Azure: Hadoop - 10 GB GraySort Sample Tutorial
Overview
This tutorial shows how to run a general purpose GraySort on a 10 GB file using Hadoop on Azure. "A GraySort is a benchmark sort whose metric is the sort rate (TB/minute) that is achieved while sorting a very large amount of data, usually a 100 TB minimum. This sample uses a more modest 10 GB of data so that it can be run in relatively quickly. This example uses the MapReduce applications developed by Owen O'Malley and Arun Murthy that won the annual general purpose ("daytona") terabyte sort benchmark in 2009 with a rate of 0.578 TB/min (100 TB in 173 minutes). For more information on this and other sorting benchmarks, see the Sortbenchmark site.
This sample uses three sets of MapReduce programs:
- TeraGen is a MapReduce program that you can use to generate the rows of data to sort.
- TeraSort samples the input data and uses MapReduce to sort the data into a total order. TeraSort is a standard sort of MapReduce functions, except for a custom partitioner that uses a sorted list of N-1 sampled keys that define the key range for each reduce. In particular, all keys such that sample[i-1] <= key < sample[i] are sent to reduce i. This guarantees that the output of reduce i are all less than the output of reduce i+1.
- TeraValidate is a MapReduce program that validates the output is globally sorted. It creates one map per a file in the output directory and each map ensures that each key is less than or equal to the previous one. The map function also generates records of the first and last keys of each file and the reduce function ensures that the first key of file i is greater than the last key of file i-1. Any problems are reported as output of the reduce with the keys that are out of order.
The input and output format, used by all three applications, read and write the text files in the right format. The output of the reduce has replication set to 1, instead of the default 3, because the benchmark contest does not require the output data be replicated on to multiple nodes." [www.windowsazure.com]
The source code for these three MapReduce programs is provided in the org.apache.hadoop.examples.terasort.zip file available on the 10 GB GraySort deployment page.
Goals
In this tutorial, you see several things:
How to run a series of MapReduce jobs by using Hadoop on Azure.
How to remote into the Hadoop cluster to monitor job progress.
Key technologies
Setup and configuration
You must have an account to access Hadoop on Azure and have created a cluster to work through this tutorial. To obtain an account and create a Hadoop cluster, follow the instructions outlined in the Getting started with Microsoft Hadoop on Azure section of the Introduction to Hadoop on Azure topic.
Tutorial
This tutorial is composed of the following segments:
- Generate the data for sorting by running the TeraGen MapReduce job..
- Sort the data by running the TeraSort MapReduce job.
- Confirm that the data has been correctly sorted by running the TeraValidate MapReduce job.
Generate the data for sorting by running the TeraGen MapReduce job
From your Account page, scroll down to the Samples icon in the Manage your account section and click it.
Click the 10 GB GraySort sample icon in the Hadoop Sample Gallery.
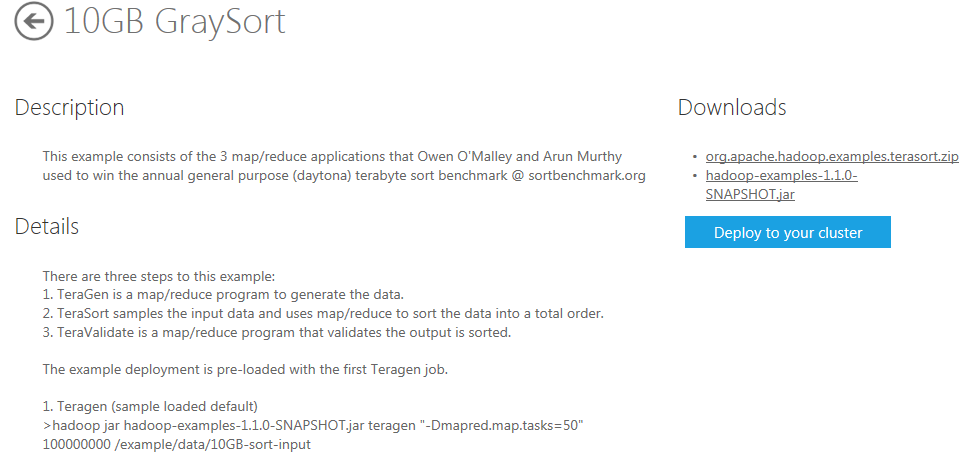
On the 10 GB GraySort page, information is provided about the application and downloads are made available with the source code for the MapReduce programs. The hadoop-examples-1.1.0-SNAPSHOT.jar file that contains the files needed by Hadoop on Azure to deploy the MapReduce jobs.
Click the Deploy to your cluster button on the right hand side to deploy the files to the cluster.
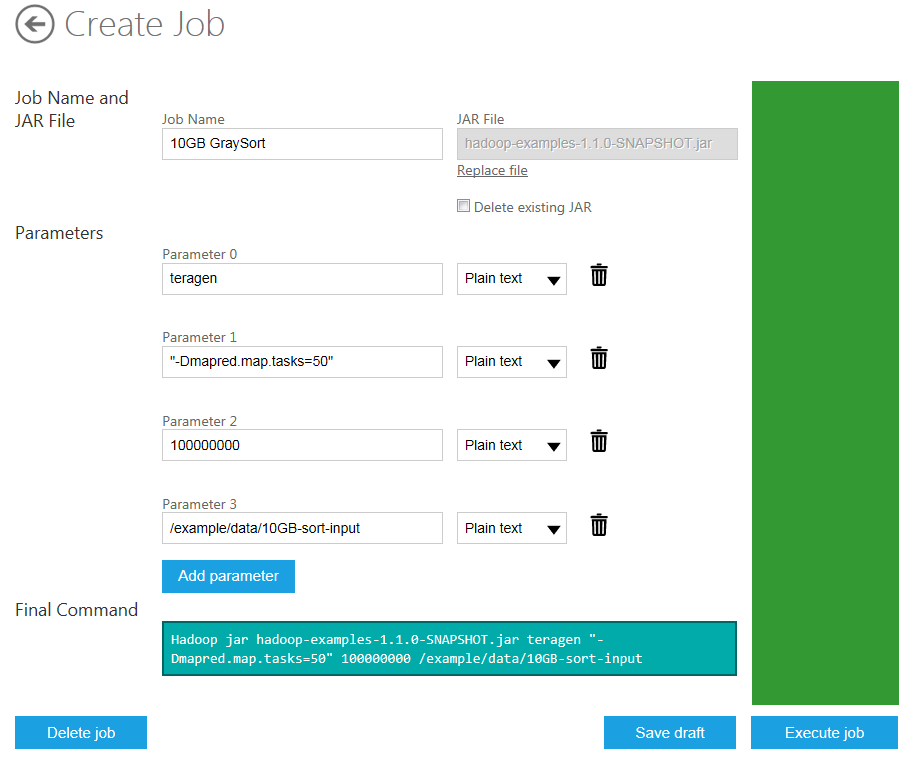
The fields on the Create Job page are populated for the running the TeraGen job. The first parameter (Parameter 0) value defaults to teragen, the name of the job. The second parameter (Parameter 1) value defaults "-Dmapred.map.tasks=50", which specifies that 50 maps will be created to execute the job. The third parameter (Parameter 2) value defaults to 100000000 which specifies the amount of data to generate. The forth parameter (Parameter 3) value defaults to /example/data/10GB-sort-input, which specifies the output directory to which it is saved (which contains the input for the following sort stage). The Final Command is automatically constructed for you from the specified parameters and jar file:
Hadoop jar hadoop-examples-1.1.0-SNAPSHOT.jar teragen "-Dmapred.map.tasks=50" 100000000 /example/data/10GB-sort-input
To run the program on the Hadoop cluster, simply click the blue Execute job button on the right-hand side of the page.
The status of the job is displayed on the page and will change to "Completed Successfully" when it is done.
You can also monitor the running and verify the completion of the job by remoting into the cluster and using the HDFS management on port 50030. Return to your Account page, scroll down to the Remote Desktop icon in the Manage your account section and click it.
Click the Open button in the pop-up window and then click on the Connect button in the Remote Desktop Connection window to connect to the cluster.
Enter the password for the cluster that you specified when you created and deployed it (not your Hadoop on Azure account password) in the Windows Security window and click OK.
Click the Hadoop MapReduce Internet Explorer icon on the desktop to open the 10 Hadoop Map/Reduce Administration page. Scroll down to find your job. You can investigate detail by following clicking the job number in the left-hand column.

Sort the data by running the TeraSort MapReduce job
Return to your Account page, scroll down to the Samples icon in the Manage your account section and click it.
Click the 10 GB GraySort sample icon in the Hadoop Sample Gallery.
To deploy the files to the cluster, click the Deploy to your cluster button on the right-hand side.
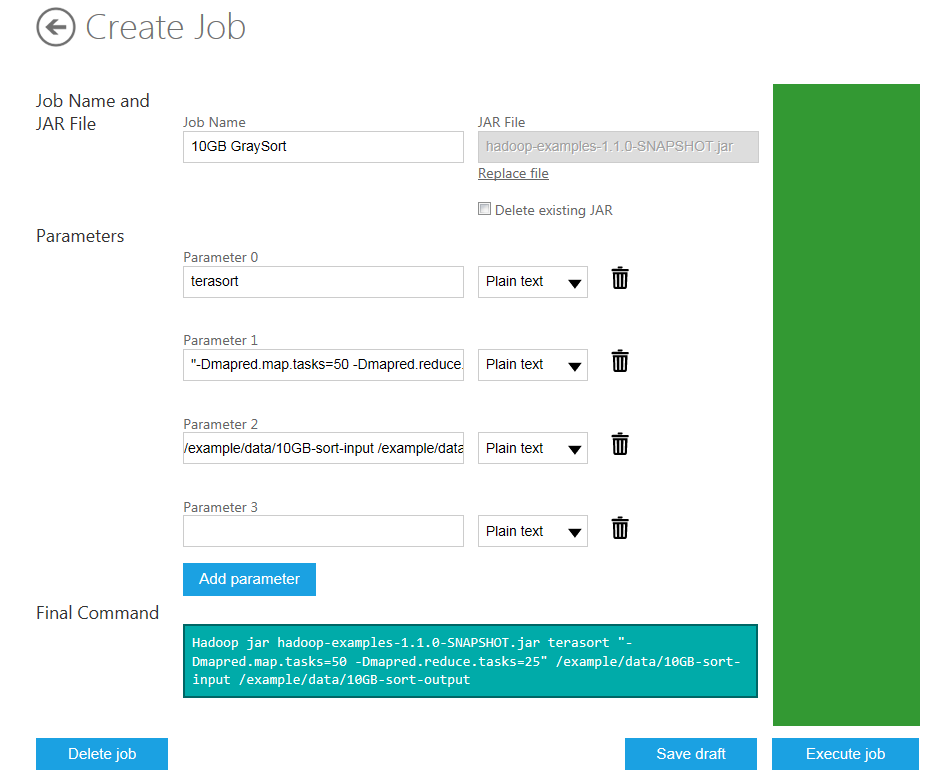
The fields on the Create Job page are populated for the running the TeraGen job. You need to change these fields to run the TeraSort MapReduce job. The first parameter (Parameter 0) value should be terasort, the name of this job. The second parameter (Parameter 1) value should be changed to "-Dmapred.map.tasks=50 -Dmapred.reduce.tasks=25", which specifies that 50 maps and 25 reduces will be created to execute the job. Set the third parameter (Parameter 2) value to /example/data/10GB-sort-input /example/data/10GB-sort-output to specify the input directory from which data will be read and the output directory to which the results will be saved. The Final Command is automatically constructed for you from the specified parameters and jar file:
Hadoop jar hadoop-examples-1.1.0-SNAPSHOT.jar terasort "-Dmapred.map.tasks=50 -Dmapred.reduce.tasks=25" /example/data/10GB-sort-input /example/data/10GB-sort-output
To run the program on the Hadoop cluster, simply click on the blue Execute job button on the right-hand side of the page.
Return to the 10 Hadoop Map/Reduce Administration page on the remote desktop if you want to monitor or confirm details that concern the status if the job.
Confirm that the data has been correctly sorted by running the TeraValidate MapReduce job
Return to your Account page, scroll down to the Samples icon in the Manage your account section and click it.
Click the 10 GB GraySort sample icon in the Hadoop Sample Gallery. To deploy the files to the cluster, click the Deploy to your cluster button on the right-hand side.
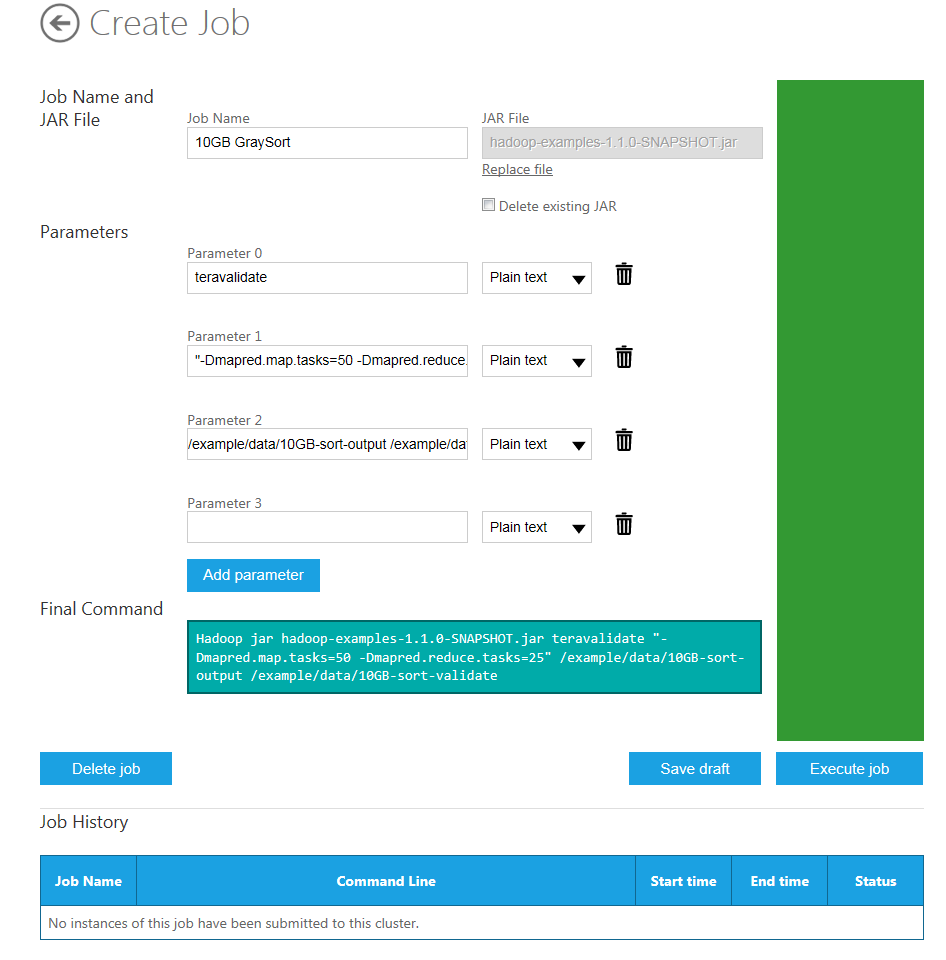
The fields on the Create Job page are populated for the running the TeraGen job. You need to change these fields to run the TeraValidate MapReduce job. The first parameter (Parameter 0) value should be teravalidate, the name of this job. The second parameter (Parameter 1) value should still be "-Dmapred.map.tasks=50 -Dmapred.reduce.tasks=25", which specifies that 50 maps and 25 reduces will be created to execute the job. Set the third parameter (Parameter 2) value to /example/data/10GB-sort-output /example/data/10GB-sort-validate to specify the input directory from which data will be read and the output directory to which the results will be saved. The Final Command is automatically constructed for you from the specified parameters and jar file:
Hadoop jar hadoop-examples-1.1.0-SNAPSHOT.jar teravalidate "-Dmapred.map.tasks=50 -Dmapred.reduce.tasks=25" /example/data/10GB-sort-output /example/data/10GB-sort-validate.
To run the program on the Hadoop cluster, simply click on the blue Execute job button on the right-hand side of the page.
Return to the 10 Hadoop Map/Reduce Administration page on the remote desktop if you want to monitor or confirm details that concern the status if the job. Any problems are reported as output of the reduce with the keys that are out of order.
Summary
In this tutorial, you have seen how to run a series of MapReduce jobs by using Hadoop on Azure where the data output for one becomes the input for the next job in the series. You have also seen how to remote into the Hadoop cluster and use the 10 Hadoop Map/Reduce Administration page to monitor progress of you jobs.