Data Mining with SQL Server Analysis Services 2008
Introduction
Data mining is a process of discovering pattern from a very large chunk of data. Pattern can be used for decision making by higher authorities, like Prediction of Sales, Probability of number of site visit in next month etc. Or in another word it is predictive analysis tool.
Data mining is in-built feature of SQL Server Analysis Service.
The Solution
These are few Steps which are used to create Data Mining Structure.
At first Create Data Source and Data Source View in SSAS Project, then In Solution Explorer, Right Click on Mining Structure and Select Create New Structure. This will open Data Mining Wizard.
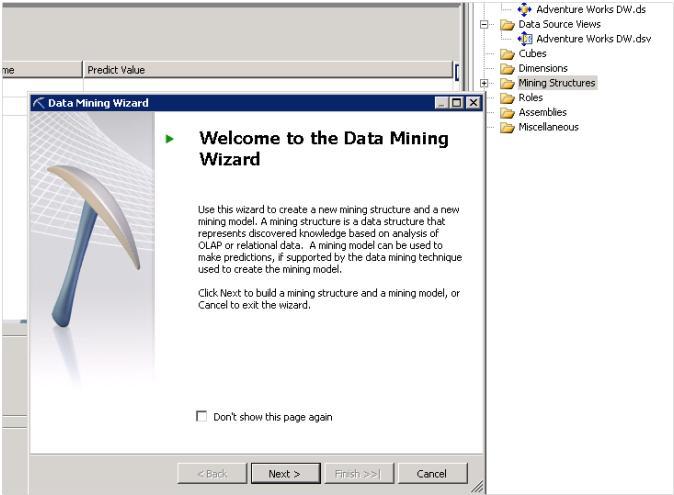
Step 1: Create Mining Structure
(Which Algorithm you want to use for Data Mining and Decision Making)
The selected algorithm is used to create Data Mining Structure. The different algorithm is used for different purpose. Below is the classification which shows which algorithm should use (From Chanel 9 Video).
- Classification
- NaiveBayes
- Decision Trees
- Neural Network
- Logistic Regression
- Estimate
- Decision Trees
- Linear Regression
- Neural Network
- Logistic Regression
- Cluster
- Clustering
- Forecasting
- Time Series
- Associate
- Association Rule
- Decision Tree
We can create Date Mining Model by using any of the above algoritm. We can also create DMM by using two or more algoritm and estimate the accuracy of different algorithms.
Some useful Link about different Algorithm:
- Microsoft Association Algorithm: http://msdn.microsoft.com/en-us/library/ms174916(v=sql.90).aspx
- Microsoft Clustering Algorithm: http://msdn.microsoft.com/en-us/library/ms174879(v=sql.90).aspx
- Microsoft Decision Tree Algorithm: http://msdn.microsoft.com/en-us/library/ms175312(v=sql.90).aspx
- Microsoft Linear Regression Algorithm: http://msdn.microsoft.com/en-us/library/ms174824(v=sql.90).aspx
- Microsoft Logistic Regression Algorithm: http://msdn.microsoft.com/en-us/library/ms174828(v=sql.90).aspx
- Microsoft Naïve Bayes Algorithm: http://msdn.microsoft.com/en-us/library/ms174806(v=sql.90).aspx
- Microsoft Neural Network Algorithm (SSAS): http://msdn.microsoft.com/en-us/library/ms174941(v=sql.90).aspx
- Microsoft Sequence Clustering Algorithm: http://msdn.microsoft.com/en-us/library/ms175462(v=sql.90).aspx
- Microsoft Time Series Algorithm: http://msdn.microsoft.com/en-us/library/ms174923(v=sql.90).aspx
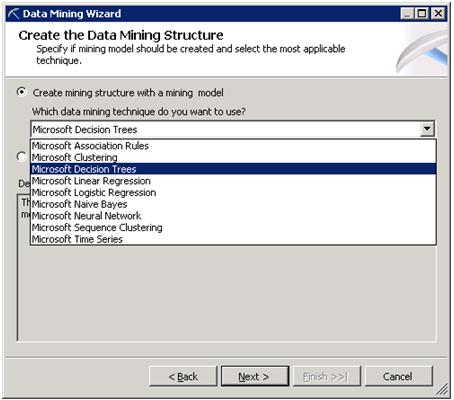
Step 2: Connect to Data Source
Data Source can be Relational Database/Data Ware or Cube.
Actually there are two concepts first is OLTP and another is OLAP. OLTP, Online Trasaction Processing involves relatively less record manupulation then OLAP (Online Analytical Processing). OLAP uses historical data, which is in high volumn. So, the structure of OLTP database are completely different from OLAP. OLTP uses relational database, while OLAP uses Cube based architecture (We can use Relational also in OLAP). Thats why MDX query in DWH.
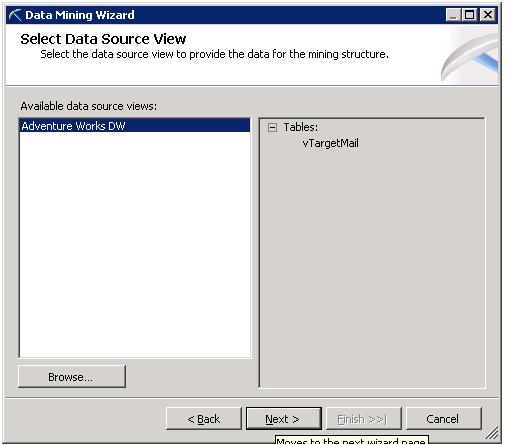
Step 3: Supply Input Table
As we can see in Step 2, we connect to Data Source; similarly we need to connect to the Table/View inside the Data Source.
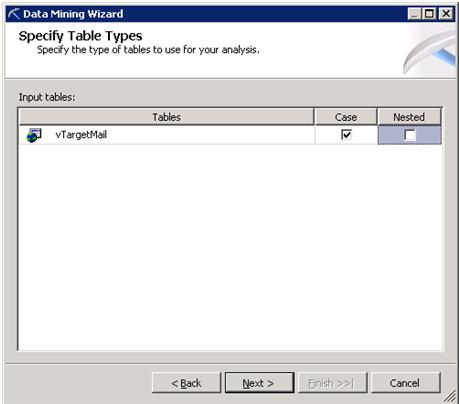
There are two types of Table:
- Case Table
- Nested Table
In data mining algorithm, data must be fed as a series of cases. The Cases are records in Case Table. But the important point is “Not All Cases are Single row of data”.
For Example (taken from MSDN): One table that contains customer information, and another table that contains customer purchases means 1:M relationship. A single customer in the customer information table might have multiple items in the customer purchases table, which makes it difficult to describe the data by using a single row.
Analysis Services provides a unique method for handling these cases, by using nested tables. The concept of a nested table is demonstrated in the following illustration.

So here Customers is a Case Table and Products is a Nested Table and the Resultant Case Table is the Joining of these two tables with 1: M relationship. This one record which is showing in above pic is Case (Input of Data Mining Algorithm).
**
Step 4: Specify Attributes of Selected Table**
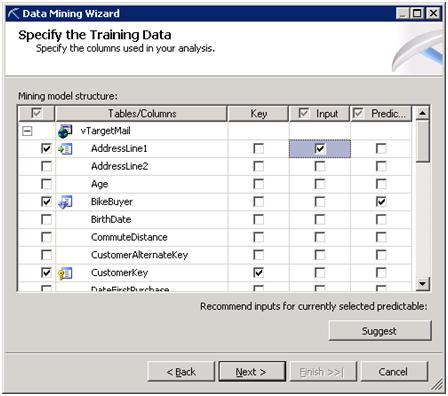
There are two types of Data.
- Training Data
- Testing Data
Training data are normal records while Testing Data are used to Testing the Mining Model. For Example: If we set 70:30 ratios, 70% records or data are used to create prediction while means 30% random data are used to test the accuracy of Model.
There are three different types of Attributes:
Key: Identify uniqueness of record.
Input: Which Inputs are required for prediction, like Age Group, No. of Bike sales this year. Etc. If we click on Suggest, then It will show weightage of different attribute, like here Age is most influential column with 0.492 weightage, second is Yearly Income, we can select the column based on suggestion.
Prediction: Which Attribute you want to predict, like how much Bike will sale in this year.

Step 5: Specify Data Types of Attributes
In this window we specify Content type and Data Type of Model structure.
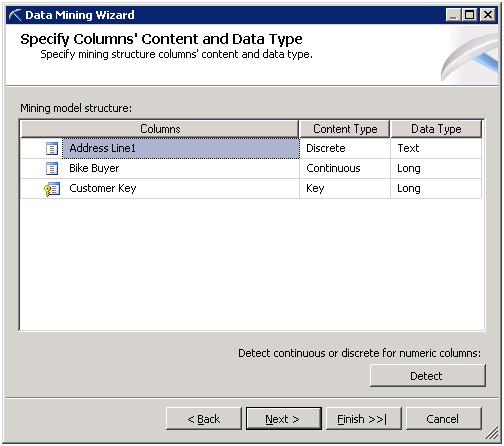
Link: http://technet.microsoft.com/en-us/library/ms174572.aspx
Step 6: Set Accuracy of Decision.
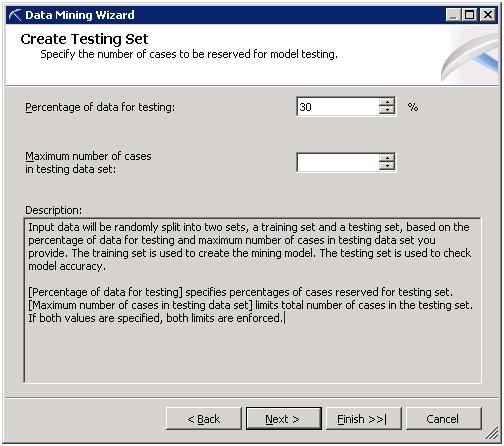
In the next article I will show you how to interprets or understand the Result of Data Mining Wizard.
There are some very nice Video presentation on SSAS available at:
http://www.learnmicrosoftbi.com/Videos/tabid/75/Default.aspx
Thanks
Jayant