Music Generation with Azure Machine Learning
This post is authored by Erika Menezes, Software Engineer at Microsoft.
Using deep learning to learn feature representations from near-raw input has been shown to outperform traditional task-specific feature engineering in multiple domains in several situations, including in object recognition, speech recognition and text classification. With the recent advancements in neural networks, deep learning has been gaining popularity in computational creativity tasks such as music generation. There has been great progress in this field via projects such as Magenta, an open-source project focused on creating machine learning projects for art and music, from the Google Brain team, and Flow Machines, who have released an entire AI generated pop album. For those of you who are curious about music generation, you can find additional resources here.
This goal of our work is to provide data scientists who are new to the field of music generation guidance on how to create deep learning models for music generation. As a sample, here is music that was generated by training an LSTM model.
In this post, we show you how to build a deep learning model for simple music generation using the Azure Machine Learning (AML) Workbench for experimentation.
Here are the most important components for a deep learning model for music generation:
- Dataset: The data used for training the model. In this work we will use the scale-chords dataset.
- Input Representation: A meaningful vector representation of music notes. In this work we will use a piano roll representation.
- Model Architecture: The deep learning model architecture for learning the task of predicting some set of musical notes, given an input of preceding musical notes. This work uses a Sequence-to-Sequence model using multi-layered Long Short-Term Memory (LSTM) to achieve this.
Dataset
Music is available in a variety of digital audio formats ranging from raw audio (WAV) to more semantic representations such as MIDI (Musical Instrument Digital Interface), ABC, and sheet music. MIDI data already contains the information needed to feed the Deep Neural Network, we just need to transform it into an appropriate numeric representation to train the model. In next section discusses the details of this transformation.
For this work we will use the scale-chords dataset from here. Download the dataset (free small pack) that contains 156 scale chords files in MIDI format. Let's take a closer look at MIDI.
MIDI
MIDI is a communications protocol for electronic musical instruments. A Python representation of a MIDI file looks something like this:

MIDI represents time in 'ticks' which essentially represent delta times, i.e. each event's tick is relative to the previous one. Each MIDI file's header contains the resolution of that file which gives us the number of ticks per beat. The MIDI file consists of one or more tracks that further consist of event messages such as the following:
- SetTempoEvent: Indicates the tempo in 8-bit words.
- NoteOnEvent: Indicates that a note has been pressed or turned on.
- NoteOffEvent: Indicates that a note has been released or turned off.
- EndOfTrackEvent: Indicates that the track has ended.
Music Theory 101
- Beat: Basic unit of time in music, a.k.a. quarter note.
- Note: Pitch or frequency of the note played. E.g. note 60 in MIDI is C5 on the piano, which is 261.625 Hz.
- Tempo: Expressed as Beats per minute (BPM) = Quarter notes per minute (QPM)
Microseconds per quarter note (MPQN) = MICROSECONDS_PER_MINUTE / BPM.
Input Representation
Input Representation is a crucial component of any music generation system. To feed the MIDI files to the Neural Network, we transform the MIDI to a piano roll representation. A piano roll is simply a 2D matrix of notes vs. time, where the black squares represent a note being pressed at that point in time. We use the MIDO python library to achieve this. The figure below shows a sample piano roll for notes in one octave.
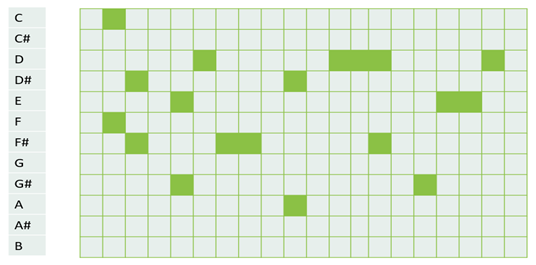
To transform the MIDI file shown above into a piano roll we need to quantize the MIDI events by time. The important trick to quantize the MIDI events is to understand how to convert MIDI ticks to absolute time. To do this we simply multiply the tempo (beats per minute) by the resolution (ticks per beat) and that gives us the ticks per second.
Model Architecture
Recurrent Neural Networks (RNN) are well suited for sequence prediction tasks as they can memorize long-range dependencies from input sequences using recurrent or looped connections. LSTMs are a special type of RNN that have multiplicative gates that enable them to retain memory for even longer sequences, making them useful for learning the sequential patterns present in musical data.
With this reasoning we decided to use an LSTM Sequence-to-Sequence model as shown in the figure below.
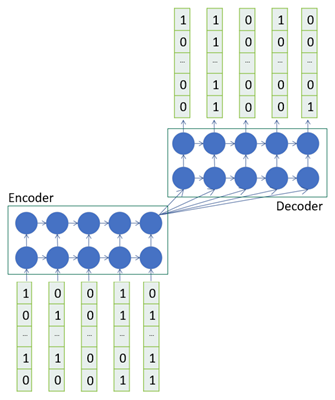
A Sequence-to-Sequence model (Seq2Seq) is made up of an Encoder (encode input) and Decoder (decode output) to convert sequences from one domain, such as sentences in English, to sequences in another domain, such as the same sentences translated into French. This has been commonly used for machine translation or for freeform question answering. As in language translation, in music, the notes played during a given time period depend on several preceding notes, and Sequence-to-Sequence models are able to generate output sequences after seeing the entire input.
In the figure shown above, we train the network to generate some length of music notes given some preceding notes. In order to create the training set we use a sliding window over the piano roll. Consider the case where we have a piano roll of dimensions 12x10, where 12 is the number of notes in one octave and 10 is the number of columns in a piano roll, where each column represents some absolute time. Assuming a sliding window of 5, the first 5 columns are fed to the encoder as the input and the next 5 are the target which the model tries to learn. Since we are generating polyphonic music, i.e. multiple notes being on at the same time, this is a multi-label classification problem and hence we use the binary cross entropy loss.
Once we are done training our network, we can carry out testing that will generate some music for us. In this case, test data is fed to the encoder and the outputs from the decoder represent the music generated by the model!
It should be noted that one limitation of Sequence-to-Sequence models is that they get overwhelmed when given very long inputs, and they need other sources of context such as attention in order to focus on specific parts of the input automatically. We will not be going over this aspect as it's beyond the scope of this post.
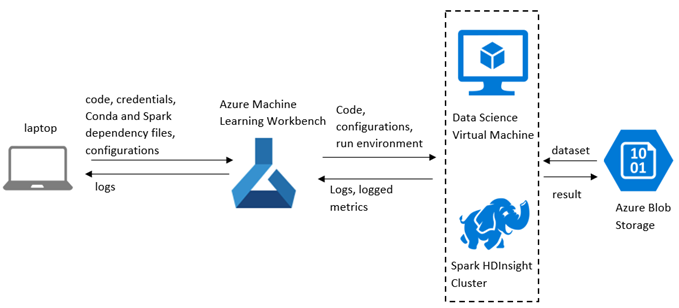
From a higher-level perspective, the flow of data through the system looks like this:

The next section walks you through how to set this up with Azure ML Workbench.
Getting Started with Azure Machine Learning
Azure Machine Learning provides data scientists and ML developers with a toolset for data wrangling and experimentation and it includes the following:
- AML Workbench. See setup and installation documentation.
- AML Experimentation Service. See configuration documentation.
- AML Model Management. See manage and deploy documentation.
We provisioned Data Science VMs (DSVMs) with GPUs and used the remote Docker execution environment provided by Azure ML Workbench (see details and more information on execution targets) for training models. Azure ML allows you to track your run history and model metrics through the Azure ML Logging API which helps us compare different experiments and compare results visually.
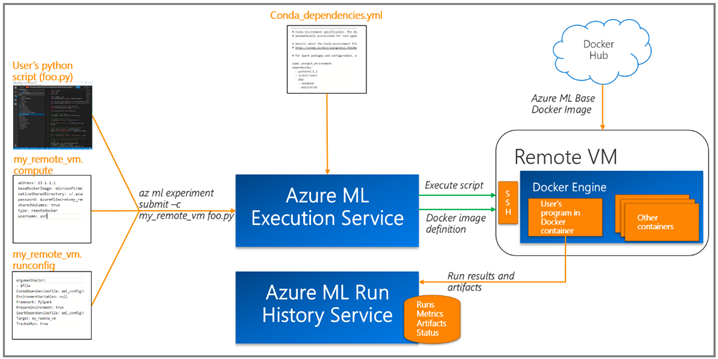
Training a Music Generation Model
The Sequence-to-Sequence model described in the previous section is implemented using Keras. In this section we are going to focus on the training setup.
Using Azure ML Workbench for Training on a Remote VM
The Azure ML Workbench provides an easy way to scale out to environments such as a Data Science VM with GPUs that enables faster training for deep learning models and isolated, reproducible, and consistent runs for all your experiments. The code for this project can be found here.
Step1: Setup remote VM as execution target
az ml computetarget attach --name "my_dsvm" --address "my_dsvm_ip_address" --username "my_name" --password "my_password" --type remotedocker
Step 2: Configure my_dsvm.compute
baseDockerImage: microsoft/mmlspark:plus-gpu-0.7.91
nvidiaDocker: true
Step 3: Configure my_dsvm.runconfig
EnvironmentVariables:
"STORAGE_ACCOUNT_NAME":
"STORAGE_ACCOUNT_KEY":
Framework: Python
PrepareEnvironment: true
We use Azure storage for storing training data, pre-trained models and generated music. The storage account credentials are provided as EnvironmentVariables.
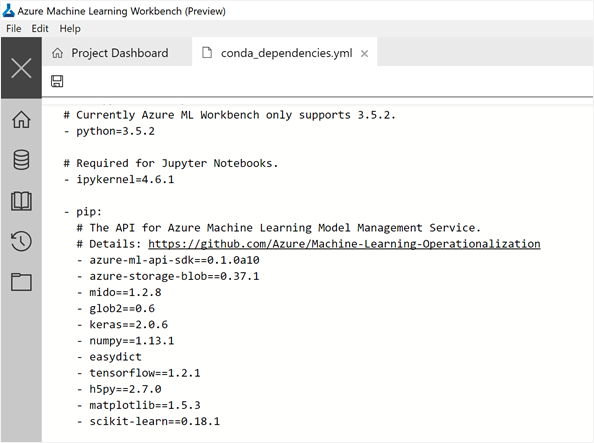
Step 4: Conda_dependencies.yml
Step 5: Prepare the remote machine
az ml experiment –c prepare m_dsvm
Step 6: Run the experiment
az ml experiment submit -c my_dsvm Musicgeneration/train.py
Evaluation Workflow
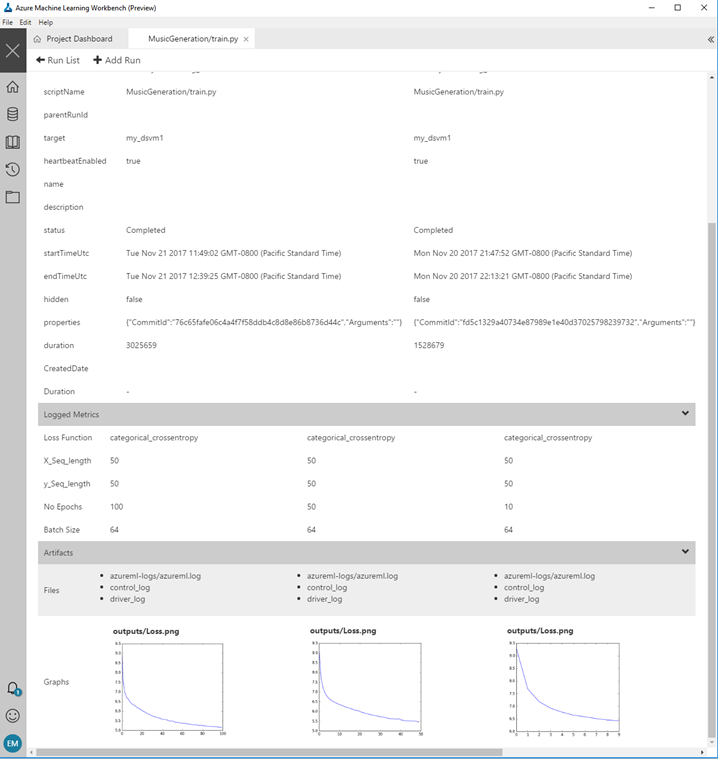
Comparing Runs
As part of experimenting with machine learning models, we would like to compare effects of different batch sizes and model hyper-parameters. We can visualize this in the run history for different epoch sizes and compare different runs with custom outputs as shown below.

The next figure below shows how we can compare runs for 10, 50 and 100 epochs and look at the corresponding loss curves.
Scoring = Music Generation!
Now you can generate music by loading the models created in the training step and calling model.predict() to generate some music. The code for this is in MusicGeneration/score.py.
az ml experiment submit -c my_dsvm Musicgeneration/score.py
Summary
In this blog post, we showed you how to build your own deep learning music generation model using Azure Machine Learning. This gives you a framework for agile experimentation with fast iterations and provides an easy path for scaling up and out to remote environments such as Data Science VMs with GPUs.
Once you have an end-to-end deep learning model that can produce music, you can experiment with different sequence lengths and different model architectures and listen to their effects on the music generated. Happy music generation!
Erika
Resources
- Code for this project can be found here.
- Azure Machine Learning documentation.
- Dataset: Scale-chords from feelyoursound.com.
Acknowledgements
Thanks to Wee Hyong Tok and Mathew Salvaris for their guidance and for reviewing this article, and to Matt Winkler, Hai Ning and Serina Kaye for all their help with Azure Machine Learning.