Anomaly Detector 일변량 API를 사용하는 경우의 모범 사례
Important
2023년 9월 20일부터 새로운 Anomaly Detector 리소스를 만들 수 없습니다. Anomaly Detector 서비스는 2026년 10월 1일에 사용 중지됩니다.
Anomaly Detector API는 상태 비저장 변칙 검색 서비스입니다. 결과의 정확성 및 성능은 다음과 같은 사항에 영향을 받을 수 있습니다.
- 시계열 데이터를 준비하는 방법
- 사용된 Anomaly Detector API 매개 변수
- API 요청의 데이터 포인트 수
이 문서에서는 API를 사용하여 데이터에 대한 최상의 결과를 얻는 모범 사례에 대해 알아봅니다.
일괄(전체) 또는 최신(마지막) 포인트 변칙 검색을 사용해야 할 때
Anomaly Detector API의 일괄 검색 엔드포인트를 사용하면 전체 시계열 데이터에 대해 변칙을 검색할 수 있습니다. 이 검색 모드에서는 데이터 세트의 각 포인트에 대해 단일 통계 모델이 만들어지고 적용됩니다. 시계열에 다음과 같은 특성이 있는 경우 일괄 검색을 사용하여 한 번의 API 호출로 데이터를 미리 보는 것이 좋습니다.
- 간헐적 변칙이 있는 계절성 시계열
- 간헐적 급증/급락이 있는 평면 추세 시계열
실시간 데이터 모니터링이나 위의 특성이 없는 시계열 데이터에는 일괄 변칙 검색을 사용하지 않는 것이 좋습니다.
일괄 검색은 하나의 모델만 만들고 적용하며 각 포인트에 대한 검색은 전체 계열의 컨텍스트에서 수행됩니다. 시계열 데이터의 추세가 계절성 없이 오르락내리락하는 경우 모델에서 일부 변화 포인트(데이터 급락 및 급증)가 누락될 수 있습니다. 마찬가지로 데이터 세트에서 나중에 나오는 것보다 덜 중요한 일부 변화 포인트는 모델에 통합될 만큼 충분히 중요한 것으로 간주되지 않을 수 있습니다.
일괄 검색은 분석하는 포인트 수 때문에 실시간 데이터 모니터링을 수행할 때 최신 포인트의 변칙 상태를 검색하는 것보다 느립니다.
실시간 데이터 모니터링의 경우 최신 데이터 포인트만 변칙 상태를 검색하는 것이 좋습니다. 최신 포인트 검색을 지속적으로 적용하여 스트리밍 데이터 모니터링을 보다 효율적이고 정확하게 수행할 수 있습니다.
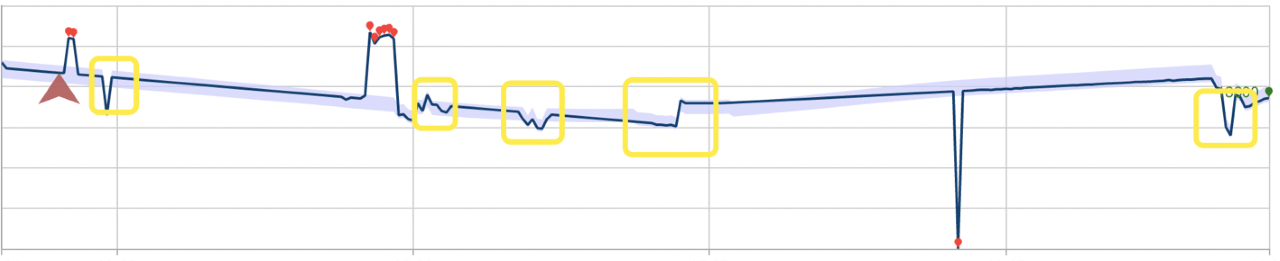
아래 예에서는 이러한 검색 모드가 성능에 미칠 수 있는 영향을 설명합니다. 첫 번째 그림은 이전에 표시된 28개의 데이터 포인트를 따라 최신 포인트의 변칙 상태를 지속적으로 검색한 결과를 보여 줍니다. 빨간색 점은 변칙입니다.

아래는 일괄 변칙 검색을 사용하는 동일한 데이터 세트입니다. 작업을 위해 빌드된 모델이 사각형으로 표시된 여러 개의 변칙을 무시했습니다.
데이터 준비
Anomaly Detector API는 JSON 요청 개체로 형식이 지정된 시계열 데이터를 허용합니다. 시계열은 시간에 따라 순차적으로 기록된 모든 숫자 데이터일 수 있습니다. 시계열 데이터의 창을 Anomaly Detector API 엔드포인트로 보내 API의 성능을 향상시킬 수 있습니다. 전송할 수 있는 데이터 포인트의 최소 개수는 12이고 최대는 8640포인트입니다. 세분성은 데이터가 샘플링되는 속도로 정의됩니다.
Anomaly Detector API로 전송되는 데이터 포인트에는 유효한 UTC(협정 세계시) 타임스탬프와 숫자 값이 있어야 합니다.
{
"granularity": "daily",
"series": [
{
"timestamp": "2018-03-01T00:00:00Z",
"value": 32858923
},
{
"timestamp": "2018-03-02T00:00:00Z",
"value": 29615278
},
]
}
데이터가 비표준 시간 간격으로 샘플링되는 경우 요청에 customInterval 특성을 추가하여 지정할 수 있습니다. 예를 들어 계열이 5분마다 샘플링되는 경우 JSON 요청에 다음을 추가할 수 있습니다.
{
"granularity" : "minutely",
"customInterval" : 5
}
누락된 데이터 포인트
누락된 데이터 포인트는 균일하게 분포된 시계열 데이터 집합, 특히 세분화된 데이터 집합에서 일반적입니다(작은 샘플링 간격. 예를 들어, 데이터는 몇 분마다 샘플링됨). 데이터에서 예상되는 포인트 수의 10% 미만이 누락되어도 검색 결과에 부정적인 영향을 주지 않아야 합니다. 이전 기간의 데이터 포인트 대체, 선형 보간 또는 이동 평균과 같은 특성을 기준으로 데이터 간격을 채우는 것을 고려합니다.
분산 데이터 집계
Anomaly Detector API는 균일하게 분산된 시계열에서 가장 잘 작동합니다. 데이터가 무작위로 분산된 경우에는 분당, 매시간 또는 매일 같은 시간 단위로 집계해야 합니다.
계절성 패턴이 있는 데이터에 대한 변칙 검색
시계열 데이터에 일정한 간격으로 발생하는 계절성 패턴이 있는 경우 정확도 및 API 응답 시간을 향상시킬 수 있습니다.
JSON 요청을 생성할 때 period를 지정하면 변칙 검색 대기 시간을 최대 50%까지 줄일 수 있습니다. period는 시계열이 패턴을 반복하는 데 걸리는 대략적인 데이터 포인트 수를 지정하는 정수입니다. 예를 들어 하루에 하나의 데이터 포인트가 있는 시계열은 period가 7이고 시간당 하나의 포인트가 있는 시계열(동일한 주간 패턴)은 period가 7*24입니다. 데이터의 패턴이 불확실한 경우 이 매개 변수를 지정할 필요가 없습니다.
최상의 결과를 얻으려면 4개의 period에 해당하는 데이터 포인트에 1개를 추가로 더해서 제공합니다. 예를 들어 위에서 설명한 대로 주간 패턴이 있는 매시간 데이터는 요청 본문에 673개의 데이터 포인트를 제공해야 합니다(7 * 24 * 4 + 1).
실시간 모니터링을 위한 데이터 샘플링
스트리밍 데이터가 짧은 간격(예를 들어 초 또는 분)으로 샘플링되는 경우 권장되는 데이터 포인트 개수를 보내면 Anomaly Detector API의 최대 허용 개수(8640 데이터 포인트)를 초과할 수 있습니다. 데이터가 안정적인 계절성 패턴을 나타내는 경우 시계열 데이터 샘플을 시 단위 같은 더 큰 시간 간격으로 전송하는 것을 고려합니다. 이러한 방식으로 데이터를 샘플링하면 API 응답 시간도 현저하게 향상될 수 있습니다.