MPP & Distribution in Azure SQL Data warehouse
Introduction
Azure SQL Data warehouse is Microsoft's data warehouse service in Azure Data Platform, that it is capable of handling large amounts of data and can scale in just few minutes.
Two of Azure SQL Data warehouse's very important concepts are MPP and distribution : These concepts define how your data is distributed and processes in parallel.
Massively Parallel Processing (MPP)
Let's start with the general architecture of Azure SQL Data warehouse.
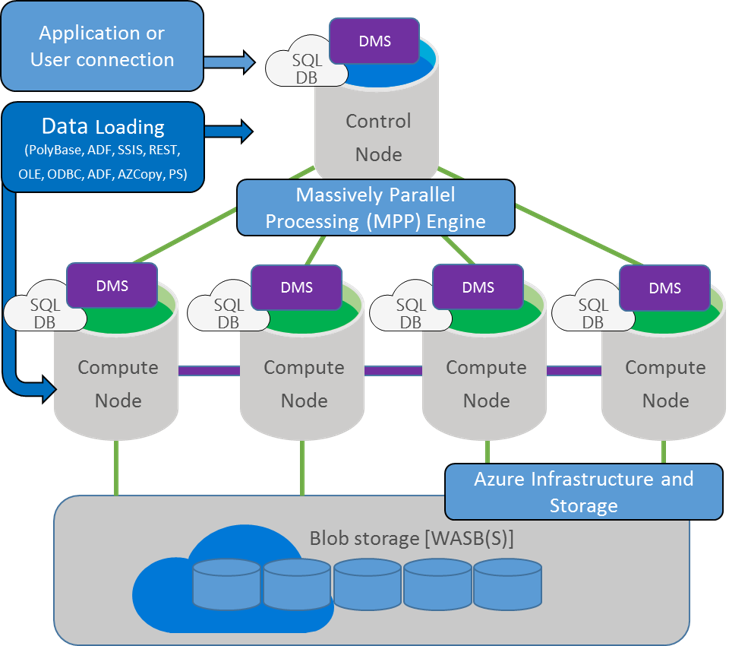
Conceptually, you have a control node on which all applications and connections interact, each interacts with a multitude of compute nodes.
The control node retrieves the input request and then analyzes it before sending it to the compute nodes. Calculation nodes run the query on their databases and return the results to the control node that collects these results.
The data is stored in Azure Blob storage and is not attached to the compute nodes. That's why you can do the scale out, scale in or even suspend you ADW quickly without losing any data.
ADW splits data between 60 databases. All the time, regardless of what you do. It is a constant.
Knowing that you can change the number of compute nodes indirectly by requesting more Data Warehouse Unit (DWU) on your instance of ADW.
ADW databases implicitly pool on the compute nodes. It is quite easy, now that you know that there are 60, to deduce the number of compute nodes from the DWU using the following table :
| DWU | # Compute nodes | # DB per node |
| 100 | 1 | 60 |
| 200 | 2 | 30 |
| 300 | 3 | 20 |
| 400 | 4 | 15 |
| 500 | 5 | 12 |
| 600 | 6 | 10 |
| 1000 | 10 | 6 |
| 1200 | 12 | 5 |
| 1500 | 15 | 4 |
| 2000 | 20 | 3 |
| 3000 | 30 | 2 |
| 6000 | 60 | 1 |
Distribution
Note that the data load in ADW is stored in 60 databases. What data is stored in which database?
Normally, with a simple SELECT query on a table and distributed data uniformly, you should not worry about it, right? The query will be sent to the compute nodes, they will query on each database, and the result will be merged together by the control node.
However, once you start attaching data from multiple tables, ADW will have to do Data Movement, in other words it will swap data around one database to another in order to join the data. It is impossible to avoid this operation in general, but you should try to minimize it for better performance.
The location of the data is controlled by the distribution attribute of your tables. By default, tables are distributed in round robin mode : data goes first to database 1 then 2 then 3 ...
You can control where your data goes by using the hash distribution method. Using this method, you can specify when creating your table, that you want to use the hash algorithm and column to use. This ensures that the data rows with same hash column value will be in the same table. However, it does not guarantee that a column value of two hashes will end up in the same databases.
So let's look at a simple example of round-robin table :
CREATE TABLE [dbo].DimProduct
(
ProductID INT NOT NULL,
ProductName VARCHAR(50) NOT NULL,
Price DECIMAL(5,2) NOT NULL,
CategoryID INT NOT NULL
)
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
And now with a hashing algorithm :
CREATE TABLE [dbo].DimProduct
(
ProductID INT NOT NULL,
ProductName VARCHAR(50) NOT NULL,
Price DECIMAL(5,2) NOT NULL,
CategoryID INT NOT NULL
)
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(CategoryID)
)
In this part, we specified that the hash is taken from the CategoryID column. As all products of the same category will be stored in the same database.
So what did we gain by making sure that the products of the same categories are stored in the same DB?
If we want to get the sum of the number of products per category, we can now do it without data movement because we are sure that the rows for a given category will all be in the same database.
Additionally, if we want to attach data from another table to CategoryID, this join may occur "locally" if the other table has a hash distribution on the CategoryID. You have to think about the type of queries you are going to have and also make sure that the data will be distributed uniformly.
It is recommended that you use distribution control on columns that are not updated and distribute the data uniformly, avoiding data bias in order to minimize the movement of data.
Conclusion
In this article we explain the different ways your data is distributed around Azure Data Warehouse (ADW) and how compute nodes access your data and how you can control their distribution.
Other Languages
This article is also available in the following languages: