Introduction
In this article we will discuss how we implemented transient fault handling in CSFundamentals to create a fault-tolerant data access layer. For those who haven’t seen it yet, the CSFundamentals is the "Cloud Service Fundamentals" application that demonstrates how to build scalable database-backed Windows Azure services. This application download includes a description of the scenario, reference architecture and reusable components for logging, configuration and data access. CSFundamentals is intended to be a tangible exploration of the best practices for delivering scalable, available services on Windows Azure, and the approaches are entirely derived from production deployments by the Windows Azure Customer Advisory Team (CAT).
The CSFundamentals data access layer discussed in this section implements a few important best practices without which building highly reliable cloud services would be virtually impossible.
Let’s go! We absolutely love transient failures, because we can handle them so easily if we know where and how they are happening. So let’s start talking how CSFundamentals leverages the transient fault handling capability of the Enterprise Library, starting with a brief introduction into the concept.
Transient Faults & Why One Should Care About Them
Simply put, transient faults are intermittent deviations from normal behavior in downstream services or underlying infrastructure. Such faults occur with any contemporary cloud platform, not just Windows Azure. They may also occur in the on-premises environments, although not as frequent as they may do in the cloud-based infrastructures. There are many different reasons for these periodic deviations. For example, a multi-tenant service suddenly reduces the volume of incoming requests to accommodate a point-in-time resource shortage. This is a common case of throttling in response to shared resource constraints and will affect the consuming application in the form of an API exception. Another good example of a transient fault is congestion on the network that results in a timeout or temporary inability to establish a new connection to the underlying service.
Regardless of the nature of transient faults, any Windows Azure solution must be prepared to deal with this class of potential abnormalities. While various Windows Azure cloud service APIs are becoming more intelligent over time by being able to handle transient faults out-of-the-box, there will always be a range of scenarios where it is necessary to add application-level transient fault handling.
To address this class of problems, the Patterns & Practices team along with Windows Azure CAT have developed and published a specialized application building block that ships as part of the Enterprise Library. For many developers, the Transient Fault Handling (TFH) Application Block (codename “Topaz”) has become fundamental for building highly resilient applications capable of sustaining a variety of transient conditions in the underlying Platform-as-a-Service (PaaS) infrastructure. The TFH block helps ensure stability in the Windows Azure cloud solutions and services by providing the instruments and knowledge base that will make the runtime behavior of the cloud solution more predictable, resilient, and tolerant to failures.
Because the functions provided by the TFH block are essential in any Windows Azure solution, CSFundamentals uses the block to guard its data access layer against any transient abnormalities in the Windows Azure SQL Database tier, whether the errors are expected -- such as resource throttling -- or unforeseen -- such as network timeouts.
How We Use Transient Fault Handling Block in CSFundamentals
CSFundamentals consumes the Enterprise Library - Transient Fault Handling Application Block package from NuGet along with Windows Azure SQL Database integration package. These packages are being maintained and regularly updated by the Patterns & Practices team (P&P). We follow their announcements and ensure we always use the very latest NuGet packages. By consuming the latest TFH NuGet package we ensure that our code is running with the latest definitions of the transient errors and their detection logic.
CSFundamentals primarily uses the SqlAzureTransientErrorDetectionStrategy which provides the error detection logic for transient faults that are specific to Windows Azure SQL Database. We did not have to customize the default implementation of this particular error detection component in TFH - its existing implementation already understands and detects all known error codes describing a range of transient conditions in the Windows Azure SQL Database infrastructure. The collection of error codes is periodically reviewed with the Windows Azure SQL Database engineers to ensure that it reflects the latest developments and improvements in the database service.
We use the application configuration file (either app.config or web.config, depending on the type of Windows Azure role) to describe the policies that tell the TFH block what to do when a transient fault is detected. These policies are often referred to as “retry policies” since they define how the TFH will attempt to recover the application from a transient fault by the means of retrying the failed operation several times until it either succeeds or all retry attempts are exhausted. The retry policy is comprised of a definition of the retry strategy and its settings. The retry strategy is nothing more than a simple algorithm determining the user code invocation pattern between retries. The settings are just numeric values describing the number of retry attempts and desired delay intervals. To define retry policies and their settings, we use the Enterprise Library Configuration Tool that provides a very simple and neat configuration experience.
Our approach to implementing the transient fault handling through the use of the TFH block in CSFundamentals is summarized in the next sections.
Binaries
We use the very latest TFH package from NuGet and keep ourselves abreast with latest updates in this specific application block from P&P. We left the default implementation of the transient error detection strategy “as is” since it includes all known transient error codes and detection logic.
Configuration
We leverage the simple configuration experience to describe various retry policies for different use cases and data access patterns. This configuration is stored in the application configuration files (web/app.config).
Retry Strategy
The Transient Fault Handling Application Block includes the following retry strategies:
- Fixed Interval retries an operation N times with the same back-off delay between each attempt. Its default implementation makes 10 retry attempts with a 1-second delay in between.
- Incremental retries an operation N times, progressively increasing the back-off delay by incrementing it by a fixed time value. The standard implementation of this strategy is configured to retry 10 times using a 1-second delay initially which then increments by 1 second for each retry attempt.
- Exponential Backoff retries an operation N times, exponentially increasing the back-off delay between each attempt by a randomly computed delta. This strategy’s out-of-the-box implementation retries 10 times with back-off delay starting with 1 second and then growing exponentially with a randomized +/- 20% delta until it reaches the maximum value of 30 seconds.
In addition to using the standard retry strategies, the TFH block offers built-in extensibility points in order to customize the transient error detection and retry strategies to meet the most demanding requirements.
When making the decision as to what retry strategy to employ, we considered the possible effects, tradeoffs, and gotchas in different retry strategies on overall application behavior in transient situations.
The fixed interval retry strategy is not desirable for handling transient faults in Windows Azure SQL Database, because it results in a standing disturbance of the database service from client calls continuing at fixed intervals. Think of it as a back-and-forth motion around the same time from all clients at constant amplitude. This adds even more pressure to the service and could lead to the rejection of simultaneous client connections by the service to protect its resources. The result is that the fixed interval retry strategy does not offer the desired transient-fault recovery velocity when used with Windows Azure SQL databases.
The above equally applies to the second candidate, the incremental retry strategy. This strategy differs from the fixed interval retry strategy only by the internal algorithm computing the back-off delay, which grows in linear proportion. The effect on the service can be virtually the same as with incremental retry.
Therefore, we decided to use the exponential backoff retry strategy for our cloud services interacting with Windows Azure SQL databases. It ensures the optimal momentum in distribution of retry attempts without overloading the downstream service (and thereby accidentally exacerbating the situation that led to a transient fault in the first place). This particular strategy enables a graceful reduction of the load on the database, especially when throttling occurs.
While designing CSFundamentals, we settled on the exponential backoff retry strategy across the board and also added some SLA-related enhancements which are described later in the document. Although this retry strategy is designed for scale, we had to customize its parameters to produce a smooth exponential curve when backing off from transient faults. The following illustration provides a comparison between the default back-off delay curve and our own customized one:
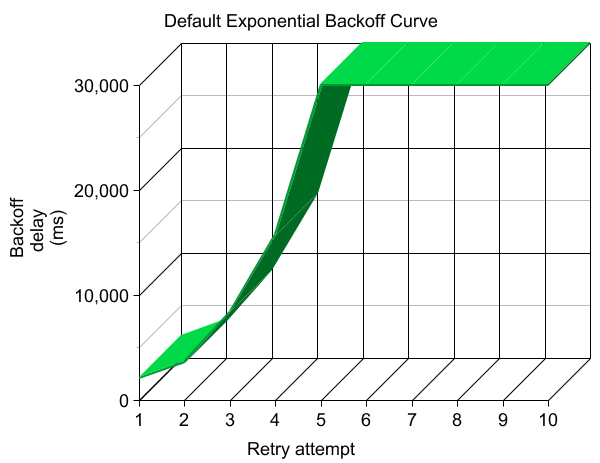 |
 |
| Figure 1: Default Exponential Delay Curve | Figure 2: Customized Exponential Delay Curve |
In the default exponential backoff diagram (figure 1), the time between retry attempts hits the maximum of 30 seconds somewhere near the fifth retry attempt. By adopting a smoother curve that spans 10 retry attempts, there are two advantages. First, more retries are performed in the first several seconds to quickly move past any short-lived transient errors (figure 2). Second, for longer-lived error conditions, the total time to complete 10 retry attempts is significantly shortened from the default settings. To achieve this smoother curve, we customized (reduced to 50) the deltaBackoff parameter value which is used for computing the range of random numbers between deltaBackoff-20% and deltaBackoff+20%. These values are factors determining the velocity of the exponential back-off curve.
Another important thing that is worth mentioning is the effect of having suboptimal (either too high or too small) timeout values on SQL connections and commands. As a general rule, avoid using the “indefinite” timeouts by setting either of these parameters to zero. This is a bad practice, especially with Windows Azure SQL Database service. Keep in mind that retrying a timing out SQL query will take significantly longer as cumulative delay imposed by the chosen retry strategy will be increased by CommandTimeout * (N+1) where N is the number of allowed retry attempts. We elaborated on some best practices for optimally configuring SQL timeouts in the dedicated section below.
Idempotent Guarantee
We make sure that our transient fault-aware data access logic is idempotent. Such a scientific word simply means that no matter how many times your application invokes the same piece of code; it produces the same results without causing unintended side effects. The goal for well-designed retry-aware code is to compose an operation that either succeeds or fails with known results and no side effects in all cases, no matter how many times it is executed.
Transient Fault-Aware Boundaries
We carefully determine the boundaries that become subject to transient fault handling. We never apply retry logic to a service call when we cannot guarantee the integrity of data between retry attempts. We wrap chunks of code (and not individual T-SQL commands) into a retry-aware scope and use SQL transactions to enforce ACID characteristics on the ADO.NET operations performed with the data. Remember, one cannot safely retry an insert operation that already succeeded as it may end up with a primary key violation or data duplication. Therefore, we use local SQL transactions to enforce atomicity of the entire operation that may need to be retried.
try
{
// Execute the entire operation as a retryable idempotent action.
_policy.ExecuteAction(() =>
{
// Note that we tell SqlBulkCopy to use the internal transaction. This is to ensure atomicity.
using (var bulkCopy = new SqlBulkCopy(_connStr, SqlBulkCopyOptions.UseInternalTransaction))
{
foreach (var kv in _mapFunc)
{
bulkCopy.ColumnMappings.Add(new SqlBulkCopyColumnMapping(kv.Key, kv.Value));
}
bulkCopy.DestinationTableName = _destTable;
Logger.Debug("Writing {0} records to {1}", value.Rows.Count, _destTable);
// Note that we applied the retry policy against the entire bulk upload operation including instantiation of the SQL connection.
// If we just wrapped the call to WriteToServer into policy.ExecuteAction(...), this could have led to an undesired outcome.
bulkCopy.WriteToServer(value);
}
});
// There are other things happening here.
}
catch (Exception ex)
{
Logger.Warning(ex, "Error in bulk insert");
// There are other things happening here.
}
Transient Fault Reporting
We log all occurrences of transient faults by using the Retrying event delegate. We use the Warning event type so that these intermittent faults won’t pollute our error logs or create a false impression that the downstream service is experiencing a hard stop condition. By tracing all transient faults, we get a better understanding of the service behavior from a client perspective. In addition, it helps us see all transient issues so that we can always go back and correlate certain abnormalities to these transient conditions, such as a spike in database operation latency. If we didn’t trace the transient faults, we would not have enough information to be able to assert whether a particular operation was being retried and therefore took additional time to complete.
public SqlDataWriter(string sqlConnection, string destinationTable, Dictionary<string, string> mapFunc, RetryPolicy retryPolicy, bool emitOnSuccess = false) : base("SqlDataWriter", "Database")
{
// There are other things happening here.
// ...
// Hook on the Retrying event to get notified every time when a transient fault occurs.
_policy.Retrying += OnTransientFaultOccurred;
}
/// <summary>
/// Handles retry policy notifications when a transient fault occurs. The purpose of this method is to record metrics and log
/// transient faults to facilitate troubleshooting.
/// </summary>
/// <param name="sender">The object sending the notification, usually the retry policy itself.</param>
/// <param name="e">The arguments associated with the notifications and carrying the transient fault details.</param>
void OnTransientFaultOccurred(object sender, RetryingEventArgs e)
{
// Log the transient fault so that we can see why our code was retrying. You may likely want to keep the message in the resource file.
Logger.Warning(e.LastException, "A transient fault has occurred while performing a database operation. The failed operation was retried {0} times. The next attempt will be made in {1} ms.", e.CurrentRetryCount, e.Delay.TotalMilliseconds);
}
Once we instrumented our services with these additional events and configured the logging component as described in "Telemetry – Application Instrumentation" article, we were able to collect and consolidate the application telemetry in the diagnostics data repository to gain invaluable insights into the services’ behavior.
SLA-Driven Design
We think about retry strategies from a Service-Level Agreement (SLA) perspective, and not in terms of retry counts and intervals. The reasoning behind this approach is the business impact of transient faults. In most cases, the SLA would be violated when the code handling the SLA-governed transaction encounters a transient fault in the downstream platform service and consequently spends extra time recovering from it. We take the SLA expressed in the maximum amount of time we are allowed to handle a business transaction and work backward from there to determine the maximum number of retry attempts as well as the exponential delay interval. The maximum compound value of all delay intervals must not exceed the defined SLA.
You really do not have to become a computer or rocket scientist in order to follow this approach, but to make it even easier we provide an extension method for the Transient Fault Handling Application Block that simply takes the timeout value which sets out the maximum amount of time TFH can spend on retrying the failed operation. Please check out the CSFundamentals source code to follow along with our thoughts on implementing this value-add extension for Transient Fault Handling Application Block.
Timeouts & Connection Management
As our attempt to answer this rhetorically popular “Should I retry on Windows Azure SQL Database timeout?” question, we investigated the underlying behavior of the ADO.NET client and the database service, and this section highlights our findings and recommendations which we applied in CSFundamentals.
Given the intrinsically multi-tenant nature of the Windows Azure SQL Database service, the potential variance in query execution and response times is one of the factors that needs to be taken into consideration when figuring out the right transient-fault-handling strategy. Handling throttling conditions is a straightforward task as these would simply manifest themself on the client side as SQL exceptions with the error code and throttling reasons which may be easily decoded using the ThrottlingCondition class. By contrast, dealing with varying query execution times and potential timeouts can be tricky.
Consider an imaginary scenario when a SQL query takes 2 seconds under normal conditions. Due to intermittent shared resource constraints, it takes, say, 40 seconds for Windows Azure SQL database engine to execute the query and return the results. However, because a default 30-second query timeout was being used, the query terminated with a SQL timeout exception. Should we consider the SQL timeout exception a “transient fault” and retry the query per the configured retry policy? Or should we simply bump up the command timeout value to, let’s say, 60 seconds and simply accept the fact that the query sometimes can run slower than expected. Perhaps, there is no single answer to these questions, as all depends on many factors, including specific application scenarios and workloads.
One approach that we found working well with typical OLTP scenarios is to keep the CommandTimeout value reasonably low, based on average query response times, and treat longer execution times as transient faults that will cause retrying the timed out operation. In this scenario, treating the timeout exceptions (SQL error code of -2) would be legitimate. The default implementation of the SqlDatabaseTransientErrorDetectionStrategy class that contains the up-to-date knowledge base of all known transient faults in Windows Azure SQL Database already understands the SQL timeout exceptions and does treat them as transient.
Through observations while working on CSFundamentals, as well as with quite a few Windows Azure customers, we also found that sometimes the SQL timeout exceptions could become “sticky” to the underlying (potentially broken) physical SQL connection. In fact, even though our retry policy correctly handled and retried on timeouts, we did not notice that the timeout condition was getting eliminated eventually. From a client application perspective, it did seem like a long-lasting transient fault that continuously results in a query timeout exception. This was mostly impacting read-only SELECT-like queries.
The remedy was to force the physical connection to close and reopen by cleaning the specific SQL connection pool holding off the “broken” connection. The following example illustrates one of the potential ways for doing this (as implemented in CSFundamentals):
protected void ExecuteSql(Action action, IDbConnection sqlConnection, string methodName = null)
{
Stopwatch stopWatch = null;
try
{
if (TimeMethods && !String.IsNullOrEmpty(methodName))
{
stopWatch = Stopwatch.StartNew();
}
_policy.ExecuteAction(() =>
{
try
{
// Verify whether or not the connection is valid and is open. This code may be retried therefore
// it is important to ensure that a connection is re-established should it have previously failed.
if (sqlConnection.State != ConnectionState.Open)
{
sqlConnection.Open();
}
// Invoke the arbitrary action.
action();
}
finally
{
try
{
// Closes the connection to the database. This is the preferred method of closing any open connection.
sqlConnection.Close();
}
catch
{
// It is acceptable to ignore any exceptions in this context as we have no clue as to the state in which we are in.
}
}
});
if (stopWatch != null)
{
stopWatch.Stop();
Logger.TraceApi(String.Format("{0}.{1}", ComponentName, methodName), stopWatch.Elapsed);
}
}
catch (SqlException sqlEx)
{
var elasped = (stopWatch == null) ? null : new System.Nullable<TimeSpan>(stopWatch.Elapsed);
AzureSqlDatabaseError.LogSqlError(Logger, sqlEx, sqlConnection.ConnectionString, elasped, methodName);
// Only recycle the connection pool if it is a timeout exception.
if (sqlEx.IsSqlTimeoutException())
{
try
{
// Resets the connection pool associated with the specified connection.
SqlConnection.ClearPool(sqlConnection as SqlConnection);
}
catch
{
// It is acceptable to ignore any exceptions in this context as we have no clue as to the state in which we are in.
}
}
}
catch (Exception ex)
{
Logger.Warning(ex, "Error in {0}:{1}", ComponentName, methodName);
throw;
}
}
Please note that this approach may not be appropriate for every type of database operation (e.g. transactional operations), and should be carefully evaluated as forcing a clean-up of the entire SQL connection pool may cause the undesirable performance impact.
Conclusion
Building distributed cloud-based applications and services can be challenging due to pitfalls of contemporary cloud infrastructures such as resource throttling, communication failures, volatility in platform service behavior. A natural solution to this class of problems is to detect potential transient failures, and retry the failed operations while keeping finger on the pulse of the business SLAs.
The CSFundamentals solution demonstrates how easy it is to compose a resilient data access layer that is capable of sustaining any potential transient failures and throttling conditions in the Windows Azure SQL Database service. The Enterprise Library’s Transient Fault Handling Application Block greatly simplifies the developer experience by offering the pre-configured transient error detection intelligence and customizable retry strategies. Then, by designing idempotent retry-aware code, choosing the acceptable retry and back-off configuration, and introducing the TFH retry policies throughout the ADO.NET client code, Windows Azure developers can streamline the implementation of fault-tolerant data access layers.
In CSFundamentals we provided some of the key techniques that can help achieve a greater degree of tolerance to cloud platform failures and replicate these best practices in bespoke solution development to build great cloud applications.