방법: 시계열 데이터에서 Anomaly Detector 단변량 API를 사용하는 방법
Important
2023년 9월 20일부터 새로운 Anomaly Detector 리소스를 만들 수 없습니다. Anomaly Detector 서비스는 2026년 10월 1일에 사용 중지됩니다.
Anomaly Detector API는 두 가지 변칙 검색 방법을 제공합니다. 시계열 전체에서 일괄 처리로 변칙을 검색하거나 최신 데이터 포인트의 변칙 상태를 검색하여 데이터가 생성될 때 변칙을 검색할 수 있습니다. 검색 모델은 각 데이터 포인트의 예상 값과 변칙 검색의 상한 및 하한을 포함하여 변칙 결과를 반환합니다. 이러한 값을 사용하여 일반 값의 범위와 데이터의 변칙을 시각화할 수 있습니다.
Anomaly Detection 모드
Anomaly Detector API는 검색 모드(일괄 처리 및 스트리밍)를 제공합니다.
참고 항목
다음 요청 URL은 구독에 적합한 엔드포인트와 결합되어야 합니다. 예: https://<your-custom-subdomain>.api.cognitive.microsoft.com/anomalydetector/v1.0/timeseries/entire/detect
일괄 검색
지정된 시간 범위 동안 데이터 포인트 일괄 처리를 통해 변칙을 검색하려면 시계열 데이터에 다음 요청 URI를 사용합니다.
/timeseries/entire/detect.
시계열 데이터를 한꺼번에 보내면 API는 전체 계열을 사용하여 모델을 생성하여 이를 통해 각 데이터 포인트를 분석합니다.
스트리밍 검색
스트리밍 데이터에 대해서 지속적으로 변칙을 검색하려면 최신 데이터 포인트와 함께 다음 요청 URI를 사용합니다.
/timeseries/last/detect.
새 데이터 포인트를 생성하면서 보내면 실시간으로 데이터를 모니터링할 수 있습니다. 보내는 데이터 포인트를 사용하여 모델이 생성되고 API는 시계열의 최신 포인트가 변칙인지 여부를 확인합니다.
변칙 검색의 하한 및 상한 조정
기본적으로 변칙 검색의 상한 및 하한은 expectedValue, upperMargin 및 lowerMargin을 사용하여 계산됩니다. 다른 경계가 필요한 경우 marginScale을 upperMargin 또는 lowerMargin에 적용하는 것이 좋습니다. 경계는 다음과 같이 계산됩니다.
| 경계 | 계산 |
|---|---|
upperBoundary |
expectedValue + (100 - marginScale) * upperMargin |
lowerBoundary |
expectedValue - (100 - marginScale) * lowerMargin |
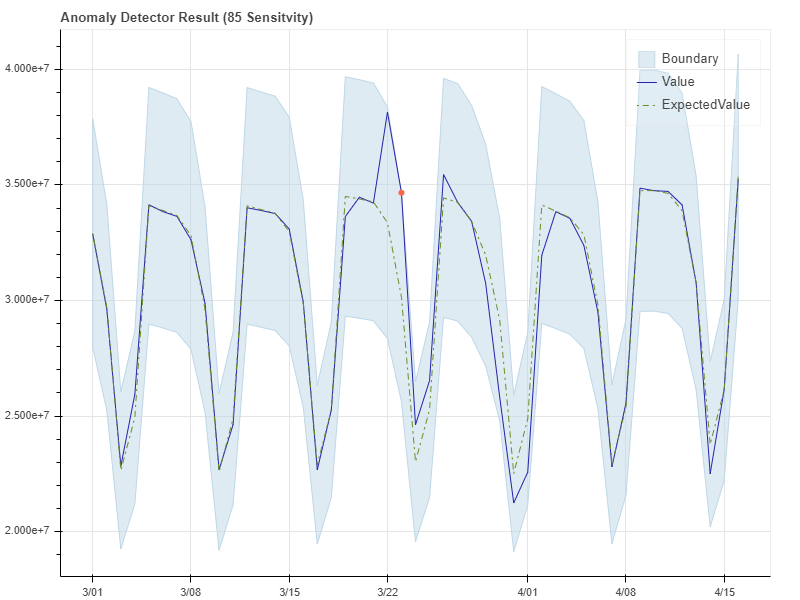
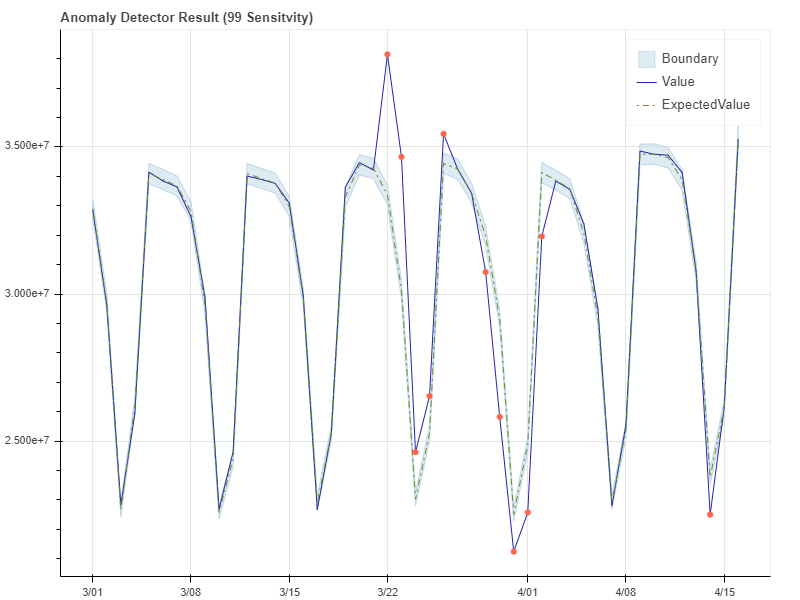
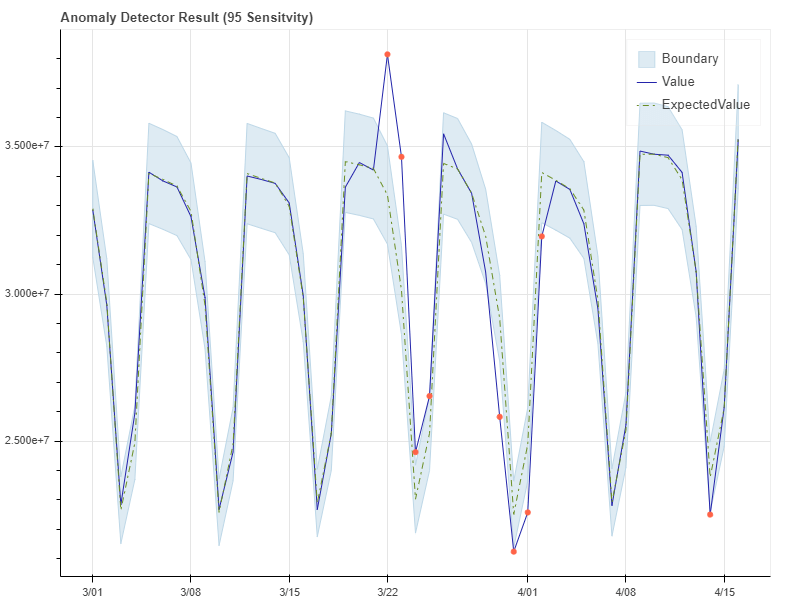
다음 예에서는 다른 민감도에서의 Anomaly Detector API 결과를 보여줍니다.
민감도 99의 예
민감도 95의 예
민감도 85의 예