풀을 선택합니다.

Python 작업을 제출하면 Visual Studio Code의 출력 창에 제출 로그가 표시됩니다. Spark UI URL 및 Yarn UI URL도 표시됩니다. Apache Spark 풀에 일괄 작업을 제출하는 경우 Spark 기록 UI URL 및 Spark 작업 애플리케이션 UI URL도 표시됩니다. 웹 브라우저에서 URL을 열어 작업 상태를 추적할 수 있습니다.
HIB(HDInsight Identity Broker)와 통합
ID 브로커(HIB)를 사용하여 HDInsight ESP 클러스터에 연결
Azure 구독에 로그인하는 일반적인 단계에 따라 ID 브로커(HIB)를 사용하여 HDInsight ESP 클러스터에 연결할 수 있습니다. 로그인한 후에는 Azure Explorer에 클러스터 목록이 표시됩니다. 자세한 지침은 HDInsight 클러스터에 연결을 참조하세요.
ID 브로커(HID)를 사용하여 HDInsight ESP 클러스터에서 Hive/PySpark 작업 실행
hive 작업을 실행하기 위해 일반적인 단계에 따라 ID 브로커(HIB)를 사용하여 HDInsight ESP 클러스터에 작업을 제출할 수 있습니다. 자세한 내용은 대화형 Hive 쿼리 및 Hive 일괄 처리 스크립트 제출을 참조하세요.
대화형 PySpark 작업을 실행하기 위해 일반적인 단계에 따라 ID Broker(HIB)를 사용하여 HDInsight ESP 클러스터에 작업을 제출할 수 있습니다. 대화형 PySpark 쿼리 제출을 참조하세요.
PySpark 일괄 작업을 실행하기 위해 일반적인 단계에 따라 ID 브로커(HIB)를 사용하여 HDInsight ESP 클러스터에 작업을 제출할 수 있습니다. 자세한 지침은 PySpark 일괄 작업 제출을 참조하세요.
Apache Livy 구성
Apache Livy 구성이 지원됩니다. 이는 작업 영역 폴더의 .VSCode\settings.json 파일에서 구성할 수 있습니다. 현재, Livy 구성은 Python 스크립트만 지원합니다. 자세한 내용은 Livy 추가 정보를 참조하세요.
방법 1
- 메뉴 모음에서 파일>기본 설정>설정으로 이동합니다.
- 검색 설정 상자에 HDInsight Job Submission: Livy Conf를 입력합니다.
- 관련 검색 결과에 대해 settings.json에서 편집을 선택합니다.
방법 2
파일을 제출합니다. 그러면 .vscode 폴더가 작업 폴더에 자동으로 추가됩니다. .vscode\settings.json을 선택하여 Livy 구성을 볼 수 있습니다.
프로젝트 설정:

참고 항목
driverMemory 및 executorMemory 설정에서 값과 단위를 설정합니다. 예를 들면 1g 또는 1,024m입니다.
지원되는 Livy 구성:
POST/일괄 처리
요청 본문
name description type 파일 실행할 애플리케이션이 포함된 파일 경로(필수) proxyUser 작업을 실행할 때 가장할 사용자 문자열 className 애플리케이션 Java/Spark 주 클래스 문자열 args 애플리케이션의 명령줄 인수 문자열 목록 jars 이 세션에서 사용할 jar 문자열 목록 pyFiles 이 세션에서 사용할 Python 파일 문자열 목록 files 이 세션에서 사용할 파일 문자열 목록 driverMemory 드라이버 프로세스에 사용할 메모리 크기 문자열 driverCores 드라이버 프로세스에 사용할 코어 수 정수 executorMemory 실행기 프로세스당 사용할 메모리 크기 문자열 executorCores 각 실행기에 사용할 코어 수 정수 numExecutors 이 세션에서 시작할 실행기 수 정수 archives 이 세션에서 사용할 보관 파일 문자열 목록 queue 제출할 YARN 큐의 이름 문자열 name 이 세션의 이름 문자열 conf Spark 구성 속성 키=값 맵 응답 본문 만들어진 일괄 처리 개체입니다.
name description type ID 세션 ID 정수 appId 이 세션의 애플리케이션 ID String appInfo 자세한 애플리케이션 정보 키=값 맵 log 로그 줄 문자열 목록 state 일괄 처리 상태 문자열 참고 항목
할당된 Livy 구성은 스크립트를 제출할 때 출력 창에 표시됩니다.
탐색기에서 Azure HDInsight와 통합
Azure HDInsight 탐색기를 통해 클러스터의 Hive 테이블을 직접 미리 볼 수 있습니다.
Azure 계정에 아직 연결하지 않은 경우 연결합니다.
맨 왼쪽 열에서 Azure 아이콘을 선택합니다.
왼쪽 창에서 AZURE: HDINSIGHT를 펼칩니다. 구독 및 클러스터가 나열됩니다.
클러스터를 확장하여 Hive 메타데이터 데이터베이스 및 테이블 스키마를 확인합니다.
Hive 테이블을 마우스 오른쪽 단추로 클릭합니다. 예를 들면 hivesampletable입니다. 미리 보기를 선택합니다.

미리 보기 결과 창이 열립니다.

결과 패널
전체 결과를 CSV, JSON 또는 Excel 파일로 로컬 경로에 저장하거나 여러 줄을 선택할 수 있습니다.
메시지 패널
테이블의 행 수가 100보다 큰 경우 “Hive 테이블에 첫 번째 100개 행이 표시됩니다”라는 메시지가 표시됩니다.
테이블의 행 수가 100보다 작거나 같으면 “Hive 테이블에 60개 행이 표시됩니다”라는 메시지가 표시됩니다.
테이블에 콘텐츠가 없는 경우 다음 메시지가 표시됩니다. “
0 rows are displayed for Hive table.”참고 항목
Linux에서 xclip을 설치하여 copy-table 데이터를 사용하도록 설정합니다.

추가 기능
Visual Studio Code용 Spark & Hive는 다음과 같은 기능도 지원합니다.
IntelliSense 자동 완성. 키워드, 메서드, 변수, 기타 프로그래밍 요소에 대한 제안이 표시됩니다. 다음과 같이 개체 형식마다 다른 아이콘으로 표시됩니다.

IntelliSense 오류 표식. 언어 서비스는 Hive 스크립트의 편집 오류에 밑줄을 긋습니다.
구문 강조 표시. 언어 서비스는 변수, 키워드, 데이터 형식, 함수, 기타 프로그래밍 요소를 구분하기 위해 각기 다른 색을 사용합니다.

독자 전용 역할
클러스터에 대한 읽기 전용 역할이 할당된 사용자는 HDInsight 클러스터에 작업을 제출하거나 Hive 데이터베이스를 볼 수 없습니다. Azure Portal에서 클러스터 관리자에게 문의하여 HDInsight 클러스터 운영자로 역할을 업그레이드하세요. 유효한 Ambari 자격 증명이 있는 경우 다음 지침을 사용하여 클러스터를 수동으로 연결할 수 있습니다.
HDInsight 클러스터 찾기
클러스터에 대한 읽기 전용 역할이 있는 경우 Azure HDInsight 탐색기를 선택하여 HDInsight 클러스터를 펼치면 클러스터를 연결하라는 메시지가 표시됩니다. Ambari 자격 증명을 사용하여 클러스터에 연결하려면 다음 방법을 사용합니다.
HDInsight 클러스터에 작업 제출
클러스터에 대한 읽기 전용 역할인 경우 HDInsight 클러스터에 작업을 제출하면 클러스터를 연결하라는 메시지가 표시됩니다. Ambari 자격 증명을 사용하여 클러스터에 연결하려면 다음 단계를 사용합니다.
클러스터에 연결
유효한 Ambari 사용자 이름을 입력합니다.
유효한 암호를 입력합니다.


참고 항목
Spark / Hive: List Cluster를 사용하여 연결된 클러스터를 확인할 수 있습니다.
Azure Data Lake Storage Gen2
Data Lake Storage Gen2 계정 찾기
Data Lake Storage Gen2 계정을 확장하려면 Azure HDInsight 탐색기를 선택합니다. Azure 계정에 Gen2 스토리지에 대한 액세스 권한이 없는 경우 스토리지 액세스 키를 입력하라는 메시지가 표시됩니다. 액세스 키가 올바르면 Data Lake Storage Gen2 계정이 자동으로 확장됩니다.
Data Lake Storage Gen2를 사용하여 HDInsight 클러스터에 작업 제출
Data Lake Storage Gen2를 사용하여 HDInsight 클러스터에 작업을 제출합니다. Azure 계정에 Gen2 스토리지에 대한 쓰기 권한이 없는 경우 스토리지 액세스 키를 입력하라는 메시지가 표시됩니다. 액세스 키가 올바르면 작업이 성공적으로 제출됩니다.

참고 항목
Azure Portal에서 스토리지 계정에 대한 액세스 키를 가져올 수 있습니다. 자세한 내용은 스토리지 계정 액세스 키 관리를 참조하세요.
클러스터 연결 해제
메뉴 모음에서 보기>명령 팔레트로 이동한 다음, Spark / Hive: Unlink a Cluster를 입력합니다.
연결을 해제할 클러스터를 선택합니다.
확인하려면 출력 보기를 참조하세요.
로그아웃
메뉴 모음에서 보기>명령 팔레트로 이동한 다음, Azure: 로그아웃을 입력합니다.
알려진 문제
Synapse PySpark 설치 오류입니다.
Synapse PySpark 설치 오류의 경우 다른 팀에서 종속성을 더 이상 유지 관리하지 않으므로 이 오류는 더 이상 유지 관리되지 않습니다. 대화형 Synapse PySpark를 사용하려는 경우 대신 Azure Synapse Analytics를 사용하세요. 그리고 그것은 장기적인 변화입니다.

다음 단계
Visual Studio Code용 Spark & Hive 사용을 보여 주는 비디오는 Spark & Hive for Visual Studio Code(Visual Studio Code용 Spark & Hive)를 참조하세요.