Azure Machine Learning: Developing a Recommender Solution
Introduction
Machine learning uses computers to run predictive models that learn from existing data in order to forecast future behaviors, outcomes, and trends.
Azure Machine Learning is a powerful cloud-based predictive analytics service that makes it possible to quickly create and deploy predictive models as analytics solutions. Azure Machine Learning not only provides tools to model predictive analytics, but also provides a fully-managed service you can use to publish your predictive models as ready-to-consume web services.
Read *Predictive Analytics with Microsoft Azure Machine Learning *for more details on the mechanisms of Azure Machine Learning.
Scope
This article demonstrates how Azure Machine Learning can be used to develop a Recommender Solution.
Ever wondered how websites like Amazon and EBay provides you useful suggestions and recommendations? This article is for you!
Designing the Experiment
Below are the steps to develop the experiment:
1. Add the dataset
In Azure Machine Learning, an existing dataset can be used of a new one can be loaded from an Azure Database, Azure Blob Storage, Data Feed Reader, Web Service or a Hive Query.
In this example the Movie Ratings Sample Data shall be used.
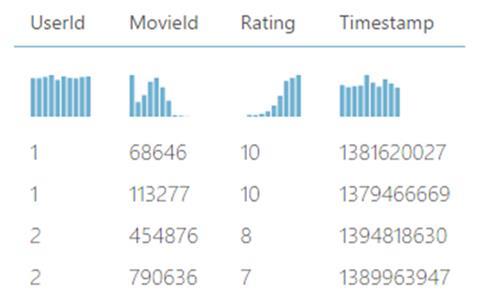
The Movie Rating sample has the following columns:
2. Exclude the columns that shall not be needed
To do so, the project columns tool object can be used. Add it in the experiment.
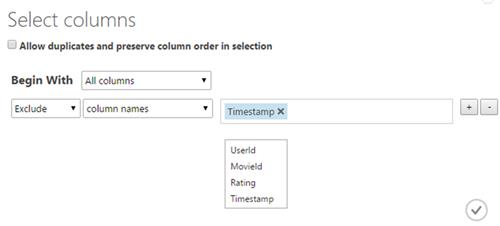
Now, from the right menu, select "launch column selector" to select the fields that shall be needed. Here, the TimeStamp column shall be excluded.
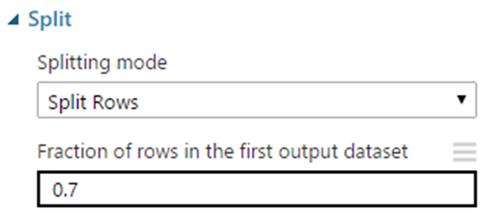
3. Split the data
Now, the data shall be partitioned into 2 distinct sets:
- Train Data: Used to “train” the recommender. That is, the algorithm shall use this data to "learn" and make predictions.
- Test Data: Used to validate the results of the recommender
Drag the split tool and connect it as below.

Deciding about the amount of data to use for training and testing is subjective.
The ratio should be typed as a decimal number between 0 and 1 to represent the percentage of rows sent to the first output dataset.
For example, if you type 0.75 as the value, the dataset would be split by using a 75:25 ratio, with 75% of the rows sent to the first output dataset, and 25% sent to the second output dataset.
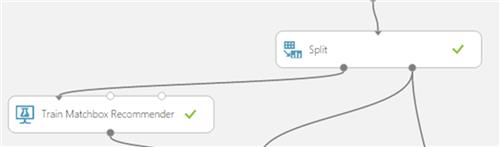
4. Add the Train Matchbox Recommender
The Train a recommendation model based on the Matchbox recommender engine. It has the ability to learn about people’s preferences from observing how they rate items such as movies, content, or other products.
This is where learning occurs.
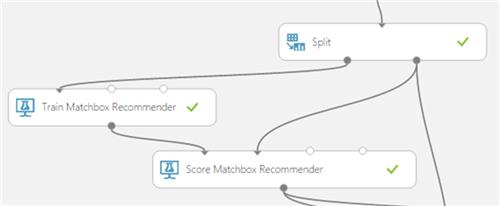
5. Add the Score Matchbox Recommender
The Score Matchbox Recommender Scores predictions for a dataset using the Matchbox recommender.
It generates results based on a trained recommendation model.
6. Add the Evaluate Recommender
The Evaluate Recommender tests the accuracy of recommender model predictions
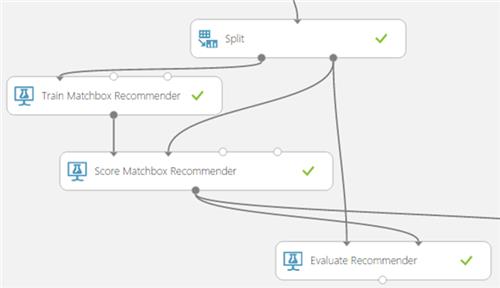
At this point in time, the solution is like below and can be executed by clicking on the Run button.
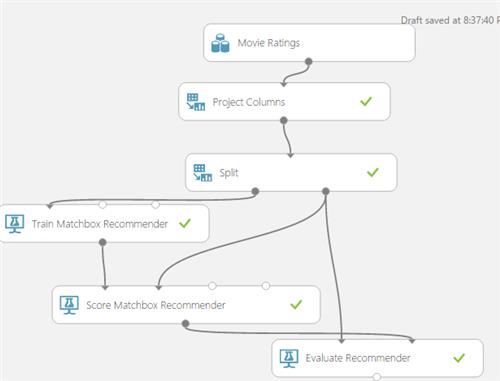
After its execution, if click on the output of the** Score Matchbox Recommender** and click on visualize, all the movie IDs together with their respective "related" movies" will now be displayed as shown below.
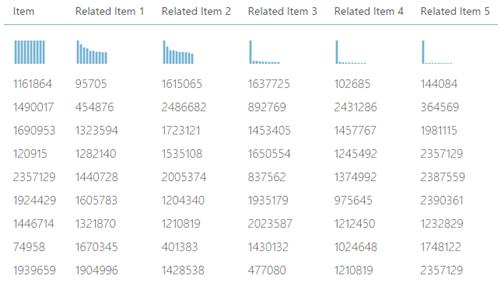
However, this won't be much useful for analysis purposes. What will be meaningful, is to have the movie names instead of the movie IDs.
Fortunately, the Join operator can be used as shown below.
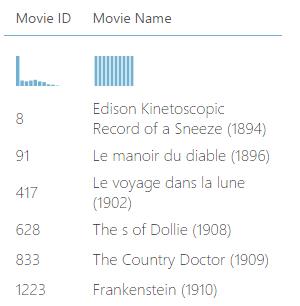
7. Add the IMDB Movie Title Sample
This sample has all the Movie Names and their respective Movie IDs.
8. Add the Meta Data Editor and make it treat the values as String
This can be done by selecting all the columns from the column selector and set the data type to String from the right pane.
9. Join the Movie IDs from the Meta Data editor with the one from the Score MatchBox Recommender
In the column selector, select "Item" from the left column and select "Movie Id" from the Right column selector.
This will join the Item column form the Score Match Box Recommender to the Movie ID from the IMDB Movie titles. So,if the experiment is executed again, the Movie Name and all the related Movie IDs shall be listed as below.
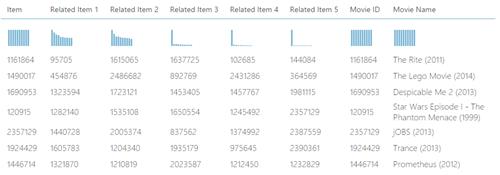
Now,the names of the related movies shall be needed too! To do so, proceed with the step below.
10. Add another Join operator, to join the result from the previous join (result) with the Movie Titles sample
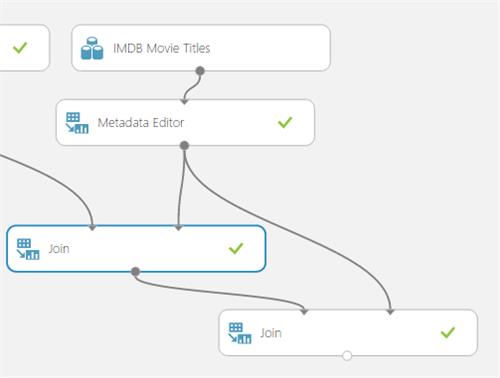
In the left column selector, select related item 1 and in the right column selector, select Movie ID.
This will join the related movie id 1 with the Movie Titles sample to return the name of the related movie.
Run the experiment to obtain a list of movie and their related movies.
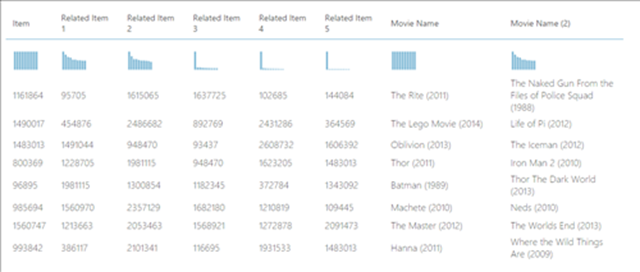
From this experiment, we have a list of movies (Movie Name) and their Related Movie (Movie Name (2)).
For example, we can deduct that people who like Thor also liked Iron Man.
See Also
Another important place to find an extensive amount of Cortana Intelligence Suite related articles is the TechNet Wiki itself. The best entry point is Cortana Intelligence Suite Resources on the TechNet Wiki.