Designing High Availability and Disaster Recovery Using SQL Server Standard Edition
In today’s world, data availability has become a critical and mandatory task for any business. Database which is a main pillar for any application should adhere to this and ensure high availability and disaster recovery for each and every database based on the defined Recovery Point Objective (RPO) and Recovery Time Objective (RTO).
Recovery Point Objective (RPO) refers to the maximum amount of data any business can afford to lose. Any solution for an application or database should be designed keeping this in mind to achieve greater success.
Recovery Time Objective (RTO) refers to how much downtime an organization can afford before making an application or database business as usual.
SQL Server Disaster Recovery is an event where SQL Server availability is ensured. SQL Server disaster is an event that may result in serious data loss or service disruption due to unavailability of underlying resources. There can be various reasons for a disaster such as - natural disaster, power failure, hardware failure, planned power outage etc. Certain SQL Server disasters can be avoided, but others should be dealt as reactive and this is where proper SQL Server disaster recovery planning helps.
Proper SQL Server disaster recovery planning will prove helpful during issues by avoiding data loss and ensures SQL Server uptime by making it available as soon as possible after a disaster. A disaster recovery plan should be properly documented and tested periodically to checks its effectiveness. It should be modified depending on the requirement and testing results.
There are several solutions that can be designed in SQL Server for achieving High availability and disaster recovery by utilizing SQL Server availability groups, SQL Server installed on a cluster with shared storage, Database Mirroing, Log shipping etc. All these designs will feature SQL Server Enterprise edition most of the time. We know that SQL Server Enterprise Edition is comparably costlier than SQL Server Standard Edition and utilizing SQL Server Standard Edition for a design where we will be able to deliver High Availability and Disaster recovery can be a double treat where we will be able to reduce the overall cost and also get the required planning to deal with a disaster.
This article will discuss utilizing SQL Server Standard edition for High Availability and Disaster recovery.
Option 1 : SQL Server Disaster recovery utilizing Basic availability group and Transaction Log shipping

This option utilizes standalone database server JBSERVER1 and JBSERVER2 participating in a basic availability group using synchronous commit with automatic failover for high availability in primary datacentre. Basic availability group will be configured for each database available on the SQL Server Instance. Log shipping is configured between Primary Replica in Primary datacentre to JBSERVER3 in secondary datacentre for disaster recovery. Transaction log backup frequency should be appropriately decided based upon the requirement. DNS alias should be configured and used in application connection string and should be modified to JBSERVER3 in case of a disaster recovery, there will be no changes required for failover in primary datacentre as Listener will be utilized.
It should be noted that in basic availability group each availability group can contain only one database. In an event of some databases failing over to secondary replica and other databases residing on primary replica can result in issues. You can work around this by failing over all availability group in an event of single availability group failover.
-> Powershell script can be employed to perform this. This solution will work only for Basic Availability groups.
-> Create a Linked Server on each of the 2 SQL Server instance to access the master database of other Database Instance. For security reasons we can use “Be made using the login’s current security context’.
-> Make sure all the Availability groups are on the same instance. Execute the below query on both Primary and secondary instance on Master Database only once.
IF EXISTS(SELECT *
FROM dbo.AG_role)
DROP TABLE dbo.AG_role
create table AG_role (AGName varchar(30)
,PrimaryReplica varchar(30)
,DBName varchar(30)
,Role int)
set nocount on
Declare @AGName varchar(30)
Declare @PrimaryReplica varchar(30)
Declare @DBName varchar(30)
DECLARE AG_Cursor CURSOR STATIC FOR
SELECT
AG.name AS [AvailabilityGroupName],
ISNULL(agstates.primary_replica, '') AS [PrimaryReplicaServerName],
dbcs.database_name AS [DatabaseName]
FROM master.sys.availability_groups AS AG
LEFT OUTER JOIN master.sys.dm_hadr_availability_group_states as agstates
ON AG.group_id = agstates.group_id
INNER JOIN master.sys.availability_replicas AS AR
ON AG.group_id = AR.group_id
INNER JOIN master.sys.dm_hadr_availability_replica_states AS arstates
ON AR.replica_id = arstates.replica_id AND arstates.is_local = 1
INNER JOIN master.sys.dm_hadr_database_replica_cluster_states AS dbcs
ON arstates.replica_id = dbcs.replica_id
LEFT OUTER JOIN master.sys.dm_hadr_database_replica_states AS dbrs
ON dbcs.replica_id = dbrs.replica_id AND dbcs.group_database_id = dbrs.group_database_id
ORDER BY AG.name ASC, dbcs.database_name
OPEN AG_Cursor
FETCH NEXT FROM AG_Cursor into @AGName, @PrimaryReplica, @DBName
WHILE @@FETCH_STATUS = 0
BEGIN
insert into AG_role values(@AGName, @PrimaryReplica, @DBName,sys.fn_hadr_is_primary_replica(@DBName))
FETCH NEXT FROM AG_Cursor into @AGName, @PrimaryReplica, @DBName
END
CLOSE AG_Cursor
DEALLOCATE AG_Cursor
->Save the below file as a powershell script on both Primary and secondary Database server. Create a Windows task on both servers to execute the script every 1 min on both servers. Please make sure $PrimaryReplica is same as the server where the powershell script is saved. The $SecondaryReplica will be the other server that is part of the Alwayson Availability group.
$PrimaryReplica = "JBSERVER1";
$SecondaryReplica = "JBSERVER2";
Invoke-Sqlcmd "create table AGFailover(AGSQL nvarchar(max),flag int default 0);" -ServerInstance $PrimaryReplica;
Invoke-Sqlcmd "
Declare @Ag_Current int
Declare @Ag_Previous int
Declare @AGName varchar(30)
Declare @PrimaryReplica varchar(30)
Declare @DBName varchar(30)
Declare @Role int
Declare @Flag int
DECLARE AG_Cursor CURSOR STATIC FOR
SELECT * from AG_Role
OPEN AG_Cursor
FETCH NEXT FROM AG_Cursor into @AGName, @PrimaryReplica, @DBName, @Role
WHILE @@FETCH_STATUS = 0
BEGIN
set @Ag_Current = (select sys.fn_hadr_is_primary_replica(@DBName))
set @Ag_Previous = (select Role from Ag_Role where DBName=@DBName)
if(@Ag_Current = @Ag_Previous)
BEGIN
print 'No Failover occured'
insert into AGFailover (AGSQL)
select 'ALTER AVAILABILITY GROUP ['+@AGName+'] FAILOVER;'
END
ELSE
BEGIN
--print 'Failover occured'
if (@Ag_Previous =1)
BEGIN
set @flag=1
END
END
FETCH NEXT FROM AG_Cursor into @AGName, @PrimaryReplica, @DBName, @Role
END
CLOSE AG_Cursor
DEALLOCATE AG_Cursor;
if (@flag=1)
begin
update AGFailover set flag=1
end" -ServerInstance $PrimaryReplica;
Invoke-Sqlcmd "
DECLARE @AGSql NVARCHAR(MAX) = N'';
SELECT
@AGSql = @AGSql + AGSQL FROM $PrimaryReplica.master.dbo.AGFailover where flag=1;
EXEC sp_executesql @AGSql;" -ServerInstance $SecondaryReplica;
Invoke-Sqlcmd "drop table AGFailover;" -ServerInstance $PrimaryReplica;
Invoke-Sqlcmd "delete from AG_role;" -ServerInstance $PrimaryReplica;
Invoke-Sqlcmd "
set nocount on
Declare @AGName varchar(30)
Declare @PrimaryReplica varchar(30)
Declare @DBName varchar(30)
DECLARE AG_Cursor CURSOR STATIC FOR
SELECT
AG.name AS [AvailabilityGroupName],
ISNULL(agstates.primary_replica, '') AS [PrimaryReplicaServerName],
dbcs.database_name AS [DatabaseName]
FROM master.sys.availability_groups AS AG
LEFT OUTER JOIN master.sys.dm_hadr_availability_group_states as agstates
ON AG.group_id = agstates.group_id
INNER JOIN master.sys.availability_replicas AS AR
ON AG.group_id = AR.group_id
INNER JOIN master.sys.dm_hadr_availability_replica_states AS arstates
ON AR.replica_id = arstates.replica_id AND arstates.is_local = 1
INNER JOIN master.sys.dm_hadr_database_replica_cluster_states AS dbcs
ON arstates.replica_id = dbcs.replica_id
LEFT OUTER JOIN master.sys.dm_hadr_database_replica_states AS dbrs
ON dbcs.replica_id = dbrs.replica_id AND dbcs.group_database_id = dbrs.group_database_id
ORDER BY AG.name ASC, dbcs.database_name
OPEN AG_Cursor
FETCH NEXT FROM AG_Cursor into @AGName, @PrimaryReplica, @DBName
WHILE @@FETCH_STATUS = 0
BEGIN
insert into AG_role values(@AGName, @PrimaryReplica, @DBName,sys.fn_hadr_is_primary_replica(@DBName))
FETCH NEXT FROM AG_Cursor into @AGName, @PrimaryReplica, @DBName
END
CLOSE AG_Cursor
DEALLOCATE AG_Cursor;" -ServerInstance $PrimaryReplica;
-> Whenever a failover of any of the availability group happens, the script executing from the task scheduler will check for the failover and fails over all other Availability groups.
Option2 - SQL Server Disaster recovery utilizing SQL Server Cluster Instance with Shared Storage and Basic availability group
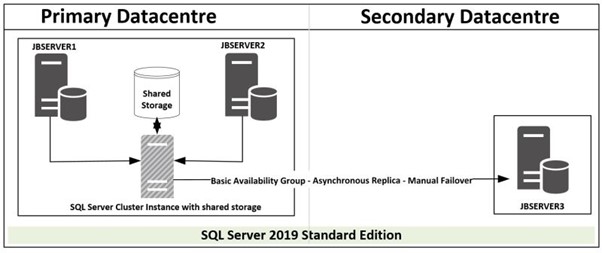
This option utilizes SQL Server installed on a failover cluster with shared storage. JBSERVER1 and JBSERVER2 will be the physical nodes with a virtual SQL Server installed and configured for high availability. Basic availability group using Asynchronous commit with manual failover will be configured between the virtual SQL Server in Primary datacentre to JBSERVER3 in secondary datacentre. DNS alias should be configured and used in application connection string and should be modified to JBSERVER3 in case of a disaster recovery, there will be no changes required for failover in primary datacentre as virtual SQL Server name will be utilized.
Option3 - SQL Server Disaster recovery utilizing SQL Server Cluster Instance with Shared Storage and Transaction Logshipping
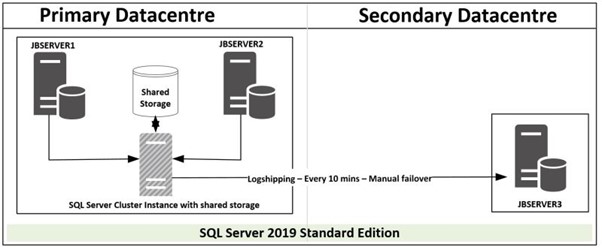
This Option utilizes SQL Server installed on a failover cluster with shared storage. JBSERVER1 and JBSERVER2 will be the physical nodes with a virtual SQL Server installed and configured for high availability. Log shipping is configured between the virtual SQL Server in Primary datacentre to JBSERVER3 in secondary datacentre for disaster recovery. DNS alias should be configured and used in application connection string and should be modified to JBSERVER3 in case of a disaster recovery, there will be no changes required for failover in primary datacentre as virtual SQL Server name will be utilized.
It is prudent to test high availability and disaster recovery to make sure how long does it take and if it is acceptable to your business. It is mandatory that the design can achieve the required RTO and RPO.