Visual Studio: Web Scraping using Node.js
Web Scraping
Web Scraping is the software technique of extracting the information server side web applications. In this blog we see how things work by simply creating a web scrapper using the DOM Parsing technique and tool which I am using is Node.js.
Before we proceed , I want you to aware of following concepts.
Serialization and Deserialization
Serialization is the process of converting an object into a stream of bytes in order to store the object or transmit it to memory, a database, or a file. Its main purpose is to save the state of an object in order to be able to recreate it when needed. The reverse process is called Deserialization.
So the data of web is serialize from the web and then we use deserialization to get that data.
Json
Java Script Object Notation or Json is syntax for storing and exchanging the data and is easier to use alternative to XML.Json is language independent and light weight data interchange format.
We are going to use Json in our process.Our data will be in Json Format .
Node.Js
An open source ,cross-platform runtime environment for developing server side web application.Node.js will be our tool during our scrapping process.
Request and Cheerio
Request and Cheerio are our npm packages .Cheerio doesn’t try to emulate a full implementation of the DOM. It specifically focuses on the scenario where you want to manipulate an HTML document using jQuery-like syntax. As such, it compares to jsdom favorably in some cases, but not in every situation.
Cheerio itself doesn’t include a mechanism for making HTTP requests, and that’s something that can be tedious to handle manually. It’s a bit easier to use a module called request to facilitate requesting remote HTML documents. Request handles common tasks like caching cookies between multiple requests, setting the content length on POSTs, and generally makes life easier.
If you don’t understand any of above concepts , simply ignore them and lets create a scrapper from here now. :)
Set up IdE
I am using
- Windows 10 x64 .
- Visual Studio 2015(Community )
- Visit Node.js and download your installer according to your specifications .
After you have your Node.js installed , activate your visual studio 2015 and create a new project there.
https://zainnisar237.files.wordpress.com/2015/12/14.png?w=700
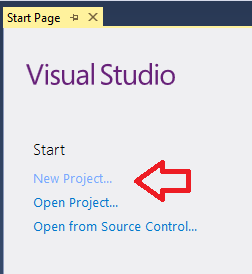{kind=link}
Select Template
Now its time to select your template .
- Select Node.js
- Select Basic Azure Node.js Express 4.
- Name it , for instance , MyScrapper
https://zainnisar237.files.wordpress.com/2015/12/21.png?w=700
{kind=link}
Install NPM Package
Now install your NPM packages , as shown in the image.
https://zainnisar237.files.wordpress.com/2015/12/31.png?w=700
{kind=link}
https://zainnisar237.files.wordpress.com/2015/12/41.png?w=700
{kind=link}
after the package is loaded , write request and cheerio and then click install.
https://zainnisar237.files.wordpress.com/2015/12/51.png?w=700
{kind=link}
https://zainnisar237.files.wordpress.com/2015/12/61.png?w=700
{kind=link}
Uninstall Jade
When you are done , uninstall Jade .
https://zainnisar237.files.wordpress.com/2015/12/71.png?w=700
{kind=link}
Changes in APP.js
- Go to app.js.
- comment the views as shown in image , as we are not displaying any.
Before
https://zainnisar237.files.wordpress.com/2015/12/81.png?w=700
{kind=link}
AFTER
https://zainnisar237.files.wordpress.com/2015/12/91.png?w=700
{kind=link}
When you are done , do some further changes as shown in the image .
Before
https://zainnisar237.files.wordpress.com/2015/12/102.png?w=700
{kind=link}
AFTER
https://zainnisar237.files.wordpress.com/2015/12/111.png?w=700
{kind=link}
Request and Cheerio
- Go to Routes(node).
- Select users.js.
- Add the request and cheerio as shown in image.
https://zainnisar237.files.wordpress.com/2015/12/121.png?w=700
{kind=link}
Website URL
select the website you want to scrape and save its url in the variable as shown in the image.For instance , I choose bbc.com
https://zainnisar237.files.wordpress.com/2015/12/131.png?w=700
{kind=link}
Edit Function
Just simply edit your router.get function as shown in the image.The router.get function is shown in the image above and you can edit it by writing the code mentioned in below image.
https://zainnisar237.files.wordpress.com/2015/12/141.png?w=700
{kind=link}
DOM Parsing .
Programs can retrieve the dynamic content generated by client-side scripts, by embedding the browsers. These browser controls also parse web pages into a DOM tree, based on which programs can retrieve parts of the pages.
DOM is a language independent ,cross-platform convention used for interacting with objects in HTML ,XML,XHTML.
- Open website you want to scrape in browser.
- for instance I open bbc.com in Google Chrome.
- Click Inspect.
- Image is there to help you.
https://zainnisar237.files.wordpress.com/2015/12/15.png?w=700
{kind=link}
Code Function
Code the function now , as you can see in above image that we are traversing the DOM , as you can see in image that I have selected the data shown in red circular region and in the inspect window , it gives me the relative dom and then you can write code for it
scrapeDataFromHtml is our function ,and we create variables in the function for every item that we want to scrape from the website and then the data is serialize from website in Json format and then we have it once deserialization is done .In this case the circular red region gives me its relative node in inspect window.
- First we reach at url.
- Then we traversed DOM.
- Select our Nodes ,the desired data we want to scrape
- Create your function for instance scrapeDataFromHtml
- In this function , store all the data you want to scrape from website in variables .
- Write your logic .For multiple values you can use an array.
- span and image are two things we want to scrape .
https://zainnisar237.files.wordpress.com/2015/12/161.png?w=700
{kind=link}
Run Application
Now run your application and its working :).
https://zainnisar237.files.wordpress.com/2015/12/171.png?w=700
{kind=link}
Conclusion
The simple example above helps you to understand what is scrapping and how stuff works. Happy Coding :)