MP Best Practice - Make likely server roles MSCS aware
Overview
When you develop a management pack for a cluster aware application or product, you need to take special steps in your management pack to help the OpsMgr health service to make the right decisions for discoveries, tasks, monitors and rules to run correctly against monitoring classes that represent the operating components in cluster aware applications. To do this, you take advantage of the IsVirtualNode property on the Windows.Server.Computer class from the Microsoft.Windows.Library management pack. This property is provide to allow MP authors to create management packs that are MSCS cluster aware by implementing special discovery logic so that your monitoring logic only "activates" the monitoring required on the virtual node and not on either of the physical nodes that make up a cluster. The management pack author has to choose to check for whether the application is in a clustered state, and then only "discover" the application components on the virtual node of the cluster.
Often, MP authors read this first paragraph and conclude that becoming cluster aware is something they can do in the management pack. Most of them fail. The reason is that to be cluster aware, the application or configuration that drives the management pack discovery has to provide two critical pieces of information that are impossible for the MP author to manufacture themself. These two items are:
- App Installed In Clustered Configuration: One of the first thing the discovery needs is to know if the app is in a cluster. If this cannot be figured out in the logic in the discovery script, there is very little the MP designer can do.
- Clustered Resource Network Name: Each time a new clustered resource group is created with cluster manager, it will be assigned a clustered resource DNS name. This is the DNS name that is registered by the cluster manager (or for it) that represents the virtual IP address that clustered requests get directed to by the clients of the clustered application.
When these two items are not discernible by the logic in your discovery scripts in a management pack, it will not be possible to successfully make the MP be cluster aware. If the app installer doesn't leave a breadcrumb that indicates that the app is in a clustered configuration, and if discovery is unable to relate the application that is being discovered to a particular DNS name for a clustered resource, then the best the MP author can do is make sure the app does NOT work in clusters.
For example, the newest SQL server MP added support for SQL clusters. This was made possible because SQL provides special table entries to reflect that the server is in an MSCS cluster, and also provides details that identify the clustered resources unique virtual DNS name. This enabled the MP to be written to determine that the SQL instance is clustered and helped the MP discovery discern which node was active.
Assuming that the above cluster awareness is provided by the application installer and the running application logic, you can the successfully make the MP be aware of clusters.
Let's look at what is going on.
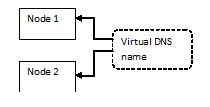
Figure 1: Conceptual cluster view for a single resource group
Figure 1 shows a diagram of a hypothetical MSCS cluster for a single resource. There are two agent managed computers (node 1, node 2) and a virtual DNS name that is the network DNS address of the clustered resource. Typically, the application clients that use the clustered resource direct calls to the virtual DNS network address, and the cluster software makes sure that the active computer is the one that receives the network request.
When SCOM is monitoring a MSCS clustered resource, there are at least three instances created that derive from Windows.Computer. Two of them are the physical nodes (typically an agent-managed computer), and one instance for each defined clustered resource DNS name. The virtual node is a instance of the base class "Windows.Computer" from the Ops Manager perspective - but since it does not really exist, it is always configured in an "agentless" configuration.
Note 1: Since a clustered resource can have more than one network DNS name associated with it, a Computer derived instance will be created automatically by the SCOM agent for each DNS name that is defined for the clustered resource. The MP author needs to make sure they pin their discoveries to the correct instance - this is done by matching the computer PrincipalName property with the assigned cluster resource DNS name that is associated with the application.
Note 2: Since Ops Manager must manage the virtual node in agentless configuration, all discovery and monitoring rules (and monitors, etc) in a cluster aware MP must be marked for "allow proxy" and for "remotable" behaviors. The "allow proxy" setting will allow Ops Manager to see the events and counters on the real from the virtual managed instance; the "remotable" will allow agentless managed configuration.
The logic required to process all of the information needed to match the discovered application seed class to the computer instance with the principalName value that matches the correct resource DNS name requires scripted seed discovery. Since this is normally undesirable because seed discoveries run on all computers, the easiest approach is to code two separate seed discoveries. One is for normal registry discovery of the seed (using the registry discovery provider) and the other is a script that manages clustered seed discovery. If you do this right using the seed pattern, you will only have to make the existence of two seed discoveries the only additional investment for supporting clustered discovery.
The first trick to making a discovery for a clustered application is to make sure that the operation components (as represented by classes defined in the management pack) are only discovered on the virtual node and not discovered on the physical nodes. This approach lets the cluster aware application be monitored from a service level perspective and allows the MP author to not have to keep track of which is the active or inactive nodes .
Operations manager provides a property on Microsoft.Windows..Computer base class that is useful for determining whether the agent is seeing the virtual node or a physical node. The agent runs workflows - and runs them in the context of the node that it is examining. The property named "isVirtualNode" is used in the discovery rule for your MP to limit discovery of the clustered elements of your product to only the virtual node. Since there are always at least three agent invocations to worry about (one for each physical node, and the remote monitoring of the virtual node), you must only discover the classes that represent the clustered application components on the agent context that is managing the virtual node.
The second consideration to making a discovery script for a clustered environment is to write all scripts in a way that prevents them from using local system resources. Since the agent uses remote management for clustered resource monitoring, the workflows that it runs must be marked "remotable = true".
A third consideration involves event based workflows (e.g. rules and monitors that utilize events). If the software logs events under the name of the virtual node instead of the physical node, the event parameters need to take this into account. For example if you are passing a computer name into a workflow as a configuration parameter, you need to use a reference that looks like
<ComputerName>
$Target/Host/Property[Type=Windows!Microsoft.Windows.Computer"]/NetworkName$>
</ComputerName>[1]
instead of
<Computername>.</ComputerName>
Other factors to plan for when supporting clustered configurations is that the OM infrastructure itself has to be configured to support the cluster. The Management Pack Guide that helps your customers be successful with the MP should point out the following:
- Agents on the cluster physical nodes - these need to be installed on all physical cluster nodes.
- All agents on these nodes need to be configured to "allow agent proxying"
- When the agents are correctly configured on the physical node, a new instance of Windows computer representing each DNS name for each clustered resource will automatically be discovered and listed in the "agentless managed" view in the administration section of the Ops Manager console.
- This agentless managed computer is the one that the cluster aware workflows will run against. The agent that manages the virtual node will be the one that manages the class instances discovered by your management pack.
- The preliminary discoveries which detect instances of the role (clustered or stand-alone) must be targeted at the Microsoft.Windows.Server class from the Microsoft.Windows.Library MP.
- o The discoveries will not work correctly if they are targeted at the specialized Windows Server and Operating System classes included in the Windows Server Base OS MP, as those objects are excluded from being discovered on Failover Cluster virtual computers.
- o Given that discoveries targeted at Microsoft.Windows.Server are run on all Windows Servers, the preliminary discovery should be as basic as is possible. More complex discoveries can then be targeted at the classes discovered by the preliminary discoveries.
Option 1: When Cluster install is optional - use dynamic name determination
Two examples of products that have cluster-aware management packs are SQL 2005 and Exchange. These MPs determine whether the agent is looking at a MSCS cluster virtual node by making discovery logic that is based in part on the special 'IsVirtualNode" property of the server class. This is done via a parameter passed in as a part of the discovery to its discovery data source module. This parameter gets its value from the server property via the following reference:
$Target/Property[Type="Windows!Microsoft.Windows.Server.Computer"]/IsVirtualNode$
At runtime, this setting value comes from the server computer class instance, which has a IsVirtualNode property. The MP only has to target a windows server computer in the discovery workflow to be able to access this value[2]. In the following abbreviated example, we see the discovery rule creating and passing a parameter to a discovery data source module. This IsVirtualNode property is automatically set to the value "true" by Operations Manager when it discovers a cluster virtual node. For physical servers, the value will always be set to the value "false".
Let's look at an example of a discovery that makes use of this property (this is from the SQL 2005 management pack)
<Discovery ID="Microsoft.SQLServer.2005.AnalysisServicesDiscoveryRule.Server" Enabled="true" Target="Windows!Microsoft.Windows.Server.Computer" ConfirmDelivery="false" Remotable="true" Priority="Normal">
<Category>Discovery</Category>
<DiscoveryTypes>
...
</DiscoveryTypes>
<DataSource ID="DS" TypeID="Microsoft.SQLServer.2005.AnalysisServicesDiscovery">
<IntervalSeconds>14400</IntervalSeconds>
<SyncTime />
<ComputerID>$Target/Property[Type="Windows!Microsoft.Windows.Computer"]
/PrincipalName$</ComputerID>
<ComputerName>$Target/Property[Type="Windows!Microsoft.Windows.Computer"]
/NetworkName$</ComputerName>
<ComputerNETBIOSName>$Target/Property[Type="Windows!Microsoft.Windows.Computer"]
/NetbiosComputerName$</ComputerNETBIOSName>
<IsVirtualNode>$Target/Property[Type="Windows!Microsoft.Windows.Server.Computer"]
/IsVirtualNode$</IsVirtualNode>
<TimeoutSeconds>300</TimeoutSeconds>
</DataSource>
</Discovery>
Example 1: Illustration of a discovery that passes the IsVirtualNode property to its data source module.
The 'IsVirtualNode' property gets a value from the base Microsoft.Windows.Server.Computer that is defined in the ops manager library classes. The value of this parameter will be the string "true" or "" (empty string), depending on whether the server is the virtual node in a cluster or not. Also, note that the discovery has to have the Remotable attribute set to true - this is because the agent has to remotely discover the elements on the virtual node. The API calls will be passed through to the underlying active computer - but the context will be the virtual. This means that your discovery will run four times on a cluster with two nodes and one DNS name - the two physical nodes (which should not discover your application types) and the virtual node that each agent manufactures for the assigned virtual DNS name associated with the resource group. If your clustered discovery script returns class data the windows computer instance does not represent the correct virtual resource node, you will have trouble with inactive nodes generating alerts when they should not. The goal is to only monitor the clustered elements of your application from the agent that is chosen to manage the virtual node.
The Management Pack author must choose whether or not to make their discovery logic place the class instance being discovered on the agent that manages the virtual node, or on the physical node[3]. This is simplified by using the Seed pattern that only identifies the application to be monitored is present, instead of making one discovery that finds all of the types that are needed for the full management pack. A rule of thumb that helps make the determination can be characterized in questions listed below:
- If the class represents the logical application from a "service availability" perspective and should not be managed separately on the underlying physical nodes in a cluster, only discover them when the IsVirtualNode value is "true".
- If the class represents a characteristic of the application that needs to impact the view of physical server health or those class instances are not cluster managed, only discover them when IsVirtualNode value is "" (empty string)
- If the application does not do anything to support MSCS clustering, then only discover the classes when "IsVirtualNode" is "" (empty string).
- o Note: This implies that all discoveries that are intended for cluster seed discovery must be aware of the IsVirtualNode setting so that an application that happens to be running on a clustered computer resource is not discovered too many times.
The clustered discovery will nearly always be a script. In that script the flow of the logic will follow the pattern in the following pseudo code.
Create a discovery data payload
If you find the application elements that could be discovered on this computer Then
If the instance of this application elements on this computer are part of a clustered instance (by looking at the application config) Then
If the node that the agent is looking at is a VirtualNode AND the assigned DNS name for this clustered instances matches the DNS value stored in the computer PrincipalName property Then
Create a class instance representing this the seed for your application
Set the key properties for this class instance
Set the key properties for the parent of this class instance (if a sub-class in a hierarchy)
Add this class instance to the discovery data payload
Else
Do not discover the node (e.g. skip this one because while a part of a clustered node, this computer is not the virtual instance)
End If
Else
'We have discovered a non-clustered instance of an operations class for this application
Create a class instance representing this node
Set the key properties for this class instance
Set the key properties for the parent of this class instance (if a sub-class in a hierarchy)
Add this new class instance to the discovery data payload
End If
Else
Do not discover the node (nothing to do because the application was not found on this computer at all)
End If
Return the discovery payload
Code Snippet 1
By following this logical path in your discovery data source module script, your discovery will work on both clustered and non-clustered instances of your application. But it is easier to make a registry key discovery for your seed for non-clustered configurations and let the customer choose to active script based discovery. Your application configuration has to be able to distinguish a clustered version of your application from a non-clustered version, and your discovery should watch for the IsVirtualNode parameter discussed earlier. The "do not discover" sections in this pseudocode example are there for clarity - you don't have to write code that does nothing J
Topical Tip
When doing discovery in a clustered environment, try to avoid making the discovered values have text in their property settings that reflect whether the item is on a real or virtual node of a MSCS cluster. Since you should not be discovering then clustered elements on the physical clusters, you won't have the opportunity to use these properties.
[1] Note: The alias "Windows!" shown in this sample is defined by the MP author. Each MP author can override the alias that is used to reference system library references, so in your own MP, this alias may change.
[2] The discovery does not need to have a target value that is the Server.Computer level. Instead, the parameter will be available if you only have a reference back to the hosting server computer. E.g. $Target/Host/Property[Type="Windows!Microsoft.Windows.Server.Computer"]/IsVirtualNode$
[3] For clarity - the discovery will run on both physical nodes, and again on the agent managing the active node - this is how the virtual node is managed. Since you want the service availability viewpoint, the agent context managing the virtual node is the one where your workflows need to be run.