문서 API 응답 분석
이 콘텐츠의 적용 대상은 다음과 같습니다.![]() v4.0(미리 보기)
v4.0(미리 보기)![]() v3.1(GA)
v3.1(GA)![]() v3.0(GA)
v3.0(GA)
이 문서에서는 응답의 AnalyzeDocument 일부로 반환된 다양한 개체와 애플리케이션에서 문서 분석 API 응답을 사용하는 방법을 살펴보겠습니다.
문서 분석 요청
문서 인텔리전스 API는 이미지, PDF 및 기타 문서 파일을 분석하여 다양한 콘텐츠, 레이아웃, 스타일 및 의미 요소를 추출하고 검색합니다. 분석 작업은 비동기 API입니다. 문서를 제출하면 완료를 위해 폴링할 URL이 포함된 Operation-Location 헤더가 반환됩니다. 분석 요청이 성공적으로 완료되면 응답에는 모델 데이터 추출에 설명된 요소가 포함됩니다.
응답 요소
콘텐츠 요소는 문서에서 추출된 기본 텍스트 요소입니다.
레이아웃 요소는 콘텐츠 요소를 구조 단위로 그룹화합니다.
스타일 요소는 콘텐츠 요소의 글꼴 및 언어를 설명합니다.
의미 체계 요소는 지정된 콘텐츠 요소에 의미를 할당합니다.
모든 콘텐츠 요소는 페이지 번호(1-인덱스 지정)로 지정된 페이지에 따라 그룹화됩니다. 또한 의미 체계적으로 연속적인 요소를 함께 배열하는 읽기 순서로 정렬됩니다. 이는 줄 또는 열 경계를 넘더라도 적용됩니다. 단락 및 기타 레이아웃 요소 간의 읽기 순서가 모호한 경우, 서비스는 일반적으로 왼쪽에서 오른쪽, 위에서 아래로 콘텐츠를 반환합니다.
참고 항목
현재 문서 인텔리전스는 페이지 경계를 넘는 읽는 순서를 지원하지 않습니다. 선택 표시가 주변 단어 내에 배치되지 않습니다.
최상위 콘텐츠 속성은 모든 콘텐츠 요소의 연결을 읽기 순서로 포함합니다. 모든 요소는 이 콘텐츠 문자열 내의 범위를 통해 읽기 순서로 위치가 지정됩니다. 일부 요소의 콘텐츠는 항상 연속적이지는 않습니다.
분석 응답
각 API에 대한 분석 응답은 서로 다른 개체를 반환합니다. API 응답에는 해당하는 경우 구성 요소 모델의 요소가 포함되어 있습니다.
| 응답 콘텐츠 | 설명 | API |
|---|---|---|
| pages | 입력 문서의 각 페이지에서 인식된 단어, 줄 및 범위입니다. | 읽기 모델, 레이아웃 모델, 일반 문서 모델, 미리 빌드된 모델, 사용자 지정 모델 |
| paragraphs | 단락으로 인식된 콘텐츠입니다. | 읽기 모델, 레이아웃 모델, 일반 문서 모델, 미리 빌드된 모델, 사용자 지정 모델 |
| styles | 식별된 텍스트 요소 속성입니다. | 읽기 모델, 레이아웃 모델, 일반 문서 모델, 미리 빌드된 모델, 사용자 지정 모델 |
| languages | 추출된 텍스트의 각 범위와 연결된 식별된 언어입니다. | 읽음 |
| tables | 문서에서 식별되고 추출된 테이블 형식 콘텐츠입니다. 테이블은 미리 학습된 레이아웃 모델로 식별된 테이블과 관련됩니다. 테이블로 레이블이 지정된 콘텐츠는 문서 개체에 구조화된 필드로 추출됩니다. | 레이아웃 모델, 일반 문서 모델, 청구서 모델, 사용자 지정 모델 |
| 수치 | 문서에서 식별 및 추출된 그림(차트, 이미지)은 복잡한 정보를 이해하는 데 도움이 되는 시각적 표현을 제공합니다. | 레이아웃 모델 |
| 섹션 | 문서에서 식별되고 추출된 계층적 문서 구조입니다. 해당 요소(단락, 표, 그림)가 연결된 섹션 또는 하위 섹션입니다. | 레이아웃 모델 |
| keyValuePairs | 미리 학습된 모델에서 인식되는 키-값 쌍입니다. 키는 관련 값이 있는 문서의 텍스트 범위입니다. | 일반 문서 모델, 청구서 모델 |
| documents | 인식된 필드는 문서 목록 내의 fields 사전에 반환됩니다. |
미리 빌드된 모델, 사용자 지정 모델. |
각 API에서 반환되는 개체에 대한 자세한 내용은 모델 데이터 추출을 참조하세요.
요소 속성
범위
범위는 전체 읽기 순서에서 각 요소의 논리적 위치를 지정하며, 각 범위는 최상위 콘텐츠 문자열 속성에서의 문자 오프셋 및 길이를 지정합니다. 기본적으로 문자 오프셋 및 길이는 사용자 인식 문자 단위(grapheme clusters 또는 텍스트 요소라고도 함)로 반환됩니다. 다른 문자 단위를 사용하는 다양한 개발 환경을 수용하려면 사용자는 유니코드 코드 포인트(Python 3) 또는 UTF16 코드 단위(Java, JavaScript, .NET)에서도 범위 오프셋 및 길이를 반환하는 stringIndexIndex 쿼리 매개 변수를 지정할 수 있습니다. 자세한 내용은 다국어/이모지 지원을 참조하세요.
경계 영역
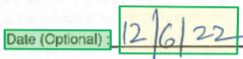
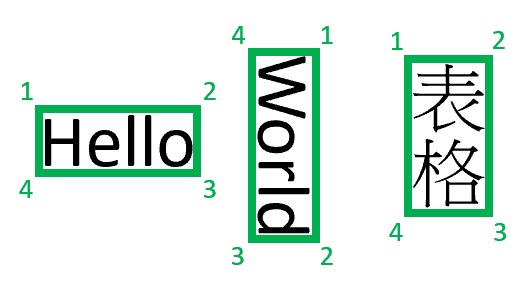
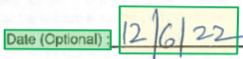
경계 영역은 파일에 있는 각 요소의 시각적 위치를 설명합니다. 요소가 시각적으로 연속되지 않거나 여러 페이지(테이블)에 걸쳐 있는 경우 대부분의 요소 위치는 경계 영역의 배열을 통해 설명됩니다. 각 영역은 페이지 번호(1 인덱싱됨) 및 경계 다각형을 지정합니다. 경계 다각형은 요소의 자연 방향을 기준으로 왼쪽에서 시계 방향으로 이어지는 포인트 시퀀스로 설명됩니다. 사분면의 경우 플롯 포인트는 왼쪽 위, 오른쪽 위, 오른쪽 아래 및 왼쪽 아래 모서리입니다. 각 점은 단위 속성에 지정된 페이지 단위의 x, y 좌표를 나타냅니다. 일반적으로 이미지의 측정 단위는 픽셀이며 PDF는 인치를 사용합니다.
참고 항목
현재 문서 인텔리전스는 4개의 꼭지점 사변형만 경계 다각형으로 반환합니다. 이후 버전에서는 곡선 또는 직사각형이 아닌 이미지와 같이 더 복잡한 셰이프를 설명할 수 있도록 다른 포인트 수를 반환하게 될 수 있습니다. 경계 영역은 렌더링된 파일에만 적용됩니다. 파일이 렌더링되지 않았다면 경계 영역이 반환되지 않습니다. 현재 docx/xlsx/pptx/html 형식의 파일은 렌더링되지 않습니다.
콘텐츠 요소
Word
단어는 문자 시퀀스로 구성된 콘텐츠 요소입니다. 문서 인텔리전스를 사용하면 단어는 인접한 문자의 시퀀스로 정의되며, 각 단어는 공백으로 구분됩니다. 단어 사이에 공백 구분 기호를 사용하지 않는 언어의 경우 각 문자는 의미 체계 단어 단위를 나타내지 않더라도 별도의 단어로 반환됩니다.

선택 표시
선택 영역 표시는 선택 영역의 상태를 나타내는 시각적 문자 모양을 대변하는 콘텐츠 요소입니다. 확인란은 흔히 사용되는 선택 표시의 한 형태입니다. 하지만 라디오 단추 또는 시각적 형식의 박스형 셀로 나타날 수도 있습니다. 선택 표시의 상태를 선택하거나 선택 취소하면 다른 시각적 표현으로 상태를 나타낼 수 있습니다.

레이아웃 요소
줄
줄은 시각적 공간으로 구분된 연속 콘텐츠 요소의 순서가 지정된 시퀀스이거나, 단어 사이에 공백 구분 기호가 없는 언어의 경우 곧바로 인접한 요소입니다. 동일한 가로 평면(행)에 있지만 둘 이상의 시각적 공간으로 구분된 콘텐츠 요소는 대부분 여러 개의 줄로 분할됩니다. 때때로 이 기능은 의미 체계적으로 연속된 콘텐츠를 별도의 줄로 분할하기도 하지만, 텍스트 콘텐츠 표현을 여러 열이나 셀로 분할할 수 있도록 합니다. 세로 쓰기의 줄은 세로 방향으로 검색됩니다.

단락
단락은 논리적 단위를 형성하는 순서가 지정된 줄 시퀀스입니다. 일반적으로 줄 간에는 동일한 공통 맞춤과 간격이 사용됩니다. 단락은 들여쓰기, 추가 간격 또는 글머리 기호/번호 매기기를 통해 구분되는 경우가 많습니다. 콘텐츠는 단일 단락에만 할당할 수 있습니다. 선택 단락은 문서의 기능 역할과도 연결될 수 있습니다. 현재 지원되는 역할에는 페이지 머리글, 페이지 바닥글, 페이지 번호, 제목, 섹션 제목 및 각주 등이 있습니다.

페이지
페이지는 콘텐츠를 그룹화한 것으로 일반적으로 용지 한쪽에 해당합니다. 렌더링된 페이지는 지정된 단위의 너비와 높이를 특징으로 합니다. 일반적으로 이미지는 픽셀을 사용하고 PDF는 인치를 사용합니다. 각도 속성은 회전할 수 있는 페이지의 전체 텍스트 각도를 도 단위로 설명합니다.
참고 항목
Excel과 같은 스프레드시트의 경우 각 시트가 페이지에 매핑됩니다. PowerPoint와 같은 프레젠테이션의 경우 각 슬라이드가 페이지에 매핑됩니다. HTML 또는 Word 문서와 같이 렌더링되지 않고 페이지의 네이티브 개념이 없는 파일 형식의 경우 파일의 기본 콘텐츠는 단일 페이지로 간주됩니다.
테이블
테이블은 콘텐츠를 그리드 레이아웃의 셀 그룹으로 구성합니다. 행과 열은 눈금선, 색상 밴딩 또는 더 큰 간격으로 시각적으로 구분될 수 있습니다. 테이블 셀의 위치는 행 및 열 인덱스를 통해 지정됩니다. 셀은 여러 행과 열에 걸쳐 있을 수 있습니다.
위치 및 스타일에 따라 셀은 일반 콘텐츠, 행 머리글, 열 머리글, 스텁 헤드 또는 설명으로 분류될 수 있습니다.
행 머리글 셀은 일반적으로 행의 다른 셀을 설명하는 행의 첫 번째 셀입니다.
열 머리글 셀은 일반적으로 열의 다른 셀을 설명하는 열의 첫 번째 셀입니다.
행 또는 열에는 계층적 콘텐츠를 설명하는 여러 머리글 셀이 포함될 수 있습니다.
스텁 헤드 셀은 일반적으로 첫 번째 행과 첫 번째 열 위치에 있는 셀입니다. 비어 있을 수도 있고, 동일한 행/열의 머리글 셀에 있는 값을 설명할 수도 있습니다.
설명 셀은 일반적으로 테이블의 맨 위쪽 또는 아래쪽 영역에 표시되며 전체 테이블 내용을 설명합니다. 그러나 테이블을 섹션으로 나누기 위해 테이블 중간에 표시되는 경우도 있습니다. 일반적으로 설명 셀은 단일 행의 여러 셀에 걸쳐 있습니다.
테이블 캡션은 테이블을 설명하는 콘텐츠를 지정합니다. 테이블에는 연결된 캡션과 일련의 각주가 있을 수 있습니다. 설명 셀과 달리 캡션은 일반적으로 그리드 레이아웃 외부에 있습니다. 표 각주가 표 안의 내용에 주석을 달며 표 표 아래에 각주 기호가 표시되는 경우가 많습니다.
레이아웃 테이블은 테이블 형식 데이터에서 추출된 문서 필드와 다릅니다. 레이아웃 테이블은 콘텐츠의 의미 체계를 고려하지 않고 문서의 테이블 형식 시각적 콘텐츠에서 추출됩니다. 실제로 일부 레이아웃 테이블은 오로지 시각적 레이아웃을 위해 설계되었으며, 구조화된 데이터를 포함하지 않는 경우도 있습니다. 영수증의 항목별 세부 정보와 같이 다양한 시각적 레이아웃이 있는 문서에서 구조화된 데이터를 추출하는 방법의 경우 일반적으로 대규모의 후처리를 진행해야 합니다. 정규화된 필드 이름이 있는 구조화된 필드에 행 또는 열 머리글을 매핑하는 것이 필수입니다. 문서 유형에 따라 미리 빌드된 모델을 사용하거나 사용자 지정 모델을 학습시켜 이러한 구조화된 콘텐츠를 추출합니다. 그 결과로 얻은 정보는 문서 필드로 공개됩니다. 이러한 학습된 모델은 테이블 형식이 아닌 머리글 및 구조화된 데이터가 없는 표 형식 데이터(예: 이력서의 경력 섹션)또한 처리할 수 있습니다.

수치
문서의 그림(차트, 이미지)은 텍스트 콘텐츠를 보완하고 향상시키는 데 중요한 역할을 하며 복잡한 정보를 이해하는 데 도움이 되는 시각적 표현을 제공합니다. 레이아웃 모델에서 검색된 그림 개체에는 그림의 경계를 윤곽을 그리는 페이지 번호 및 다각형 좌표를 포함하여 문서 페이지에 있는 그림의 공간 위치) spans 와 같은 boundingRegions 주요 속성이 있습니다(그림과 관련된 텍스트 범위를 자세히 설명하고 문서 텍스트 내에서 오프셋과 길이를 지정합니다. 이 연결은 그림을 관련 텍스트 컨텍스트 elements 와 연결하고,(그림과 관련되거나 설명되는 문서 내의 텍스트 요소 또는 단락에 대한 식별자) 및 caption 있는 경우 도움이 됩니다.
{
"figures": [
{
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15",
...
],
"caption": {
"content": "Here is a figure with some text",
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15"
]
}
}
]
}
섹션
계층적 문서 구조 분석은 광범위한 문서를 구성, 이해 및 처리하는 데 중요한 역할을 합니다. 이 접근 방식은 이해력을 높이고 탐색을 용이하게 하며 정보 검색을 개선하기 위해 긴 문서를 의미상 분할하는 데 매우 중요합니다. 문서 생성 AI에서 RAG(검색 보강 세대) 의 출현은 계층적 문서 구조 분석의 중요성을 강조합니다. 레이아웃 모델은 각 섹션 내의 섹션과 개체의 관계를 식별하는 출력의 섹션 및 하위 섹션을 지원합니다. 계층 구조는 각 섹션에 elements 기본.
{
"sections": [
{
"spans": [],
"elements": [
"/paragraphs/0",
"/sections/1",
"/sections/2",
"/sections/5"
]
},
...
}
양식 필드(키 값 쌍)
양식 필드는 필드 레이블(키) 및 값으로 구성됩니다. 필드 레이블은 일반적으로 필드의 의미를 설명하는 설명 텍스트 문자열입니다. 값의 왼쪽에 표시되는 경우가 많지만 값 위쪽이나 아래쪽에 표시될 수도 있습니다. 필드 값에는 특정 필드 인스턴스의 콘텐츠 값이 포함됩니다. 값은 단어, 선택 표시 및 기타 콘텐츠 요소로 구성될 수 있습니다. 채워지지 않은 양식 필드의 경우 비어 있을 수도 있습니다. 특수 형식의 양식 필드에는 필드 레이블이 오른쪽에 있는 선택 표시 값이 있습니다. 문서 필드는 일반 양식 필드와 비슷하면서도 다른 개념입니다. 일반 양식 필드의 필드 레이블(키)은 문서에 표시되어야 합니다. 따라서 일반적으로 영수증의 가맹점 이름과 같은 정보는 캡처할 수 없습니다. 문서 필드에는 레이블이 지정되고 키를 추출하지 않습니다. 문서 필드는 추출된 값만 레이블이 지정된 키에 매핑합니다. 자세한 내용은 문서 필드를 참조하세요.

스타일 요소
스타일
스타일 요소는 텍스트 콘텐츠에 적용할 글꼴 스타일을 설명합니다. 콘텐츠는 전역 콘텐츠 속성에 대한 범위를 통해 지정됩니다. 현재 감지되는 유일한 글꼴 스타일은 텍스트가 필기로 작성된 것인지 여부뿐입니다. 앞으로 다른 스타일이 추가되면 충돌하지 않는 여러 스타일 개체를 통해 텍스트를 설명할 수 있습니다. 압축성을 높이기 위해, 특정 글꼴 스타일을 (동일한 신뢰도로) 공유하는 모든 텍스트는 단일 스타일 개체를 통해 설명됩니다.
{
"confidence": 1,
"spans": [
{
"offset": 2402,
"length": 7
}
],
"isHandwritten": true
}
언어
언어 요소는 전역 콘텐츠 속성에 대한 범위를 통해 지정된 콘텐츠로 감지된 언어를 설명합니다. 감지된 언어는 BCP-47 언어 태그를 통해 지정되어 기본 언어와 선택적 스크립트 및 지역 정보를 나타냅니다. 예를 들어 영어와 중국어 번체는 각각 "en" 및 zh-Hant로 인식됩니다. 영국 영어의 지역별 맞춤법 차이로 인해 텍스트가 en-GB로 감지될 수도 있습니다. 언어 요소는 주요 언어(예: 숫자)가 없는 텍스트를 다루지 않습니다.
의미 체계 요소
참고 항목
여기서 설명하는 의미 체계 요소는 문서 인텔리전스 미리 빌드된 모델에 적용됩니다. 사용자 지정 모델은 다른 데이터 표현을 반환할 수 있습니다. 예를 들어 사용자 지정 모델에서 반환되는 날짜 및 시간은 표준 ISO 8601 서식과 다른 패턴으로 표시될 수 있습니다.
문서
문서는 의미 체계상 완전한 하나의 단위입니다. PDF 파일 안에 세금 양식이 여러 개 있거나, 단일 페이지 안에 영수증이 여러 개 있는 경우처럼 파일에 여러 문서가 포함될 수 있습니다. 그러나 파일 내의 문서 순서는 전달되는 정보에 근본적인 영향을 미치지 않습니다.
참고 항목
현재 문서 인텔리전스는 단일 페이지에 여러 문서를 지원하지 않습니다.
문서 형식은 시각적 개체 템플릿이나 레이아웃과 관계없이 구조화된 스키마로 표현되는 공통된 의미 체계 필드 집합을 공유하는 문서를 설명합니다. 예를 들어 "영수증" 유형의 모든 문서에는 가맹점 이름, 거래 날짜 및 거래 합계가 포함될 수 있지만, 레스토랑 영수증과 호텔 영수증은 모양이 다른 경우가 많습니다.
문서 요소에는 감지된 문서 형식의 의미 체계 스키마에 의해 지정된 필드 중에서 인식된 필드의 목록이 포함됩니다.
문서 필드는 추출하거나 유추할 수 있습니다. 추출된 필드는 추출된 콘텐츠로 표시되며, 해석 가능한 경우 필요에 따라 정규화된 값으로 표시됩니다.
유추된 필드에는 콘텐츠 속성이 없으며 해당 필드의 값으로만 표시됩니다.
배열 필드에는 콘텐츠 속성이 포함되지 않습니다. 이 콘텐츠는 배열 요소의 콘텐츠와 연결할 수 있습니다.
개체 필드에는 추출된 하위 필드의 상위 집합일 수 있는 개체를 나타내는 전체 콘텐츠를 지정하는 콘텐츠 속성이 포함되어 있습니다.
문서 형식의 의미 체계 스키마는 문서 형식에 포함될 수 있는 필드를 통해 설명되어 있습니다. 각 필드 스키마는 정식 이름과 값 형식을 통해 지정됩니다. 필드 값 형식에는 기본(예: 문자열), 복합(예: 주소) 및 구조적(예: 배열, 개체) 형식이 있습니다. 필드 값 형식은 감지된 콘텐츠를 정규화 표현으로 변환하기 위해 수행되는 의미 체계 정규화 또한 지정합니다. 정규화는 로캘에 따라 달라질 수 있습니다.
기본 형식
| 필드 값 형식 | 설명 | 정규화된 표현 | 예제(필드 콘텐츠 -> 값) |
|---|---|---|---|
| string | 일반 텍스트 | 콘텐츠와 동일 | MerchantName: "Contoso" → "Contoso" |
| date | 날짜 | ISO 8601 - YYYY-MM-DD | InvoiceDate: "2022년 5월 7일" → "2022-05-07" |
| time | Time | ISO 8601 - hh:mm:ss | TransactionTime: "오후 9시 45분" → "21:45:00" |
| phoneNumber | 전화번호 | E.164 - +{CountryCode}{SubscriberNumber} | WorkPhone: "(800) 555-7676" → "+18005557676" |
| countryRegion | 국가/지역 | ISO 3166-1 alpha-3 | CountryRegion: "미국" → "USA" |
| selectionMark | 선택됨 | "signed" 또는 "unsigned" | AcceptEula: ☑ → "selected" |
| signature | 서명됨 | 콘텐츠와 동일 | LendeeSignature: {signature} → "signed" |
| 번호 | 부동 소수점 수 | 부동 소수점 수 | 수량: "1.20" → 1.2 |
| 정수 | 정수 | 64비트 부호 있는 숫자 | 개수: "123" → 123 |
| 부울 값 | 부울 값 | true/false | IsStatutoryEmployee: ☑ → true |
복합 형식
통화: 통화 단위(선택 사항)가 있는 통화 금액입니다. 값이며, 예를 들면
InvoiceTotal: $123.45입니다.{ "amount": 123.45, "currencySymbol": "$" }주소: 구문 분석된 주소입니다. 예:
ShipToAddress: 123 Main St., Redmond, WA 98052{ "poBox": "PO Box 12", "houseNumber": "123", "streetName": "Main St.", "city": "Redmond", "state": "WA", "postalCode": "98052", "countryRegion": "USA", "streetAddress": "123 Main St." }
구조적 형식
배열: 형식이 동일한 필드의 목록
"Items": { "type": "array", "valueArray": [ ] }개체: 형식이 다를 수 있는 하위 필드의 명명된 목록
"InvoiceTotal": { "type": "currency", "valueCurrency": { "currencySymbol": "$", "amount": 110 }, "content": "$110.00", "boundingRegions": [ { "pageNumber": 1, "polygon": [ 7.3842, 7.465, 7.9181, 7.465, 7.9181, 7.6089, 7.3842, 7.6089 ] } ], "confidence": 0.945, "spans": [ { "offset": 806, "length": 7 } ] }
다음 단계
Document Intelligence Studio를 사용하여 사용자 고유의 양식 및 문서를 처리해 보세요.
Document Intelligence 빠른 시작을 완료하고 원하는 개발 언어로 문서 처리 앱 만들기를 시작해 보세요.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기