Dropping a Clustered Index Will Not Reorganize the Heap
If a clustered index will be turned into a HEAP, no reorganization of the data will occur. This "myth" is sometimes popping up in forums or blogs. A view "behind the scenes" will describe how Microsoft SQL Server is handling this operation. Before the deep dive into the internals, some basics of relations in Microsoft SQL Server databases must be understand.
What is a clustered index?
A clustered index IS the relation itself ordered logically by the clustered key. Clustered indexes sort and store the data rows in the table or view based on their key values. These are the columns included in the index definition. There can be only one clustered index per table, because the data rows themselves can be sorted in only one order. Get detailed information about clustered index at http://technet.microsoft.com/en-us/library/ms190457.aspx.
What is a heap?
A heap is the relation without a clustered index. One or more nonclustered indexes can be created on tables stored as a heap in the same way as it can be created in relations which are clustered indexes. Data is stored in the heap without specifying an order. Usually data is initially stored in the order in which is the rows are inserted into the table, but the Database Engine can move data around in the heap to store the rows efficiently. Get detailed information about structures of a heap at http://technet.microsoft.com/en-us/library/hh213609.aspx.
Problem definition
A relation with a clustered index should be turned into a heap. Therefore the clustered index will be removed by using the command
ALTER TABLE [schema].[relation] DROP INDEX [NAME_OF_CLUSTERED_INDEX];
If a relation may have hundreds of millions of records the above operation can be very time consuming which lead to the assumption that the relation will be rebuild when it turns into a heap. That's not true as the following sample(s) may demonstrate:
Test scenario
First a simple relation with a clustered index will be created and filled with 100.000 records. The results for the physical index statistics show the depth of each index which depends on the size of the key attributes.
-- Creation of a relation for demonstration
IF OBJECT_ID('dbo.tbl_demo', 'U') IS NOT NULL
DROP TABLE dbo.tbl_demo;
GO
CREATE TABLE dbo.tbl_demo
(
Id int NOT NULL IDENTITY (1, 1),
col1 char(189) NOT NULL DEFAULT ('just stuff'),
col2 char(200) NOT NULL DEFAULT ('more stuff')
);
-- Filling the table with a few records
SET NOCOUNT ON
GO
INSERT INTO dbo.tbl_demo DEFAULT VALUES
GO 100000
-- create two indexes for demonstration
CREATE UNIQUE CLUSTERED INDEX tbl_demo_Id ON dbo.tbl_demo (Id);
CREATE INDEX tbl_demo_Col1 ON dbo.tbl_demo(Col1);
The above code creates a relation named [dbo].[tbl_demo] and inserts 100.000 records. After finishing the INSERT-operation a clustered index [tbl_demo_id] and a non clustered index [tbl_demo_col1] will be created. When the script is finished you will get an overview of the physical structures of both indexes with the following script.
-- Check the physical index stats
SELECT OBJECT_NAME(i.object_id) AS object_name,
i.name,
i.index_id,
index_level,
index_type_desc,
page_count,
record_count
FROM sys.indexes i INNER JOIN sys.dm_db_index_physical_stats(db_id(), OBJECT_ID('dbo.tbl_demo', 'U'), DEFAULT, DEFAULT, 'DETAILED') ps
ON (
i.object_id = ps.object_id AND
i.index_id = ps.index_id
)
ORDER BY
i.index_id ASC,
ps.index_level ASC;
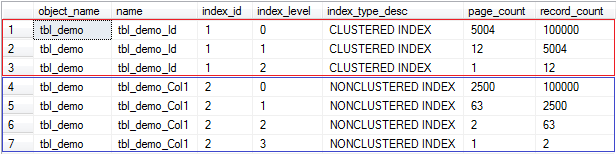
The clustered index has a ROOT-Level (index_level = 2) and a B-Tree (balanced Tree) level (index_level = 1). The Leaf-Level contains the data which are distributed over 5.004 data pages (index_level = 0). Because the clustered index IS the relation itself the leaf-level contains the data of the relation.
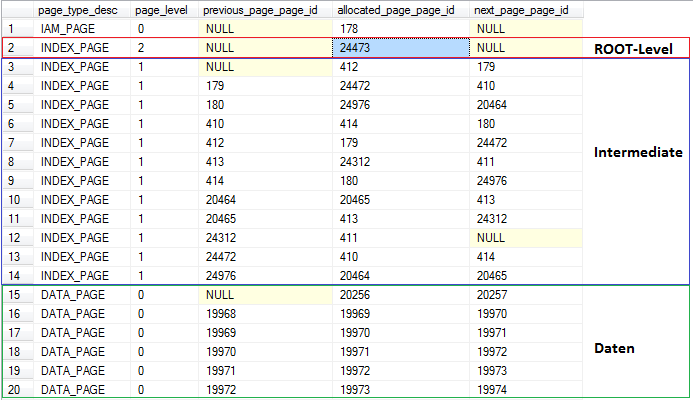
The internal structure of the clustered index can be viewed by using sys.dm_db_database_page_allocations (available since SQL 2012). The next pic shows an extract from the first data pages)
SELECT page_type_desc,
page_level,
previous_page_page_id,
allocated_page_page_id,
next_page_page_id
FROM sys.dm_db_database_page_allocations
(db_id(), OBJECT_ID('dbo.tbl_demo', 'U'), 1, DEFAULT, 'DETAILED')
WHERE is_allocated = 1
ORDER BY
page_type DESC,
page_level DESC,
previous_page_page_id ASC;
A pretty good way to make page allocations visible are the following queries which use information from sys.fn_PhysLocFormatter about the position of a record:
-- see the location of each record in the affected index
SELECT sys.fn_PhysLocFormatter(%%physloc%%) AS Location, * FROM dbo.tbl_demo WITH (INDEX (tbl_demo_Id));
SELECT sys.fn_PhysLocFormatter(%%physloc%%) AS Location, * FROM dbo.tbl_demo WITH (INDEX (tbl_demo_Col1));
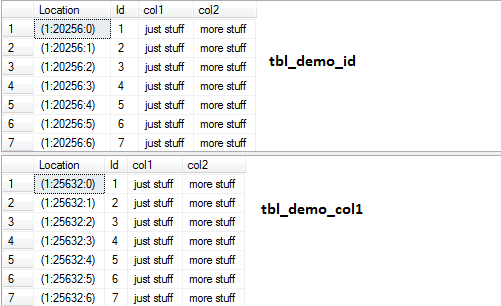
The first resultset shows the very first seven records stored in the clusterd index which starts on data page 20256 in the first data file of the database. The storage of data for the non clustered index starts on data page 25632 on the same data file of the database.
Now the operation starts with dropping the clustered index from the relation. This operation automatically turns the relation into a HEAP which is - by definition - the relation itself without a clustered index. Some people assume a completely rebuild of the relation when dropping the clustered index - because the operation can consume much time and resources of Microsoft SQL Server. To see exactly what steps will Microsoft SQL Server go through when the clustered index is dropped the operation will be covered in a named transaction. This trick will make it easy to filter the transaction steps in a simple way from the transaction log.. After the clustered has been dropped again the page allocation of the relation will be listed by sys.fn_PhysLocFormatter.
-- drop the clustered index which will turn the relation into a HEAP
BEGIN TRANSACTION DropClusteredIndex
DROP INDEX tbl_demo_Id ON dbo.tbl_demo;
COMMIT TRANSACTION DropClusteredIndex
GO
-- see the location of each record in the affected index
SELECT sys.fn_PhysLocFormatter(%%physloc%%) AS Location, * FROM dbo.tbl_demo ORDER BY Id;
GO
SELECT sys.fn_PhysLocFormatter(%%physloc%%) AS Location, * FROM dbo.tbl_demo
WITH (INDEX (tbl_demo_Col1))
ORDER BY Id;
GO
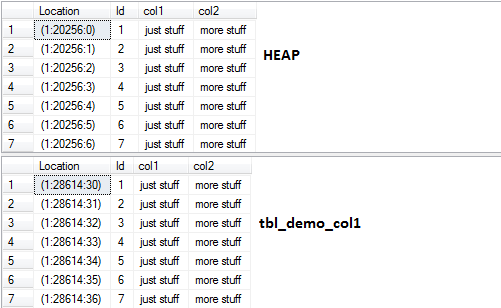
The result for the relation - which has now turned into a heap - surprises. The formerly allocated data pages have not been deallocated. The records are located at the same position as before the DROP-operation. But the page allocation of the non clustered index [tbl_demo_col1] has changed! The non clustered index has been rebuild! A look into the transaction log shows, why the DROP operation didn't affect the allocation of the data pages of the relation itself.
SELECT Operation, Context, AllocUnitId, AllocUnitName, [Lock Information]
FROM sys.fn_dblog(NULL, NULL)
WHERE [Transaction ID] IN
(
SELECT [Transaction ID]
FROM sys.fn_dblog(NULL, NULL)
WHERE [Transaction Name] = 'DropClusteredIndex'
);
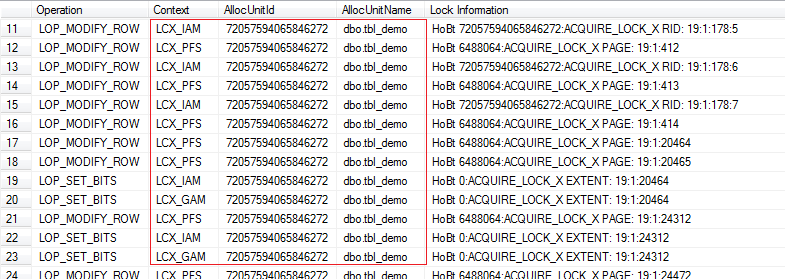
The picture above shows a shorten extract from the transaction log and the recorded steps Microsoft SQL Server has taken while dropping the clustered index. In total is was over 150 single operations but only a few of them can demonstrate the technical background; Microsoft SQL Server does not move data from one page to another but releases data from the data pages which hold meta data information of the relation.
| PFS | Page Free Space | Information about allocated and free space on data pages |
| GAM / SGAM | Global Allocation Map / Shared Global Allocation Map | Information whether Extents are allocated or free |
| IAM | Index Allocation Map | Information of extents which are allocated by a clustered index ore a non clustered index. |
To dive deeper into the internal structure of databases / data pages / records is recommended to read the great blog article "Inside the Storage Engine: GAM, SGAM, PFS and other allocation maps" from Paul S. Randal concerning the internals of the storage engine. An alternative to the www is the really great "bible for SQL Server Professionals" from Kalen Delaney "Microsoft SQL Server 2012 Internals". Have a look into the chapter "Databases Under the Hood" to get very detailed information about the storage engine.
From the transaction log it is obvious that only data pages which hold meta data will be part of the changes. The data itself won't be moved / touched in any way. Because a heap doesn't have a B-Tree structure, only these structure information will be removed when dropping a clustered index.
As an example for the operation the row 11 of the resultset of the transaction log will be object of deeper investigation. The [Lock Information] holds an exclusive lock in database 19 (which is my demo database) in file 1 and page 178 and slot 5. The page 178 is the IAM-page of the relation [dbo].[tbl_demo] which holds information about allocation of space by clustered or non clustered indexes. A close view into the data page demonstrates that extents have been deallocated.
DBCC TRACEON (3604);
DBCC PAGE (19, 1, 178, 3);
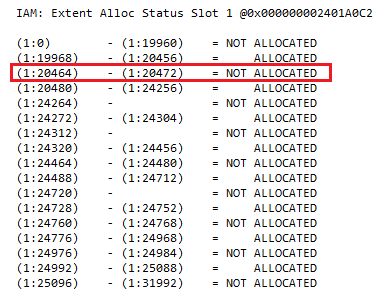
The following ranges are deallocated - they will be compared to the pages of the clustered index which "built" the B-tree structure
| Not allocated | data pages of root level or intermediate level (B-Tree) of the clustered index |
| 0-19960 | 179, 180, 410 - 414 |
| 20464 - 20472 | 20464, 20465 |
| 24312 - 24319 | 24312 |
| 24464 - 24480 | 24472, 24473 |
| 24976 - 24984 | 24976 |
All named pages in the above table are pages from the root-level and the B-tree-level of the former clustered index. So really NO data itself have been moved / manipulated but only meta data of the structure of the relation itself. The "middle construct" between IAM and data has been removed completely - which describes the structure of a heap perfectly.
Why have the data of the non clustered index been rebuild?
What impacts a non clustered index when any meta data manipulation will be used against the relation itself (e.g. creation / dropping a clustered index). The dependency between a non clustered index and the relation itself (whether a heap or a clustered index) is the link inside the non clustered index to the data pages of the heap / Clustered Index. Each non clustered index need to have a reference to the data of the relation. This "link" can be three different types of pointers:
| type of relation | pointer in non clustered index |
| unique clustered index | the clustered key |
| non unique clustered index | the clustered key and a UNIQUEIFIER which makes the row unique inside the relation |
| heap | RID (RowLocator Id) |
Concerning the structure of the demo relation it was a unique clustered key on the primary attribut [Id]. Due to the fact that the clustered key has been determined as unique no UNIQUIFIER need to be stored "on top" to the clustered key. This key is always part in any non clustered key. The following pic demonstrates the structure of the non clustered index before the DROP operation has taken place:
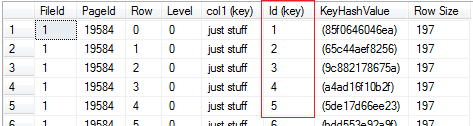
For every row in the non clustered index the pointer to the clustered key is stored, too. By this method Microsoft SQL Server is able to locate data from other attributes which are not part of the non clustered index (e.g. [col2]). The next picture shows the same non clustered index after the clustered index has been dropped.
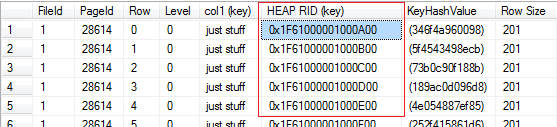
As a side effect you can see that a RID consumes another 4 bytes more than the previous clustered key which was an INT (4 bytes).
Conclusion
Dropping a clustered index will not force Microsoft SQL Server to rebuild the complete relation. Dropping a clustered index will only change the meta data and turn the B-Tree structure of an index into a flat hierarchy of an IAM page and multiple data pages (which is a heap). Adding a clustered index or dropping a clustered index will have deep impacts to ALL non clustered index of a relation because the pointers to the clustered index / heap will change and forces a rebuild of each non clustered index.
References
| heap-structures | http://technet.microsoft.com/en-us/library/ms188270.aspx |
| Clustered Index | http://technet.microsoft.com/en-us/library/ms177443.aspx |
| Nonclustered Index: | http://technet.microsoft.com/en-us/library/ms177484.aspx |