Operations Manager Management Pack Authoring - Discovery
This document is part of the Operations Manager Management Pack Authoring Center.
Discovery Concepts
The discovery process lets you locate instances of classes and relationships that are defined in a management pack and create them in the Operations Manager database. A discovery is an element that runs on agents creating new objects as they appear in the environment, changing the properties on existing objects, and removing objects as applications and components are uninstalled. Each class that is defined in the service model must have at least one discovery associated with it or no instances of the class will ever be created.
Note: Discovery does not apply to abstract or singleton classes.
The Mechanics of Discovery
Discoveries collect information from the local computer to determine whether one or more instances of a particular class are installed and collect values for its properties. The discovery itself is only responsible for collecting this information. It sends the collected discovery data to the agent’s management server that is responsible for processing the collected data to insert into the Operations Manager database.
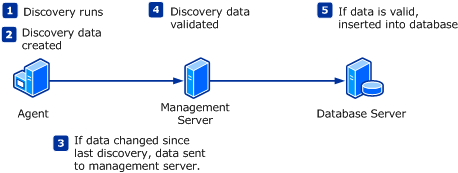
Discoveries are typically run on a scheduled basis. They continue to run on the agent even after instances are first discovered to determine whether changes were made. This interval will vary for different discoveries, balancing the considerations of the time until a new instance is discovered with the overhead generated from the discovery process.
The first time that a discovery runs on an agent, it sends its information to the agent’s management server. It also stores a copy of the collected data in the local cache. Each successive time that discovery runs, the data is only sent to the management server if a change is detected. Such changes could include a new instance, at least one property change to a previously discovered instance, or a previously discovered instance being removed. If any of these conditions are met, the discovery data is sent to the management server where it is processed.
When the management server receives the discovery data, it will inspect it to determine whether the data is valid. This includes checks such as verifying that all specified classes and properties are valid and that all required key properties were provided. If the discovery data is invalid, an error is generated on the management server and no discovery data is submitted. If the discovery data includes multiple instances and there is a problem with even a single instance, no data for any of the instances is submitted.
If the discovery data is valid, one of the following scenarios occur:
- If any of the instances have not previously been discovered, they are then created.
- If any of the instances have previously been discovered, any properties that may have changed are replaced with the value in the discovery data.
- Any instances that were previously discovered but that are not in the current discovery data are removed.
Discovery Data
The primary responsibility of a discovery is to create discovery data. This includes the details of each class and relationship instance being discovered. A single discovery may only output a single set of discovery data. However, a single set of discovery data can include a single instance of a single class or relationship, multiple instances of the same class or relationship, or multiple instances of multiple classes and relationships.
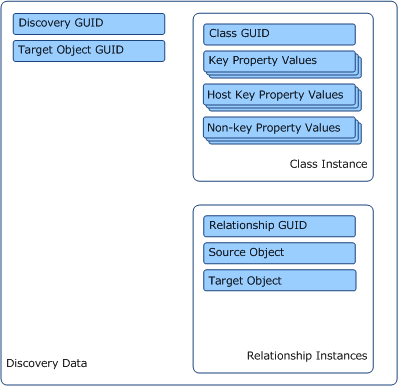
Discovery data must include the following information.
- GUID of the discovery element itself
- GUID of the target object that the discovery is running against
- GUID of each class or relationship being discovered
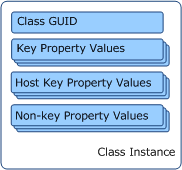
- Value for each key property of any class instances
- Value for each key property of any hosting parents of any class instances
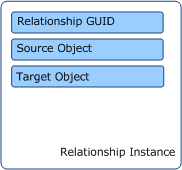
- Source and target object for any relationship instances
In addition to this information, the discovery data can also include values for any non-key properties.
**
**Each kind of discovery accesses this information through different means by using a combination of information that is provided by the management pack author and variables that are resolved when the management pack is run. Script discoveries in particular must be aware of each of these elements and explicitly provide a value for each.
Discovery Data Sources
A discovery can access any information on the local agent to collect required information. The source of information will vary for different applications and for different classes and relationships. Because a management pack can include custom modules able to access almost any available data, there is almost no limit to the sources that a particular discovery may use. There are a common set of data sources that apply to most scenarios however, and these are supported by modules included in management pack libraries and wizards in the Authoring console.
Registry
Accessing the registry on the local computer is a preferred method of discovery because of the small overhead required. The registry frequently contains lots of easy to access configuration information for many applications. A discovery can check whether a particular key or value exists, or it can collect the data from any value. Collected values may be either only collected for a property or compared to some known value to determine whether discovery data should be created.
For example, a discovery may have to check for a particular registry key to indicate that its application is installed on the local computer. If only a particular version of that application is supported by the management pack, a registry value holding the application version may be inspected to determine whether an instance should be created. Other values in the registry may then be collected to populate properties of the discovered instance.
WMI
WMI can provide lots of information about a computer or Windows operating system components. It can also be the source of information for any application that includes a WMI provider exposing parts of the application through a WMI interface. A discovery can run a WMI query to determine whether instances of a particular WMI class exist and to collect the properties from any returned instances.
For example, a particular management pack might collect information from the computer BIOS, that can be obtained by using the WMI32_BIOS WMI class.
Scripts
If a discovery requires data inaccessible from the registry or WMI, or if the discovery needs more complex logic than those discoveries provide, a discovery script must be used. A discovery script can be written in any language that can access the MOM.ScriptAPI COM object that is installed with the Operations Manager agent. The most typical scripts are written either in a language supported by Windows Script Host (VBScript or Jscript by default) or Windows PowerShell.
Discovery scripts that use VBScript or Jscript can be created by using modules in management pack libraries and wizards in the Authoring console. Modules are available for discovery scripts that are written in Windows PowerShell in Operations Manager R2 but are not supported by wizards in the Authoring console. A custom discovery would have to be created by using the appropriate module.
Any management pack requiring support by Operations Manager 2007 SP1 cannot use the Windows PowerShell modules because they are only installed with the Operations Manager R2 agent. In this case, custom discoveries that use Windows PowerShell can be created by using a module that runs a command, configuring it to build the powershell.exe command line and starting the discovery script.
Discovery Targets
The target of a discovery determines where the discovery will run. Any agent managing an instance of the target class will run the discovery. In order to minimize overhead, the target for a discovery should represent the most specific class where the class being discovered may potentially be found.
For example, a discovery determining whether an application is installed on a computer may have to target a broad class, such as the Windows Operating System class, because the application could be potentially installed on any computer in the environment. Another discovery responsible for a particular component of that application could target the newly discovered application class, because the component would presumably never be discovered on a computer where the application wasn’t installed.
Discovering Relationships
In addition to instances of classes, instances of relationships must also be discovered. Hosting relationships are discovered automatically as part of the discovery of hosted objects, but containment relationships must be explicitly discovered.
Hosting Relationships
Because a hosted object cannot exist without its hosting parent, the parent object must either already have been created before the child can be discovered or must be discovered at the same time as the child. Discovering the objects at the same time means that both classes are discovered by the same discovery with instances included in the same set of discovery data.
Instances of hosting relationships are not explicitly discovered but are created automatically when a hosted object is discovered. If the object is hosted, the discovery data must provide the key property of any of its hosting parents in addition to the key property for any instances that it includes. This is sufficient information to identify the source and target objects of the hosting relationship so that it can be automatically created.
For example, a class may be based on the Windows Computer Role class representing a particular application installed on a computer. Because the Windows Computer Role class is hosted by the Windows Computer class, the application’s class is also hosted by the Windows Computer class. The discovery for the class must provide the computer name because this is the key property of the Windows Computer class, that is, the hosting parent of the object being discovered. If the class also had its own key property, this would have to be included. If it did not have a key property, the computer name would be the only key property that would have to be provided.
Containment Relationships
Unlike hosting relationships, containment relationships must be explicitly discovered. The source and target objects for the relationship instance must either already have been discovered or be included in the same discovery. Containment relationships between specific objects are usually discovered with a discovery script. The resulting discovery data specifies the GUID of the relationship in addition to the source object and target object for the relationship instance that should be created.
Populating Groups
Groups are populated by creating instances of the containment relationship between the group objects and its members. You can do this by using a discovery script like other containment relationships, or a special group population module can be used. Group population is different from other kinds of discoveries because it is performed on the Root Management Server by using information from the Operations Manager database instead of running on the agent that uses data that is collected from the local computer. This process is typically easier and more efficient than manually creating the containment relationship instances.
The Authoring console does not provide a wizard for implementing group population. This kind of discovery must be created manually by using a special Group Populator module.
Proxy Discoveries
Most discoveries discover objects managed by the local agent computer. There are scenarios where an agent may have to perform discovery of a particular object or set of objects that are either unhosted or hosted by another computer. An example of this scenario may include collecting information from a Configuration Management Database. In this case, one agent might be responsible for running a discovery that uses a script to perform queries against information that is stored in the database. This information is then used to create instances and set property values for objects that are located on other computers. The agent running the discovery is acting as a proxy for the other agents.
The proxy scenario is typically performed with a script because other kinds of discovery are typically unable to access the required data or perform the required logic. As previously discussed, discovery data requires the key property of each discovered object and any of their hosting parents. In the proxy scenario, the hosting computer will differ from the agent running the discovery, and the discovery merely needs to provide this computer name in the discovery data. The object will be discovered and managed by the specified agent.
In order to perform discovery on behalf of another agent or discovery of an unhosted object, the agent running the discovery must have its proxy setting enabled. If this proxy setting is not enabled, the discovery will generate an error, and the discovered instances will not be created. The proxy setting is configured in the Agent Properties, which are accessed from the Administration pane in the Operations console.
Discovery on Demand
Most discoveries are performed on a scheduled basis. New objects or changes to existing objects are not discovered until the next time that the discovery for the particular class is scheduled to run. Discoveries with intervals that are too frequent put too great a load on the agent performing discovery, whereas discoveries that are too infrequent can take too much time to recognize such changes.
Discoveries can be designed to be executed in response to a particular event, assuming that an application generates such an event in response to a configuration change. In this case, the discovery could be run immediately after the configuration change and may not have to be scheduled. A discovery could also be designed to be run on demand by a user through an Agent Task.
The Authoring console provides wizards for scheduled discoveries only. Discoveries that run on demand or in response to an event may be created by using the Authoring console, but they must be created with custom discoveries that use custom modules.
Defining Discoveries
After a set of classes and relationships is defined for an application, a method of discovering each must be defined. No instances of a class will be available for monitoring in Operations Manager until they are discovered.
Identifying Discoveries for Each Class
There are three basic questions that must be answered for each class requiring discovery.
What source or sources hold the data required to determine whether an instance should be created and to populate its properties? This defines the kind of discovery.
What agent hosts the required data source? This defines the target of the discovery.
How frequently should the discovery be run? This defines the interval of the discovery.
Basic Discovery Strategy
The discovery process for an application model composed of multiple classes will typically be performed in multiple steps, with each step including one or multiple discoveries. A basic set of classes is first discovered to identify the agents where the application is installed. These classes act as targets for successive discovery of other classes.
For the basic model described in Defining Classes and Relationships, discovery can typically be performed in three basic steps.
- Discover application role classes to identify those agents with the application installed. This is typically performed with registry discoveries targeting a broad class, such as Windows Operating System.
- Discover application components hosted by each role. This is typically performed with WMI or script discoveries targeting the hosting role class.
- Populate groups. This is typically performed with group population discoveries targeting the group classes themselves.
Application Roles
The first step in the discovery process for an application model with multiple classes is typically to identify which agents the application is installed on. Because application installations are identified by the application role classes based on the Windows Computer Role class or the Windows Local Application class, these are typically the first classes discovered.
These discoveries will typically target a broad class, such as Windows Operating System, because the application could be installed on any computer in the environment. There is no way to know which computers the application is installed on until the discovery runs. If the application can only be installed on a particular version of Windows or if it can only be installed on a server or a client operating system, a slightly more refined target could be used. Examples include the Windows Server Operating System class for an application that could only be installed on a server or the Windows Server 2008 class for an application that could only be installed on a computer that is running Windows Server 2008.
Because discoveries of application roles are targeted at such a broad class, only registry discoveries should be used because they consume minimal resources. A heavier kind of discovery, such as a script, would put an unnecessary load on multiple computers that do not have an instance of the class being discovered. For most applications, a registry key is sufficient to at least confirm that the application exists. If certain properties must use another data source, such as a script, an additional discovery for the same class could be added that targeted to the class itself. This would guarantee that the more resource-intensive process runs only on those agents where it is required.
Application Components
After the application’s roles are discovered, the newly discovered objects can be used as targets for discoveries identifying application components. These classes are typically hosted by one of the application’s roles so that the hosting parent class can be used for the target. In addition to making sure that the discovery only runs on those agents where instances of the class being discovered are likely to be located, using the hosting parent as a target provides access to the hosting parent class’s properties by using $Target variables.
For example, suppose that a class named MyLocalApplication hosts a class called MyApplicationComponent. When an instance of MyApplicationComponent is discovered, it must provide a value for any key properties of MyLocalApplication because that is the class’s hosting parent. If the discovery for MyApplicationComponent targets MyLocalApplication, the discovery has access to all the properties of MyLocalApplication by using $Target variables.
Discoveries for application components typically use either WMI or script discovery. Registry discovery can be used if information about the application is stored there, but frequently another data source is required for this information. If a WMI provider for the application is available and the discovery does not require complex logic, a WMI discovery can be used. If more complex logic is required, a script can be used to access information from the registry, WMI, or any other data source that can be accessed from a script.
Group Population
After all other classes are discovered, group population may be performed because this discovery uses instances and properties that have already been discovered. Group population discoveries target the group class itself. Because groups are unhosted, they are managed by the Root Management Server. Any discoveries targeted at a group class will run on the RMS. This is appropriate because this is where group population discoveries are required to run so that the discovery can access information in the Operations Manager database.
Discovery Intervals
Most discoveries are run at set intervals, and this interval must be specified when the discovery is created. If the interval is too long, the user may have to wait an extended time until new instances or changes to existing instances are discovered. For example, a particular discovery for an application may be configured to run one time every 24 hours. When a new copy of the application is installed on a computer, it may take that long until the new instance appears in Operations Manager 2007 and monitoring begins.
Too short a time interval puts too much overhead on agents while providing minimal value. Also, if instances of the discovered class are expected to change frequently enough to warrant an aggressive discovery schedule, the design of the class may violate the best practices for classes as described here.
The following table provides recommended intervals for different kinds of discoveries.
| Discovery Type | Minimum Interval | Comments |
| Registry | 5 minutes | The interval for registry discoveries can be set very low with minimal effect, assuming that properties of the discovered objects rarely change. Because registry discoveries typically discover classes that change so rarely however, an interval of as much as 24 hours is often used. |
| WMI Query | 4 hours | Avoid the use of wildcard characters (*) in the query to return all properties. Should not be targeted at a broad class, such as Microsoft Windows Operating System. |
| Script | 4 hours | Should not be targeted at a broad class, such as Microsoft Windows Operating System. |
Practices to Avoid
The following are common practices that should be avoided when defining discoveries.
Too Frequent Discoveries
New objects installed on a managed computer or changes to existing objects will not be recognized by Operations Manager until the next time that the discovery for the class runs. Frequencies of only a few minutes are sometimes used to reduce the time that is required for such additions and changes to be detected. However, a short frequency interval increases the load on the agent running the discovery and usually provides minimal value.
Even though a particular management pack may have only a few discoveries, an agent must run discoveries from multiple management packs installed in the environment in addition to the other kinds of workflows, such as rules and monitors. Because of this, care should be taken to balance the need for quick detection of changes with a minimization of overhead.
If a particular class requires a short discovery interval because of frequent changes to the application’s components, this may indicate a health model that violates the above recommendations for volatile objects and properties that update frequently.
Script Discoveries Targeting Broad Classes
Discoveries for some classes in a management pack will need to search across all computers in an environment (or at least a large set of computers) to identify where the application is installed. These discoveries will continue to run on a regular basis even though the application may never be installed on most of these computers.
Because of their fairly small overhead, we strongly recommended that only registry discoveries target broad classes, such as the Windows Operating System class. Script discoveries that have significantly larger resource requirements should target only those classes specific to the application that were previously discovered through the registry. This strategy means that only those computers that have the application installed are required to run the scripts. Computers without the application installed must run only registry discoveries. These have minimal resource requirements.
Discover too many objects in a discovery
There is a 4 MB limit to the discovery data that can be sent from the agent to the server at one time. If there is a need to discover a lot of data that might cross this limit, break the discovery down to discover different object types as a part of different discoveries. It is also possible to have the discovery run at the management server to bypass the 4 MB limit.