All-at-Once Operations in T-SQL
I remember when I read about this concept in a book from Itzik Ben-Gan in 2006, I was so excited and could not sleep until daylight. When I encountered the question about this concept in MSDN Forum, I answered it with the same passion that I read about this mysterious concept. So I made a decision to write an article about it. I want to ask you to be patient and do not see the link of the question until end up reading this article. Please wait, even you know this concept completely, because I hope this will be an amazing trip.
Introduction ** **
Each SQL query statement is made up by some clauses and each clause helps us to achieve the expected result. Simply, in one SELECT query we may have some of these clauses:
- SELECT
- FROM
- WHERE
- GROUP BY
- HAVING
Each of which performs one logical query processing phase. T-SQL is based on Sets and logic. When we run a query against a table, in fact, the expected result is a Sub-Set of that table. With each phase we create a smaller Sub-Set until we get our expected result. In each phase we perform a process over whole Sub-Set elements. The next figure illustrates this:
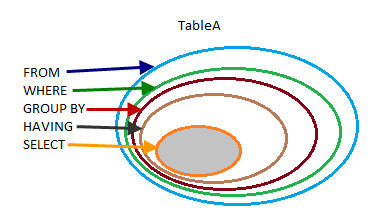
**Definition **
All-at-Once
"All-at-Once Operations" means that all expressions in the same logical query process phase are evaluated logically at the same time.
I explain this with an example using the following code:
-- create a test table
DECLARE @Test TABLE ( FirstName NVARCHAR(128), LastName NVARCHAR(128));
-- populate with sample data
INSERT @Test
( FirstName, LastName )
VALUES ( N' Saeid ', -- FirstName
N'Hasani Darabadi' -- LastName
) ;
-- query
SELECT
LTRIM( RTRIM( FirstName ) ) + ' ' AS [Corrected FirstName],
[Corrected FirstName] + LastName AS FullName
FROM @Test ;

As illustrated with this figure, after executing we encounter this error message:
* Invalid column name 'Corrected FirstName'.*
This error message means that we cannot use an alias in next column expression in the SELECT clause. In the query we create a corrected first name and we want to use it in next column to produce the full name, but the All-at-Once operations concept tells us you cannot do this because all expressions in the same logical query process phase (here is SELECT) are evaluated logically at the same time.
Why this concept is essential?
Because T-SQL is a query language over Relational Database System (Microsoft SQL SERVER), it deals with Sets instead of variables. Therefore, query must be operated on a Set of elements. Now I want to show another example to illustrate this.
-- drop test table
IF OBJECT_ID( 'dbo.Test', 'U') IS NOT NULL
DROP TABLE dbo.Test ;
GO
-- create a test table
CREATE TABLE dbo.Test
(
Id INT PRIMARY KEY ,
ParentId INT ,
CONSTRAINT FK_Self_Ref
FOREIGN KEY ( ParentId )
REFERENCES dbo.Test ( Id )
);
GO
-- insert query
INSERT dbo.Test
( Id, ParentId )
VALUES ( 1, 2 ), -- there is not any id = 2 in table
( 2, 2 ) ;
SELECT * FROM dbo.Test ;
-- update query
UPDATE dbo.Test
SET Id = 7,
ParentId = 7 -- there is not any id = 7 in table
WHERE Id = 1 ;
SELECT * FROM dbo.Test ;
After execution of this code, as it is shown in the following figure, we see that there is no id=2 in the table, but we can insert it as a foreign key in the table. This is because of All-at-Once operations.
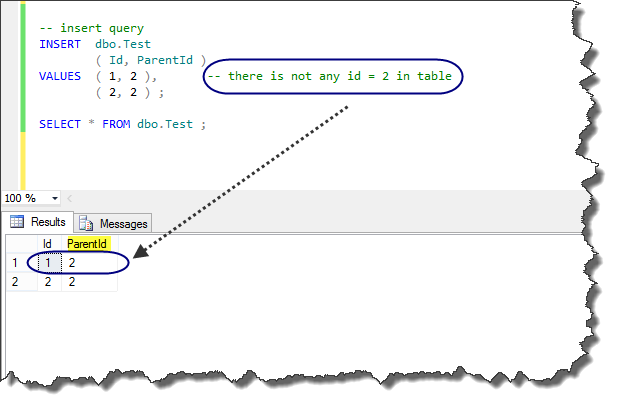
As illustrated in next figure this behavior is repeated in UPDATE query. If we do not have All-at-Once operations feature we should first insert or update the primary key of the table, then modify the foreign key.
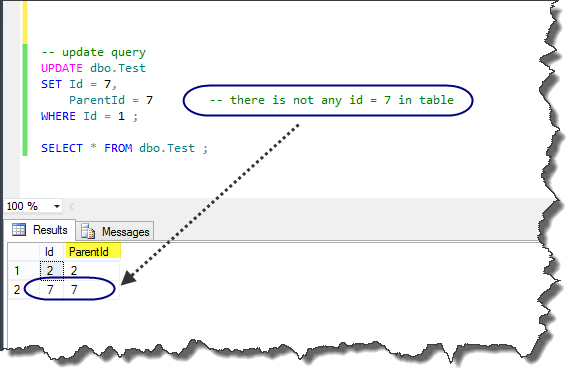
Many programmers who are experts in non SQL language, like C# and VB, are confused with this behavior at first, because they fall into the habit that processing a variable in first line of code and using the processed variable in the next line. They expected to do something like that in the T-SQL. But as I noted earlier, T-SQL is a query language over Relational Database System (Microsoft SQL SERVER), and it deals with Sets instead of variables. Therefore, the query must be operated on a Set of elements at the same time. Moreover, in each logical query process phase, all expressions processed logically at the same point of time.
Pros and Cons
This concept impacts on every situation in T-SQL querying. Some days it makes things hard to do and sometimes it makes a fantastic process that we do not expect. To illustrate these impacts I explain four real situations with their examples.
Silent Death
One of the problems that lack of attention to All-at-Once operations concept might produce is writing a code that might encounter the unexpected error.
We know that square root of a negative number is undefined. So in the code below we put two conditions inside where clause; first condition checks that Id1 is greater than zero. This query might encounter an error, because the All-at-Once operations concept tells us that these two conditions are evaluated logically at the same point of time. If the first expression evaluates to FALSE, SQL Server will Short Circuit and whole WHERE clause condition evaluates to FALSE. Therefore, SQL Server can evaluate conditions in WHERE clause in arbitrary order, based on the estimated execution plan.
-- drop test table
IF OBJECT_ID( 'dbo.Test', 'U') IS NOT NULL
DROP TABLE dbo.Test ;
GO
-- create a test table
CREATE TABLE dbo.Test ( Id1 INT, Id2 INT)
GO
-- populate with sample data
INSERT dbo.Test
( Id1, Id2 )
VALUES ( 0, 0 ), ( 1, 1 ), ( -1, -1 )
GO
-- query
SELECT *
FROM dbo.Test
WHERE
id1 > 0
AND
SQRT(Id1) = 1
If after executing the above code you do not receive any error, we need to perform some changes on our code to force SQL Server to choose another order when evaluating conditions in the WHERE clause.
-- drop test table
IF OBJECT_ID( 'dbo.Test', 'U') IS NOT NULL
DROP TABLE dbo.Test ;
GO
-- create a test table
CREATE TABLE dbo.Test ( Id1 INT, Id2 INT)
GO
-- populate with sample data
INSERT dbo.Test
( Id1, Id2 )
VALUES ( 0, 0 ), ( 1, 1 ), ( -1, -1 )
GO
-- create a function that returns zero
CREATE FUNCTION dbo.fnZero ()
RETURNS INT
AS
BEGIN
DECLARE @Result INT;
SET @Result = ( SELECT TOP (1) Id2 FROM dbo.Test WHERE Id1 < 1 );
RETURN @Result;
END
GO
-- query
SELECT *
FROM dbo.Test
WHERE
id1 > dbo.fnZero()
AND
SQRT(Id1) = 1
As illustrated in the next figure we encounter an error.
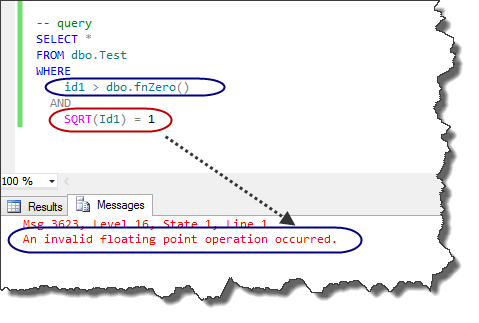
One way to avoid encountering error in this query is using CASE like this query:
-- query
SELECT *
FROM dbo.Test
WHERE
CASE
WHEN Id1 < dbo.fnZero() THEN 0
WHEN SQRT(Id1) = 1 THEN 1
ELSE 0
END = 1;
CAUTION
After publishing this article, Naomi Nosonovsky noted me that "even CASE does not provide deterministic order of evaluation with short circuiting".
For more information please see these links:
Don’t depend on expression short circuiting in T-SQL (not even with CASE)
Aggregates Don't Follow the Semantics Of CASE
Now we see another example. Although we add a condition in HAVING clause to check if Id2 is opposite to zero, because of the All-at-Once operations concept, there is a probability to encounter an error.
-- drop test table
IF OBJECT_ID( 'dbo.Test', 'U') IS NOT NULL
DROP TABLE dbo.Test ;
GO
-- create a test table
CREATE TABLE dbo.Test ( Id1 INT, Id2 INT)
GO
-- populate with sample data
INSERT dbo.Test
( Id1, Id2 )
VALUES ( 0, 0 ), ( 1, 1 ), ( 2, 1 )
GO
-- query
SELECT Id2, SUM(Id1)
FROM dbo.Test
GROUP BY Id2
HAVING
id2 <> ( SELECT Id2 FROM dbo.Test WHERE Id1 < 1 ) /* this subquery returns zero*/
AND
SUM(Id1) / Id2 = 3 ;
As illustrated in the next figure we encounter an error.
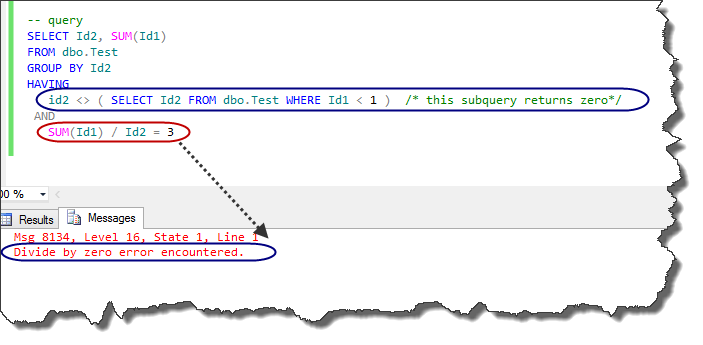
Therefore, the lack of attention to All-at-Once operations concept in T-SQL might result in encountering the unexpected errors!
Code complexity
Moreover, this concept leads to complexity in debugging T-SQL code. Suppose we have a table “Person”. This table has two columns “FirstName” and “LastName”. For some reasons the values within these columns are mixed with extra characters. The problem is to write a query that retrieve a new column as Full Name. This code produces our test data:
-- drop test table
IF OBJECT_ID( 'dbo.Person', 'U') IS NOT NULL
DROP TABLE dbo.Person ;
GO
-- create a test table
CREATE TABLE dbo.Person
(
PersonId INT IDENTITY PRIMARY KEY ,
FirstName NVARCHAR(128) ,
LastName NVARCHAR(128)
);
GO
-- populate table with sample data
INSERT dbo.Person
( FirstName, LastName )
VALUES ( N' Saeid 123 ', -- FirstName
N' Hasani ' -- LastName
) ;
GO
As illustrated in this figure the problem with column “FirstName” is that it’s mixed with extra numbers that should be removed. And the problem with column “LastName” is that it’s mixed with extra space characters before and after the real Last Name. Here is the code to do this:
SELECT PersonId ,
LEFT( LTRIM( RTRIM( FirstName ) ) , CHARINDEX( N' ' , LTRIM( RTRIM( FirstName ) ) ) - 1 ) + N' ' + LTRIM( RTRIM( LastName ) ) AS [FullName]
FROM dbo.Person ;
Because of All-at-Once operations we cannot use an alias in next column expression in the SELECT clause. So the code can be very complex to debug.
I found that one way to avoid this problem is using right Code Style and extra comments. The next code is a well formed code style of the former code with same output result and it's easy to debug.
SELECT PersonId ,
/*
Prototype:
[FullName] ::: LEFT( [FirstName Trim], [Index of first space character in FirstName Trim] - 1 ) + ' ' + [Corrected LastName]
elements:
[FirstName Trim] ::: LTRIM( RTRIM( FirstName ) )
[Index of first space character in FirstName Trim] ::: CHARINDEX( N' ' , [FirstName Trim] )
[Corrected LastName] ::: LTRIM( RTRIM( LastName ) )
*/
LEFT( LTRIM( RTRIM( FirstName ) ) --[FirstName Trim]
, CHARINDEX( N' ' , LTRIM( RTRIM( FirstName ) ) ) - 1 --[Index of first space character in FirstName Trim]
)
+ N' '
+ LTRIM( RTRIM( LastName ) --[Corrected LastName]
) AS [FullName]
FROM dbo.Person ;
Other solutions are "creating modular views" or "using Derived Table or CTE". I showed "creating modular view" approach in this Forum thread  .
.
Impact on Window Functions
This concept explains why we cannot use Window Functions in WHERE clause. We use ad absurdum argument like those we use in mathematics. Suppose that we can use Window Functions in WHERE clause. Please see the following code.
IF OBJECT_ID('dbo.Test', 'U') IS NOT NULL
DROP TABLE dbo.Test ;
CREATE TABLE dbo.Test ( Id INT) ;
GO
INSERT INTO dbo.Test
VALUES ( 1001 ), ( 1002 ) ;
GO
SELECT Id
FROM dbo.Test
WHERE
Id = 1002
AND
ROW_NUMBER() OVER(ORDER BY Id) = 1;
All-at-Once operations tell us these two conditions evaluated logically at the same point of time. Therefore, SQL Server can evaluate conditions in WHERE clause in arbitrary order, based on estimated execution plan. So the main question here is which condition evaluates first.
We can think about these two orders:
- SQL Server check if ( Id = 1002 ) first,
Then check if ( ROW_NUMBER() OVER(ORDER BY Id) = 1 )
In this order the output will be ( 1002 ).
- SQL Server check if ( ROW_NUMBER() OVER(ORDER BY Id) = 1 ) first, it means ( Id = 1001 )
Then check if ( Id = 1002 )
In this order the output will be empty.
So we have a paradox.
This example shows why we cannot use Window Functions in WHERE clause. You can think more about this and find why Window Functions are allowed to be used just in SELECT and ORDER BY clauses!
Magic Update
This is the most exciting part of this article that I love it. The question is that how to swap values of two columns in a table without using a temporary table? This code provide sample data for us:
-- drop test table
IF OBJECT_ID( 'dbo.Person', 'U') IS NOT NULL
DROP TABLE dbo.Person ;
GO
-- create a test table
CREATE TABLE dbo.Person
(
PersonId INT IDENTITY PRIMARY KEY,
FirstName NVARCHAR(128) ,
LastName NVARCHAR(128)
);
GO
-- populate table with sample data
INSERT dbo.Person
( FirstName, LastName )
VALUES
( N'Hasani', N'Saeid' ) ,
( N'Nosonovsky', N'Naomi' ) ,
( N'Price', N'Ed' ) ,
( N'Toth', N'Kalman' )
GO
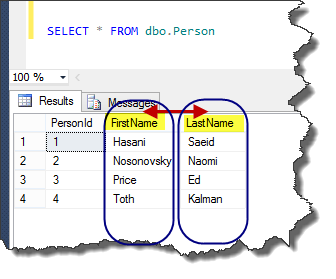
Consider that in all other non SQL languages, we have to use a temporary variable to swap values between two variables. If we want to see the problem from the non SQL programmer, we should do something like this prototype:
update Person
set @swap=Firstname
set Firstname=Lastname
set lastname=@swap
If we see the problem from a SQL programmer we can translate the above prototype by using a temporary table “#swap”. The code should be like this:
SELECT PersonId,
FirstName ,
LastName
INTO #swap
FROM dbo.Person ;
UPDATE dbo.Person
SET FirstName = a.LastName ,
LastName = a.FirstName
FROM #swap a
INNER JOIN dbo.Person b ON a.PersonId = b.PersonId
This code works fine. But the main question is that how much time above script needs to run, if we have millions of records?
If we are known with All-at-Once operations concept in T-SQL, we can do this job through one update statement with the following simple code:
UPDATE dbo.Person
SET FirstName = LastName ,
LastName = FirstName ;
This behavior is amazing, isn't it?
Exception
In definition section I noted that the query must be operated on a Set of elements. What will happen if a query deal with multiple tables? In such queries we use table operators like JOIN and APPLY inside FROM clause. By the way, these operators are logically evaluated from left to right. Because we have multiple Sets, first we need to transform them to a Set then we have All-at-Once operations concept. Therefore, this concept is not applicable to the table operators in FROM clause.
Conclusion
All-at-Once operations is one of the most important concept in T-SQL language that has an extreme impact on our T-SQL programming, code style and performance tuning solutions.