Azure HDInsight에서 지원하는 고가용성 서비스
분석 구성 요소에 대한 최적의 가용성 수준을 제공하기 위해 HDInsight는 중요한 서비스의 HA(고가용성)를 보장하기 위한 고유한 아키텍처로 개발되었습니다. 이 아키텍처의 일부 구성 요소는 Microsoft에서 자동 장애 조치(failover)를 제공하기 위해 개발했습니다. 다른 구성 요소는 특정 서비스를 지원하기 위해 배포되는 표준 Apache 구성 요소입니다. 이 문서에서는 HDInsight의 HA 서비스 모델 아키텍처, HDInsight에서 HA 서비스의 장애 조치를 지원하는 방법, 다른 서비스 중단에서 복구하기 위한 모범 사례를 설명합니다.
참고 항목
이 문서에는 Microsoft에서 더 이상 사용하지 않는 용어인 슬레이브라는 용어에 대한 참조가 포함되어 있습니다. 소프트웨어에서 용어가 제거되면 이 문서에서 해당 용어가 제거됩니다.
고가용성 인프라
HDInsight는 아래의 네 가지 기본 서비스가 자동 장애 조치 기능을 포함하는 고가용성인지 확인하는 사용자 지정 인프라를 제공합니다.
- Apache Ambari 서버
- Apache YARN용 애플리케이션 타임라인 서버
- Hadoop MapReduce용 작업 기록 서버
- Apache Livy
이 인프라는 다양한 서비스 및 소프트웨어 구성 요소로 구성되며, 그중 일부는 Microsoft에서 디자인되었습니다. 다음 구성 요소는 HDInsight 플랫폼에 고유합니다.
- 슬레이브 장애 조치 컨트롤러
- 마스터 장애 조치 컨트롤러
- 슬레이브 고가용성 서비스
- 마스터 고가용성 서비스
오픈 소스 Apache 안정성 구성 요소에서 지원하는 다른 고가용성 서비스도 있습니다. 이 구성 요소는 HDInsight 클러스터에도 있습니다.
- HDFS(Hadoop File System) NameNode
- YARN ResourceManager
- HBase Master
다음 섹션에서는 이 서비스가 함께 작동하는 방법에 관한 자세한 정보를 제공합니다.
HDInsight 고가용성 서비스
Microsoft는 HDInsight 클러스터의 다음 표에서 네 가지 Apache 서비스에 대한 지원을 제공합니다. Apache의 구성 요소에서 지원하는 고가용성 서비스와 구별하기 위해 이를 ‘HDInsight HA 서비스’라고 합니다.
| 서비스 | 클러스터 노드 | 클러스터 유형 | 목적 |
|---|---|---|---|
| Apache Ambari 서버 | 활성 헤드 노드 | 모두 | 클러스터를 모니터링하고 관리합니다. |
| Apache YARN용 애플리케이션 타임라인 서버 | 활성 헤드 노드 | Kafka를 제외한 모두 | 클러스터에서 실행되는 YARN 작업에 관한 디버깅 정보를 유지 관리합니다. |
| Hadoop MapReduce용 작업 기록 서버 | 활성 헤드 노드 | Kafka를 제외한 모두 | MapReduce 작업의 디버깅 데이터를 유지 관리합니다. |
| Apache Livy | 활성 헤드 노드 | Spark | REST 인터페이스를 통해 Spark 클러스터와 쉽게 상호 작용할 수 있습니다. |
참고 항목
현재 HDInsight ESP(Enterprise Security Package) 클러스터는 Ambari 서버 고가용성만 제공합니다. 애플리케이션 타임라인 서버, 작업 기록 서버, Livy는 모두 헤드 노드 0에서만 실행되며 Ambari가 장애 조치되는 경우 헤드 노드 1로 장애 조치되지 않습니다. 애플리케이션 타임라인 데이터베이스는 Ambari SQL 서버가 아닌 헤드 노드 0에도 있습니다.
아키텍처
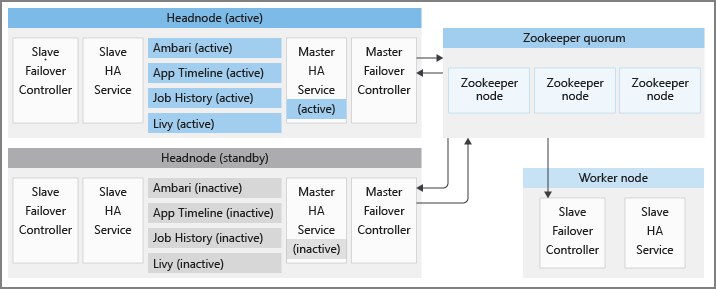
각 HDInsight 클러스터에는 활성 모드와 대기 모드별로 헤드 노드 두 개가 있습니다. HDInsight HA 서비스는 헤드 노드에서만 실행됩니다. 이 서비스는 항상 활성 헤드 노드에서 실행되며 대기 헤드 노드에서 중지되고 유지 관리 모드로 전환되어야 합니다.
HA 서비스의 올바른 상태를 유지 관리하고 빠른 장애 조치를 제공하기 위해 HDInsight는 분산 애플리케이션의 조정 서비스인 Apache ZooKeeper를 이용하여 활성 헤드 노드 선택을 수행합니다. 또한 HDInsight는 HDInsight HA 서비스의 장애 조치 절차를 조정하는 몇 가지 백그라운드 Java 프로세스를 프로비저닝합니다. 해당 서비스는 마스터 장애 조치(failover) 컨트롤러, 슬레이브 장애 조치 컨트롤러, master-ha-service 및 slave-ha-service입니다.
Apache ZooKeeper
Apache ZooKeeper는 분산 애플리케이션을 위한 고성능 조정 서비스입니다. 프로덕션에서 ZooKeeper는 일반적으로 ZooKeeper 서버의 복제된 그룹이 쿼럼을 형성하는 복제 모드에서 실행됩니다. 각 HDInsight 클러스터에는 세 개의 ZooKeeper 서버가 쿼럼을 형성할 수 있는 세 개의 ZooKeeper 노드가 있습니다. HDInsight에는 서로 병렬로 실행되는 두 개의 ZooKeeper 쿼럼이 있습니다. 한 쿼럼은 HDInsight HA 서비스가 실행되어야 하는 클러스터의 활성 헤드 노드를 결정합니다. 다른 쿼럼은 이후 섹션에 설명된 대로 Apache에서 제공하는 HA 서비스를 조정하는 데 사용됩니다.
슬레이브 장애 조치 컨트롤러
슬레이브 장애 조치 컨트롤러는 HDInsight 클러스터의 모든 노드에서 실행됩니다. 이 컨트롤러는 각 노드에서 Ambari 에이전트 및 slave-ha-service를 시작하는 작업을 처리합니다. 활성 헤드 노드에 관한 첫 번째 ZooKeeper 쿼럼을 주기적으로 쿼리합니다. 활성 및 대기 헤드 노드가 변경되면 슬레이브 장애 조치(failover) 컨트롤러가 다음을 수행합니다.
- 호스트 구성 파일을 업데이트합니다.
- Ambari 에이전트를 다시 시작합니다.
slave-ha-service는 대기 헤드 노드에서 HDInsight HA 서비스(Ambari 서버 제외)를 중지하는 작업을 처리합니다.
마스터 장애 조치 컨트롤러
마스터 장애 조치 컨트롤러는 두 헤드 노드에서 모두 실행됩니다. 두 마스터 장애 조치 컨트롤러는 모두 첫 번째 ZooKeeper 쿼럼과 통신하여 실행 중인 헤드 노드를 활성 헤드 노드로 지정합니다.
예를 들어, 헤드 노드 0의 마스터 장애 조치 컨트롤러가 선택되는 경우 다음 변경 내용이 발생됩니다.
- 헤드 노드 0이 활성화됩니다.
- 마스터 장애 조치 컨트롤러는 헤드 노드 0에서 Ambari 서버 및 master-ha-service를 시작합니다.
- 다른 마스터 장애 조치 컨트롤러는 헤드 노드 1에서 Ambari 서버 및 master-ha-service를 중지합니다.
master-ha-service는 활성 헤드 노드에서만 실행되고, 대기 헤드 노드에서 HDInsight HA 서비스(Ambari 서버 제외)를 중지하고, 활성 헤드 노드에서 해당 서비스를 시작합니다.
장애 조치 프로세스
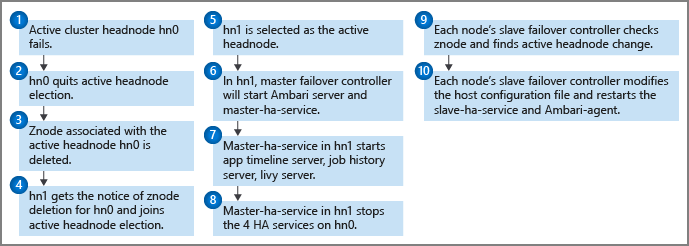
성능 상태 모니터는 마스터 장애 조치 컨트롤러와 함께 각 헤드 노드에서 실행되어 ZooKeeper 쿼럼에 하트비트 알림을 보냅니다. 헤드 노드는 이 시나리오에서 HA 서비스로 간주됩니다. 성능 상태 모니터는 각 고가용성 서비스가 정상 상태이고 리더십 선택에 조인할 준비가 되었는지 확인합니다. 해당하는 경우 이 헤드 노드는 선택에서 경쟁합니다. 해당하지 않는 경우 다시 준비될 때까지 선택을 끝냅니다.
대기 헤드 노드가 리더십을 획득하고 활성화된 경우(예: 이전 활성 노드에 실패가 있는 경우) 해당 마스터 장애 조치 컨트롤러에서는 모든 HDInsight HA 서비스를 시작합니다. 또한 마스터 장애 조치 컨트롤러는 다른 헤드 노드에서 이러한 서비스를 중지합니다.
서비스가 다운되거나 비정상 상태인 경우와 같은 HDInsight HA 서비스 실패의 경우 마스터 장애 조치 컨트롤러는 헤드 노드 상태에 따라 서비스를 자동으로 다시 시작하거나 중지해야 합니다. 사용자는 두 헤드 노드에서 모두 HDInsight HA 서비스를 수동으로 시작하면 안 됩니다. 대신, 자동 또는 수동 장애 조치를 사용하여 서비스 복구를 지원할 수 있습니다.
의도치 않은 수동 개입
HDInsight HA 서비스는 활성 헤드 노드에서만 실행해야 하며 필요한 경우 자동으로 다시 시작됩니다. 개별 HA 서비스에는 자체 성능 상태 모니터가 없으므로 개별 서비스 수준에서 장애 조치를 트리거할 수 없습니다. 장애 조치는 서비스 수준이 아닌 노드 수준에서 보장됩니다.
일부 알려진 문제
대기 헤드 노드에서 HA 서비스를 수동으로 시작하면 다음 장애 조치가 발생할 때까지 HA 서비스가 중지되지 않습니다. HA 서비스가 두 헤드 노드에서 모두 실행 중인 경우 Ambari UI에 액세스할 수 없고, Ambari가 오류를 throw하고, YARN, Spark, Oozie 작업이 중단될 수 있는 몇 가지 잠재적인 문제가 있습니다.
활성 헤드 노드의 HA 서비스가 중지되면 다음 장애 조치가 발생하거나 마스터 장애 조치 컨트롤러/master-ha-service가 다시 시작될 때까지 HA 서비스가 다시 시작되지 않습니다. 활성 헤드 노드에서 하나 이상의 HA 서비스가 중지되는 경우, 특히 Ambari 서버가 중지되는 경우에는 Ambari UI에 액세스할 수 없으며 다른 잠재적 문제에는 YARN, Spark, Oozie 작업 실패가 포함됩니다.
Apache 고가용성 서비스
Apache는 HDInsight 클러스터에서도 사용할 수 있는 HDFS NameNode, YARN ResourceManager 및 HBase Master에 대한 고가용성을 제공합니다. HDInsight HA 서비스와 달리 이 서비스는 ESP 클러스터에서 지원됩니다. Apache HA 서비스는 두 번째 ZooKeeper 쿼럼(위 섹션에서 설명됨)과 통신하여 활성/대기 상태를 선택하고 자동 장애 조치를 수행합니다. 다음 섹션에서는 해당 서비스의 작동 방식을 자세히 설명합니다.
HDFS(Hadoop Distributed File System) NameNode
Apache Hadoop 2.0 이상을 기반으로 하는 HDInsight 클러스터는 NameNode 고가용성을 제공합니다. 헤드 노드에서 실행되는 두 개의 NameNode는 자동 장애 조치를 위해 구성됩니다. NameNode는 ZKFailoverController를 통해 Zookeeper와 통신하여 활성/대기 상태를 선택합니다. ZKFailoverController는 두 헤드 노드에서 모두 실행되며 마스터 장애 조치 컨트롤러와 동일한 방식으로 작동합니다.
두 번째 Zookeeper 쿼럼은 첫 번째 쿼럼과 독립적이므로 활성 NameNode는 활성 헤드 노드에서 실행되지 않을 수 있습니다. 활성 NameNode가 데드 또는 비정상 상태이면 대기 NameNode가 선택되고 활성화됩니다.
YARN ResourceManager
Apache Hadoop 2.4 이상을 기반으로 하는 HDInsight 클러스터는 YARN ResourceManager 고가용성을 지원합니다. 각각 헤드 노드 0과 헤드 노드 1에서 실행되는 두 개의 ResourceManager인 rm1과 rm2가 있습니다. NameNode처럼 YARN ResourceManager도 자동 장애 조치를 위해 구성됩니다. 현재 활성 ResourceManager가 다운되거나 응답하지 않는 경우 또 다른 ResourceManager가 활성화되도록 자동으로 선택됩니다.
YARN ResourceManager는 포함된 ActiveStandbyElector를 오류 탐지기 및 리더 선택기로 사용합니다. HDFS NameNode와 달리 YARN ResourceManager에는 별도의 ZKFC 디먼이 필요하지 않습니다. 활성 ResourceManager는 Apache Zookeeper에 상태를 기록합니다.
YARN ResourceManager의 고가용성은 NameNode 및 기타 HDInsight HA 서비스와 독립적입니다. 활성 ResourceManager는 활성 NameNode가 실행 중인 헤드 노드나 활성 헤드 노드에서 실행되지 않을 수 있습니다. YARN ResourceManager 고가용성에 관한 자세한 내용은 ResourceManager 고가용성을 참조하세요.
HBase Master
HDInsight HBase 클러스터는 HBase Master 고가용성을 지원합니다. 헤드 노드에서 실행되는 다른 HA 서비스와 달리 HBase Master는 세 개의 Zookeeper 노드에서 실행됩니다. 이러한 Zookeeper 노드 중 하나는 활성 마스터이고 다른 두 개는 대기 노드입니다. NameNode처럼 HBase Master는 리더 선택을 위해 Apache Zookeeper와 조율되며 현재 활성 마스터에 문제가 있는 경우 자동 장애 조치를 수행합니다. 언제든지 활성 HBase Master는 하나만 있습니다.