Azure data factory service Step-by-Step: configuration and build simple data pipeline
Introduction
The purpose of this article is to provide high level technical overview & setup guide for Azure data factory service. This guide has step by step approach that can be followed in order to create Azure data factory service and build simple pipeline for integration and transformation of any data.
What is Azure Data Factory
Azure data factory is Microsoft’s cloud version of extract-transform-load (ETL), extract-load-transform (ELT) tool which can be used for integration and transformation of any data. Whether they’re on on-premises or Azure or on another public cloud such as AWS & GCP this tool allows integration with almost zero code effort.
Using Azure Data Factory, you can create and schedule data-driven workflows (called pipelines) without any code. Pipeline can ingest data from any data source where you can build complex ETL processes that transform data visually with data flows or by using compute services such as Azure HDInsight Hadoop, Azure Databricks, and Azure SQL Database.
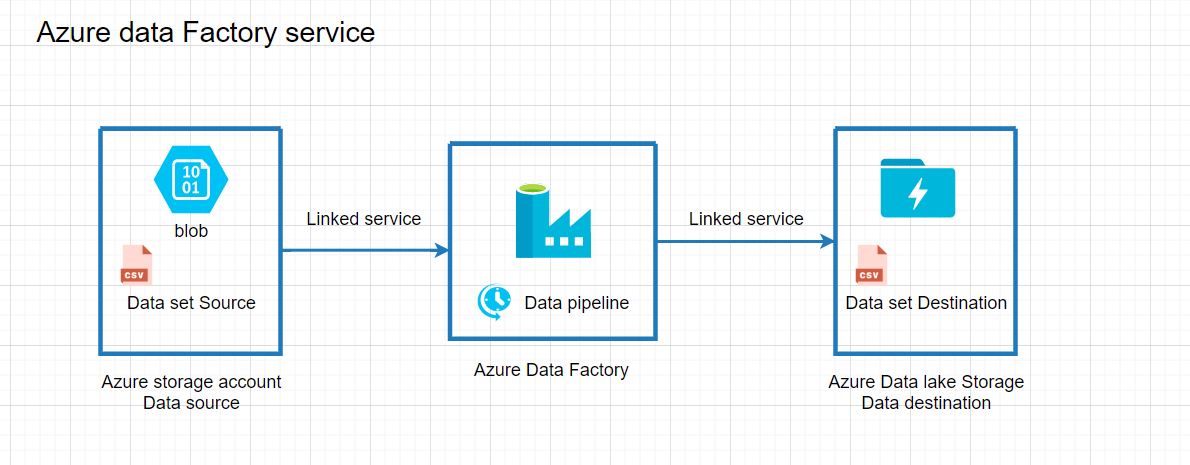
Azure data factory is composed of many different components which we will cover in the next articles but let's start with listed components.
Linked service
Linked service is kind of connections string in SQL that define the connection information needed for Data Factory to connect to external resources. ADF has various linked service which can be used as per the scenario you have.
Data set
A dataset is an intermediate layer between a pipeline and data store. Data sets identify data within different data layers, such as tables, files, folders and documents.
Data Pipeline
Data Pipeline is a logical group of activities to process the data from start to an end. The activities in a pipeline define actions to be performed for the data. For example, you can use a copy activity to which copies the data from an Onprem SQL Server to Azure Blob Storage or Data lake storage.
Now we understand what Azure Data factory is so let's start with very simple usecase.
Use case
Let's say customer has data (its csv file) that is stored in Azure storage account and now they want to copy the data into Azure data lake storage for further process. But there is small problem here, Customer has custom analytic application which only understand "Comma separated" values and data we have at source location is "Pipe separated not Comma". Therefore we are not just copying the data but we also need to change the Delimiter-separated values from Pipe to Comma.
We will use Azure data factory service to perform the use case.
Prerequisites
- An active Azure subscription
- Azure data factory (we'll cover in the article)
- Create new Azure storage account (this will used as data source)
- Create new Azure data lake V2 account (this will used as destination of our processed data)
Create Azure Data factory service
In this step we use Azure subscription to create Azure data factory service.
Sign in to the Azure account with your valid ID and follow New Resource --> Analytics --> Data Factory
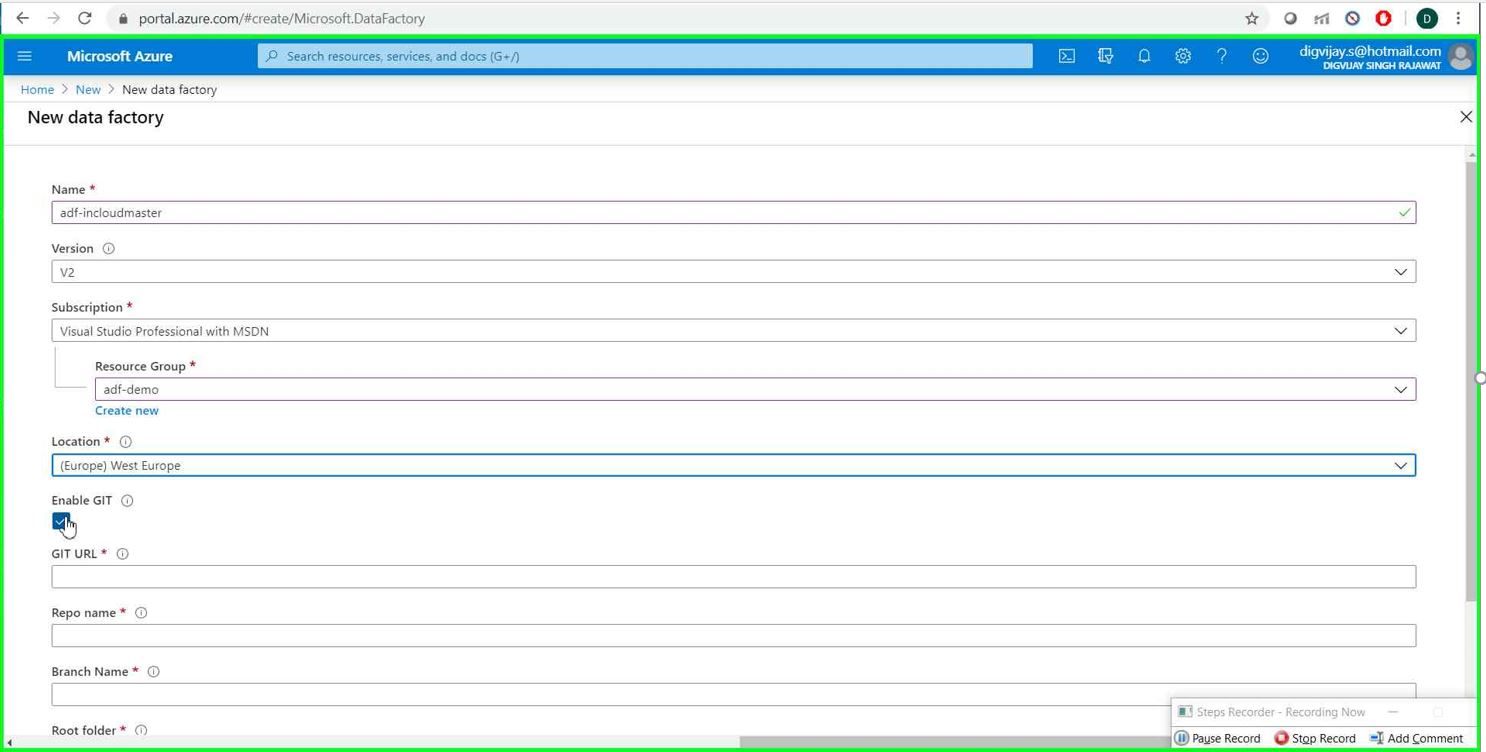
Give the name of your data factory service. Select version as V2 and then chose subscription (in case you have multiple Azure accounts associated with your ID)
It'll ask for resource group you want to use for your ADF service.
Select the region for your ADF service
Uncheck Enable GIT for now (I'll come back to this option in my upcoming article) and hit on Create button
(One important thing to note that the name of the Azure data factory mush be globally unique)
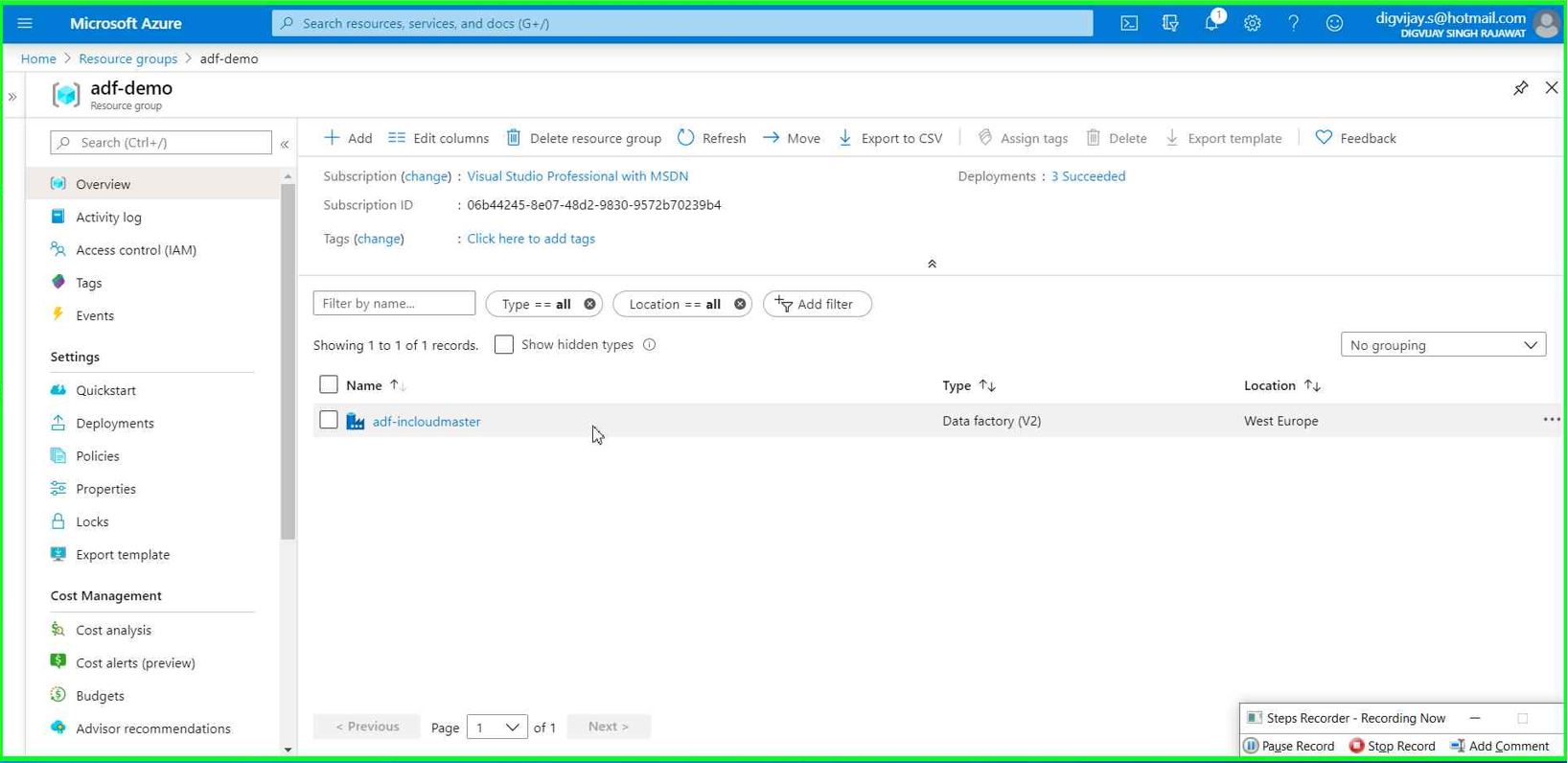
It won’t take more than few seconds to create after that you’ll see ADF service under the targeted resource group.
Create Azure blob storage
Azure Blob storage is another service which allow us to store any type of data in cloud. We'll use this blob as source for our data pipeline.
You can follow below steps to create that service
Go to your Resource Group --> Click Add button --> Storage --> Storage account - blob,file.table.queue
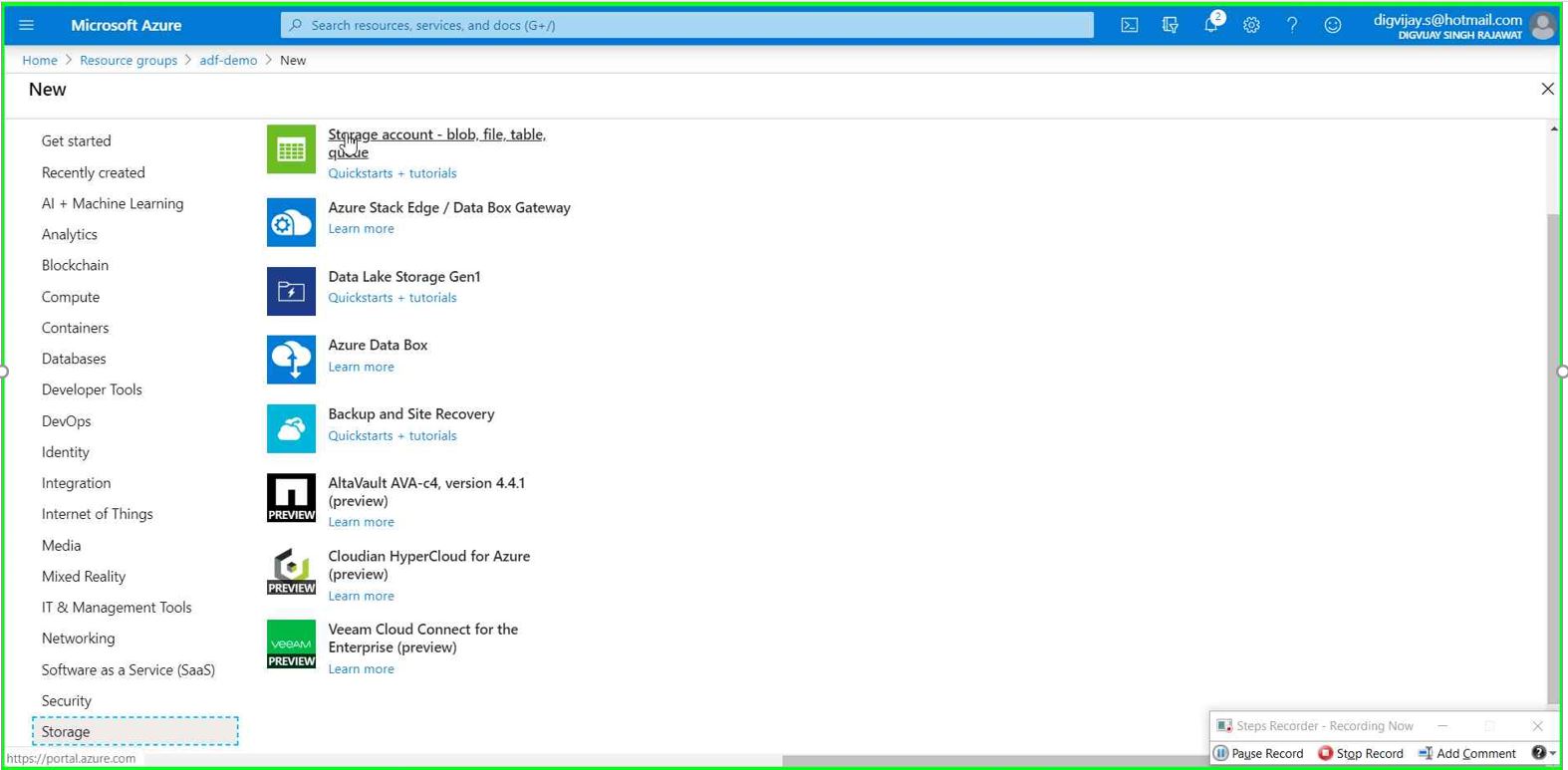
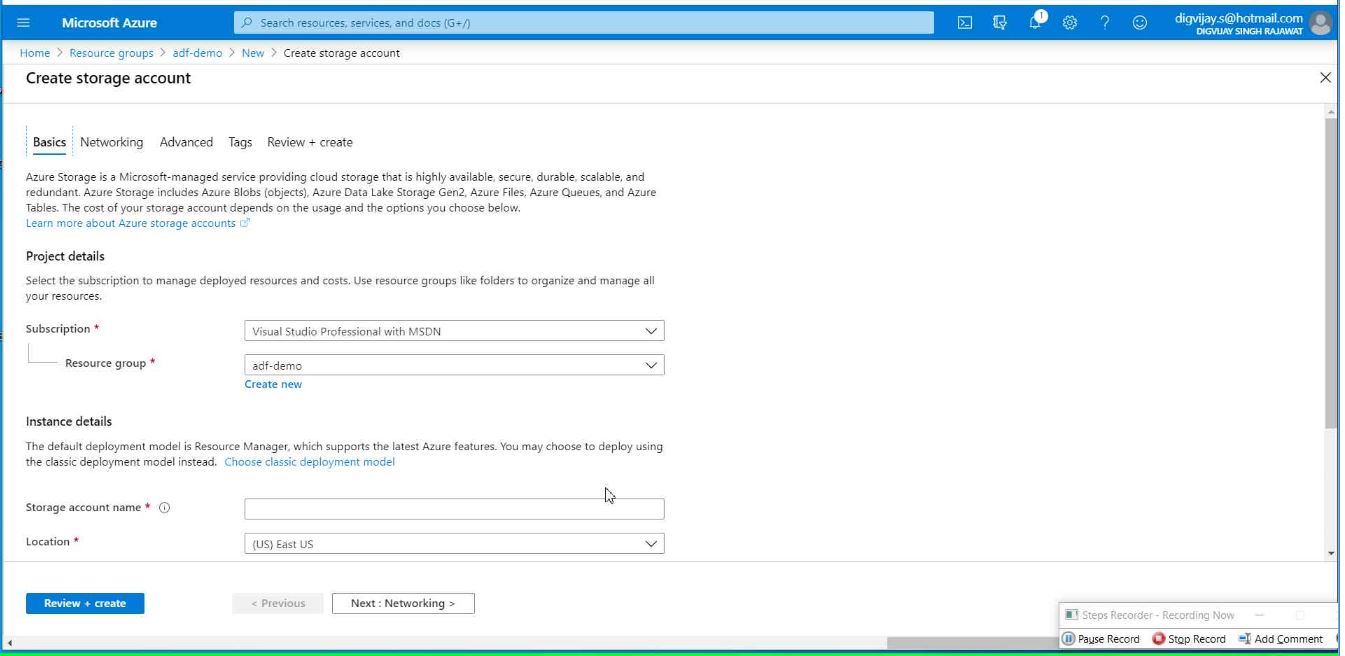
Give the name of your storage account and select region(All your Azure resources must be under the same region
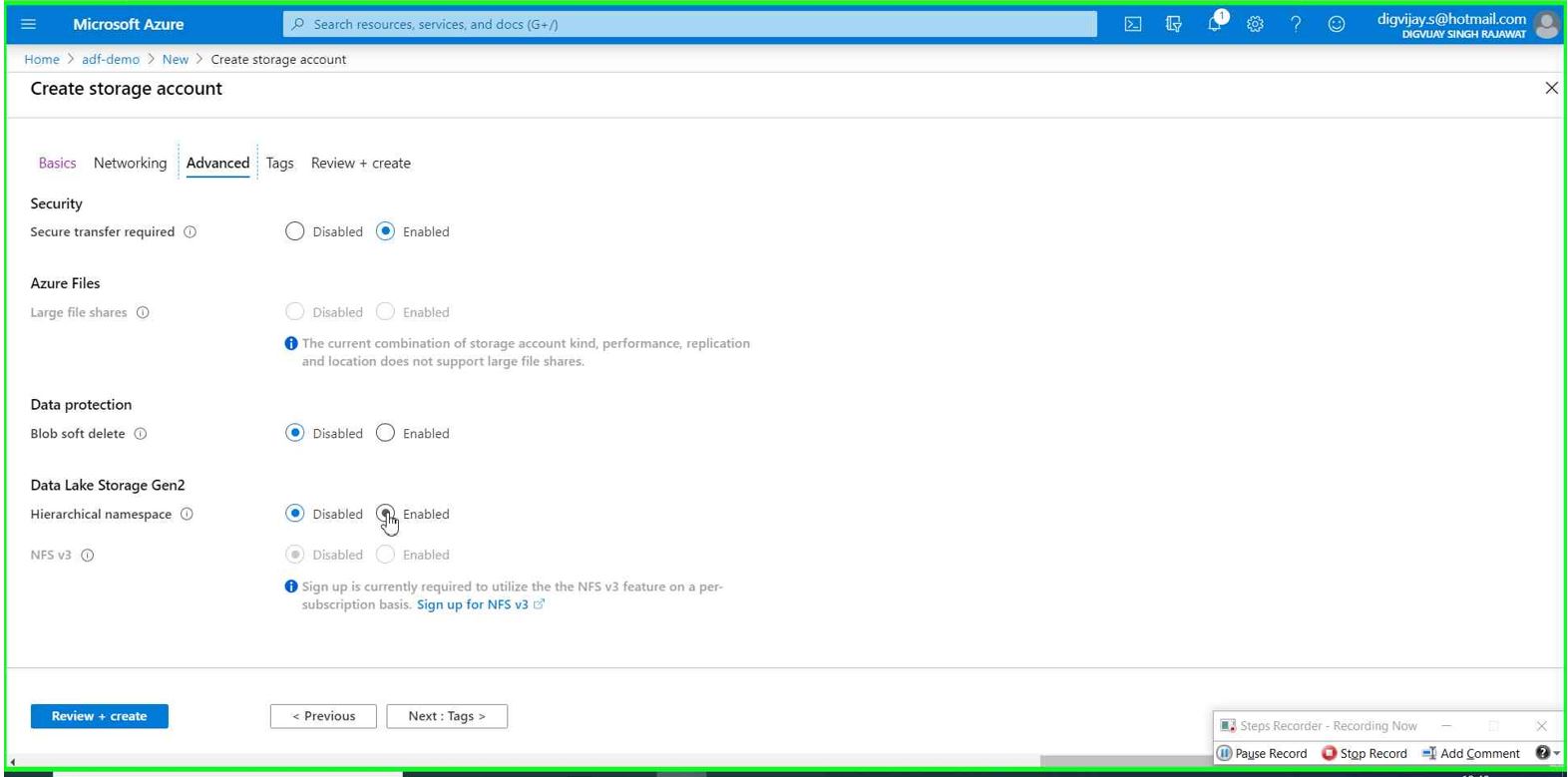
Create Azure data lake storage
ADL storage service can be created the same way as Azure storage account but there is additional setting within advanced option- You need to enable Data lake storage Gen2 option as per the picture below.
You now should see below three Azure services under the resource group.
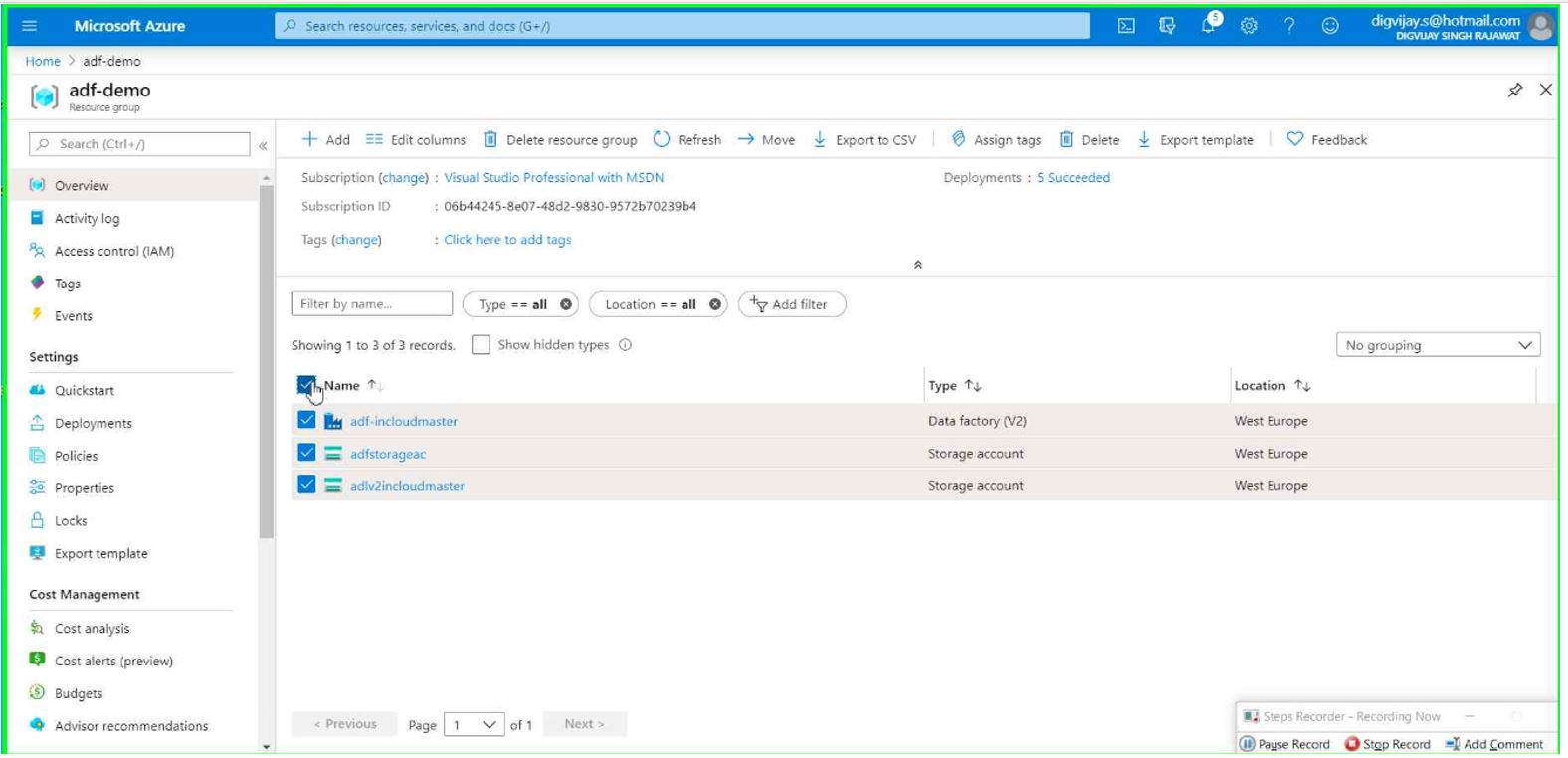
Our environment is now ready to move and transform the data based on the above usecase.
Create Linked service (Connection)
We need to create connections before we build data pipeline.
In our example, we are using Azure blob storage as source and Azure data lake storage as destination so we need to create connections for each
You can follow below steps to create linked service for Azure blob storage.
Go to the Resource GroupàAzure data factory resourceà Click on Author & Monitor
This will redirect you to the new page from where you can access Azure data factory service.
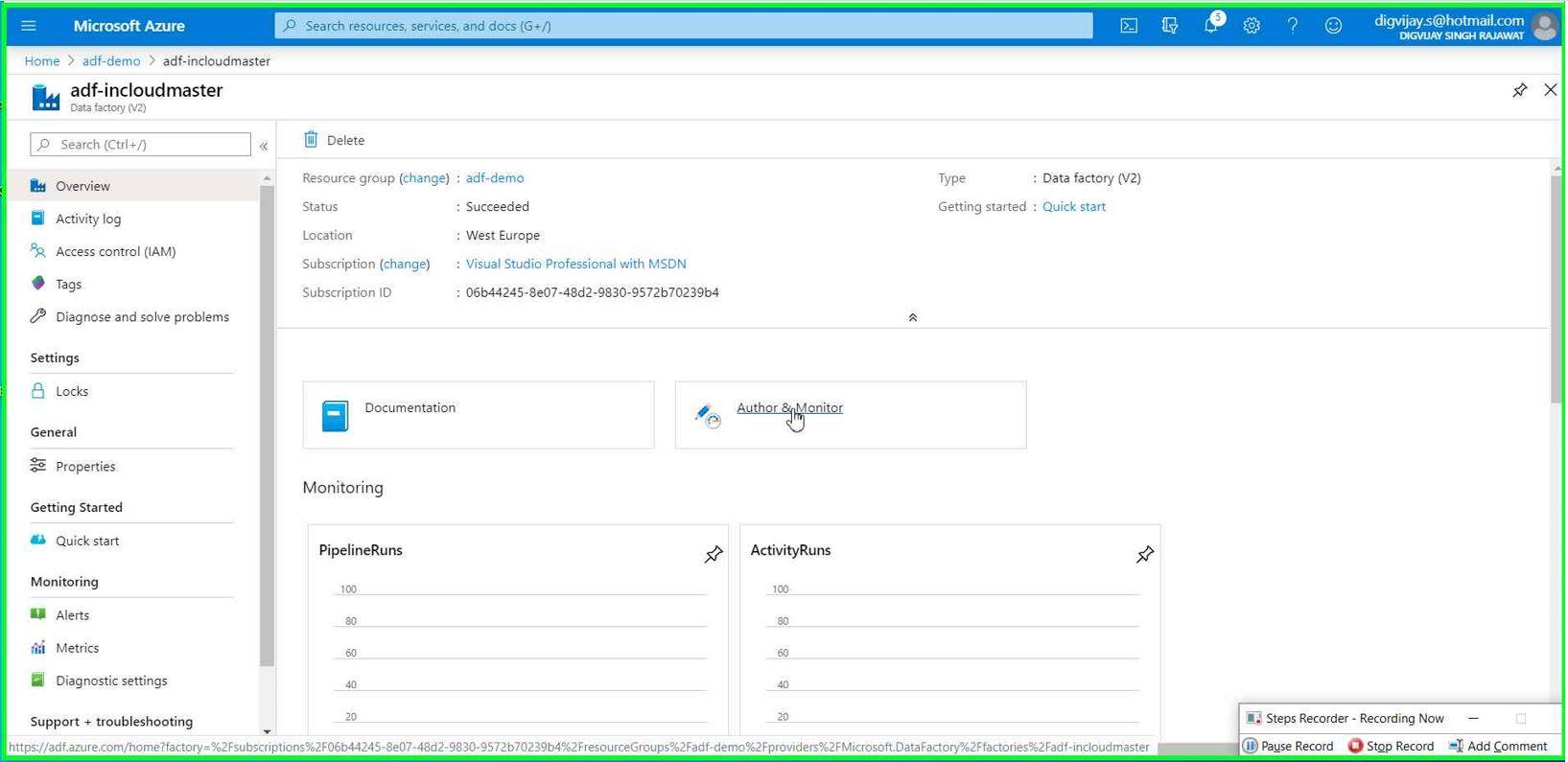
Click on Author option.

Click on Connections (Down left) --> New
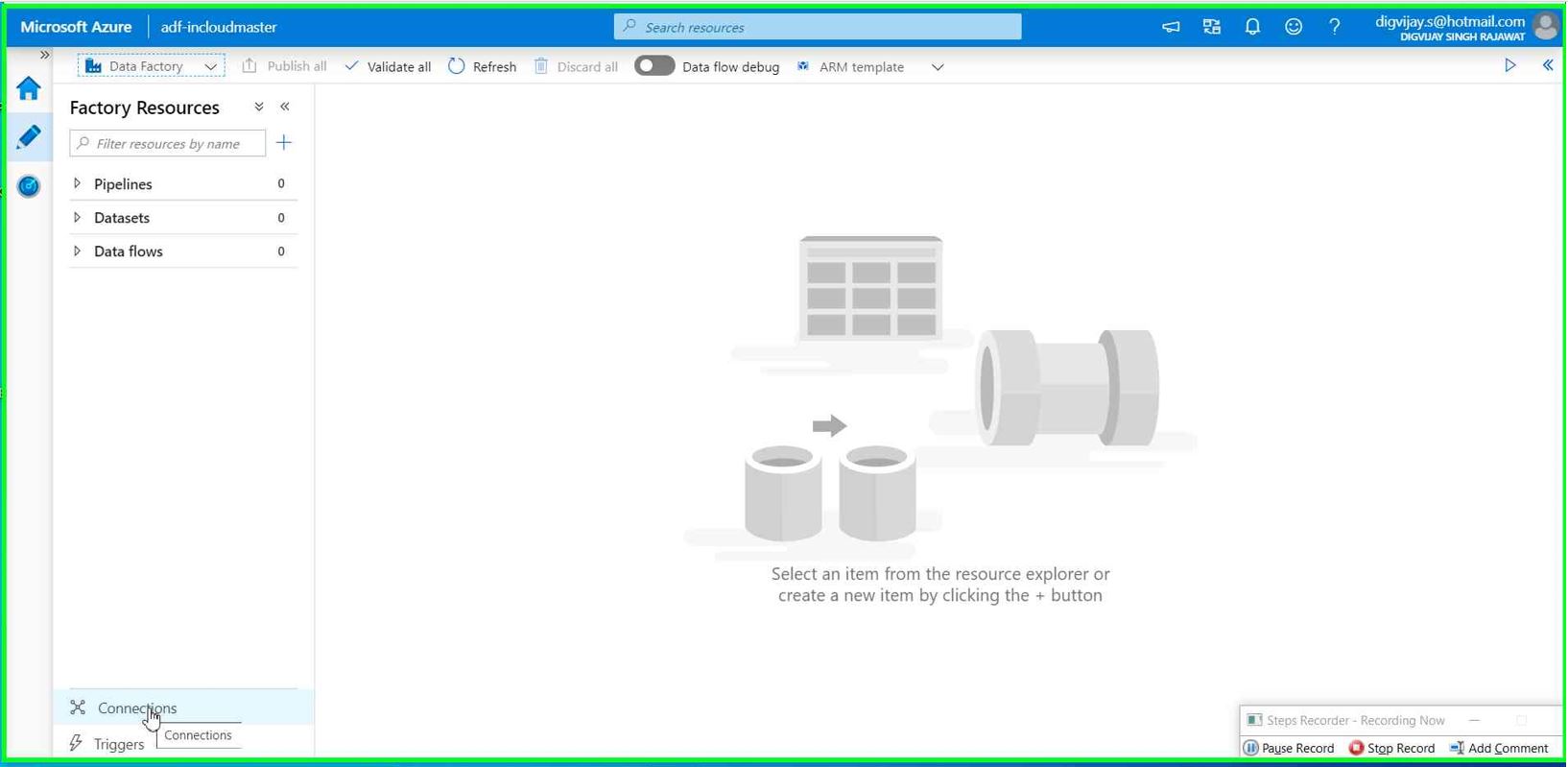
Search for Azure blob storage
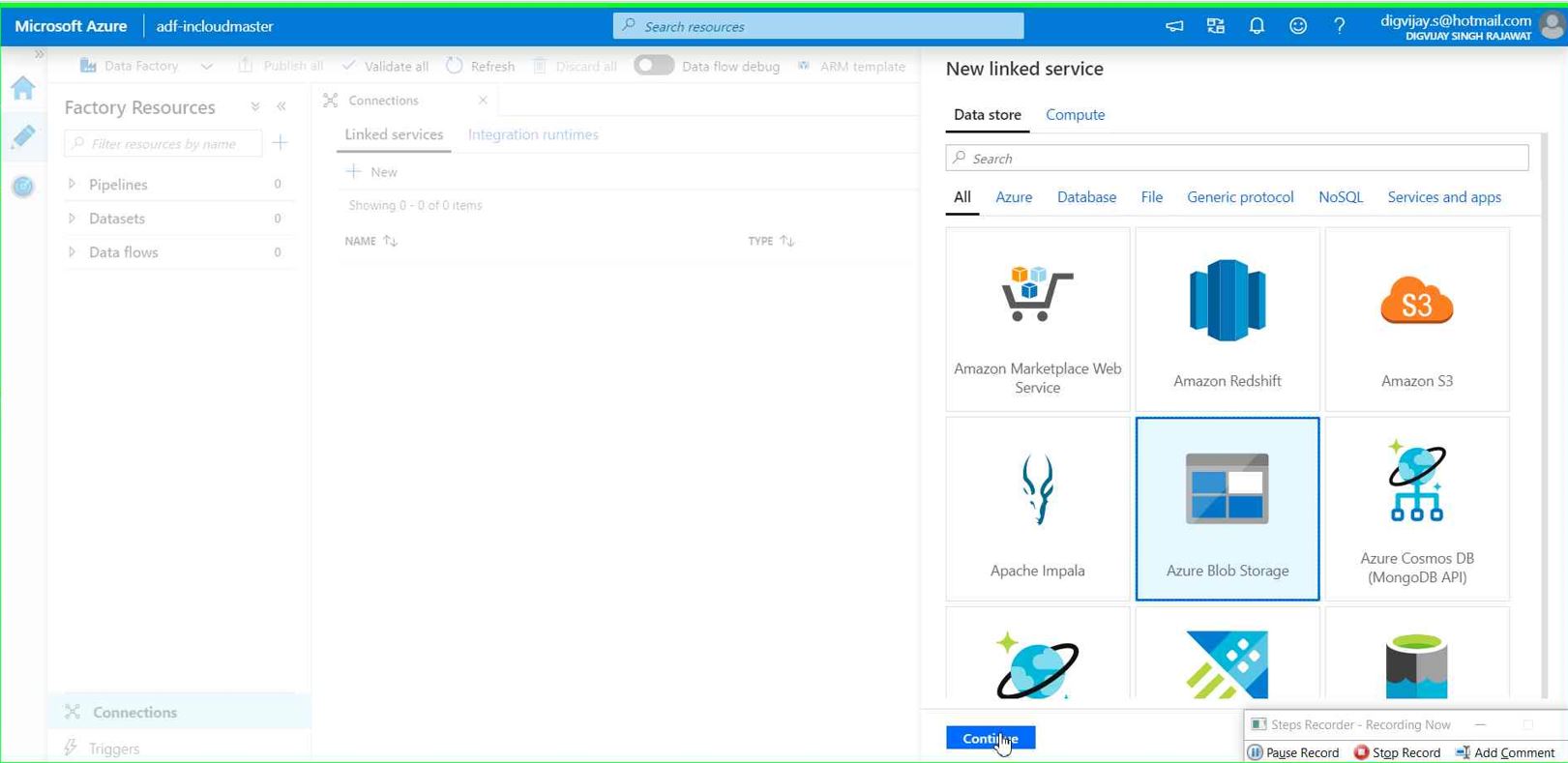
Give the connection name you want. Use all default settings for now and then click on “Test connection”
You will see a message Connection successful. if not, check the connection settings and access.
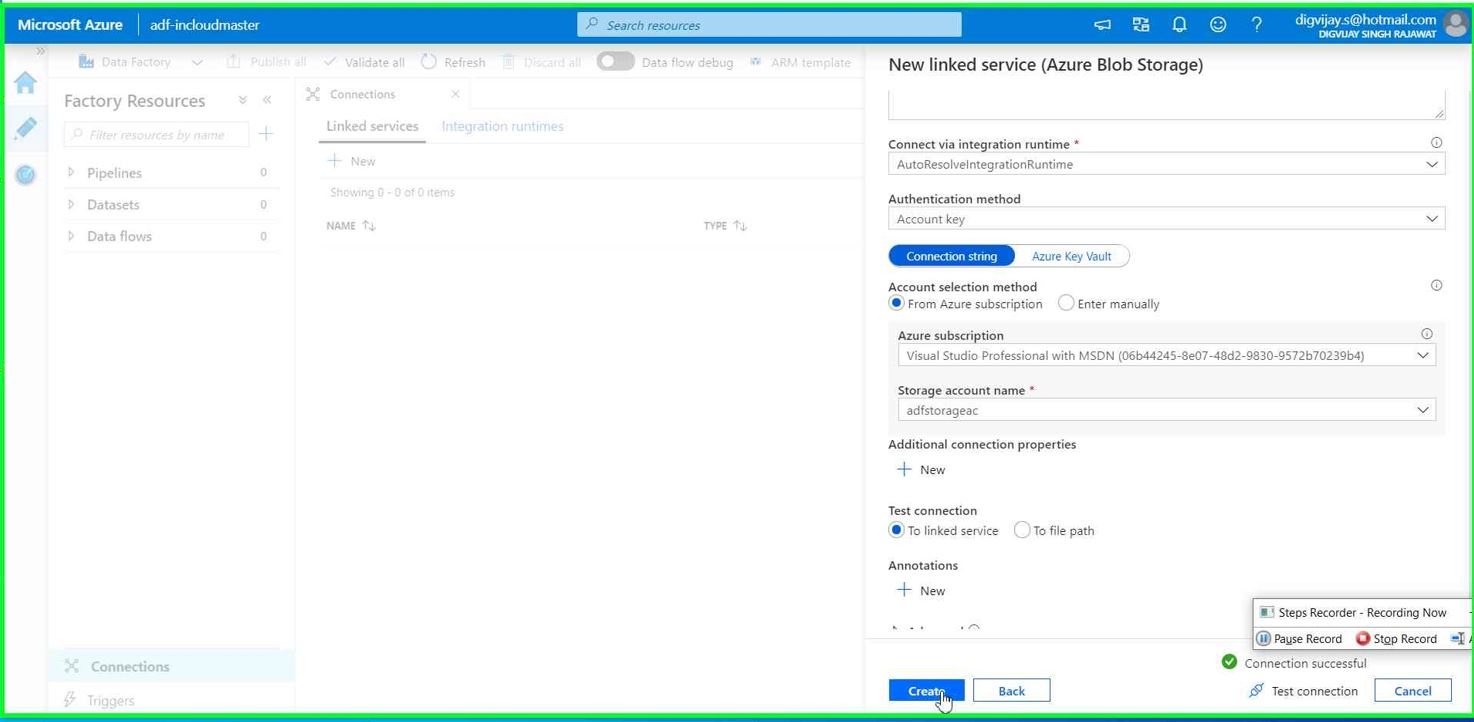
We have created linked service for source. now we need to create linked service for destination.
Click on New and search for Azure data lake storage Gen2
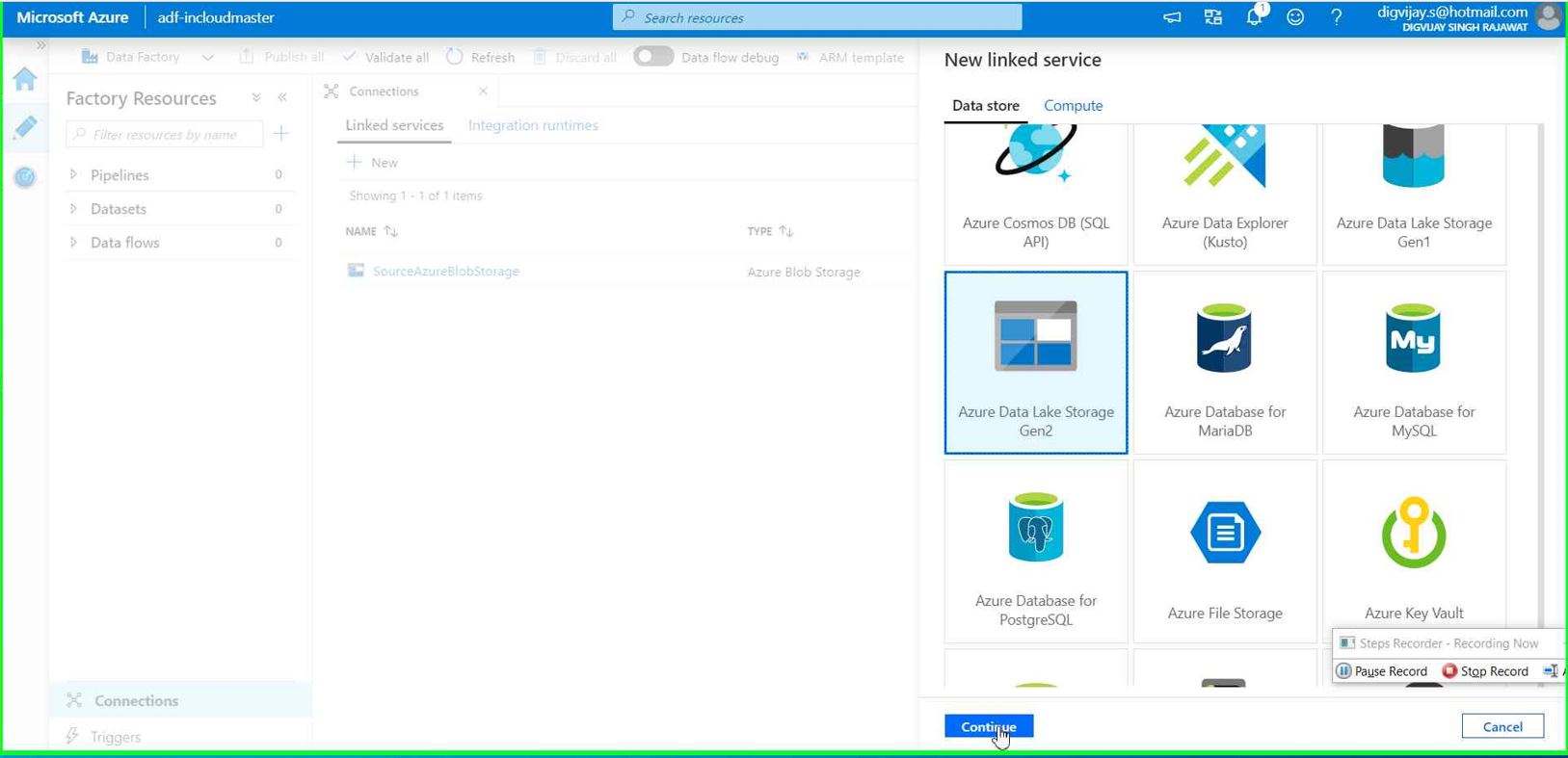
Give the connection name you want. Use all default settings for now and then click on “Test connection”
You will see message a Connection successful. if not, check the connection settings and access.
You will now see two connections (Linked service)
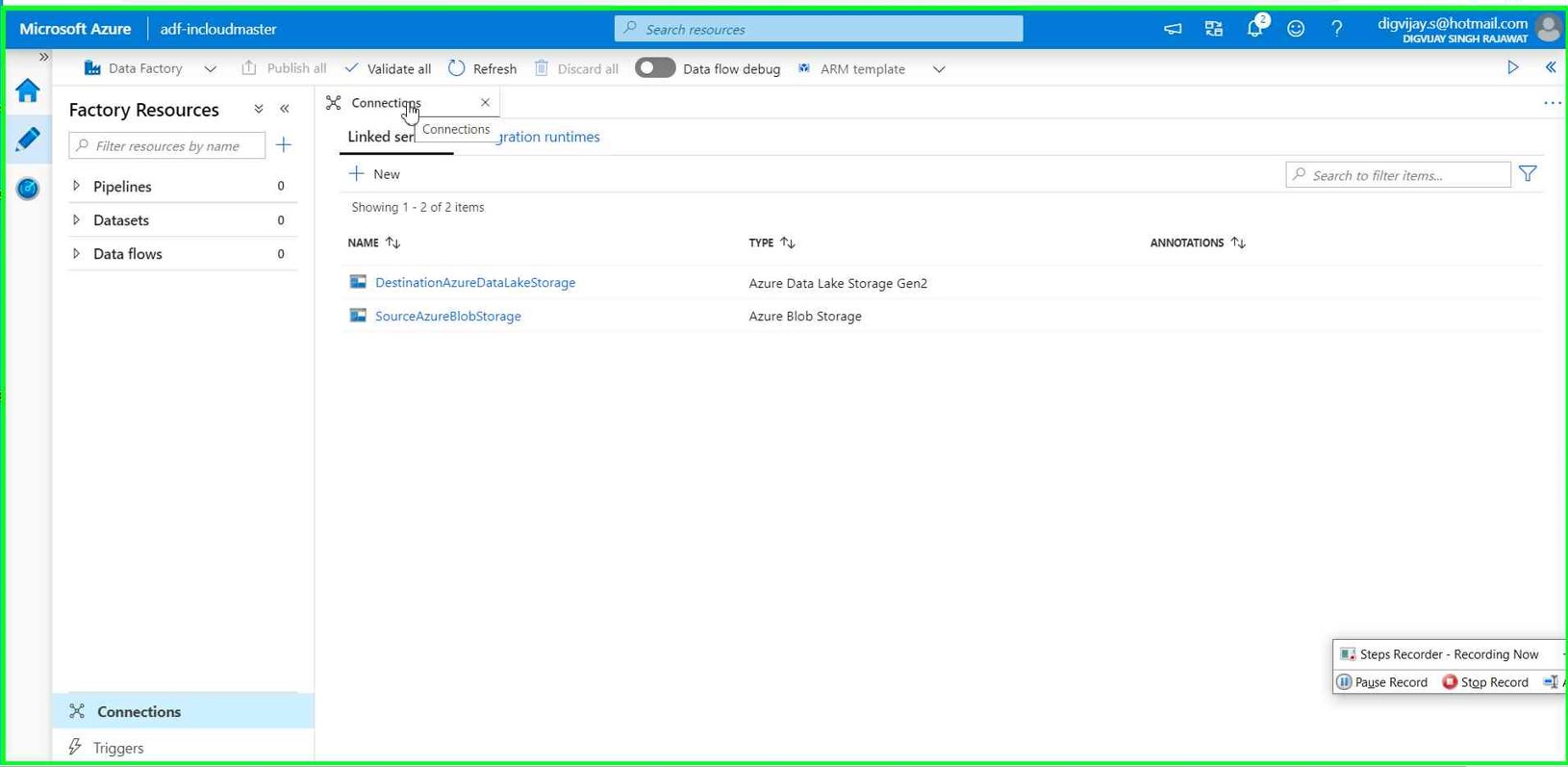
Now we are ready to build data pipeline.
For data pipeline, We need to select activity from Home button. If you remember in our usecase we need to perform below things.
- Move the data from Azure blob storage to Azure data lake storage.
- Change the Delimiter-separated values from Pipe(|) to Comma(,)

Follow the steps to fulfil both the requirements.
Go to the **Home ** and Click on “Copy Data” Give the task name and default settings.
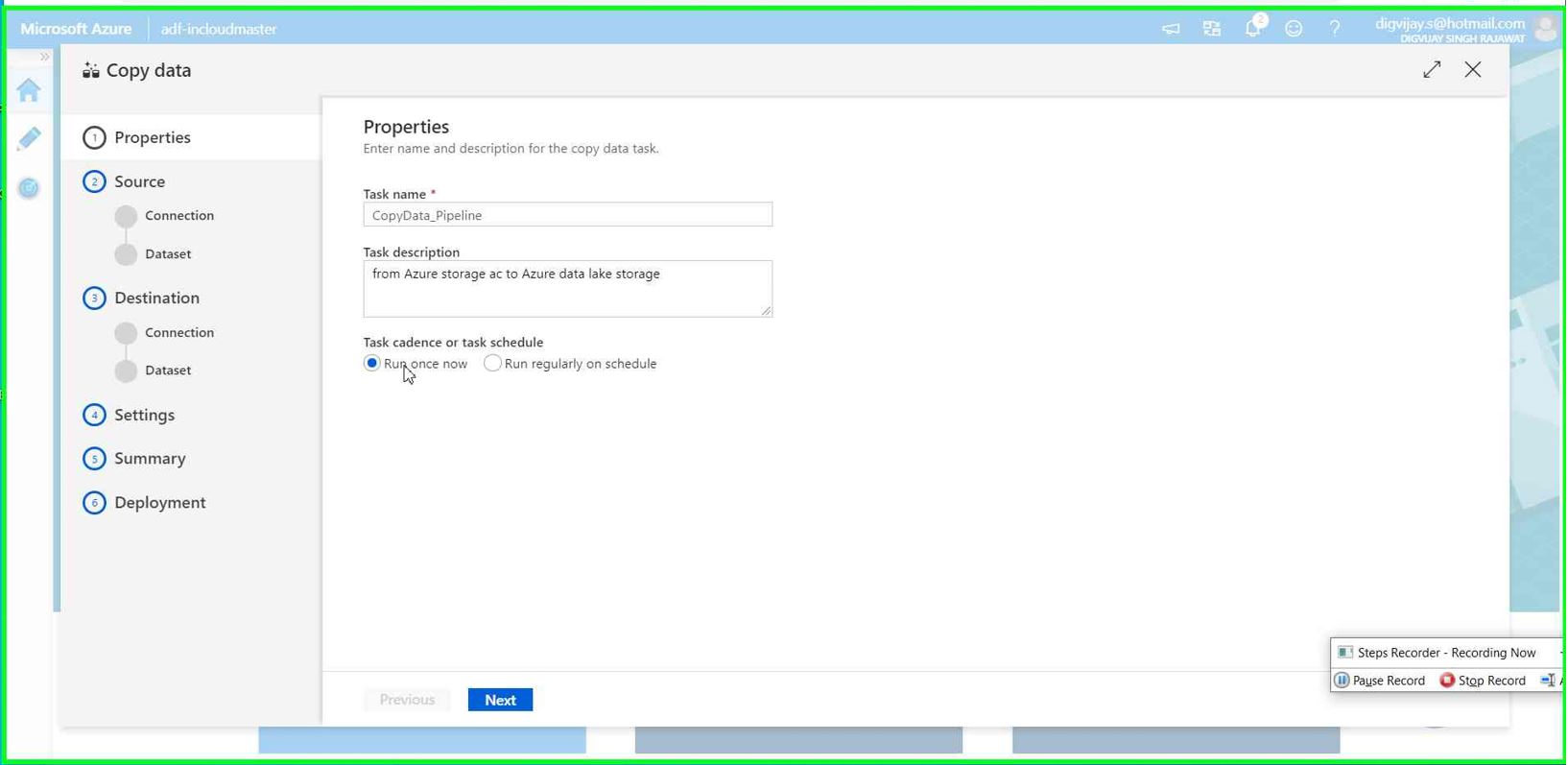
Connections for Source and Destination
Both will have two sub configurations as below.
Connection- Select linked service we have created previously. For both source and destination
Dataset- This is where you target specific data to be processed, this could be table with in the data base or file such as csv or json.
Prepare Source for pipeline
Select the connection for source. This is Azure blob storage in our case.
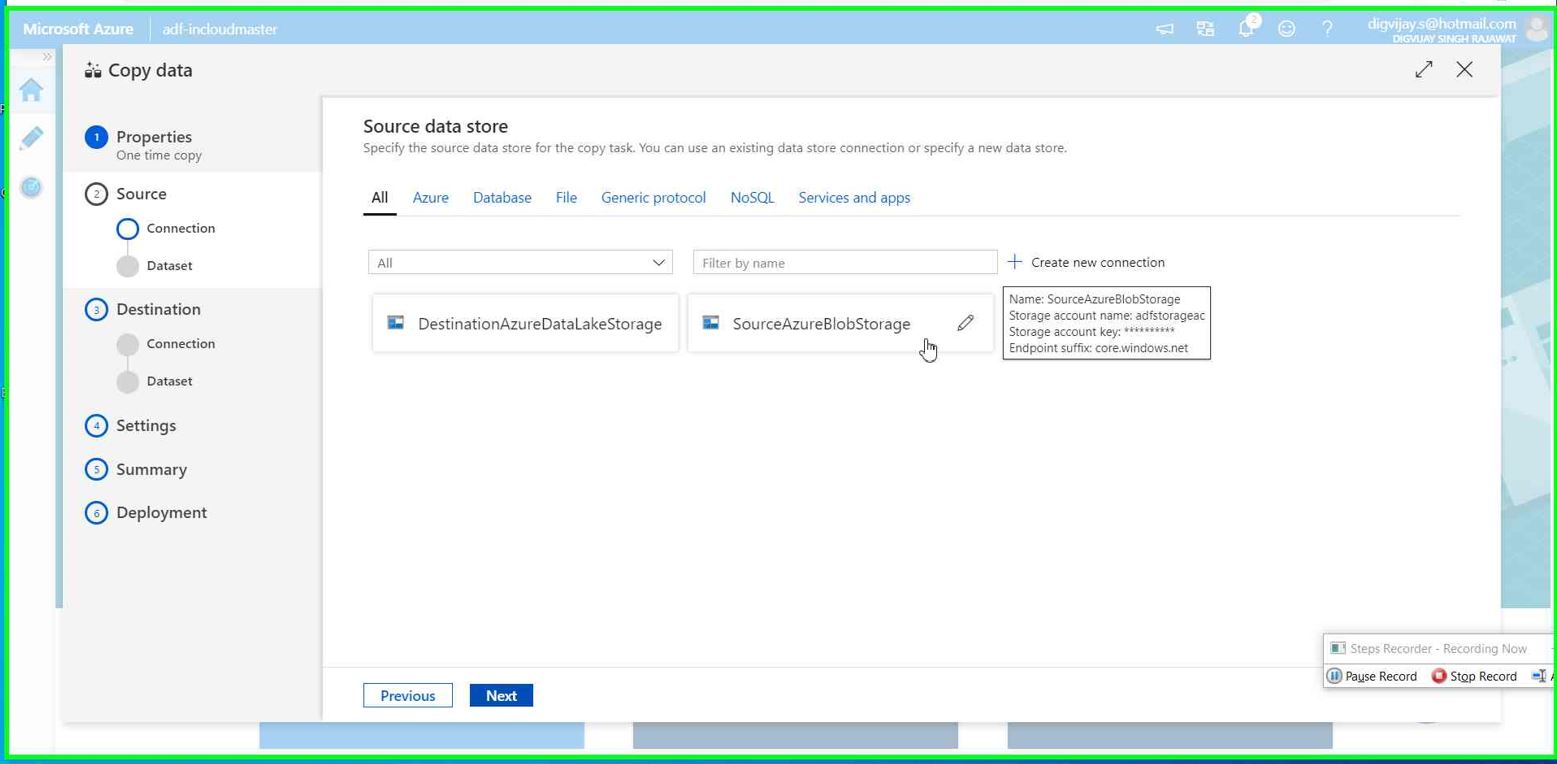
We have dummay-data.csv file uploaded into the Azure blob storage under source container. This csv file will be used as row data which we need to be processed using Azure data factory pipeline.
Click Next
**
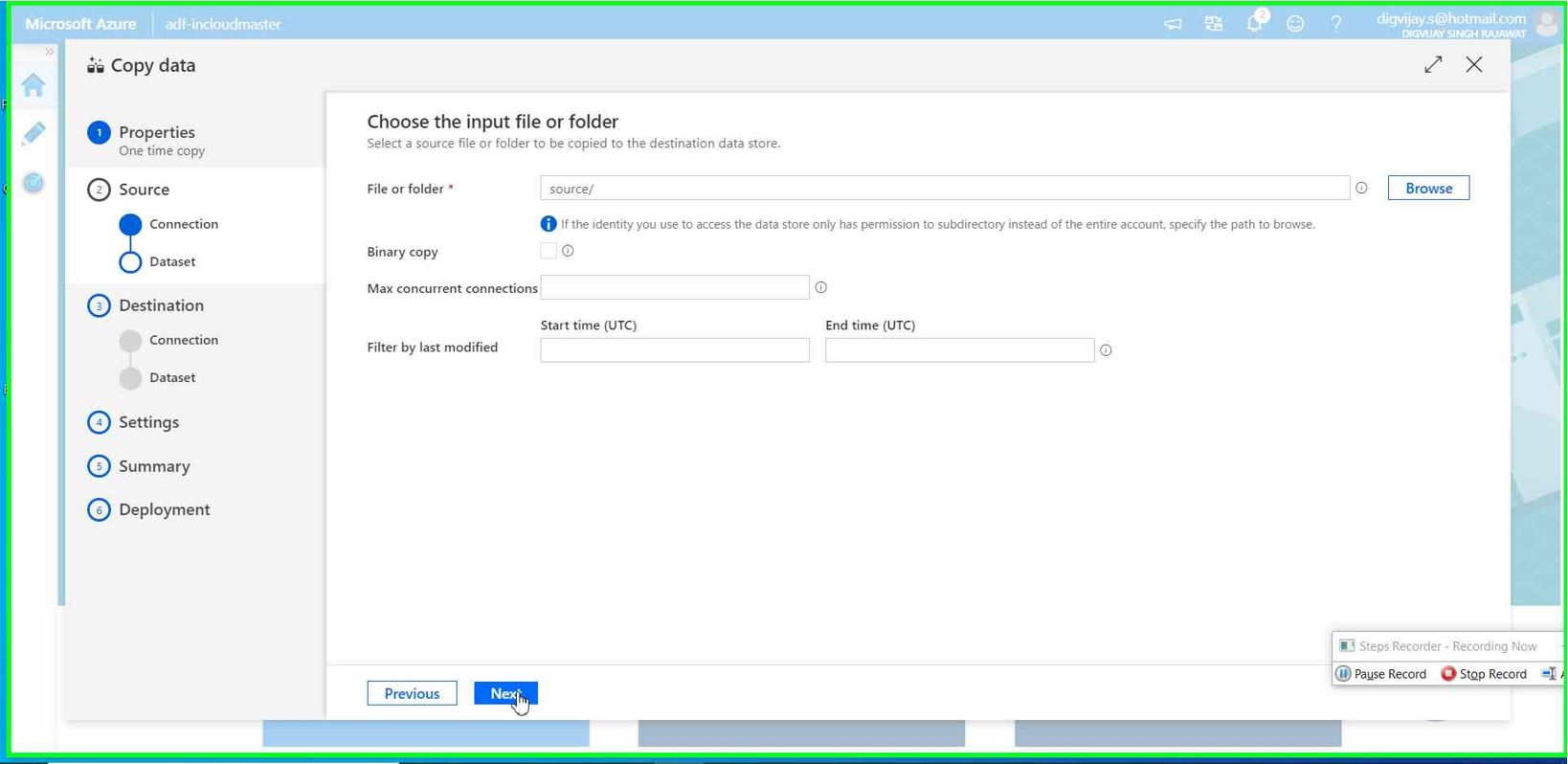
**
Use the setting as per your need. Remember that at source we have pipe(|) separated value so select accordingly
Click Next
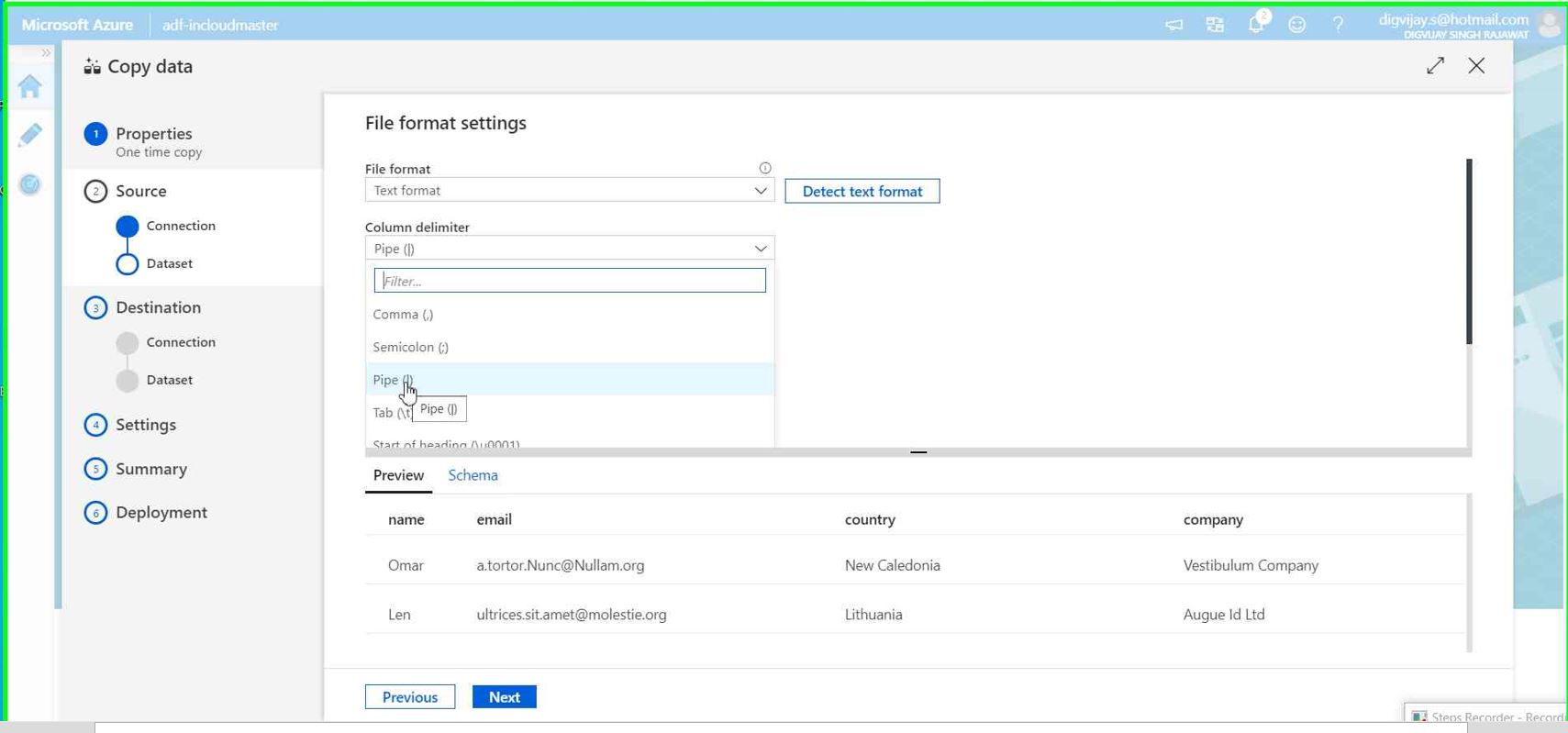
Prepare destination for pipeline
Select the connection for destination. This is Azure data lake Gen2 for our case.
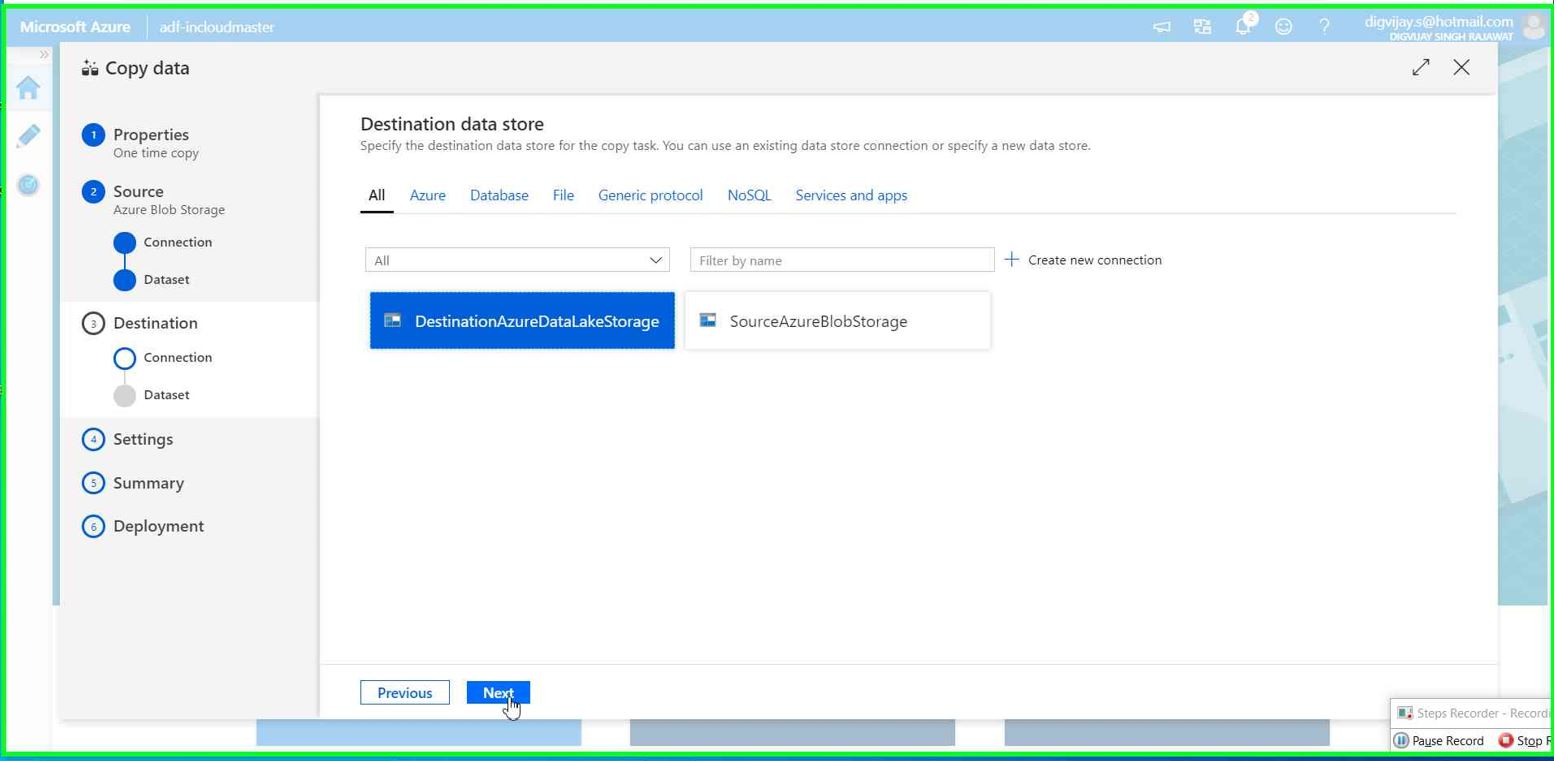
Browse Azure data lake storage service we have created in previous steps.
Select the container (we have created container called destination)
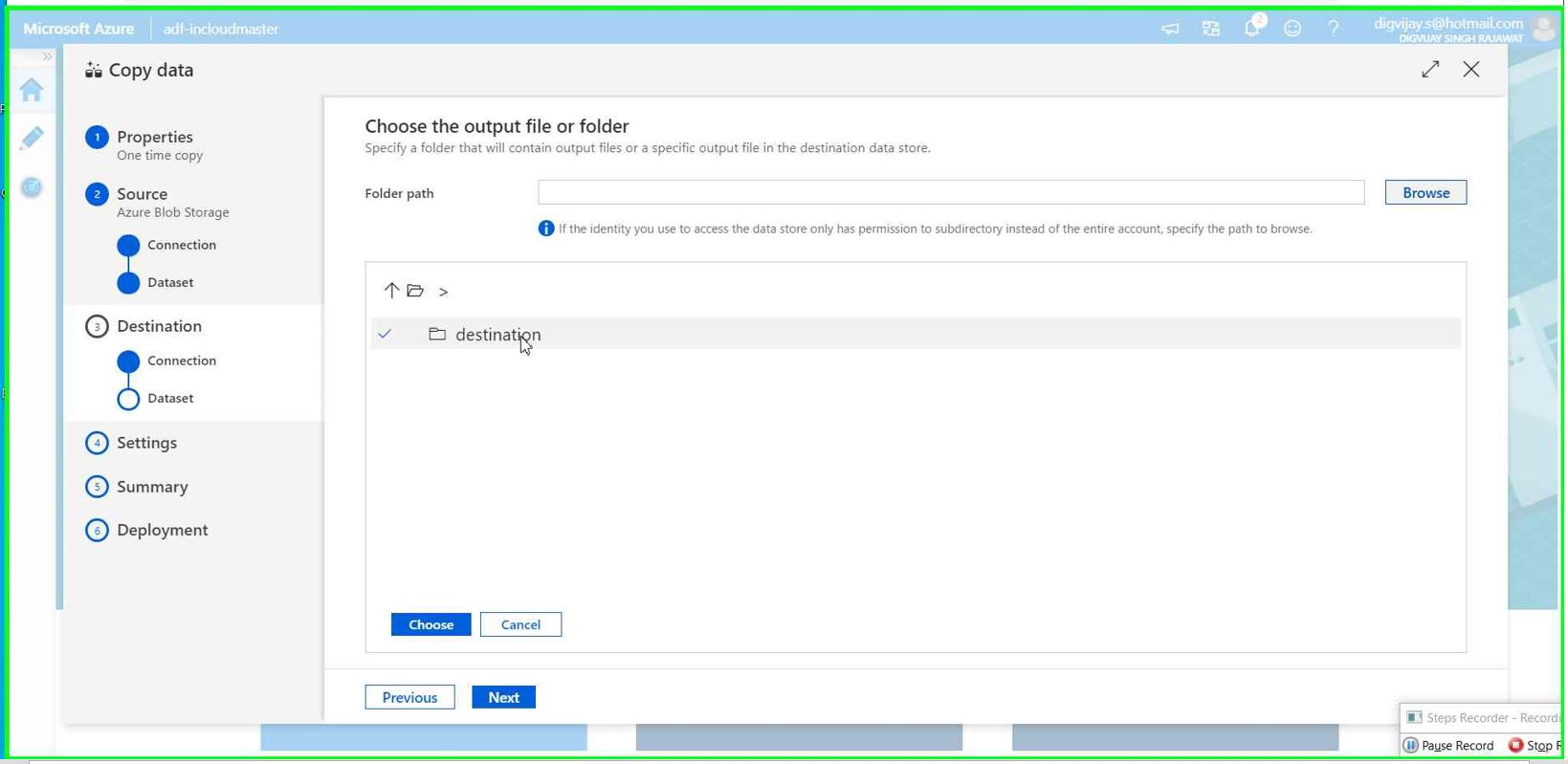
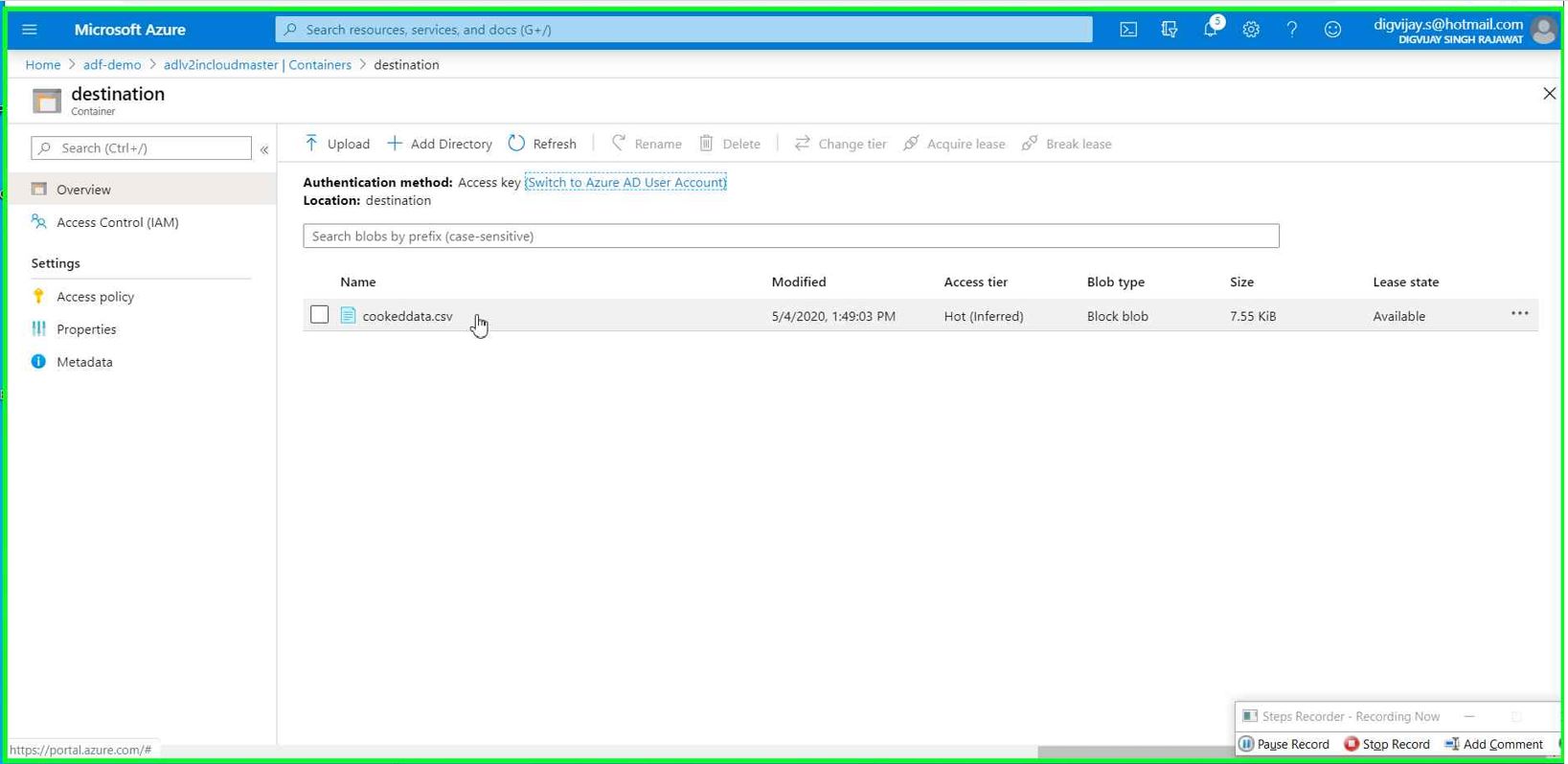
Give the file name you want for processed data. In our case, we mentioned cookeddata.csv
Make rest of the settings as below and click Next
**
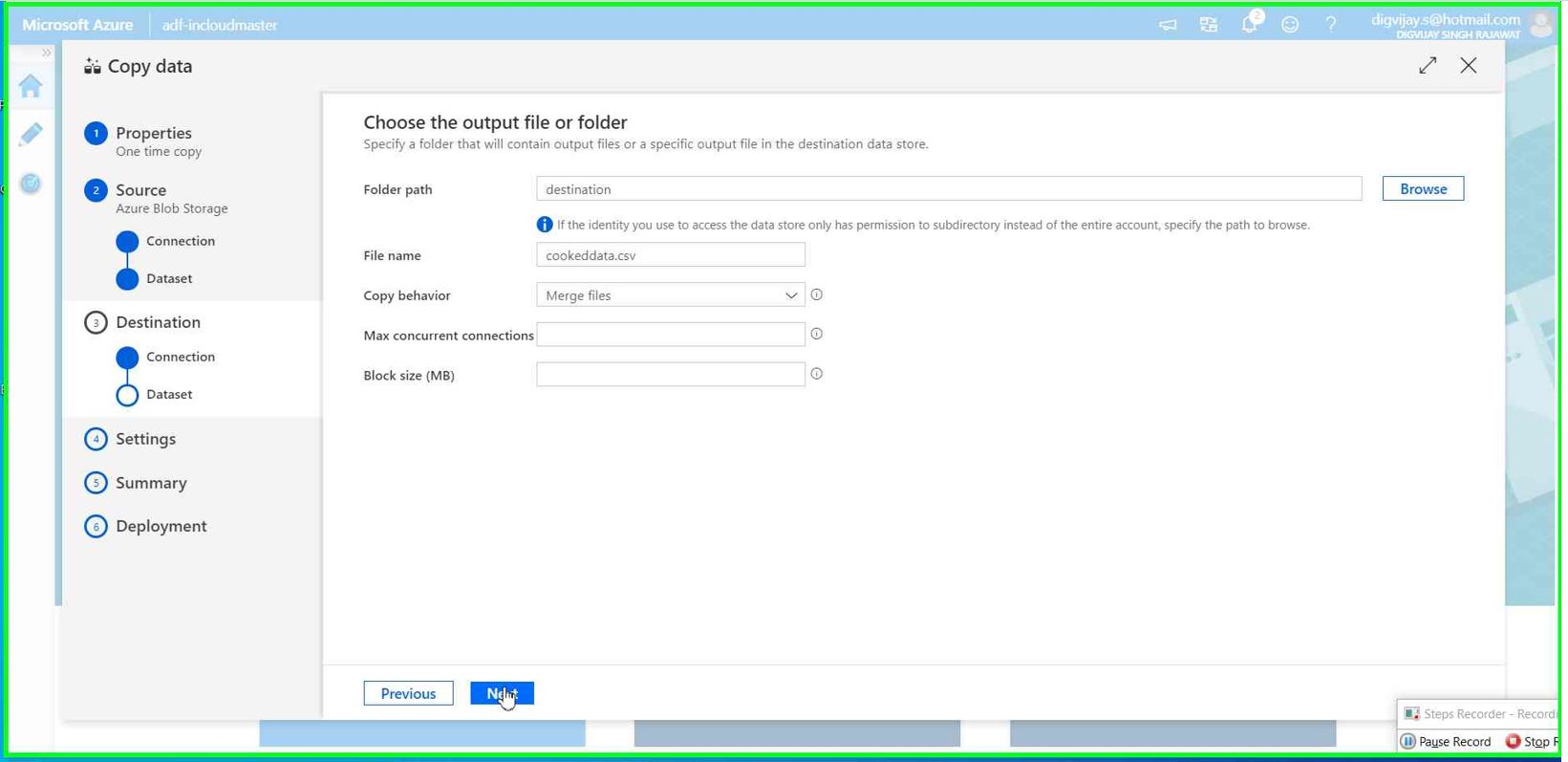
**
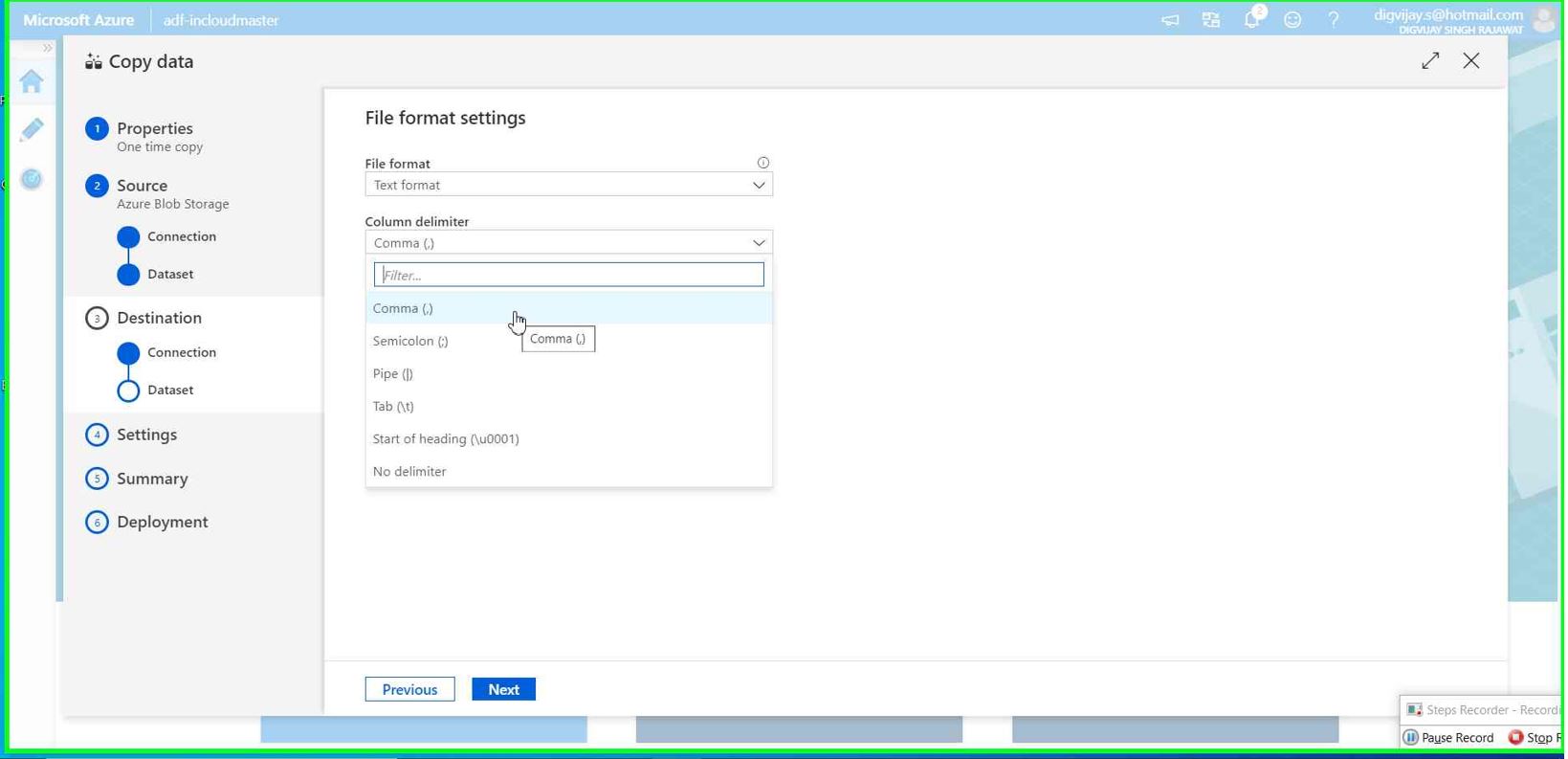
In this step, we need to select Comma(,) as column delimiter (this is for transforming the data as per the usecase)
Click Next
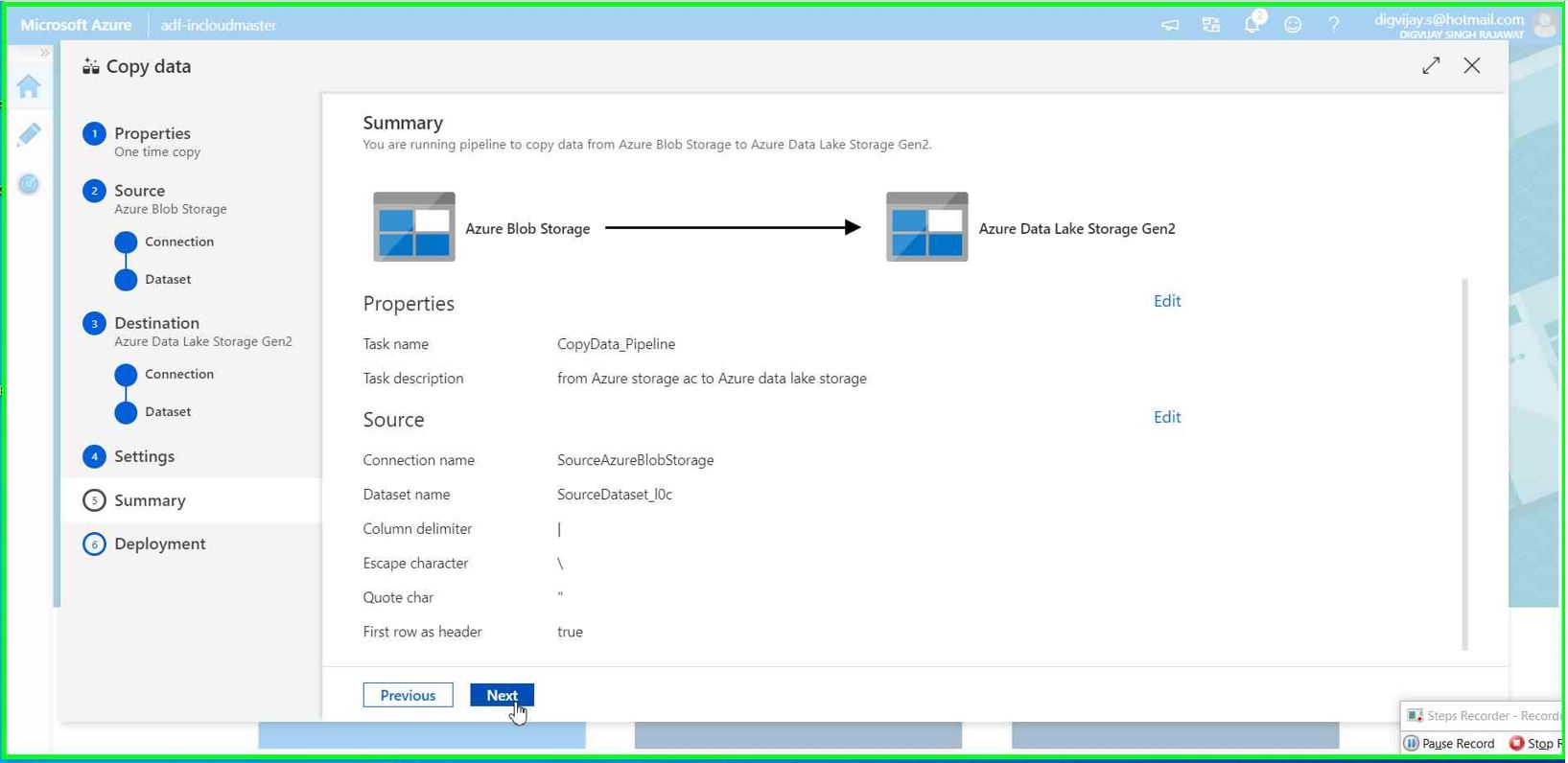
Validate the summary and click Next to finish and kick-off the pipeline.
It's should not take much time (depending on the data set size you have)
You will see message Deployment complete.
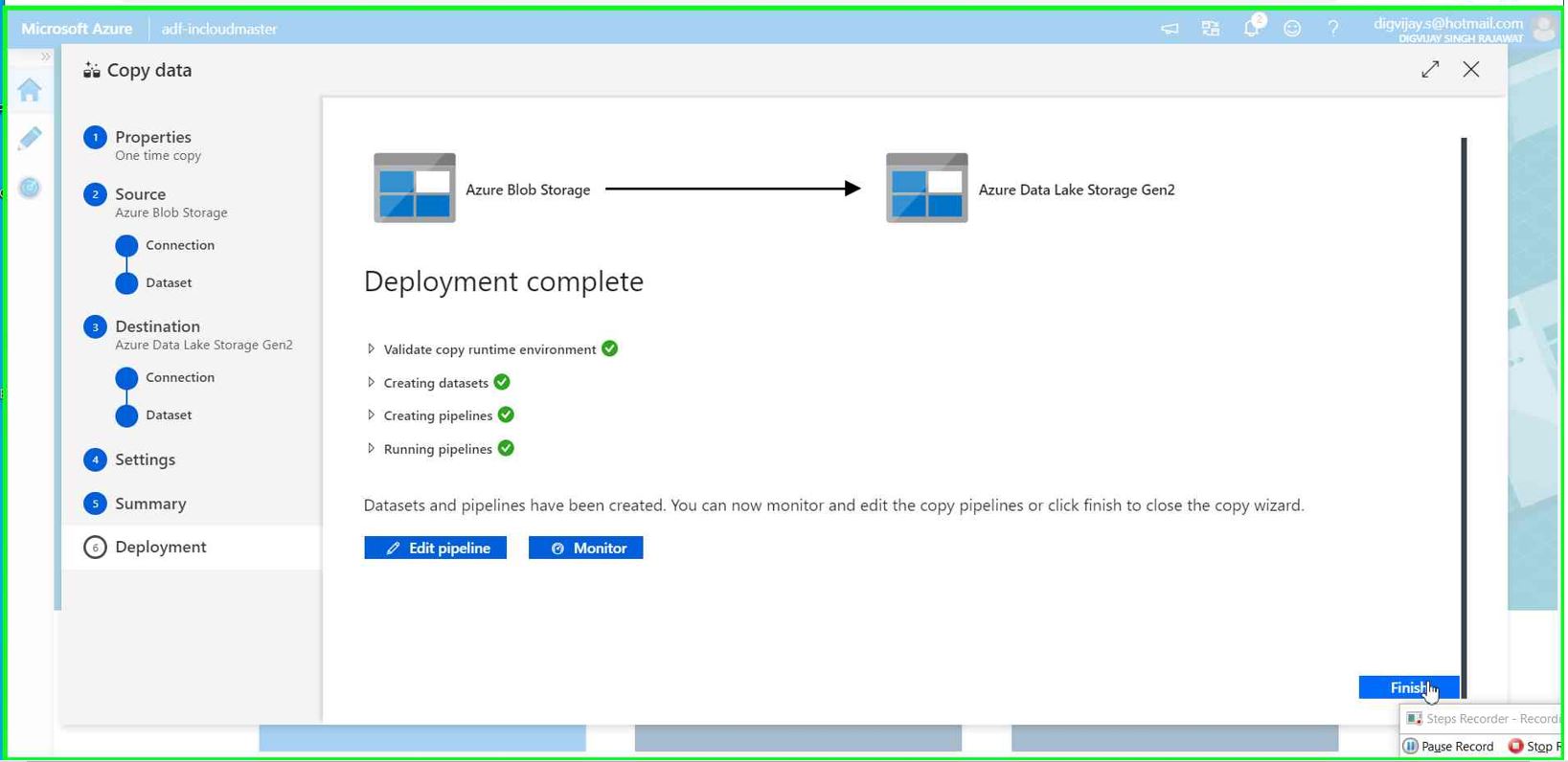
You can also monitor data pipeline to see the detailed over view of each activity and perform troubleshooting in case of any error.
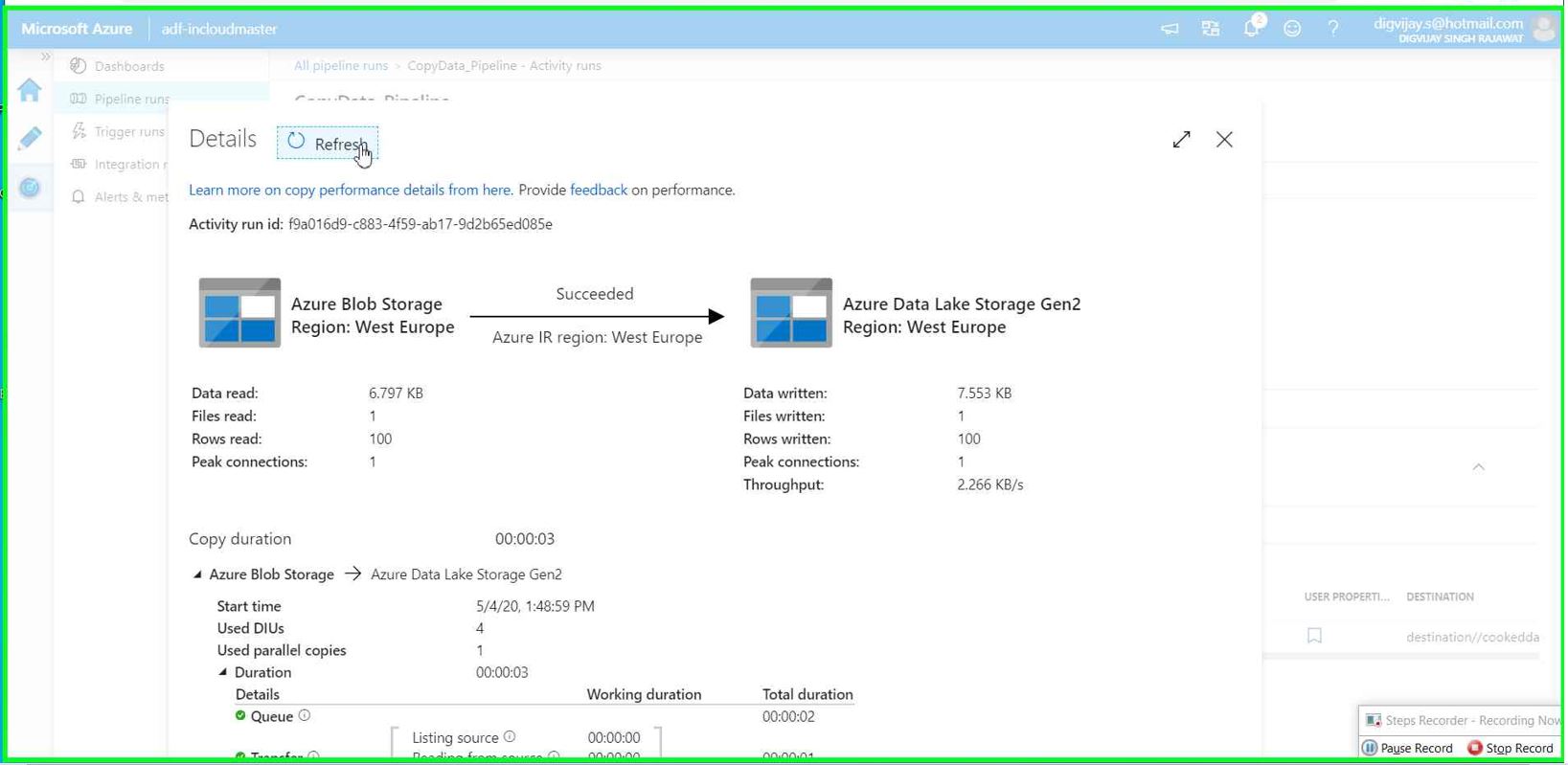
Verify the data
Go to the Azure data lake storage Gen2 service --> container --> search for file (in our case it’s cookeddata.csv)
Summary
You have successfully create Azure data factory service and build very basic pipeline for your data. I hope this article will be informative to you help you to learn Azure data factory service in general. If you have any question/feedback please put that into the comment box.