자습서: Azure Functions 및 Python을 사용하여 저장된 문서 처리
문서 인텔리전스는 Azure Functions를 사용하여 빌드된 자동화된 데이터 처리 파이프라인의 일부로 사용할 수 있습니다. 이 가이드에서는 Azure Functions를 사용하여 Azure Blob 스토리지 컨테이너에 업로드된 문서를 처리하는 방법을 보여 줍니다. 이 워크플로는 문서 인텔리전스 레이아웃 모델을 사용하여 저장된 문서에서 테이블 데이터를 추출하고 테이블 데이터를 Azure의 .csv 파일에 저장합니다. 그런 다음, Microsoft Power BI를 사용하여 데이터를 표시할 수 있습니다(여기서는 설명하지 않음).
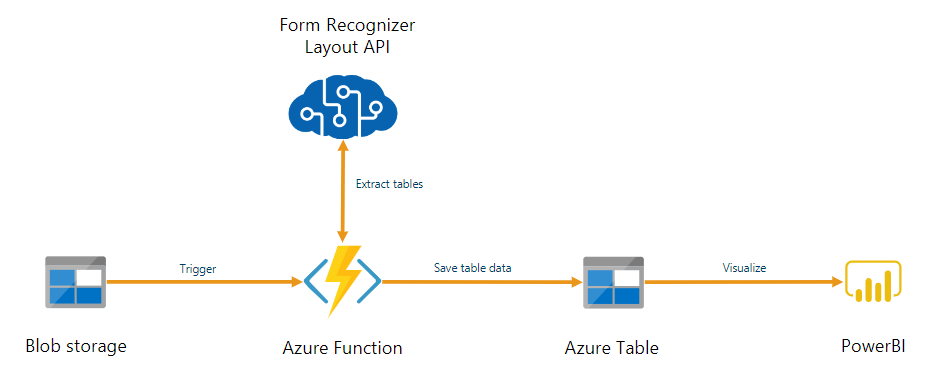
이 자습서에서는 다음을 하는 방법을 알아볼 수 있습니다.
- Azure Storage 계정을 만듭니다.
- Azure Functions 프로젝트를 만듭니다.
- 업로드된 양식에서 레이아웃 데이터를 추출합니다.
- 추출된 레이아웃 데이터를 Azure Storage에 업로드합니다.
필수 조건
Azure 구독 - 체험 구독 만들기
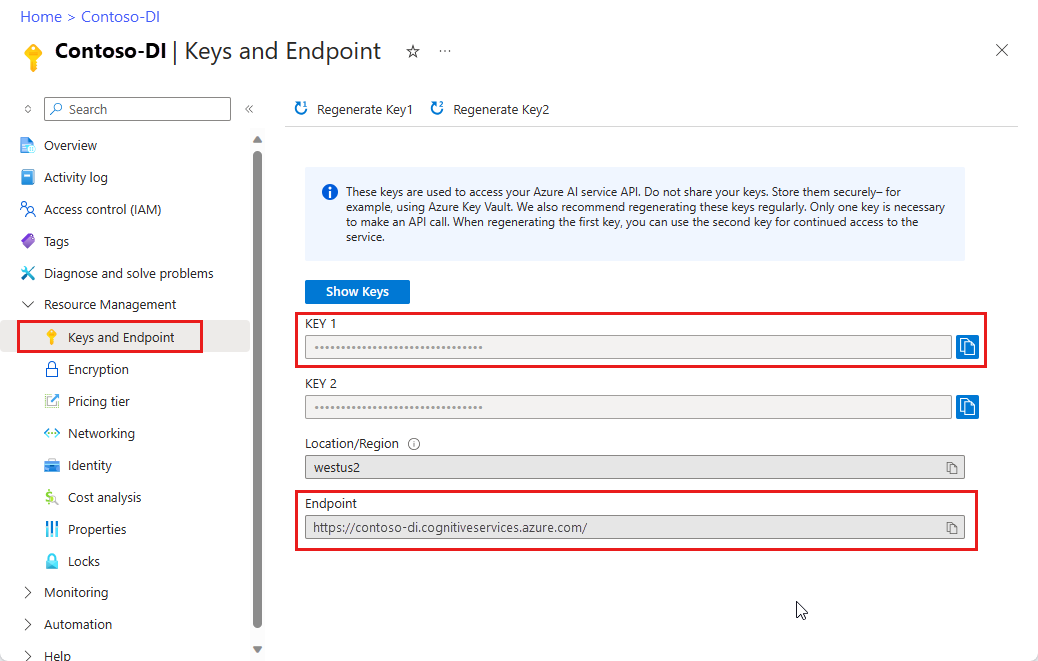
문서 인텔리전스 리소스. Azure를 구독하고 나면 Azure portal에서 문서 인텔리전스 리소스를 생성하여 키와 엔드포인트를 가져옵니다. 평가판 가격 책정 계층(
F0)을 통해 서비스를 사용해보고, 나중에 프로덕션용 유료 계층으로 업그레이드할 수 있습니다.리소스를 배포한 후 리소스로 이동을 선택합니다. 애플리케이션을 문서 인텔리전스 API에 연결하려면 만든 리소스의 키와 엔드포인트가 필요합니다. 이 자습서의 뒷부분에서 키와 엔드포인트를 아래 코드에 붙여넣습니다.
Python 3.6.x, 3.7.x, 3.8.x 또는 3.9.x(Python 3.10.x는 이 프로젝트에서 지원되지 않음)
다음 확장이 설치된 최신 버전의 VS Code(Visual Studio Code)
Azure Functions 확장. 설치되면 왼쪽 탐색 창에 Azure 로고가 표시됩니다.
Azure Functions Core Tools 버전 3.x(버전 4.x는 이 프로젝트에서 지원되지 않음)
Python 확장(Visual Studio Code용). 자세한 내용은 VS Code에서 Python 시작을 참조하세요.
분석할 로컬 PDF 문서. 샘플 PDF 문서를 이 프로젝트에 사용할 수 있습니다.
Azure Storage 계정 만들기
Azure Portal에서 범용 v2 Azure Storage 계정을 만듭니다. 스토리지 컨테이너를 사용하여 Azure 스토리지 계정을 만드는 방법을 모르는 경우 다음 빠른 시작을 따릅니다.
- 스토리지 계정 만들기 스토리지 계정을 만들 때 인스턴스 세부 사항>성능 필드에서 표준 성능을 선택합니다.
- 컨테이너를 만듭니다. 컨테이너를 만드는 경우 새 컨테이너 창에서 퍼블릭 액세스 수준을 컨테이너(컨테이너 및 파일에 대한 익명 읽기 액세스)로 설정합니다.
왼쪽 창에서 리소스 공유(CORS) 탭을 선택하고, 기존 CORS 정책을 제거합니다(있는 경우).
배포되면 test 및 output이라는 두 개의 빈 Blob 스토리지 컨테이너를 만듭니다.
Azure Functions 프로젝트 만들기
프로젝트를 포함할 functions-app이라는 새 폴더를 만들고, 선택을 선택합니다.
Visual Studio Code를 열고, 명령 팔레트를 엽니다(Ctrl+Shift+P). Python: 인터프리터 선택을 검색하여 선택하고, 버전 3.6.x, 3.7.x, 3.8.x 또는 3.9.x인 설치된 Python 인터프리터를 선택합니다. 이 선택 항목은 선택한 Python 인터프리터 경로를 프로젝트에 추가합니다.
왼쪽 탐색 창에서 Azure 로고를 선택합니다.
[리소스] 보기에 기존 Azure 리소스가 표시됩니다.
이 프로젝트에 사용하는 Azure 구독을 선택합니다. 그러면 그 아래에 [Azure Function 앱]이 표시됩니다.
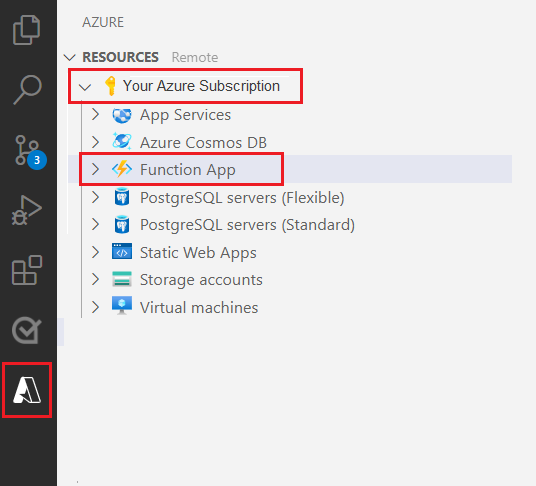
나열된 리소스 아래에 있는 [작업 영역(로컬)] 섹션을 선택합니다. 더하기 기호, 함수 만들기 단추를 차례로 선택합니다.

메시지가 표시되면 새 프로젝트 만들기를 선택하고, function-app 디렉터리로 이동합니다. 선택을 선택합니다.
다음과 같은 몇 가지 여러 설정을 구성하라는 메시지가 표시됩니다.
언어 선택 → Python을 선택합니다.
가상 환경을 만들 Python 인터프리터 선택 → 이전에 기본값으로 설정한 인터프리터를 선택합니다.
템플릿 선택 → Azure Blob Storage 트리거를 선택하고. 트리거 이름을 지정하거나 기본 이름을 적용합니다. Enter 키를 눌러 확인합니다.
설정 선택 → 드롭다운 메뉴에서 ➕ 새 로컬 앱 설정 만들기를 선택합니다.
구독 선택 → 만든 스토리지 계정이 있는 Azure 구독을 선택하고, 스토리지 계정을 선택하고, 스토리지 입력 컨테이너의 이름(이 경우
input/{name})을 선택합니다. Enter 키를 눌러 확인합니다.프로젝트를 여는 방법 선택 → 드롭다운 창에서 현재 창에서 프로젝트 열기를 선택합니다.
이러한 단계가 완료되면 VS Code에서 __init__.py Python 스크립트를 사용하여 새 Azure Function 프로젝트를 추가합니다. 이 스크립트는 파일을 input 스토리지 컨테이너에 업로드할 때 트리거됩니다.
import logging
import azure.functions as func
def main(myblob: func.InputStream):
logging.info(f"Python blob trigger function processed blob \n"
f"Name: {myblob.name}\n"
f"Blob Size: {myblob.length} bytes")
함수 테스트
F5 키를 눌러 기본 함수를 실행합니다. VS Code에서 인터페이스할 스토리지 계정을 선택하라는 메시지를 표시합니다.
만든 스토리지 계정을 선택하고 계속합니다.
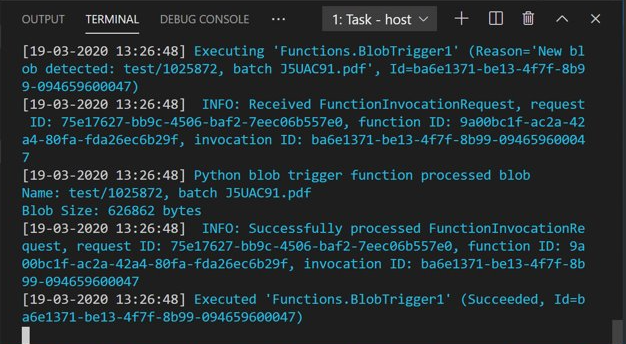
Azure Storage Explorer를 열고, 샘플 PDF 문서를 input 컨테이너에 업로드합니다. 그런 다음, VS Code 터미널을 확인합니다. 스크립트에서 PDF 업로드를 통해 트리거되었다고 기록해야 합니다.
계속하기 전에 스크립트를 중지합니다.
문서 처리 코드 추가
다음으로, 문서 인텔리전스 서비스를 호출하고 문서 인텔리전스 레이아웃 모델을 사용하여 업로드된 문서를 구문 분석하는 자체 코드를 Python 스크립트에 추가합니다.
VS Code에서 함수의 requirements.txt 파일로 이동합니다. 이 파일은 스크립트에 대한 종속성을 정의합니다. 다음 Python 패키지를 파일에 추가합니다.
cryptography azure-functions azure-storage-blob azure-identity requests pandas numpy그런 다음, __init__.py 스크립트를 엽니다. 다음
import문을 추가합니다.import logging from azure.storage.blob import BlobServiceClient import azure.functions as func import json import time from requests import get, post import os import requests from collections import OrderedDict import numpy as np import pandas as pd생성된
main함수를 있는 그대로 둘 수 있습니다. 사용자 지정 코드를 이 함수 내에 추가합니다.# This part is automatically generated def main(myblob: func.InputStream): logging.info(f"Python blob trigger function processed blob \n" f"Name: {myblob.name}\n" f"Blob Size: {myblob.length} bytes")다음 코드 블록에서는 업로드된 문서에서 문서 인텔리전스 레이아웃 분석 API를 호출합니다. 엔드포인트 및 키 값을 입력합니다.
# This is the call to the Document Intelligence endpoint endpoint = r"Your Document Intelligence Endpoint" apim_key = "Your Document Intelligence Key" post_url = endpoint + "/formrecognizer/v2.1/layout/analyze" source = myblob.read() headers = { # Request headers 'Content-Type': 'application/pdf', 'Ocp-Apim-Subscription-Key': apim_key, } text1=os.path.basename(myblob.name)Important
완료되면 코드에서 키를 제거하고 공개적으로 게시하지 마세요. 프로덕션의 경우 Azure Key Vault와 같은 자격 증명을 안전하게 저장하고 액세스하는 방법을 사용합니다. 자세한 내용은 Azure AI 서비스 보안을 참조하세요.
다음으로, 서비스를 쿼리하고 반환된 데이터를 가져오는 코드를 추가합니다.
resp = requests.post(url=post_url, data=source, headers=headers) if resp.status_code != 202: print("POST analyze failed:\n%s" % resp.text) quit() print("POST analyze succeeded:\n%s" % resp.headers) get_url = resp.headers["operation-location"] wait_sec = 25 time.sleep(wait_sec) # The layout API is async therefore the wait statement resp = requests.get(url=get_url, headers={"Ocp-Apim-Subscription-Key": apim_key}) resp_json = json.loads(resp.text) status = resp_json["status"] if status == "succeeded": print("POST Layout Analysis succeeded:\n%s") results = resp_json else: print("GET Layout results failed:\n%s") quit() results = resp_jsonAzure Storage output 컨테이너에 연결하는 다음 코드를 추가합니다. 스토리지 계정 이름 및 키에 대한 사용자 고유의 값을 입력합니다. Azure Portal에 있는 스토리지 리소스의 액세스 키 탭에서 키를 가져올 수 있습니다.
# This is the connection to the blob storage, with the Azure Python SDK blob_service_client = BlobServiceClient.from_connection_string("DefaultEndpointsProtocol=https;AccountName="Storage Account Name";AccountKey="storage account key";EndpointSuffix=core.windows.net") container_client=blob_service_client.get_container_client("output")다음 코드에서는 반환된 문서 인텔리전스 응답을 구문 분석하고, .csv 파일을 생성한 후 output 컨테이너에 업로드합니다.
Important
자체 문서 구조와 일치하도록 이 코드를 편집해야 할 수 있습니다.
# The code below extracts the json format into tabular data. # Please note that you need to adjust the code below to your form structure. # It probably won't work out-of-the-box for your specific form. pages = results["analyzeResult"]["pageResults"] def make_page(p): res=[] res_table=[] y=0 page = pages[p] for tab in page["tables"]: for cell in tab["cells"]: res.append(cell) res_table.append(y) y=y+1 res_table=pd.DataFrame(res_table) res=pd.DataFrame(res) res["table_num"]=res_table[0] h=res.drop(columns=["boundingBox","elements"]) h.loc[:,"rownum"]=range(0,len(h)) num_table=max(h["table_num"]) return h, num_table, p h, num_table, p= make_page(0) for k in range(num_table+1): new_table=h[h.table_num==k] new_table.loc[:,"rownum"]=range(0,len(new_table)) row_table=pages[p]["tables"][k]["rows"] col_table=pages[p]["tables"][k]["columns"] b=np.zeros((row_table,col_table)) b=pd.DataFrame(b) s=0 for i,j in zip(new_table["rowIndex"],new_table["columnIndex"]): b.loc[i,j]=new_table.loc[new_table.loc[s,"rownum"],"text"] s=s+1마지막으로, 코드의 마지막 블록에서는 추출된 테이블과 텍스트 데이터를 Blob 스토리지 요소에 업로드합니다.
# Here is the upload to the blob storage tab1_csv=b.to_csv(header=False,index=False,mode='w') name1=(os.path.splitext(text1)[0]) +'.csv' container_client.upload_blob(name=name1,data=tab1_csv)
함수 실행
F5 키를 눌러 함수를 다시 실행합니다.
Azure Storage Explorer를 사용하여 샘플 PDF 양식을 input 스토리지 컨테이너에 업로드합니다. 이 작업은 실행할 스크립트를 트리거한 다음, output 컨테이너에 결과 .csv 파일(테이블로 표시됨)을 표시합니다.
이 컨테이너를 Power BI에 연결하여 포함된 데이터에 대한 풍부한 시각화를 만들 수 있습니다.
다음 단계
이 자습서에서는 Python으로 작성된 Azure 함수를 사용하여 업로드된 PDF 문서를 자동으로 처리하고 해당 콘텐츠를 보다 더 데이터 친화적인 형식으로 출력하는 방법을 알아보았습니다. 다음으로 Power BI를 사용하여 데이터를 표시하는 방법을 알아봅니다.
- 문서 인텔리전스란?
- 레이아웃 모델에 대해 자세히 알아보기
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기