Beware crawling the non-Default zone for a SharePoint 2013 Web Application
Update: I've now published another post "Problems Crawling the non-Default zone *Explained" that goes on to explain the underlying behaviors that I warned about and described in this post...
---------------------------------------
After playing for a while with SharePoint 2013 Search, I thought we were out of the woods regarding crawls of the non-Default Alternate Access Mapping (AAM) zone for a SharePoint Web Application. This caused all sorts of problems in earlier versions of SharePoint (primarily busted contextual scopes, broken social tagging, and workflow emails linking to the incorrect zone) because there is a built in assumption by other components throughout SharePoint that the Default zone is being crawled.
I'm still working to fully nail down the impacts for SP2013, but, from my initial testing [in SP2013], when crawling a non-Default URL, all search results will be relative to the URL crawled rather than the URL from which you query (and suspect it’s going to break scoping rules for queries as well), meaning you will get unexpected URLs when you query.
Update: I want to seriously caution against using Server Name Mappings, particularly in SharePoint 2013. Admittedly, with SharePoint 2010, Server Name Mappings did appear to provide a workaround. However, although they appear to work, Server Name Mappings were definitely not designed for this particular scenario.
Second, In SharePoint 2013, I know for certain that some managed properties (e.g. SPSiteUrl and ParentUrl to name two) in the Index absolutely do not get *updated by Server Name Mappings, so adding them will only make the problem worse!!! In other words, you'll have some URL-based properties that are relative to one URL and other MPs relative to the mapped URL...
But because Server Name Mappings were not intended for this scenario, I would not have expectation that this should work in all cases.
For example, if I issued a query from some site in the Web Application https://initech, then I should expect all results from this Web Application to be returned relative to https://initech (as in https://initech/result1.aspx and https://initech/result2.aspx). However, if I were crawling the URL of a non-Default zone, then my results will all be returned relative to this non-Default URL (such as: https://bargainclownmart:88/sites/myTeam/result1.aspx and https://bargainclownmart:88/sites/myTeam/result2.aspx ).
Update: I recently published "Alternate Access Mappings (AAMs) *Explained" to provide more insights on AAMs and to better illustrate its often misunderstood concepts.
In this scenario below, I have two Web Applications with the following Alternate Access Mappings (as a side note, I believe Host Named site collections are now the preferred method over AAMs, but I wanted to demonstrate this as an example):
| Internal URL | Zone | Public URL for Zone |
|---|---|---|
| https://sp-foo:88 | Default | https://sp-foo:88 |
| https://testingfoo:88 | Intranet | https://testingfoo:88 |
| https://bargainclownmart:88 | Internet | https://bargainclownmart:88 |
| https://bargainclownmart.officespace.lab:88 | Extranet | https://bargainclownmart.officespace.lab:88 |
| https://faceman | Default | https://faceman |
| https://initech | Intranet | https://initech |
| https://initech.officespace.lab | Internet | https://initech.officespace.lab |
Observed behaviors when crawling the Default URLs...
In my content source, I specify https://faceman and https://sp-foo:88 as the start addresses and then perform a full crawl.

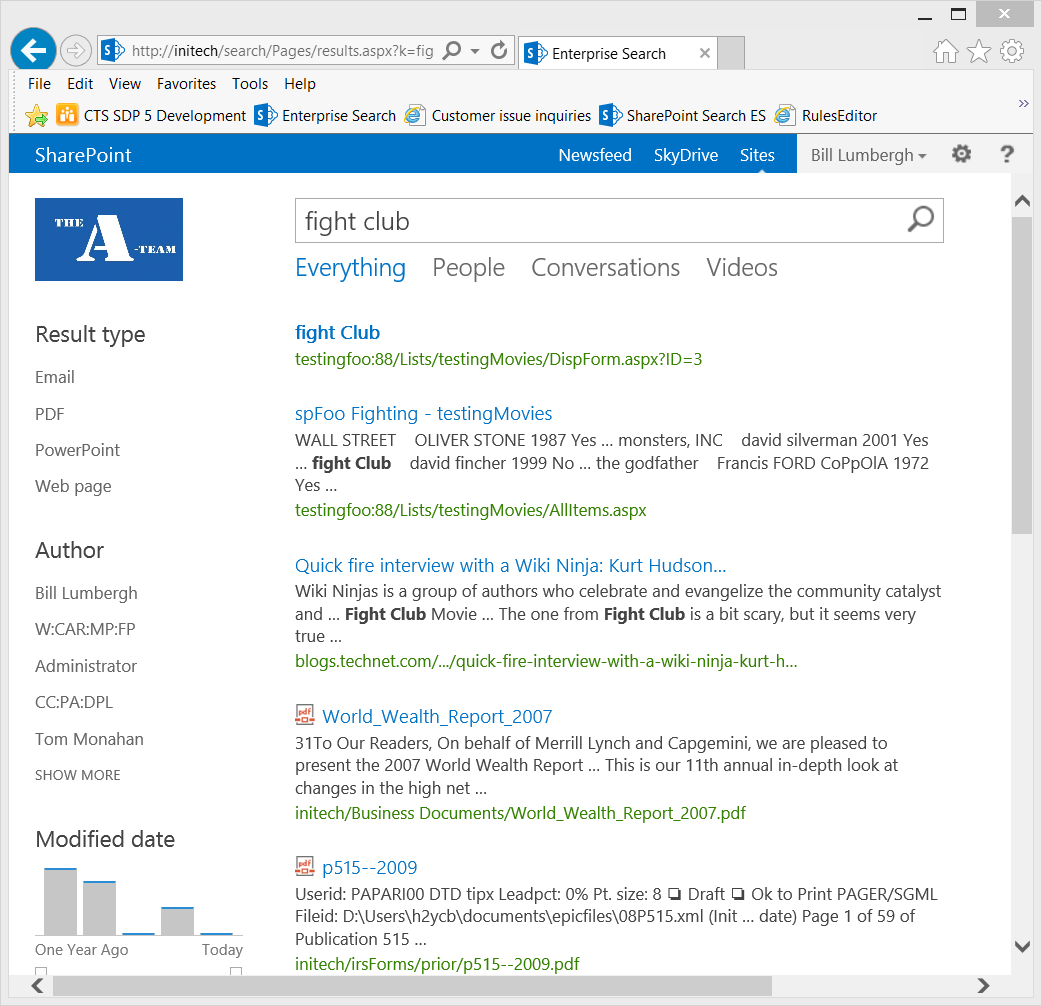
As expected, the URL for results is relative to the URL from which the query is performed. For example, notice the URL in the browser's address navigation bar shows https://sp-foo:88 and the results for this Web Application are also displayed relative to this same https://sp-foo:88 URL:

Results related to another Web App would also be relative to this zone (which to knowledge is new to SP2013). For example, if I query from the https://initech URL (in other words, from the Intranet zone), then all results related to this Web App would be relative to the https://initech URL (such as https://initech/result1.aspx, https://initech/result2.aspx, etc...) as seen in the last two results in the screen shot below...
- Further, the query, which was issued from the Intranet zone of the https://faceman Web App (In this case, https://initech as seen in the browser's address navigation bar), the results related to the https://sp-foo:88 Web App would also be relative to that Web App's Intranet zone
- As seen below, the search results for this Web App are relative to the https://testingfoo:88 URL (such as https://testingfoo:88/item1.aspx, https://testingfoo:88/item2.aspx, etc...) because it is also the Intranet zone for that Web Application
- If the query occurred in the Internet zone, then the results for the https://sp-foo:88 Web App would also be relative to the Internet zone (In that case, results would appear such as https://bargainclownmart:88/item1.aspx, https://bargainclownmart:88/item2.aspx, etc...)
- If the zone you're in doesn't exist in the other Web App, the results will just defer to the Default zone for that applicable Web App
- For example, if I issue a query from https://bargainclownmart.officespace.lab:88 (the Extranet zone of the https://sp-foo:88 Web App), the results from this Web App would be relative to the https://bargainclownmart.officespace.lab:88 URL (such as https://bargainclownmart.officespace.lab:88/item1.aspx, https://bargainclownmart.officespace.lab:88/item2.aspx, etc...)
- However, the https://faceman Web App does not have an Extranet zone, so all results would be relative to its Default URL for https://faceman (such as https://faceman/result1.aspx, https://faceman/result2.aspx, etc...)
- Likewise, if I extended https://faceman into https://hulkmaster as the Custom zone, queries from https://hulkmaster would show results relating to the https://sp-foo:88 Web App using its Default zone because that Web App does not have a Custom zone. In other words, results for this Web App would be relative to the Default URL https://sp-foo:88 such as https://sp-foo:88/item1.aspx, https://sp-foo:88/item2.aspx, etc...
- For example, if I issue a query from https://bargainclownmart.officespace.lab:88 (the Extranet zone of the https://sp-foo:88 Web App), the results from this Web App would be relative to the https://bargainclownmart.officespace.lab:88 URL (such as https://bargainclownmart.officespace.lab:88/item1.aspx, https://bargainclownmart.officespace.lab:88/item2.aspx, etc...)
For comparison, observed behaviors when crawling the non-Default URLs...
In my content source, I then specify https://faceman and the Internet zone https://bargainclownmart:88 as the start addresses and then perform a full crawl.

For my queries from any zone for any Web App, the search results related to the https://sp-foo:88 Web App will always return relative to the URL that was crawled... in this case https://bargainclownmart:88. In other words...
- If I query from https://sp-foo:88, https://testingfoo:88, etc., all results for this Web App will be relative to the crawled URL https://bargainclownmart:88 (such as https://bargainclownmart:88/item1.aspx, https://bargainclownmart:88/item2.aspx, etc...)
- For example, in this screen capture below, notice the URL for the result "Fight Club" shows bargainlclownmart:88 even though the query was issued from the https://sp-foo:88 URL (as seen in the browser's address navigation bar)
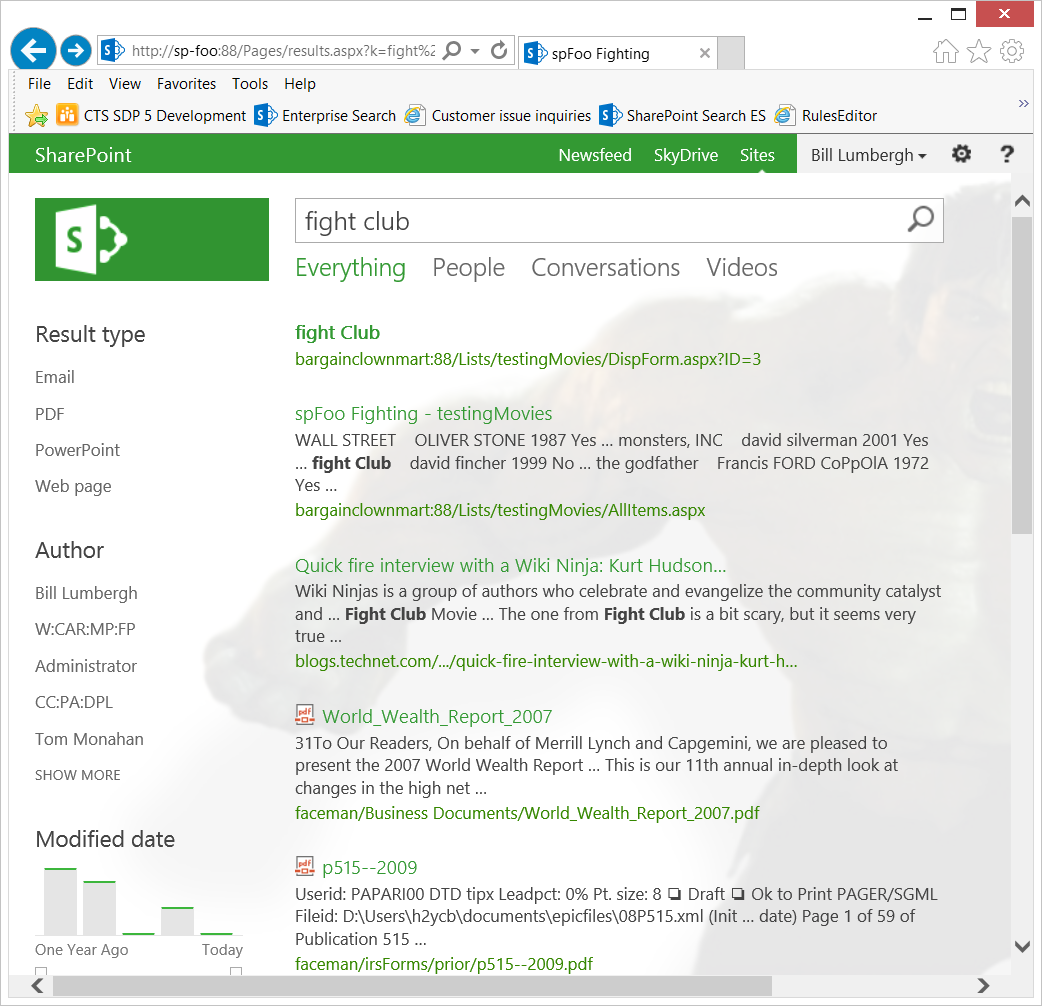
- Likewise, if I query from https://faceman, https://initech, etc., all results related to the https://sp-foo:88 Web App will be relative to the crawled URL https://bargainclownmart:88 such as below:

The moral to this story...
Always crawl the default URL (*the URL being crawled must be a Windows Authenticated zone) unless there is a REALLY good reason otherwise.
Comments
Anonymous
August 30, 2013
I also saw that results returned from a REST search query, always returns the default zone url, even if you are in the same web app (but different zone). This effects Content Search Web Part results.Anonymous
October 01, 2013
You can also use server name mappings in Central Administration. Although it is not advisable to use those in conjunction with alternate access mappings-- which may be what the scope of this article covers. I had a situation where my results were http://<server name>:8847 and I wanted https://site.domain.com to appear in results and didn't need zone-specific paths. Changing the server name mapping to https://site.domain.com worked for me. Results may vary depending on each environment. Thanks for the post, very informative.Anonymous
November 18, 2013
Hello bspender, Thank you for your blog article. Are you aware of the "Server Name Mappings" settings in "Search Administration" in SharePoint "Central Admin"? The description of the settings says: "Create server name mappings to override how URLs are shown in search results. Server name mappings are typically needed when the URLs used by the crawler to access content are different than the URLs which users use to navigate to the same files." See the following URL for an example of how to configure SharePoint on a non-default zone and configuring the Server Name Mappings to prevent erroneous URL's in the search results: sharepointobservations.wordpress.com/.../sharepoint-2013-configuring-search-to-crawl-web-applications-using-claims-and-adfs-2-0 Might this solve the issues you experienced? Regards, Beat NideröstAnonymous
November 18, 2013
I want to seriously caution against using Server Name Mappings, particularly in SharePoint 2013. Admittedly, with SharePoint 2010, Server Name Mappings did appear to provide a workaround. However, although they appear to work, Server Name Mappings were definitely not designed for this particular scenario. Second, In SharePoint 2013, I know for certain that some managed properties (e.g. SPSiteUrl and ParentUrl to name two) in the Index absolutely do not get *updated by Server Name Mappings, so adding them will only make the problem worse!!! In other words, you'll have some URL-based properties that are relative to one URL and other MPs relative to the mapped URL... But because Server Name Mappings were not intended for this scenario, I would not have expectation that this should work in all cases.Anonymous
December 11, 2013
When following the SharePoint 2013 Design Samples (technet.microsoft.com/.../cc261995.aspx) the extranet sample doesn't crawl on the default zone. We have a similar configuration. The default zone is the "default" zone. All users access that zone and it's configured for SAML authentication. We have an intranet zone with NTLM for crawling. We cannot switch the zone's because administrative emails sent from SharePoint would contain the URL of the wrong zone. (as described in the design samples). We use server name mappings to fix the URL's in the search index. How can we configure the zones correctly for search and keep the correct URL's in administrative e-mails?Anonymous
February 06, 2014
Hi Brad - just now seeing this comment, so apologies for delayed response. This is admittedly a scenario that I don't have a blanket "do this". If you don't crawl the default zone, I am certain that aspects of Search won't function as expected as noted above. I've also previously reached out to the content owners of that TechNet article that you referenced and noted my concerns Without deep diving here, you'd generally want to configure both Authentication providers in the same zone (e.g. both SAML and Windows NTLM). Then, in Central Administration -> Web Application -> Authentication providers, set the “Sign In Page Url” to a custom login page (e.g. the relative URL used as the default login page for FBA like /_forms/default.aspx) ...then verify the crawl can access the default URL (using NTLM). ...For full disclosure, I haven't actually implemented this specifically as a workaround, but have heard others report that this works. Being said, I would test and verify before just trusting me :-)Anonymous
May 05, 2014
Have you ever experienced a problem where a Search Application was crawling the wrong web-app entirely due to AAM ? I have a public site web-app and an internal site web-app as well as corresponding Search Application / Content Sources for each. The Internal Site Search Application is crawling the Site Columns ( Properties ) from the Public Site. In the Public Site Search Application, the crawled properties are completely unavailable.Anonymous
September 30, 2015
Hi bspender, Is crawling of https sites in default zone fully recommended ? I am going to create 1 web application with https and that by default , place under 'Default zone' . So do i see any issues with crawling ? Please suggest . Best Regards, RizAnonymous
July 15, 2017
We have to consider few points while setting up the topology checkout on http://sathiya.io/sharepoint/sharepoint-crawling-not-working-with-non-default-zone-public-facing-site.phpCheers!