Why Host Distribution Rules Don't Apply to SharePoint 2013
After reading my post to rebalance Crawl Stores in SharePoint 2013, several people have since reached out to ask something such as the following:
I wanted to consult with you about rebalancing Crawl Store databases. Basically, I have a customer looking for a way to dedicate crawl resources for a specific content source. In previous advisory cases for SP2010/FS14, we suggested to add Crawl Components with a dedicated Crawl Store, and add host distribution rules in order to make it crawl a specific content source.
Currently, my customer is asking how to do that in SharePoint 2013, as we have removed the host distribution rules according to this TechNet article, which states:
“In SharePoint Server 2010, host distribution rules are used to associate a host with a specific crawl database. Because of changes in the search system architecture, SharePoint Server 2013 does not use host distribution rules. Instead, Search service application administrators can determine whether the crawl database should be rebalanced by monitoring the Databases view in the crawl log”
I saw your blog post , but it doesn’t seem to dedicate crawlers to a content source as expected. Is it possible to dedicate specific host or content source to a specific crawl store database(s) in SharePoint 2013?
The root of this question stems from a mix up of two seemingly related, but different concepts around the Crawler architecture. The first concept, described by both the TechNet article and my post on Crawl Store rebalancing, relates to how crawled links get distributed across multiple Crawl Stores (e.g. the logic of how URLs get grouped by Host and “balanced” by link count). The second concept, however, is more of a byproduct of the SharePoint 2010 architecture that dedicates Crawl Components to a specific [set of] Host(s).
The short answer to this question…
In SharePoint 2013, with architectural changes relating to the way Crawl Components associate to a Crawl Store Database, it is no longer possible to dedicate a Crawl Component to a particular Host (where “Host” throughout this post refers to the root portion of a URL such as https://foo, https://initech.com, or https://bargainclownmart). However, using Site Hit Rules, you can tweak the number of session threads for Crawl Components on a per-Host basis. In other words, you can scale out Crawl resources for a particular Host without having to continually provision more Crawl Stores, Crawl Components, and (the now defunct) Host Distribution Rules.
Note: In most the cases that I’ve seen, crawling bottlenecks were not caused by an insufficient number of Crawl Components, but rather other factors including poor repository response (e.g. a slow WFE), poor SQL performance, insufficient crawler session threads accessing the Content Source (Site Hit Rules), or not enough CTS nodes to process crawled items causing a bottleneck in the content processing side of the pipeline. Update: SharePoint 2013 Crawl Scaling Recommendations has a lot more specifics around this.
The more detailed answer…
Depending on your perspective, the practice of creating dedicated Crawl Components was either seen as a byproduct of the SharePoint 2010 architecture or more often, a workaround for it. With Hosts tied to a specific Crawl Store (defined by the Host Distribution Rules) and Crawl Components tied to a specific Crawl Store, the implicit side effect of this SharePoint 2010 architecture means that Crawl Components are tied to particular Host(s). With some planning, you could then dedicate particular Crawl Components to a specific Host.
To further explain this nuance, it’s first important to describe the relationship between a crawled Host and a Crawl Store. In SharePoint 2010, a single Host is confined to one and only one Crawl Store DB. In other words, crawled URLs from one Host cannot span from one Crawl Store to another.
The Host Distribution Rules in SharePoint 2010 allow a SharePoint administrator to designate which Crawl Store would manage URLs from a particular Host. Alternatively, you could allow SharePoint to automatically manage the distribution of Hosts across Crawl Stores where each new Host is simply added to an existing Crawl Store that has the lowest link count (e.g. the row count in MSSCrawlUrl).
For example, in SharePoint 2010, you could designate the Host https://foo and https://initech.com to CrawlStore-A and https://bargainclownmart to CrawlStore-B. In this case, all URLs relative to https://foo (such as https://foo/1.aspx, https://foo/2.aspx, and so on) would all be tracked in CrawlStore-A, while all https://bargainclownmart URLs would be tracked in CrawlStore-B. However, links from one Host could not span into another Crawl Store even if this content source had more than 25 million links (which is the maximum number of links that could be stored in a single Crawl Store Database for SharePoint 2010).
For comparison, in SharePoint 2013, Hosts are now able to span multiple Crawl Stores and are no longer bound to only one Crawl Store. My blog post describes how to further refine this behavior, but balancing will occur by default for Hosts with greater than 10 million links (assuming multiple Crawl Stores). The key takeaway here is that SharePoint 2013 “balances” the storage of crawled links across Crawl Stores differently than it did in SharePoint 2010.
Next, let’s look at how Crawl Components come into play. In SharePoint 2010, there is a one-to-many relationship between a Crawl Component and a Crawl Store Database. In this architecture, each Crawl Component belongs to one and only one Crawl Store (and multiple Crawl Components can belong to the same Crawl Store), such as:
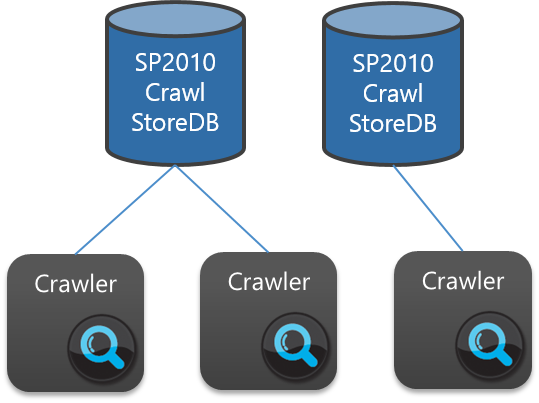
In SharePoint 2010, assuming links relative to https://bargainclownmart get managed in CrawlStore-B, only the Crawl Components for CrawlStore-B would be engaged when crawling this Host – the Crawl Components for CrawlStore-A would remain idle. Likewise, if Hosts https://foo and https://initech.com were associated with CrawlStore-A, only Crawl Components for CrawlStore-A would be engaged when crawling these two start addresses.
For comparison, in SharePoint 2013, Crawl Components are no longer explicitly tied to a Crawl Store, so think of these having a many-to-many relationship like in the picture below. In this case, all Crawlers would participate in a crawl regardless of the Host involved.

With the SharePoint 2010 architecture, two key problems arise:
First, assume Host Distribution Rules tied https://initech.com to CrawlStore-A. Over time, this site became wildly popular causing the link count to grow rapidly. To reduce the total number of crawled links being managed in CrawlStore-A, the SharePoint Admin created CrawlStore-C with Host Distribution rules that dedicated this Crawl Store to https://initech.com.
In this scenario, even if the existing Crawl Component(s) have the capacity/resources to handle the load of crawling https://initech.com, you must also provision new Crawl Components for this new Crawl Store due to the 1-to-many relationship described above for SharePoint 2010.
Note: In reality, for load balancing and/or redundancy reasons, you would likely want to provision multiple Crawl Components for this new Crawl Store. Assuming our example architecture with three Crawl Stores, you would then have a total of six or more Crawl Components (e.g. two per Crawl Store) provisioned for this SSA …Just be aware of the potential performance hit of all Crawl Components running simultaneously if you fire these all up at the same time for full crawls (or if each of these start addresses were in the same SSA content source)
In SharePoint 2013, the Crawl Components are more independent from the Crawl Stores, meaning you can add more Crawl Stores without having to provision new Crawl Components (And as noted above, in most the cases that I’ve seen, crawling bottlenecks were typically not caused by an insufficient number of Crawl Components).
The second problem emerges when any single Host has more than 25 million links, which is the limit for a Crawl Store. Because the SharePoint 2010 SSA confines a Host to only one Crawl Store, this environment hits a ceiling for which I’m not aware of any workarounds. In other words, in SharePoint 2010, there is no way to manage the first 25 million items from a Host in one Crawl Store, and then have the next 15 million spill over into a second Crawl Store.
For comparison, in SharePoint 2013, a Host can span multiple Crawl Stores. So, if your single host had 40 million items, you could accommodate this scenario by simply adding a second Crawl Store, and the Host would then be spanned across both Crawl Stores.
In Summary…
In SharePoint 2013, with Hosts no longer bound to a single Crawl Store and Crawl Components no longer tied to a specific Crawl Store, the implicit connection between the Crawl Component to a Host no longer exists. Further, with Hosts no longer bound to a particular Crawl Store, there is no longer a need for Host Distribution Rules. Hopefully this gives more clarity as to why there is more nuance to the question than initially appears, and given the architecture in SharePoint 2013, why Host Distribution Rules no longer apply.
Until next time…
Understandably, the heart of the initial question still stands: How can I dedicate more crawl resources to a specific Host? As referenced above, the bottleneck in poor crawl performance isn’t typically tied a lack of Crawlers. As such, I would argue that the question should be: How do I isolate the bottleneck in the crawling process?
It’s a topic that extends beyond the scope of this post and one I plan to write on further in a future post.
In a nut shell, the Crawler is designed to saturate the number of threads between itself and all of the Content Processing nodes. I tend to start my crawl performance troubleshooting here in the middle to determine if the CTS nodes are backlogged (which tends to indicate some downstream bottleneck processing the content or writing it to the index) or if they are starved for content (which tends to indicate an upstream bottleneck such as a slow WFE or poor SQL performance).
If the WFE can handle an increased load, try using Site Hit Rules to increase the number of session threads utilized by the Crawl Component(s). For reference, see the TechNet for:
- Get-SPEnterpriseSearchSiteHitRule, which states:
“The Get-SPEnterpriseSearchSiteHitRule cmdlet reads a SiteHitRule object when the site hit rule is created, updated, or deleted. A SiteHitRule object sets how many crawler sessions (threads) can simultaneously crawl the given site.
The SiteHitRules are per Host and these can also be set per Server that has a crawl component (e.g. using the SearchService parameter of the New-SPEnterpriseSearchSiteHitRule cmdlet)”
- And New-SPEnterpriseSearchSiteHitRule, which states:
“The New-SPEnterpriseSearchSiteHitRule cmdlet sets the maximum limits for crawling a site. The new site hit rule is used by all search service applications on the current farm.”