Azure HDInsight Emulator: Getting Started
Introduction
(Note: The parts of this topic, especially the Getting Started section, need revision for the latest release of the HDInsight Emulator.)
The Windows Azure HDInsight Emulator is an implementation of HDInsight on Windows. This Apache™ Hadoop™-based services on Windows uses only a single node deployment. HDInsight Server provides a local development environment for the Windows Azure HDInsight Service. This technology is being developed to provide a software framework designed to manage, analyze and report on big data
Like the Windows Azure HDInsight Service, this local development environment for HDInsight simplifies the configuring, running, and post-processing of Hadoop jobs by providing a PowerShell library with HDInsight cmdlets for managing the cluster and the jobs run on it as well as a .NET SDK for HDInsight available to automate these procedures.
Big Data
Data is described as "big data" to indicate that it is being collected in ever escalating volumes, at increasingly high velocities, and for a widening variety of unstructured formats and variable semantic contexts. For big data to provide value in the form of actionable intelligence or insight to an enterprise, it must be accessible, cleaned, analyzed, and then presented in a useful way.
Apache Hadoop
Apache Hadoop is a software framework that facilitates big data management and analysis. Apache Hadoop core provides reliable data storage with the Hadoop Distributed File System (HDFS), and a simple MapReduce programming model to process and analyze in parallel the data stored in this distributed system.
The MapReduce programming model
To simplify the complexities of analyzing unstructured data from various sources, the MapReduce programming model provides a core abstraction that provides closure for map and reduce operations. The MapReduce programming model views all of its jobs as computations over key-value pair datasets. So both input and output files must contain such key-value pair datasets. MapReduce jobs can be run with the Developer Preview of Apache™ Hadoop™-based services on Windows.
Pig and Hive
Other Hadoop-related projects such as Pig and Hive are built on top of HDFS and the MapReduce framework, providing higher abstraction levels such as data flow control and querying, as well as additional functionality such as warehousing and mining, required to integrate big data analysis and end-to-end management. Pig and Hive jobs can be run with the Windows Azure HDInsight Emulator either by using HDInsight cmdlets in PowerShell or by programming with the .NET SDK for HDInsight.
Pig is a high-level platform for processing big data on Hadoop clusters. Pig consists of a data flow language, called Pig Latin, supporting writing queries on large datasets. The Pig Latin programs consist of dataset transformation series converted under the covers, to a MapReduce program series.
Hive is a distributed data warehouse managing data stored in an HDFS. It is the Hadoop query engine. Hive is for analysts with strong SQL skills providing an SQL-like interface and a relational data model. Hive uses a language called HiveQL; a dialect of SQL. Hive, like Pig, is an abstraction on top of MapReduce and when run, Hive translates queries into a series of MapReduce jobs.
Hadoop Scenarios
Hadoop is most suitable for handling a large amount of logged or archived data that does not require frequent updating once it is written, and that is read often or extensively during analysis. This scenario is complementary to data more suitably handled by a RDBMS that require lesser amounts of data (Gigabytes instead of Petabytes), and that must be continually updated or queried for specific data points within the full dataset. A RDBMS works best with structured data organized and stored according to a fixed schema. MapReduce works well with unstructured data with no predefined schema because it interprets data when being processed.
The scenario for using Hadoop is valid for a wide variety of activities in business, science, and governance. These activities include, for example, monitoring supply chains in retail, suspicious trading patterns in finance, demand patterns for public utilities and services, air and water quality from arrays of environmental sensors, or crime patterns in metropolitan areas.
Scenarios for Hive are closer in concept to those for a RDBMS, and so are appropriate for use with more structured data. For unstructured data, Pig is typically a better choice.
The Azure HDInsight Emulator
Although this Windows Azure HDInsight Emulator uses only a single node deployment, the framework is designed to scale up from a single server to hundreds or thousands of machines, each offering local computation and storage. HDFS is designed to use data replication to address any hardware failure issues that arise when deploying such highly distributed systems. Also, the same simple MapReduce programming model that has been deployed in this simple, single node preview will be used in this more complex, distributed environments in subsequent releases.
A feature of Microsoft Big Data Solution is the integration of Hadoop with components of Microsoft Business Intelligence (BI). An example of Hadoop integration with Microsoft BI provided in the Developer Preview is the ability for Excel to connect to the Hive data warehouse framework in the Hadoop cluster via either Power Query or the Simba Hive ODBC driver for HDInsight to access and view data in the cluster.
The HDInsight Emulator provides a set of samples that enable new users to get started quickly by walking them through a series of tasks that are typically needed when process a big data set.
you may like to visit site for Run the Hadoop samples in HDInsight :
https://azure.microsoft.com/en-us/documentation/articles/hdinsight-run-samples/
Key Hadoop Technologies
- -C# MapReduce
- -Java MapReduce
- -Hive
- -Pig
Topic Outline
This topic provides help getting started with the Windows Azure HDInsight Emulator. It contains the following sections:
- Installation the Windows Azure HDInsight Emulator - How to install and deploy the Windows Azure HDInsight Emulator.
- Getting Started with the Windows Azure HDInsight Emulator - How to load data, run MapReduce, and Pig and Hive Jobs on the HDInsight Emulator .
- Additional Resources - Where to find additional resources for using the Windows Azure HDInsight Emulator and information about the Hadoop ecosystem.
Installation of Windows Azure HDInsight Emulator
The installation procedures for the Windows Azure HDInsight Emulator are outlined here Install the Windows Azure HDInsight Emulator.
Getting started with the Windows Azure HDInsight Emulator
(New content is needed here now that the Windows Azure HDInsight Emulator is publically available. The material that follows also needs updating.)
What these samples are
These samples are provided to get new users started learning Apache Hadoop-based Services on Windows quickly. They do this by walking them through the sort of tasks that are typically needed when processing a big data set and that allow them to familiarize themselves with concepts associated with the MapReduce programming model and its ecosystem.
The samples are organized around the IIS W3C log data scenarios. A data generation tool is provided to create and import these two data sets in various sizes. MapReduce, Pig or Hive jobs may then be run on the pages of data generated by using Powershell scripts that are also provided. Note that the Pig an Hive scripts used both compile to MapReduce programs. Users may run a series of jobs to observe, for themselves, the effects of using these different technologies and the effects of the size of the data on the execution of the processing tasks.
The data scenarios
The W3c scenario generates and imports IIS W3C log data in three sizes into HDFS: 1MB, 500MB, and 2GB. It provides three job types and implements each of them in C#, Java, Pig and Hive.
- totalhits: Calculates the total number of requests for a given page
- avgtime: Calculates the average time taken (in seconds) for a request per page
- errors: Calculates the number of errors per page, per hour, for requests whose status was 404 or 500
Building and extending the samples
The samples currently contain all of the binaries required, so building is not required. If users make changes to the Java or .NET samples, they can rebuild them either by using msbuild or PowerShell scripts. So the samples can be used as an extensible testing bed to explore the key Hadoop technologies deployed in this preview. Build the C# implementation and the Java sample implementation by running:
powershell –F buildsamples.ps1
What these samples are not
These samples and their documentation do not provide an in-depth study or full implementation of the key Hadoop technologies. The cluster used has only a single node and so the effect of adding more nodes cannot, with this release, be observed. Extensive documentation exists on the web for the Java MapReduce, Pig and Hive technologies.
Running the samples
There is a simple driver program in the runSamples.ps1 file for running the samples that takes four parameters: scenario, size, method, job. You can run the samples by calling:
powershell –F runSamples.ps1 <scenario> <size> <method> <job>
The values available for four parameters in the W3c log data scenario are:
- scenario w3c
- size small | medium | large
- method java | c# | pig | hive
- job totalhits | avgtime | errors
Additional information on generating and importing the scenario data and on how to run the samples is available by clicking on the tiles at the top of the Getting Started with HDInsight Server page or here:
- Load Some Data - How to import data.
- Run Map/Reduce - How run MapReduce jobs.
- Run Pig Jobs - How to run Pig jobs.
- Run Hive Jobs - How to run Hive jobs.
Load Some Data
Importing the data is done using the powershell script importdata.ps1. Note: Importing the data can take quite a while and can also be resource intensive. Import the w3c scenario data now by running:
- Open the Hadoop command prompt
- Navigate to c:\Hadoop\GettingStarted and execute the following command
powershell -ExecutionPolicy unrestricted –F importdata.ps1 w3c
This will create the following data structure in HDFS:
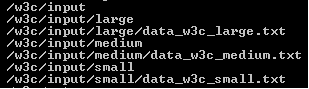
Running MapReduce Jobs
Map/Reduce is the basic compute engine for Hadoop. By default, it is implemented in Java, but there are also examples that leverage .NET and Hadoop Streaming that use C#.
Running Java MapReduce Jobs
To run Java MapReduce jobs, open the Hadoop command prompt, navigate to c:\Hadoop\GettingStarted and execute a command of the form:
powershell -ExecutionPolicy unrestricted /F runSamples.ps1 w3c <size> java <job>
There are three values available for the size and job parameters in the W3c log data scenario:
- size small | medium | large
- job totalhits | avgtime | errors
Use one of the possible sets of parameter values, for example:
powershell -ExecutionPolicy unrestricted /F runSamples.ps1 w3c small java totalhits
This will begin to output the status of the job to the console. To track the job, you can follow along with the output in the console, or navigate to the http://social.technet.microsoft.com/wiki/contents/articles/14143.getting-started-with-the-developer-preview-of-apachetm-hadooptm-based-services-on-windows/Job'%20originalAttribute= that's hosted on the headnode in the HDFS cluster.
If you are interested in the Java source code, it is available here:
- AverageTimeTaken.java
- ErrorsByPage.java
- TotalHitsForPage.java
Running .NET Map Reduce Jobs
The samples leverage the Hadoop SDK for .NET, which uses a wrapper API around Hadoop Streaming. To run .NET Map Reduce jobs, open the Hadoop command prompt, navigate to c:\Hadoop\GettingStarted and execute a command of the form:
powershell -ExecutionPolicy unrestricted /F runSamples.ps1 w3c <size> csharp <job>
There are three values available for the size and job parameters in the W3c log data scenario:
- size small | medium | large
- job totalhits | avgtime | errors
Use one of the possible sets of parameter values, for example:
powershell -ExecutionPolicy unrestricted /F runSamples.ps1 w3c small csharp totalhits
This will begin to output the status of the job to the console. To track the job, you can follow along with the output in the console, or navigate to the http://social.technet.microsoft.com/wiki/contents/articles/14143.getting-started-with-the-developer-preview-of-apachetm-hadooptm-based-services-on-windows/Job'%20originalAttribute= that's hosted on the headnode in the HDFS cluster.
If you are interested in the C# source code, it is available here:
- AverageTimeTaken.cs
- ErrorsByPage.cs
- TotalHitsForPage.cs
Running Pig Jobs
Pig processsing uses a data flow language, called Pig Latin. Pig Latin abstractions provide richer data structures than MapReduce, and perform for Hadoop what SQL performs for RDBMS systems. For more information, see http://social.technet.microsoft.com/wiki/contents/articles/14143.getting-started-with-the-developer-preview-of-apachetm-hadooptm-based-services-on-windows/Welcome'%20originalAttribute=
To run Pig jobs, open the Hadoop command prompt, navigate to c:\Hadoop\GettingStarted and execute the command:
powershell -ExecutionPolicy unrestricted /F runSamples.ps1 <scenario> <size> Pig <job>
There are three values available for the size and job parameters and two scenarios can be used:
- scenario w3c | traffic
- size small | medium | large
- job totalhits | avgtime | errors
Use one of the possible sets of parameter values, for example:
powershell -ExecutionPolicy unrestricted /F runSamples.ps1 w3c small pig totalhits
This will begin to output the status of the job to the console. To track the job, you can follow along with the output in the console, or navigate to the http://social.technet.microsoft.com/wiki/contents/articles/14143.getting-started-with-the-developer-preview-of-apachetm-hadooptm-based-services-on-windows/Job'%20originalAttribute= that's hosted on the headnode in the HDFS cluster.
If you are interested in the Pig source code, it is available here:
- AverageTimeTaken.pig
- ErrorsByPage.pig
- TotalHitsForPage.pig
Note that since Pig scripts compile to MapReduce jobs, and potentially to more than one such job, users may see multiple MapReduce jobs executing in the course of processing a Pig job.
Running Hive Jobs
The Hive query engine will feel familiar to analysts with strong SQL skills. It provides a SQL-like interface and a relational data model for HDFS. Hive uses a language called HiveQL (or HQL), which is a dialect of SQL. For more information, see http://social.technet.microsoft.com/wiki/contents/articles/14143.getting-started-with-the-developer-preview-of-apachetm-hadooptm-based-services-on-windows/Welcome'%20originalAttribute=
To run Hive jobs, open the Hadoop command prompt, navigate to c:\Hadoop\GettingStarted and execute a command of the form:
powershell -ExecutionPolicy unrestricted /F runSamples.ps1 w3c <size> Hive <job>
There are three values available for the size and job parameters in the W3c log data scenario:
- size small | medium | large
- job totalhits | avgtime | errors
Use one of the possible sets of parameter values, for example:
powershell -ExecutionPolicy unrestricted /F runSamples.ps1 w3c small hive totalhits
This will begin to output the status of the job to the console. To track the job, you can follow along with the output in the console, or navigate to the http://social.technet.microsoft.com/wiki/contents/articles/14143.getting-started-with-the-developer-preview-of-apachetm-hadooptm-based-services-on-windows/Job'%20originalAttribute= that's hosted on the headnode in the HDFS cluster.
Note that as a first step in each of the jobs, a table will be created and data will be loaded into the table from the file created earlier. You can browse the file that was created by looking under the /Hive node in HDFS
If you are interested in the Hive source code, it is available here:
- AverageTimeTaken.pig
- ErrorsByPage.pig
- TotalHitsForPage.pig
Building the Samples
The samples currently contain all of the binaries required, so building is not required. If you'd like to make changes to the Java or .NET samples, you can rebuild them either using msbuild, or we've included PowerShell scripts to run them.Build the C# implementation and the Java sample implementations by running: powershell –F buildsamples.ps1
Additional Resources:
Apache Hadoop
- http://social.technet.microsoft.com/wiki/contents/articles/14143.getting-started-with-the-developer-preview-of-apachetm-hadooptm-based-services-on-windows/Apache'%20originalAttribute= - software library providing a framework that allows for the distributed processing of large data sets across clusters of computers.
- HDFS - Hadoop Distributed File System (HDFS) is the primary storage system used by Hadoop applications.
- http://social.technet.microsoft.com/wiki/contents/articles/14143.getting-started-with-the-developer-preview-of-apachetm-hadooptm-based-services-on-windows/Map'%20originalAttribute= - a programming model and software framework for writing applications that rapidly process vast amounts of data in parallel on large clusters of compute nodes.
- http://social.technet.microsoft.com/wiki/contents/articles/14143.getting-started-with-the-developer-preview-of-apachetm-hadooptm-based-services-on-windows/Apache'%20originalAttribute= - The Welcome to Apache Pig! page.
- http://social.technet.microsoft.com/wiki/contents/articles/14143.getting-started-with-the-developer-preview-of-apachetm-hadooptm-based-services-on-windows/Apache'%20originalAttribute= - The Welcome to Apache Hive! page.
Windows Azure HDInsight Emulator
http://social.technet.microsoft.com/wiki/contents/articles/14143.getting-started-with-the-developer-preview-of-apachetm-hadooptm-based-services-on-windows/Support'%20originalAttribute= - Links to the Apache Hadoop on Azure CPT forum on the Yahoo Groups site
Additional installation issues for the HDInsight Community Technology Preview may be found in the Release Notes
 .
.Microsoft HDInsight feature suggestions may be made on the Feature Voting
pageMSDN forum for discussing HDInsight (Windows and Windows Azure)
HDInsight Services for Windows Azure
http://social.technet.microsoft.com/wiki/contents/articles/14143.getting-started-with-the-developer-preview-of-apachetm-hadooptm-based-services-on-windows/Welcome'%20originalAttribute= - the welcome page for the Developer Preview of Apache™ Hadoop™-based services on Windows Azure.
http://social.technet.microsoft.com/wiki/contents/articles/14143.getting-started-with-the-developer-preview-of-apachetm-hadooptm-based-services-on-windows/Apache'%20originalAttribute= - TechNet wiki with links to Hadoop on Windows Azure documentation.
http://social.technet.microsoft.com/wiki/contents/articles/14143.getting-started-with-the-developer-preview-of-apachetm-hadooptm-based-services-on-windows/Development'%20originalAttribute= - Portal to the Windows Azure cloud platform.
http://social.technet.microsoft.com/wiki/contents/articles/14143.getting-started-with-the-developer-preview-of-apachetm-hadooptm-based-services-on-windows/TechNet'%20originalAttribute= - The main portal for technical information about Hadoop-based services for Windows and related Microsoft technologies.
MSDN forum for discusssing HDInsight (Windows and Windows Azure)