빠른 시작: 음성을 인식하고 텍스트로 변환
Important
이 문서에 표시된 항목(미리 보기)은 현재 퍼블릭 미리 보기에서 확인할 수 있습니다. 이 미리 보기는 서비스 수준 계약 없이 제공되며, 프로덕션 워크로드에는 권장되지 않습니다. 특정 기능이 지원되지 않거나 기능이 제한될 수 있습니다. 자세한 내용은 Microsoft Azure Preview에 대한 추가 사용 약관을 참조하세요.
이 빠른 시작에서는 Azure AI Foundry에서 실시간 음성 텍스트 변환을 시도합니다.
필수 조건
- Azure 구독 - 체험 구독 만들기
- 일부 Azure AI 서비스 기능은 Azure AI Foundry 포털에서 무료로 사용해 보세요. 이 문서에 설명된 모든 기능에 액세스하려면 Azure AI Foundry에서 AI 서비스를 연결해야 합니다.
실시간 음성 텍스트 변환 시도
Azure AI Foundry 프로젝트로 이동합니다. 프로젝트를 만들어야 하는 경우 Azure AI Foundry 프로젝트 만들기를 참조하세요.
왼쪽 창에서 플레이그라운드를 선택한 다음 사용할 놀이터를 선택합니다. 이 예제에서는 Speech 플레이그라운드 시도를 선택합니다.
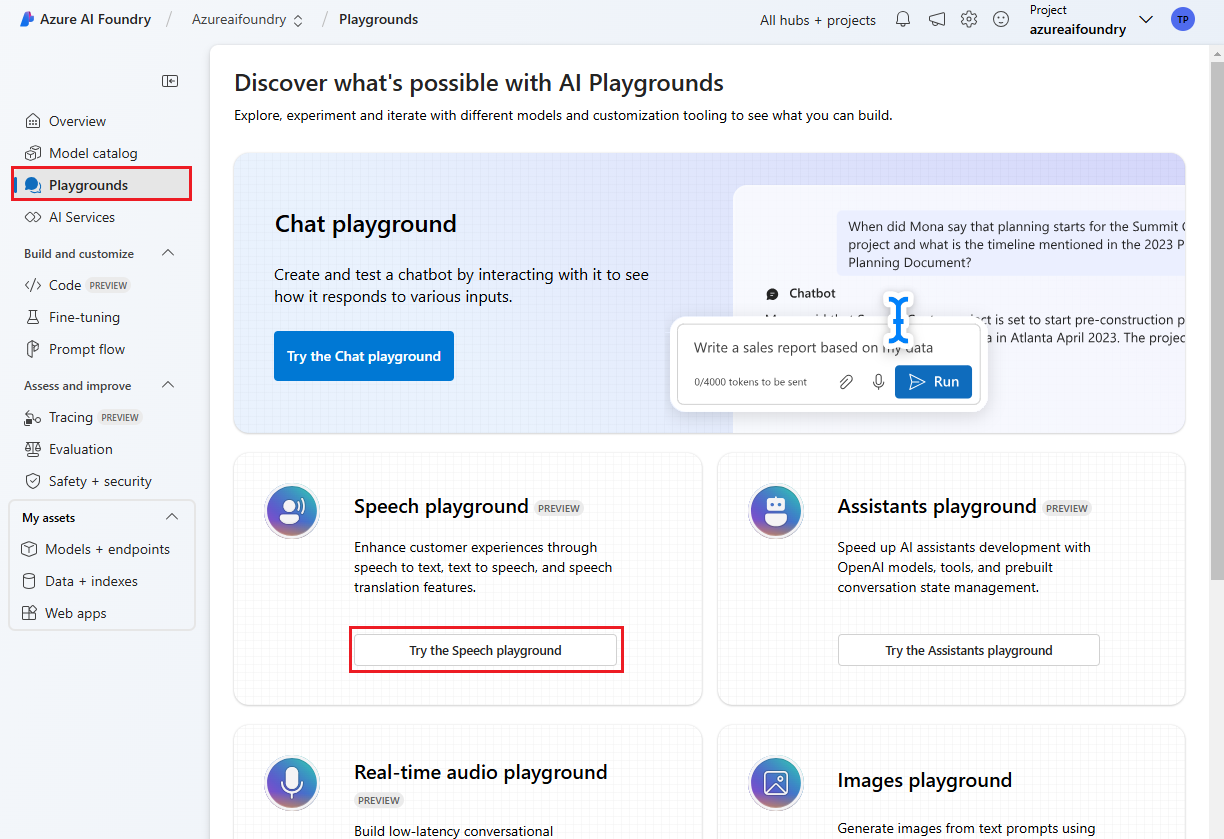
필요에 따라 놀이터에서 사용할 다른 연결을 선택할 수 있습니다. Speech Playground에서 Azure AI Services 다중 서비스 리소스 또는 Speech Service 리소스에 연결할 수 있습니다.
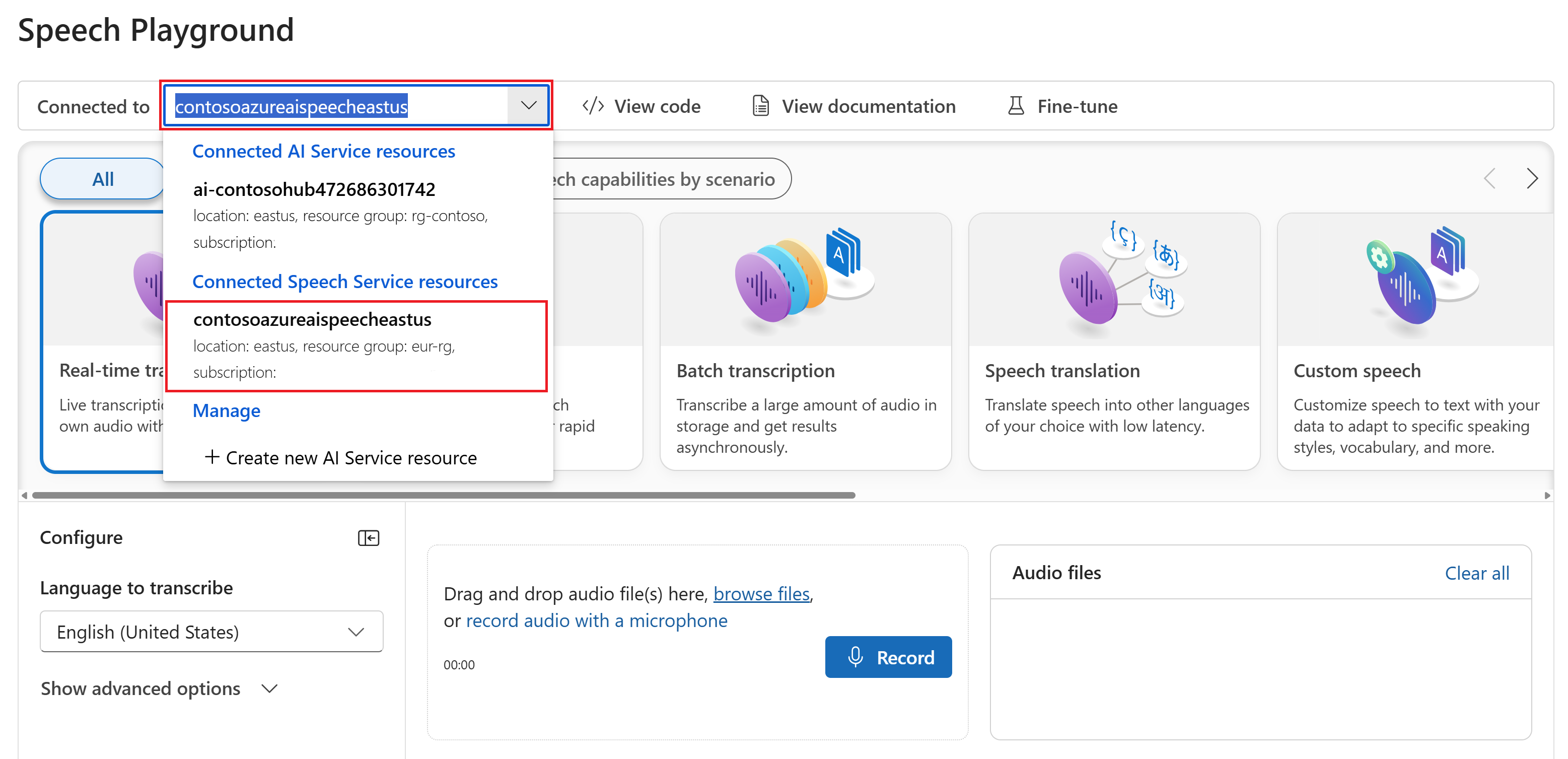
실시간 전사를 선택합니다.
고급 옵션 표시를 선택하여 다음과 같은 음성 텍스트 변환 옵션을 구성합니다.
- 언어 식별: 지원되는 언어 목록과 비교할 때 오디오에서 말하는 언어를 식별하는 데 사용됩니다. 시작 시 및 지속적인 인식과 같은 언어 식별 옵션에 대한 자세한 내용은 언어 식별을 참조하세요.
- 화자 분리: 오디오에서 화자를 식별하고 구분하는 데 사용됩니다. 분할은 대화에 참여하는 서로 다른 화자를 구분합니다. Speech Services는 어떤 화자가 기록된 음성의 특정 부분을 말하고 있는지에 대한 정보를 제공합니다. 화자 분리에 대한 자세한 내용은 화자 분리를 사용하여 실시간 음성 텍스트 변환 빠른 시작을 참조하세요.
- 사용자 지정 엔드포인트: 사용자 지정 음성에서 배포된 모델을 사용하여 인식 정확도를 향상시킵니다. Microsoft의 기준 모델을 사용하려면 이 집합을 없음으로 둡니다. Custom Speech에 대한 자세한 내용은 Custom Speech를 참조하세요.
- 출력 형식: 간단한 출력 형식과 자세한 출력 형식 중에서 선택합니다. 간단한 출력에는 표시 형식 및 타임스탬프가 포함됩니다. 자세한 출력에는 더 많은 형식(예: 표시, 어휘, ITN 및 마스킹된 ITN), 타임스탬프 및 N-best 목록이 포함됩니다.
- 구 목록: 사람 이름 또는 특정 위치와 같은 알려진 구 목록을 제공하여 대화 내용 기록 정확도를 향상시킵니다. 쉼표 또는 세미콜론을 사용하여 구 목록의 각 값을 구분합니다. 구 목록에 대한 자세한 내용은 구 목록을 참조하세요.
업로드할 오디오 파일을 선택하거나 실시간으로 오디오를 녹음합니다. 이 예제에서는 GitHub의 음성 SDK 리포지토리에서 사용할 수 있는
Call1_separated_16k_health_insurance.wav파일을 사용합니다. 파일을 다운로드하거나 사용자 고유의 오디오 파일을 사용할 수 있습니다.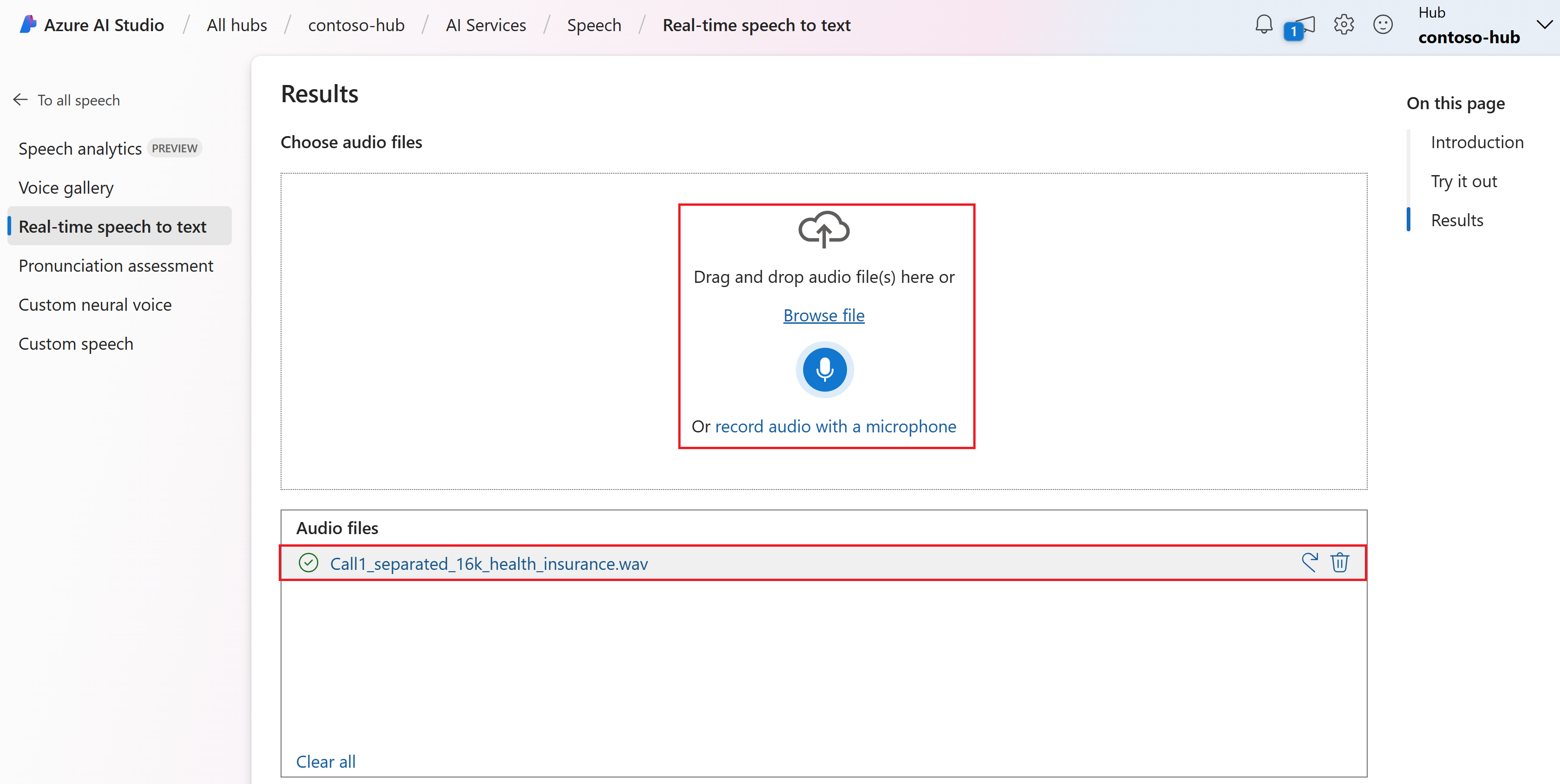
페이지 아래쪽에서 실시간 전사를 볼 수 있습니다.
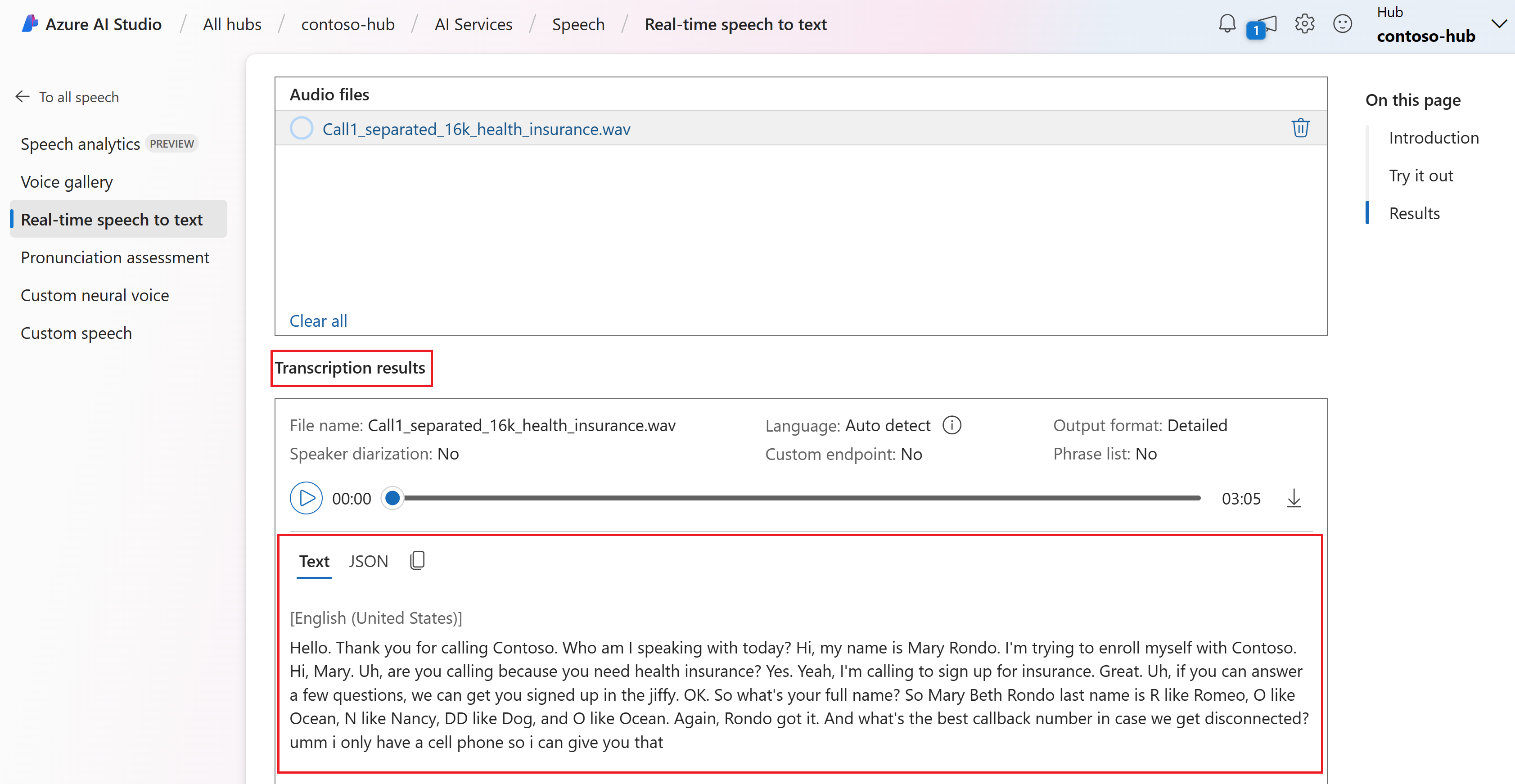
JSON 탭을 선택하여 전사의 JSON 출력을 볼 수 있습니다. 속성에는 ,
Duration,RecognitionStatusDisplay,Lexical등이ITN포함Offset됩니다.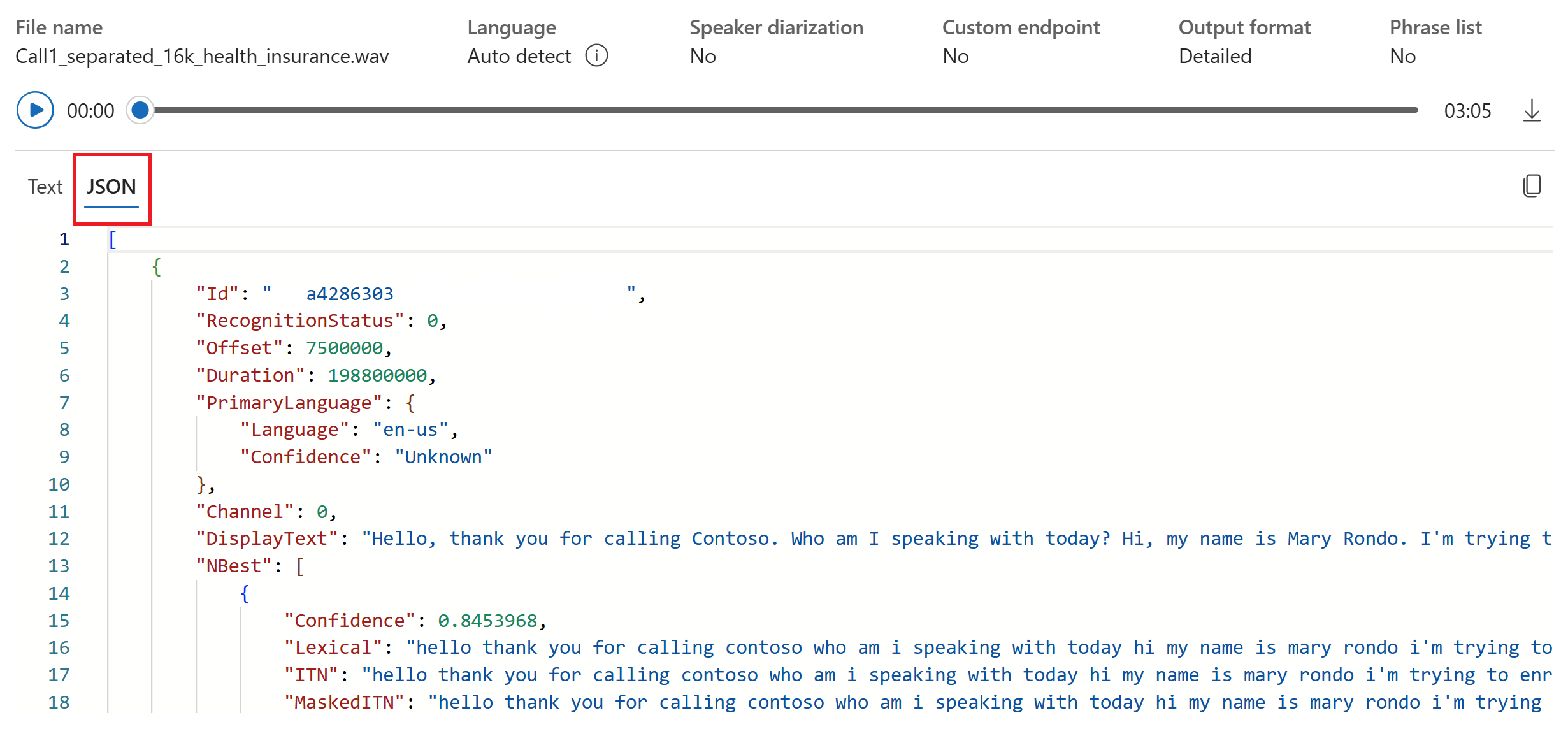





참조 설명서 | 패키지(NuGet) | GitHub의 추가 샘플
이 빠른 시작에서는 실시간으로 음성을 인식하고 텍스트로 전사하는 애플리케이션을 만들고 실행합니다.
대신 오디오 파일을 비동기적으로 전사하려면 일괄 처리 기록이란을 참조하세요. 어떤 음성 텍스트 변환 솔루션이 적합한지 잘 모르는 경우 음성 텍스트 변환이란을 참조하세요.
필수 구성 요소
- Azure 구독 무료로 하나를 만들 수 있습니다.
- Azure Portal에서 음성 리소스를 만듭니다.
- 음성 리소스 키 및 지역을 가져옵니다. 음성 리소스가 배포된 후, 리소스로 이동을 선택하여 키를 보고 관리합니다.
환경 설정
음성 SDK는 NuGet 패키지로 사용할 수 있으며 .NET Standard 2.0을 구현합니다. 이 가이드의 뒷부분에서 음성 SDK를 설치합니다. 모든 요구 사항은 음성 SDK 설치를 참조하세요.
환경 변수 설정
Azure AI 서비스에 액세스하려면 애플리케이션을 인증해야 합니다. 이 문서에서는 환경 변수를 사용하여 자격 증명을 저장하는 방법을 보여 줍니다. 그런 다음, 코드에서 환경 변수에 액세스하여 애플리케이션을 인증할 수 있습니다. 프로덕션의 경우 더 안전한 방법으로 자격 증명을 저장하고 액세스하세요.
Important
클라우드에서 실행되는 애플리케이션에 자격 증명을 저장하지 않으려면 Microsoft Entra ID 인증과 함께 Azure 리소스에 대한 관리 ID를 사용하는 것이 좋습니다.
API 키를 사용하는 경우 Azure Key Vault와 같이 다른 곳에 안전하게 저장합니다. API 키를 코드에 직접 포함하지 말고, 공개적으로 게시하지 마세요.
AI 서비스 보안에 대한 자세한 내용은 Azure AI 서비스에 대한 요청 인증을 참조하세요.
Speech 리소스 키와 지역에 대한 환경 변수를 설정하려면 콘솔 창을 열고 운영 체제 및 개발 환경에 대한 지침을 따릅니다.
-
SPEECH_KEY환경 변수를 설정하려면 your-key를 리소스에 대한 키 중 하나로 바꿉니다. -
SPEECH_REGION환경 변수를 설정하려면 your-region를 리소스에 대한 지역 중 하나로 바꿉니다.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
참고 항목
현재 콘솔에서만 환경 변수에 액세스해야 하는 경우 환경 변수를 setx 대신 set으로 설정할 수 있습니다.
환경 변수를 추가한 후에는 콘솔 창을 포함하여 실행 중인 프로그램 중에서 환경 변수를 읽어야 하는 프로그램을 다시 시작해야 할 수도 있습니다. 예를 들어 편집기로 Visual Studio를 사용하는 경우 Visual Studio를 다시 시작한 후 예제를 실행합니다.
마이크에서 음성 인식
팁
Visual Studio Code에서 샘플을 쉽게 빌드하고 실행하려면 Azure AI Speech Toolkit 을 사용해 보세요.
다음 단계에 따라 콘솔 애플리케이션을 만들고 음성 SDK를 설치합니다.
새 프로젝트가 필요한 폴더에서 명령 프롬프트 창을 엽니다. 이 명령을 실행하여 .NET CLI를 사용하여 콘솔 애플리케이션을 만듭니다.
dotnet new console이 명령은 프로젝트 디렉터리에 Program.cs 파일을 만듭니다.
.NET CLI를 사용하여 새 프로젝트에 음성 SDK를 설치합니다.
dotnet add package Microsoft.CognitiveServices.SpeechProgram.cs의 내용을 다음 코드로 바꿉니다.
using System; using System.IO; using System.Threading.Tasks; using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; class Program { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); static void OutputSpeechRecognitionResult(SpeechRecognitionResult speechRecognitionResult) { switch (speechRecognitionResult.Reason) { case ResultReason.RecognizedSpeech: Console.WriteLine($"RECOGNIZED: Text={speechRecognitionResult.Text}"); break; case ResultReason.NoMatch: Console.WriteLine($"NOMATCH: Speech could not be recognized."); break; case ResultReason.Canceled: var cancellation = CancellationDetails.FromResult(speechRecognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you set the speech resource key and region values?"); } break; } } async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); using var speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); Console.WriteLine("Speak into your microphone."); var speechRecognitionResult = await speechRecognizer.RecognizeOnceAsync(); OutputSpeechRecognitionResult(speechRecognitionResult); } }음성 인식 언어를 변경하려면
en-US를 다른 지원되는 언어로 바꿉니다. 예를 들어 스페인어(스페인)의 경우es-ES를 사용합니다. 값을 지정하지 않으면 기본값이en-US로 설정됩니다. 음성에 사용될 수 있는 여러 언어 중 하나를 식별하는 방법에 대한 자세한 내용은 언어 식별을 참조하세요.새 콘솔 애플리케이션을 실행하여 마이크의 음성 인식을 시작합니다.
dotnet runImportant
SPEECH_KEY및SPEECH_REGION환경 변수를 설정해야 합니다. 이 변수를 설정하지 않으면 샘플이 오류 메시지와 함께 실패합니다.메시지가 표시되면 마이크에 말합니다. 말하는 내용이 텍스트로 출력되어야 합니다.
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
설명
기타 고려 사항은 다음과 같습니다.
이 예제에서는
RecognizeOnceAsync작업을 사용하여 최대 30초의 발화를 기록하거나 침묵이 감지될 때까지 기록합니다. 다국어 대화를 포함한 더 긴 오디오에 대한 지속적인 인식에 대한 자세한 내용은 음성을 인식하는 방법을 참조하세요.오디오 파일에서 음성을 인식하려면
FromDefaultMicrophoneInput대신FromWavFileInput를 사용합니다.using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav");MP4와 같은 압축 오디오 파일의 경우 GStreamer를 설치하고
PullAudioInputStream또는PushAudioInputStream을 사용합니다. 자세한 내용은 압축 입력 오디오 사용 방법을 참조하세요.
리소스 정리
Azure Portal 또는 Azure CLI(명령줄 인터페이스)를 사용하여 생성된 음성 리소스를 제거할 수 있습니다.
참조 설명서 | 패키지(NuGet) | GitHub의 추가 샘플
이 빠른 시작에서는 실시간으로 음성을 인식하고 텍스트로 전사하는 애플리케이션을 만들고 실행합니다.
대신 오디오 파일을 비동기적으로 전사하려면 일괄 처리 기록이란을 참조하세요. 어떤 음성 텍스트 변환 솔루션이 적합한지 잘 모르는 경우 음성 텍스트 변환이란을 참조하세요.
필수 구성 요소
- Azure 구독 무료로 하나를 만들 수 있습니다.
- Azure Portal에서 음성 리소스를 만듭니다.
- 음성 리소스 키 및 지역을 가져옵니다. 음성 리소스가 배포된 후, 리소스로 이동을 선택하여 키를 보고 관리합니다.
환경 설정
음성 SDK는 NuGet 패키지로 사용할 수 있으며 .NET Standard 2.0을 구현합니다. 이 가이드의 뒷부분에서 음성 SDK를 설치합니다. 모든 요구 사항은 음성 SDK 설치를 참조하세요.
환경 변수 설정
Azure AI 서비스에 액세스하려면 애플리케이션을 인증해야 합니다. 이 문서에서는 환경 변수를 사용하여 자격 증명을 저장하는 방법을 보여 줍니다. 그런 다음, 코드에서 환경 변수에 액세스하여 애플리케이션을 인증할 수 있습니다. 프로덕션의 경우 더 안전한 방법으로 자격 증명을 저장하고 액세스하세요.
Important
클라우드에서 실행되는 애플리케이션에 자격 증명을 저장하지 않으려면 Microsoft Entra ID 인증과 함께 Azure 리소스에 대한 관리 ID를 사용하는 것이 좋습니다.
API 키를 사용하는 경우 Azure Key Vault와 같이 다른 곳에 안전하게 저장합니다. API 키를 코드에 직접 포함하지 말고, 공개적으로 게시하지 마세요.
AI 서비스 보안에 대한 자세한 내용은 Azure AI 서비스에 대한 요청 인증을 참조하세요.
Speech 리소스 키와 지역에 대한 환경 변수를 설정하려면 콘솔 창을 열고 운영 체제 및 개발 환경에 대한 지침을 따릅니다.
-
SPEECH_KEY환경 변수를 설정하려면 your-key를 리소스에 대한 키 중 하나로 바꿉니다. -
SPEECH_REGION환경 변수를 설정하려면 your-region를 리소스에 대한 지역 중 하나로 바꿉니다.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
참고 항목
현재 콘솔에서만 환경 변수에 액세스해야 하는 경우 환경 변수를 setx 대신 set으로 설정할 수 있습니다.
환경 변수를 추가한 후에는 콘솔 창을 포함하여 실행 중인 프로그램 중에서 환경 변수를 읽어야 하는 프로그램을 다시 시작해야 할 수도 있습니다. 예를 들어 편집기로 Visual Studio를 사용하는 경우 Visual Studio를 다시 시작한 후 예제를 실행합니다.
마이크에서 음성 인식
팁
Visual Studio Code에서 샘플을 쉽게 빌드하고 실행하려면 Azure AI Speech Toolkit 을 사용해 보세요.
다음 단계에 따라 콘솔 애플리케이션을 만들고 음성 SDK를 설치합니다.
Visual Studio Community에서
SpeechRecognition이라는 새 C++ 콘솔 프로젝트를 만듭니다.도구>NuGet 패키지 관리자>패키지 관리자 콘솔을 선택합니다. 패키지 관리자 콘솔에서 이 명령을 실행합니다.
Install-Package Microsoft.CognitiveServices.SpeechSpeechRecognition.cpp의 내용을 다음 코드로 바꿉니다.#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); if ((size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set both SPEECH_KEY and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto speechRecognizer = SpeechRecognizer::FromConfig(speechConfig, audioConfig); std::cout << "Speak into your microphone.\n"; auto result = speechRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you set the speech resource key and region values?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }음성 인식 언어를 변경하려면
en-US를 다른 지원되는 언어로 바꿉니다. 예를 들어 스페인어(스페인)의 경우es-ES를 사용합니다. 값을 지정하지 않으면 기본값이en-US로 설정됩니다. 음성에 사용될 수 있는 여러 언어 중 하나를 식별하는 방법에 대한 자세한 내용은 언어 식별을 참조하세요.새 콘솔 애플리케이션을 작성하고 실행하여 마이크의 음성 인식을 시작합니다.
Important
SPEECH_KEY및SPEECH_REGION환경 변수를 설정해야 합니다. 이 변수를 설정하지 않으면 샘플이 오류 메시지와 함께 실패합니다.메시지가 표시되면 마이크에 말합니다. 말하는 내용이 텍스트로 출력되어야 합니다.
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
설명
기타 고려 사항은 다음과 같습니다.
이 예제에서는
RecognizeOnceAsync작업을 사용하여 최대 30초의 발화를 기록하거나 침묵이 감지될 때까지 기록합니다. 다국어 대화를 포함한 더 긴 오디오에 대한 지속적인 인식에 대한 자세한 내용은 음성을 인식하는 방법을 참조하세요.오디오 파일에서 음성을 인식하려면
FromDefaultMicrophoneInput대신FromWavFileInput를 사용합니다.auto audioConfig = AudioConfig::FromWavFileInput("YourAudioFile.wav");MP4와 같은 압축 오디오 파일의 경우 GStreamer를 설치하고
PullAudioInputStream또는PushAudioInputStream을 사용합니다. 자세한 내용은 압축 입력 오디오 사용 방법을 참조하세요.
리소스 정리
Azure Portal 또는 Azure CLI(명령줄 인터페이스)를 사용하여 생성된 음성 리소스를 제거할 수 있습니다.
참조 설명서 | 패키지(Go) | GitHub의 추가 샘플
이 빠른 시작에서는 실시간으로 음성을 인식하고 텍스트로 전사하는 애플리케이션을 만들고 실행합니다.
대신 오디오 파일을 비동기적으로 전사하려면 일괄 처리 기록이란을 참조하세요. 어떤 음성 텍스트 변환 솔루션이 적합한지 잘 모르는 경우 음성 텍스트 변환이란을 참조하세요.
필수 구성 요소
- Azure 구독 무료로 하나를 만들 수 있습니다.
- Azure Portal에서 음성 리소스를 만듭니다.
- 음성 리소스 키 및 지역을 가져옵니다. 음성 리소스가 배포된 후, 리소스로 이동을 선택하여 키를 보고 관리합니다.
환경 설정
Go용 Speech SDK를 설치합니다. 요구 사항 및 지침은 음성 SDK 설치를 참조하세요.
환경 변수 설정
Azure AI 서비스에 액세스하려면 애플리케이션을 인증해야 합니다. 이 문서에서는 환경 변수를 사용하여 자격 증명을 저장하는 방법을 보여 줍니다. 그런 다음, 코드에서 환경 변수에 액세스하여 애플리케이션을 인증할 수 있습니다. 프로덕션의 경우 더 안전한 방법으로 자격 증명을 저장하고 액세스하세요.
Important
클라우드에서 실행되는 애플리케이션에 자격 증명을 저장하지 않으려면 Microsoft Entra ID 인증과 함께 Azure 리소스에 대한 관리 ID를 사용하는 것이 좋습니다.
API 키를 사용하는 경우 Azure Key Vault와 같이 다른 곳에 안전하게 저장합니다. API 키를 코드에 직접 포함하지 말고, 공개적으로 게시하지 마세요.
AI 서비스 보안에 대한 자세한 내용은 Azure AI 서비스에 대한 요청 인증을 참조하세요.
Speech 리소스 키와 지역에 대한 환경 변수를 설정하려면 콘솔 창을 열고 운영 체제 및 개발 환경에 대한 지침을 따릅니다.
-
SPEECH_KEY환경 변수를 설정하려면 your-key를 리소스에 대한 키 중 하나로 바꿉니다. -
SPEECH_REGION환경 변수를 설정하려면 your-region를 리소스에 대한 지역 중 하나로 바꿉니다.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
참고 항목
현재 콘솔에서만 환경 변수에 액세스해야 하는 경우 환경 변수를 setx 대신 set으로 설정할 수 있습니다.
환경 변수를 추가한 후에는 콘솔 창을 포함하여 실행 중인 프로그램 중에서 환경 변수를 읽어야 하는 프로그램을 다시 시작해야 할 수도 있습니다. 예를 들어 편집기로 Visual Studio를 사용하는 경우 Visual Studio를 다시 시작한 후 예제를 실행합니다.
마이크에서 음성 인식
새 GO 모듈을 만들려면 다음 단계를 수행합니다.
새 프로젝트를 원하는 폴더에서 명령 프롬프트 창을 엽니다. speech-recognition.go라는 새 파일을 만듭니다.
다음 코드를 speech-recognition.go에 복사합니다.
package main import ( "bufio" "fmt" "os" "github.com/Microsoft/cognitive-services-speech-sdk-go/audio" "github.com/Microsoft/cognitive-services-speech-sdk-go/speech" ) func sessionStartedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Started (ID=", event.SessionID, ")") } func sessionStoppedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Stopped (ID=", event.SessionID, ")") } func recognizingHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognizing:", event.Result.Text) } func recognizedHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognized:", event.Result.Text) } func cancelledHandler(event speech.SpeechRecognitionCanceledEventArgs) { defer event.Close() fmt.Println("Received a cancellation: ", event.ErrorDetails) fmt.Println("Did you set the speech resource key and region values?") } func main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speechKey := os.Getenv("SPEECH_KEY") speechRegion := os.Getenv("SPEECH_REGION") audioConfig, err := audio.NewAudioConfigFromDefaultMicrophoneInput() if err != nil { fmt.Println("Got an error: ", err) return } defer audioConfig.Close() speechConfig, err := speech.NewSpeechConfigFromSubscription(speechKey, speechRegion) if err != nil { fmt.Println("Got an error: ", err) return } defer speechConfig.Close() speechRecognizer, err := speech.NewSpeechRecognizerFromConfig(speechConfig, audioConfig) if err != nil { fmt.Println("Got an error: ", err) return } defer speechRecognizer.Close() speechRecognizer.SessionStarted(sessionStartedHandler) speechRecognizer.SessionStopped(sessionStoppedHandler) speechRecognizer.Recognizing(recognizingHandler) speechRecognizer.Recognized(recognizedHandler) speechRecognizer.Canceled(cancelledHandler) speechRecognizer.StartContinuousRecognitionAsync() defer speechRecognizer.StopContinuousRecognitionAsync() bufio.NewReader(os.Stdin).ReadBytes('\n') }다음 명령을 실행하여 GitHub에서 호스팅되는 구성 요소에 연결되는 go.mod 파일을 만듭니다.
go mod init speech-recognition go get github.com/Microsoft/cognitive-services-speech-sdk-goImportant
SPEECH_KEY및SPEECH_REGION환경 변수를 설정해야 합니다. 이 변수를 설정하지 않으면 샘플이 오류 메시지와 함께 실패합니다.코드 빌드 및 실행:
go build go run speech-recognition
리소스 정리
Azure Portal 또는 Azure CLI(명령줄 인터페이스)를 사용하여 생성된 음성 리소스를 제거할 수 있습니다.
이 빠른 시작에서는 실시간으로 음성을 인식하고 텍스트로 전사하는 애플리케이션을 만들고 실행합니다.
대신 오디오 파일을 비동기적으로 전사하려면 일괄 처리 기록이란을 참조하세요. 어떤 음성 텍스트 변환 솔루션이 적합한지 잘 모르는 경우 음성 텍스트 변환이란을 참조하세요.
필수 구성 요소
- Azure 구독 무료로 하나를 만들 수 있습니다.
- Azure Portal에서 음성 리소스를 만듭니다.
- 음성 리소스 키 및 지역을 가져옵니다. 음성 리소스가 배포된 후, 리소스로 이동을 선택하여 키를 보고 관리합니다.
환경 설정
환경을 설정하려면 Speech SDK를 설치합니다. 이 빠른 시작의 샘플은 Java 런타임에서 작동합니다.
Apache Maven을 설치합니다. 그런 다음
mvn -v을(를) 실행하여 성공적인 설치를 확인합니다.새
pom.xml파일을 프로젝트의 루트에 만들고, 다음 코드를 복사합니다.<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.microsoft.cognitiveservices.speech.samples</groupId> <artifactId>quickstart-eclipse</artifactId> <version>1.0.0-SNAPSHOT</version> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>com.microsoft.cognitiveservices.speech</groupId> <artifactId>client-sdk</artifactId> <version>1.42.0</version> </dependency> </dependencies> </project>Speech SDK 및 종속성을 설치합니다.
mvn clean dependency:copy-dependencies
환경 변수 설정
Azure AI 서비스에 액세스하려면 애플리케이션을 인증해야 합니다. 이 문서에서는 환경 변수를 사용하여 자격 증명을 저장하는 방법을 보여 줍니다. 그런 다음, 코드에서 환경 변수에 액세스하여 애플리케이션을 인증할 수 있습니다. 프로덕션의 경우 더 안전한 방법으로 자격 증명을 저장하고 액세스하세요.
Important
클라우드에서 실행되는 애플리케이션에 자격 증명을 저장하지 않으려면 Microsoft Entra ID 인증과 함께 Azure 리소스에 대한 관리 ID를 사용하는 것이 좋습니다.
API 키를 사용하는 경우 Azure Key Vault와 같이 다른 곳에 안전하게 저장합니다. API 키를 코드에 직접 포함하지 말고, 공개적으로 게시하지 마세요.
AI 서비스 보안에 대한 자세한 내용은 Azure AI 서비스에 대한 요청 인증을 참조하세요.
Speech 리소스 키와 지역에 대한 환경 변수를 설정하려면 콘솔 창을 열고 운영 체제 및 개발 환경에 대한 지침을 따릅니다.
-
SPEECH_KEY환경 변수를 설정하려면 your-key를 리소스에 대한 키 중 하나로 바꿉니다. -
SPEECH_REGION환경 변수를 설정하려면 your-region를 리소스에 대한 지역 중 하나로 바꿉니다.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
참고 항목
현재 콘솔에서만 환경 변수에 액세스해야 하는 경우 환경 변수를 setx 대신 set으로 설정할 수 있습니다.
환경 변수를 추가한 후에는 콘솔 창을 포함하여 실행 중인 프로그램 중에서 환경 변수를 읽어야 하는 프로그램을 다시 시작해야 할 수도 있습니다. 예를 들어 편집기로 Visual Studio를 사용하는 경우 Visual Studio를 다시 시작한 후 예제를 실행합니다.
마이크에서 음성 인식
음성 인식을 위한 새 콘솔 애플리케이션을 만들려면 다음 단계를 수행합니다.
동일한 프로젝트 루트 디렉터리에 SpeechRecognition.java라는 새 파일을 만듭니다.
다음 코드를 SpeechRecognition.java에 복사합니다.
import com.microsoft.cognitiveservices.speech.*; import com.microsoft.cognitiveservices.speech.audio.AudioConfig; import java.util.concurrent.ExecutionException; import java.util.concurrent.Future; public class SpeechRecognition { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" private static String speechKey = System.getenv("SPEECH_KEY"); private static String speechRegion = System.getenv("SPEECH_REGION"); public static void main(String[] args) throws InterruptedException, ExecutionException { SpeechConfig speechConfig = SpeechConfig.fromSubscription(speechKey, speechRegion); speechConfig.setSpeechRecognitionLanguage("en-US"); recognizeFromMicrophone(speechConfig); } public static void recognizeFromMicrophone(SpeechConfig speechConfig) throws InterruptedException, ExecutionException { AudioConfig audioConfig = AudioConfig.fromDefaultMicrophoneInput(); SpeechRecognizer speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); System.out.println("Speak into your microphone."); Future<SpeechRecognitionResult> task = speechRecognizer.recognizeOnceAsync(); SpeechRecognitionResult speechRecognitionResult = task.get(); if (speechRecognitionResult.getReason() == ResultReason.RecognizedSpeech) { System.out.println("RECOGNIZED: Text=" + speechRecognitionResult.getText()); } else if (speechRecognitionResult.getReason() == ResultReason.NoMatch) { System.out.println("NOMATCH: Speech could not be recognized."); } else if (speechRecognitionResult.getReason() == ResultReason.Canceled) { CancellationDetails cancellation = CancellationDetails.fromResult(speechRecognitionResult); System.out.println("CANCELED: Reason=" + cancellation.getReason()); if (cancellation.getReason() == CancellationReason.Error) { System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode()); System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails()); System.out.println("CANCELED: Did you set the speech resource key and region values?"); } } System.exit(0); } }음성 인식 언어를 변경하려면
en-US를 다른 지원되는 언어로 바꿉니다. 예를 들어 스페인어(스페인)의 경우es-ES를 사용합니다. 값을 지정하지 않으면 기본값이en-US로 설정됩니다. 음성에 사용될 수 있는 여러 언어 중 하나를 식별하는 방법에 대한 자세한 내용은 언어 식별을 참조하세요.새 콘솔 애플리케이션을 실행하여 마이크의 음성 인식을 시작합니다.
javac SpeechRecognition.java -cp ".;target\dependency\*" java -cp ".;target\dependency\*" SpeechRecognitionImportant
SPEECH_KEY및SPEECH_REGION환경 변수를 설정해야 합니다. 이 변수를 설정하지 않으면 샘플이 오류 메시지와 함께 실패합니다.메시지가 표시되면 마이크에 말합니다. 말하는 내용이 텍스트로 출력되어야 합니다.
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
설명
기타 고려 사항은 다음과 같습니다.
이 예제에서는
RecognizeOnceAsync작업을 사용하여 최대 30초의 발화를 기록하거나 침묵이 감지될 때까지 기록합니다. 다국어 대화를 포함한 더 긴 오디오에 대한 지속적인 인식에 대한 자세한 내용은 음성을 인식하는 방법을 참조하세요.오디오 파일에서 음성을 인식하려면
fromDefaultMicrophoneInput대신fromWavFileInput를 사용합니다.AudioConfig audioConfig = AudioConfig.fromWavFileInput("YourAudioFile.wav");MP4와 같은 압축 오디오 파일의 경우 GStreamer를 설치하고
PullAudioInputStream또는PushAudioInputStream을 사용합니다. 자세한 내용은 압축 입력 오디오 사용 방법을 참조하세요.
리소스 정리
Azure Portal 또는 Azure CLI(명령줄 인터페이스)를 사용하여 생성된 음성 리소스를 제거할 수 있습니다.
참조 설명서 | 패키지(npm) | GitHub의 추가 샘플 | 라이브러리 소스 코드
이 빠른 시작에서는 실시간으로 음성을 인식하고 텍스트로 전사하는 애플리케이션을 만들고 실행합니다.
대신 오디오 파일을 비동기적으로 전사하려면 일괄 처리 기록이란을 참조하세요. 어떤 음성 텍스트 변환 솔루션이 적합한지 잘 모르는 경우 음성 텍스트 변환이란을 참조하세요.
필수 구성 요소
- Azure 구독 무료로 하나를 만들 수 있습니다.
- Azure Portal에서 음성 리소스를 만듭니다.
- 음성 리소스 키 및 지역을 가져옵니다. 음성 리소스가 배포된 후, 리소스로 이동을 선택하여 키를 보고 관리합니다.
로컬 컴퓨터에 .wav 오디오 파일도 필요합니다. 고유한 .wav 파일(최대 30초)을 사용하거나 https://crbn.us/whatstheweatherlike.wav 샘플 파일을 다운로드할 수 있습니다.
환경 설정
환경을 설정하려면 JavaScript용 Speech SDK를 설치합니다.
npm install microsoft-cognitiveservices-speech-sdk 명령을 실행합니다. 단계별 설치 지침은 음성 SDK 설치를 참조하세요.
환경 변수 설정
Azure AI 서비스에 액세스하려면 애플리케이션을 인증해야 합니다. 이 문서에서는 환경 변수를 사용하여 자격 증명을 저장하는 방법을 보여 줍니다. 그런 다음, 코드에서 환경 변수에 액세스하여 애플리케이션을 인증할 수 있습니다. 프로덕션의 경우 더 안전한 방법으로 자격 증명을 저장하고 액세스하세요.
Important
클라우드에서 실행되는 애플리케이션에 자격 증명을 저장하지 않으려면 Microsoft Entra ID 인증과 함께 Azure 리소스에 대한 관리 ID를 사용하는 것이 좋습니다.
API 키를 사용하는 경우 Azure Key Vault와 같이 다른 곳에 안전하게 저장합니다. API 키를 코드에 직접 포함하지 말고, 공개적으로 게시하지 마세요.
AI 서비스 보안에 대한 자세한 내용은 Azure AI 서비스에 대한 요청 인증을 참조하세요.
Speech 리소스 키와 지역에 대한 환경 변수를 설정하려면 콘솔 창을 열고 운영 체제 및 개발 환경에 대한 지침을 따릅니다.
-
SPEECH_KEY환경 변수를 설정하려면 your-key를 리소스에 대한 키 중 하나로 바꿉니다. -
SPEECH_REGION환경 변수를 설정하려면 your-region를 리소스에 대한 지역 중 하나로 바꿉니다.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
참고 항목
현재 콘솔에서만 환경 변수에 액세스해야 하는 경우 환경 변수를 setx 대신 set으로 설정할 수 있습니다.
환경 변수를 추가한 후에는 콘솔 창을 포함하여 실행 중인 프로그램 중에서 환경 변수를 읽어야 하는 프로그램을 다시 시작해야 할 수도 있습니다. 예를 들어 편집기로 Visual Studio를 사용하는 경우 Visual Studio를 다시 시작한 후 예제를 실행합니다.
파일에서 음성 인식
팁
Visual Studio Code에서 샘플을 쉽게 빌드하고 실행하려면 Azure AI Speech Toolkit 을 사용해 보세요.
음성 인식을 위한 Node.js 콘솔 애플리케이션을 만들려면 다음 단계를 수행합니다.
새 프로젝트를 원하는 명령 프롬프트 창을 열고 SpeechRecognition.js라는 새 파일을 만듭니다.
JavaScript용 Speech SDK를 설치합니다.
npm install microsoft-cognitiveservices-speech-sdk다음 코드를 SpeechRecognition.js에 복사합니다.
const fs = require("fs"); const sdk = require("microsoft-cognitiveservices-speech-sdk"); // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" const speechConfig = sdk.SpeechConfig.fromSubscription(process.env.SPEECH_KEY, process.env.SPEECH_REGION); speechConfig.speechRecognitionLanguage = "en-US"; function fromFile() { let audioConfig = sdk.AudioConfig.fromWavFileInput(fs.readFileSync("YourAudioFile.wav")); let speechRecognizer = new sdk.SpeechRecognizer(speechConfig, audioConfig); speechRecognizer.recognizeOnceAsync(result => { switch (result.reason) { case sdk.ResultReason.RecognizedSpeech: console.log(`RECOGNIZED: Text=${result.text}`); break; case sdk.ResultReason.NoMatch: console.log("NOMATCH: Speech could not be recognized."); break; case sdk.ResultReason.Canceled: const cancellation = sdk.CancellationDetails.fromResult(result); console.log(`CANCELED: Reason=${cancellation.reason}`); if (cancellation.reason == sdk.CancellationReason.Error) { console.log(`CANCELED: ErrorCode=${cancellation.ErrorCode}`); console.log(`CANCELED: ErrorDetails=${cancellation.errorDetails}`); console.log("CANCELED: Did you set the speech resource key and region values?"); } break; } speechRecognizer.close(); }); } fromFile();SpeechRecognition.js에서 YourAudioFile.wav를 고유한 .wav 파일로 대체합니다. 이 예제에서는 .wav 파일의 음성만 인식합니다. 다른 오디오 형식에 대한 자세한 내용은 압축 입력 오디오 사용 방법을 참조하세요. 이 예제에서는 최대 30초 오디오를 지원합니다.
음성 인식 언어를 변경하려면
en-US를 다른 지원되는 언어로 바꿉니다. 예를 들어 스페인어(스페인)의 경우es-ES를 사용합니다. 값을 지정하지 않으면 기본값이en-US로 설정됩니다. 음성에 사용될 수 있는 여러 언어 중 하나를 식별하는 방법에 대한 자세한 내용은 언어 식별을 참조하세요.새 콘솔 애플리케이션을 실행하여 파일의 음성 인식을 시작합니다.
node.exe SpeechRecognition.jsImportant
SPEECH_KEY및SPEECH_REGION환경 변수를 설정해야 합니다. 이 변수를 설정하지 않으면 샘플이 오류 메시지와 함께 실패합니다.오디오 파일의 음성이 텍스트로 출력되어야 합니다.
RECOGNIZED: Text=I'm excited to try speech to text.
설명
이 예제에서는 recognizeOnceAsync 작업을 사용하여 최대 30초의 발화를 기록하거나 침묵이 감지될 때까지 기록합니다. 다국어 대화를 포함한 더 긴 오디오에 대한 지속적인 인식에 대한 자세한 내용은 음성을 인식하는 방법을 참조하세요.
참고 항목
마이크의 음성 인식은 Node.js에서 지원되지 않습니다. 이는 브라우저 기반 JavaScript 환경에서만 지원됩니다. 자세한 내용은 GitHub의 React 샘플 및 마이크의 음성 텍스트 변환 구현을 참조하세요.
React 샘플은 인증 토큰의 교환 및 관리를 위한 디자인 패턴을 보여줍니다. 또한 음성 텍스트 변환을 위해 마이크 또는 파일에서 오디오 캡처를 보여줍니다.
리소스 정리
Azure Portal 또는 Azure CLI(명령줄 인터페이스)를 사용하여 생성된 음성 리소스를 제거할 수 있습니다.
참조 설명서 | 패키지(PyPi) | GitHub의 추가 샘플
이 빠른 시작에서는 실시간으로 음성을 인식하고 텍스트로 전사하는 애플리케이션을 만들고 실행합니다.
대신 오디오 파일을 비동기적으로 전사하려면 일괄 처리 기록이란을 참조하세요. 어떤 음성 텍스트 변환 솔루션이 적합한지 잘 모르는 경우 음성 텍스트 변환이란을 참조하세요.
필수 구성 요소
- Azure 구독 무료로 하나를 만들 수 있습니다.
- Azure Portal에서 음성 리소스를 만듭니다.
- 음성 리소스 키 및 지역을 가져옵니다. 음성 리소스가 배포된 후, 리소스로 이동을 선택하여 키를 보고 관리합니다.
환경 설정
Python용 Speech SDK는 PyPI(Python Package Index) 모듈로 사용할 수 있습니다. Python용 Speech SDK는 Windows, Linux 및 macOS와 호환됩니다.
- Windows의 경우 플랫폼에 맞는 Microsoft Visual Studio용 Visual C++ 재배포 가능 패키지 2015, 2017, 2019, 2022를 설치해야 합니다. 이 패키지를 처음 설치하려면 다시 시작해야 할 수 있습니다.
- Linux에서는 x64 대상 아키텍처를 사용해야 합니다.
Python 3.7 이상 버전을 설치합니다. 모든 요구 사항은 음성 SDK 설치를 참조하세요.
환경 변수 설정
Azure AI 서비스에 액세스하려면 애플리케이션을 인증해야 합니다. 이 문서에서는 환경 변수를 사용하여 자격 증명을 저장하는 방법을 보여 줍니다. 그런 다음, 코드에서 환경 변수에 액세스하여 애플리케이션을 인증할 수 있습니다. 프로덕션의 경우 더 안전한 방법으로 자격 증명을 저장하고 액세스하세요.
Important
클라우드에서 실행되는 애플리케이션에 자격 증명을 저장하지 않으려면 Microsoft Entra ID 인증과 함께 Azure 리소스에 대한 관리 ID를 사용하는 것이 좋습니다.
API 키를 사용하는 경우 Azure Key Vault와 같이 다른 곳에 안전하게 저장합니다. API 키를 코드에 직접 포함하지 말고, 공개적으로 게시하지 마세요.
AI 서비스 보안에 대한 자세한 내용은 Azure AI 서비스에 대한 요청 인증을 참조하세요.
Speech 리소스 키와 지역에 대한 환경 변수를 설정하려면 콘솔 창을 열고 운영 체제 및 개발 환경에 대한 지침을 따릅니다.
-
SPEECH_KEY환경 변수를 설정하려면 your-key를 리소스에 대한 키 중 하나로 바꿉니다. -
SPEECH_REGION환경 변수를 설정하려면 your-region를 리소스에 대한 지역 중 하나로 바꿉니다.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
참고 항목
현재 콘솔에서만 환경 변수에 액세스해야 하는 경우 환경 변수를 setx 대신 set으로 설정할 수 있습니다.
환경 변수를 추가한 후에는 콘솔 창을 포함하여 실행 중인 프로그램 중에서 환경 변수를 읽어야 하는 프로그램을 다시 시작해야 할 수도 있습니다. 예를 들어 편집기로 Visual Studio를 사용하는 경우 Visual Studio를 다시 시작한 후 예제를 실행합니다.
마이크에서 음성 인식
팁
Visual Studio Code에서 샘플을 쉽게 빌드하고 실행하려면 Azure AI Speech Toolkit 을 사용해 보세요.
콘솔 애플리케이션을 만들려면 다음 단계를 수행합니다.
새 프로젝트를 원하는 폴더에서 명령 프롬프트 창을 엽니다. speech_recognition.py라는 새 파일을 만듭니다.
다음 명령을 실행하여 Speech SDK를 설치합니다.
pip install azure-cognitiveservices-speech다음 코드를 speech_recognition.py에 복사합니다.
import os import azure.cognitiveservices.speech as speechsdk def recognize_from_microphone(): # This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('SPEECH_KEY'), region=os.environ.get('SPEECH_REGION')) speech_config.speech_recognition_language="en-US" audio_config = speechsdk.audio.AudioConfig(use_default_microphone=True) speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config) print("Speak into your microphone.") speech_recognition_result = speech_recognizer.recognize_once_async().get() if speech_recognition_result.reason == speechsdk.ResultReason.RecognizedSpeech: print("Recognized: {}".format(speech_recognition_result.text)) elif speech_recognition_result.reason == speechsdk.ResultReason.NoMatch: print("No speech could be recognized: {}".format(speech_recognition_result.no_match_details)) elif speech_recognition_result.reason == speechsdk.ResultReason.Canceled: cancellation_details = speech_recognition_result.cancellation_details print("Speech Recognition canceled: {}".format(cancellation_details.reason)) if cancellation_details.reason == speechsdk.CancellationReason.Error: print("Error details: {}".format(cancellation_details.error_details)) print("Did you set the speech resource key and region values?") recognize_from_microphone()음성 인식 언어를 변경하려면
en-US를 다른 지원되는 언어로 바꿉니다. 예를 들어 스페인어(스페인)의 경우es-ES를 사용합니다. 값을 지정하지 않으면 기본값이en-US로 설정됩니다. 음성에 사용될 수 있는 여러 언어 중 하나를 식별하는 방법에 대한 자세한 내용은 언어 식별을 참조하세요.새 콘솔 애플리케이션을 실행하여 마이크의 음성 인식을 시작합니다.
python speech_recognition.pyImportant
SPEECH_KEY및SPEECH_REGION환경 변수를 설정해야 합니다. 이 변수를 설정하지 않으면 샘플이 오류 메시지와 함께 실패합니다.메시지가 표시되면 마이크에 말합니다. 말하는 내용이 텍스트로 출력되어야 합니다.
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
설명
기타 고려 사항은 다음과 같습니다.
이 예제에서는
recognize_once_async작업을 사용하여 최대 30초의 발화를 기록하거나 침묵이 감지될 때까지 기록합니다. 다국어 대화를 포함한 더 긴 오디오에 대한 지속적인 인식에 대한 자세한 내용은 음성을 인식하는 방법을 참조하세요.오디오 파일에서 음성을 인식하려면
use_default_microphone대신filename를 사용합니다.audio_config = speechsdk.audio.AudioConfig(filename="YourAudioFile.wav")MP4와 같은 압축 오디오 파일의 경우 GStreamer를 설치하고
PullAudioInputStream또는PushAudioInputStream을 사용합니다. 자세한 내용은 압축 입력 오디오 사용 방법을 참조하세요.
리소스 정리
Azure Portal 또는 Azure CLI(명령줄 인터페이스)를 사용하여 생성된 음성 리소스를 제거할 수 있습니다.
참조 설명서 | 패키지(다운로드) | GitHub의 추가 샘플
이 빠른 시작에서는 실시간으로 음성을 인식하고 텍스트로 전사하는 애플리케이션을 만들고 실행합니다.
대신 오디오 파일을 비동기적으로 전사하려면 일괄 처리 기록이란을 참조하세요. 어떤 음성 텍스트 변환 솔루션이 적합한지 잘 모르는 경우 음성 텍스트 변환이란을 참조하세요.
필수 구성 요소
- Azure 구독 무료로 하나를 만들 수 있습니다.
- Azure Portal에서 음성 리소스를 만듭니다.
- 음성 리소스 키 및 지역을 가져옵니다. 음성 리소스가 배포된 후, 리소스로 이동을 선택하여 키를 보고 관리합니다.
환경 설정
Swift용 Speech SDK는 프레임워크 번들로 배포됩니다. 프레임워크는 iOS와 macOS 모두에서 Objective-C 및 Swift를 모두 지원합니다.
이 음성 SDK는 Xcode 프로젝트에서 CocoaPod로 사용하거나, 직접 다운로드하고 수동으로 연결할 수 있습니다. 이 가이드에서는 CocoaPod를 사용합니다. 해당 설치 지침에 설명된 대로 CocoaPod 종속성 관리자를 설치합니다.
환경 변수 설정
Azure AI 서비스에 액세스하려면 애플리케이션을 인증해야 합니다. 이 문서에서는 환경 변수를 사용하여 자격 증명을 저장하는 방법을 보여 줍니다. 그런 다음, 코드에서 환경 변수에 액세스하여 애플리케이션을 인증할 수 있습니다. 프로덕션의 경우 더 안전한 방법으로 자격 증명을 저장하고 액세스하세요.
Important
클라우드에서 실행되는 애플리케이션에 자격 증명을 저장하지 않으려면 Microsoft Entra ID 인증과 함께 Azure 리소스에 대한 관리 ID를 사용하는 것이 좋습니다.
API 키를 사용하는 경우 Azure Key Vault와 같이 다른 곳에 안전하게 저장합니다. API 키를 코드에 직접 포함하지 말고, 공개적으로 게시하지 마세요.
AI 서비스 보안에 대한 자세한 내용은 Azure AI 서비스에 대한 요청 인증을 참조하세요.
Speech 리소스 키와 지역에 대한 환경 변수를 설정하려면 콘솔 창을 열고 운영 체제 및 개발 환경에 대한 지침을 따릅니다.
-
SPEECH_KEY환경 변수를 설정하려면 your-key를 리소스에 대한 키 중 하나로 바꿉니다. -
SPEECH_REGION환경 변수를 설정하려면 your-region를 리소스에 대한 지역 중 하나로 바꿉니다.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
참고 항목
현재 콘솔에서만 환경 변수에 액세스해야 하는 경우 환경 변수를 setx 대신 set으로 설정할 수 있습니다.
환경 변수를 추가한 후에는 콘솔 창을 포함하여 실행 중인 프로그램 중에서 환경 변수를 읽어야 하는 프로그램을 다시 시작해야 할 수도 있습니다. 예를 들어 편집기로 Visual Studio를 사용하는 경우 Visual Studio를 다시 시작한 후 예제를 실행합니다.
마이크에서 음성 인식
macOS 애플리케이션에서 음성을 인식하려면 다음 단계를 수행합니다.
Azure-Samples/cognitive-services-speech-sdk 리포지토리를 복제하여 macOS의 Swift에서 마이크의 음성 인식 샘플 프로젝트를 가져옵니다. 리포지토리에는 iOS 샘플도 있습니다.
터미널에서 다운로드한 샘플 앱(
helloworld)의 디렉터리로 이동합니다.pod install명령을 실행합니다. 이 명령은 샘플 앱 및 음성 SDK를 종속성으로 모두 포함하는helloworld.xcworkspaceXcode 작업 영역을 생성합니다.XCode에서
helloworld.xcworkspace작업 영역을 엽니다.여기에 표시된 대로 AppDelegate.swift라는 파일을 열고
applicationDidFinishLaunching및recognizeFromMic메서드를 찾습니다.import Cocoa @NSApplicationMain class AppDelegate: NSObject, NSApplicationDelegate { var label: NSTextField! var fromMicButton: NSButton! var sub: String! var region: String! @IBOutlet weak var window: NSWindow! func applicationDidFinishLaunching(_ aNotification: Notification) { print("loading") // load subscription information sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"] label = NSTextField(frame: NSRect(x: 100, y: 50, width: 200, height: 200)) label.textColor = NSColor.black label.lineBreakMode = .byWordWrapping label.stringValue = "Recognition Result" label.isEditable = false self.window.contentView?.addSubview(label) fromMicButton = NSButton(frame: NSRect(x: 100, y: 300, width: 200, height: 30)) fromMicButton.title = "Recognize" fromMicButton.target = self fromMicButton.action = #selector(fromMicButtonClicked) self.window.contentView?.addSubview(fromMicButton) } @objc func fromMicButtonClicked() { DispatchQueue.global(qos: .userInitiated).async { self.recognizeFromMic() } } func recognizeFromMic() { var speechConfig: SPXSpeechConfiguration? do { try speechConfig = SPXSpeechConfiguration(subscription: sub, region: region) } catch { print("error \(error) happened") speechConfig = nil } speechConfig?.speechRecognitionLanguage = "en-US" let audioConfig = SPXAudioConfiguration() let reco = try! SPXSpeechRecognizer(speechConfiguration: speechConfig!, audioConfiguration: audioConfig) reco.addRecognizingEventHandler() {reco, evt in print("intermediate recognition result: \(evt.result.text ?? "(no result)")") self.updateLabel(text: evt.result.text, color: .gray) } updateLabel(text: "Listening ...", color: .gray) print("Listening...") let result = try! reco.recognizeOnce() print("recognition result: \(result.text ?? "(no result)"), reason: \(result.reason.rawValue)") updateLabel(text: result.text, color: .black) if result.reason != SPXResultReason.recognizedSpeech { let cancellationDetails = try! SPXCancellationDetails(fromCanceledRecognitionResult: result) print("cancelled: \(result.reason), \(cancellationDetails.errorDetails)") print("Did you set the speech resource key and region values?") updateLabel(text: "Error: \(cancellationDetails.errorDetails)", color: .red) } } func updateLabel(text: String?, color: NSColor) { DispatchQueue.main.async { self.label.stringValue = text! self.label.textColor = color } } }AppDelegate.m에서 음성 리소스 키 및 지역에 대해 이전에 설정한 환경 변수를 사용합니다.
sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"]음성 인식 언어를 변경하려면
en-US를 다른 지원되는 언어로 바꿉니다. 예를 들어 스페인어(스페인)의 경우es-ES를 사용합니다. 값을 지정하지 않으면 기본값이en-US로 설정됩니다. 음성에 사용될 수 있는 여러 언어 중 하나를 식별하는 방법에 대한 자세한 내용은 언어 식별을 참조하세요.디버그 출력을 표시하려면 보기>디버그 영역>콘솔 활성화를 선택합니다.
메뉴에서 제품>실행을 선택하거나 재생 단추를 선택하여 예제 코드를 빌드하고 실행합니다.
Important
SPEECH_KEY및SPEECH_REGION환경 변수를 설정해야 합니다. 이 변수를 설정하지 않으면 샘플이 오류 메시지와 함께 실패합니다.
앱에서 이 단추를 선택하고 몇 단어를 말하면 화면 아래쪽 부분에 사용자가 말한 텍스트가 표시되어야 합니다. 처음으로 앱을 실행하는 경우 컴퓨터 마이크에 대한 앱 액세스 권한을 부여하라는 메시지가 표시됩니다.
설명
이 예제에서는 recognizeOnce 작업을 사용하여 최대 30초의 발화를 기록하거나 침묵이 감지될 때까지 기록합니다. 다국어 대화를 포함한 더 긴 오디오에 대한 지속적인 인식에 대한 자세한 내용은 음성을 인식하는 방법을 참조하세요.
Objective-C
Objective-C용 음성 SDK는 Swift용 음성 SDK와 클라이언트 라이브러리 및 참조 설명서를 공유합니다. Objective-C 코드 예제는 GitHub에서 macOS의 Objective-C에서 마이크의 음성 인식 샘플 프로젝트를 참조하세요.
리소스 정리
Azure Portal 또는 Azure CLI(명령줄 인터페이스)를 사용하여 생성된 음성 리소스를 제거할 수 있습니다.
음성 텍스트 변환 REST API 참조 | 짧은 오디오 참조를 위한 음성 텍스트 변환 REST API | GitHub의 추가 샘플
이 빠른 시작에서는 실시간으로 음성을 인식하고 텍스트로 전사하는 애플리케이션을 만들고 실행합니다.
대신 오디오 파일을 비동기적으로 전사하려면 일괄 처리 기록이란을 참조하세요. 어떤 음성 텍스트 변환 솔루션이 적합한지 잘 모르는 경우 음성 텍스트 변환이란을 참조하세요.
필수 구성 요소
- Azure 구독 무료로 하나를 만들 수 있습니다.
- Azure Portal에서 음성 리소스를 만듭니다.
- 음성 리소스 키 및 지역을 가져옵니다. 음성 리소스가 배포된 후, 리소스로 이동을 선택하여 키를 보고 관리합니다.
로컬 컴퓨터에 .wav 오디오 파일도 필요합니다. 고유한 .wav 파일(최대 60초)을 사용하거나 https://crbn.us/whatstheweatherlike.wav 샘플 파일을 다운로드할 수 있습니다.
환경 변수 설정
Azure AI 서비스에 액세스하려면 애플리케이션을 인증해야 합니다. 이 문서에서는 환경 변수를 사용하여 자격 증명을 저장하는 방법을 보여 줍니다. 그런 다음, 코드에서 환경 변수에 액세스하여 애플리케이션을 인증할 수 있습니다. 프로덕션의 경우 더 안전한 방법으로 자격 증명을 저장하고 액세스하세요.
Important
클라우드에서 실행되는 애플리케이션에 자격 증명을 저장하지 않으려면 Microsoft Entra ID 인증과 함께 Azure 리소스에 대한 관리 ID를 사용하는 것이 좋습니다.
API 키를 사용하는 경우 Azure Key Vault와 같이 다른 곳에 안전하게 저장합니다. API 키를 코드에 직접 포함하지 말고, 공개적으로 게시하지 마세요.
AI 서비스 보안에 대한 자세한 내용은 Azure AI 서비스에 대한 요청 인증을 참조하세요.
Speech 리소스 키와 지역에 대한 환경 변수를 설정하려면 콘솔 창을 열고 운영 체제 및 개발 환경에 대한 지침을 따릅니다.
-
SPEECH_KEY환경 변수를 설정하려면 your-key를 리소스에 대한 키 중 하나로 바꿉니다. -
SPEECH_REGION환경 변수를 설정하려면 your-region를 리소스에 대한 지역 중 하나로 바꿉니다.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
참고 항목
현재 콘솔에서만 환경 변수에 액세스해야 하는 경우 환경 변수를 setx 대신 set으로 설정할 수 있습니다.
환경 변수를 추가한 후에는 콘솔 창을 포함하여 실행 중인 프로그램 중에서 환경 변수를 읽어야 하는 프로그램을 다시 시작해야 할 수도 있습니다. 예를 들어 편집기로 Visual Studio를 사용하는 경우 Visual Studio를 다시 시작한 후 예제를 실행합니다.
파일에서 음성 인식
콘솔 창을 열고 다음 cURL 명령을 실행합니다. YourAudioFile.wav를 오디오 파일의 경로와 이름으로 바꿉니다.
curl --location --request POST "https://%SPEECH_REGION%.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?language=en-US&format=detailed" ^
--header "Ocp-Apim-Subscription-Key: %SPEECH_KEY%" ^
--header "Content-Type: audio/wav" ^
--data-binary "@YourAudioFile.wav"
Important
SPEECH_KEY 및 SPEECH_REGION환경 변수를 설정해야 합니다. 이 변수를 설정하지 않으면 샘플이 오류 메시지와 함께 실패합니다.
여기에 표시된 것과 유사한 응답이 수신되어야 합니다.
DisplayText는 오디오 파일에서 인식된 텍스트여야 합니다. 명령은 최대 60초의 오디오를 인식하고 텍스트로 변환합니다.
{
"RecognitionStatus": "Success",
"DisplayText": "My voice is my passport, verify me.",
"Offset": 6600000,
"Duration": 32100000
}
자세한 내용은 짧은 오디오를 위한 음성 텍스트 변환 REST API를 참조하세요.
리소스 정리
Azure Portal 또는 Azure CLI(명령줄 인터페이스)를 사용하여 생성된 음성 리소스를 제거할 수 있습니다.
이 빠른 시작에서는 실시간으로 음성을 인식하고 텍스트로 전사하는 애플리케이션을 만들고 실행합니다.
대신 오디오 파일을 비동기적으로 전사하려면 일괄 처리 기록이란을 참조하세요. 어떤 음성 텍스트 변환 솔루션이 적합한지 잘 모르는 경우 음성 텍스트 변환이란을 참조하세요.
필수 구성 요소
- Azure 구독 무료로 하나를 만들 수 있습니다.
- Azure Portal에서 음성 리소스를 만듭니다.
- 음성 리소스 키 및 지역을 가져옵니다. 음성 리소스가 배포된 후, 리소스로 이동을 선택하여 키를 보고 관리합니다.
환경 설정
다음 단계를 수행합니다. 플랫폼에 대한 추가 요구 사항은 음성 CLI 빠른 시작을 참조하세요.
다음 .NET CLI 명령을 실행하여 음성 CLI를 설치합니다.
dotnet tool install --global Microsoft.CognitiveServices.Speech.CLI다음 명령을 실행하여 음성 리소스 키 및 지역을 구성합니다.
SUBSCRIPTION-KEY를 음성 리소스 키로 바꾸고,REGION을 음성 리소스 지역으로 바꿉니다.spx config @key --set SUBSCRIPTION-KEY spx config @region --set REGION
마이크에서 음성 인식
다음 명령을 실행하여 마이크에서 음성 인식을 시작합니다.
spx recognize --microphone --source en-US마이크에 대고 말하면 실시간으로 단어를 텍스트로 전사하는 것을 볼 수 있습니다. 음성 CLI는 일정 시간(30초) 동안 침묵 후 또는 Ctrl+C를 누를 때 중지됩니다.
Connection CONNECTED... RECOGNIZED: I'm excited to try speech to text.
설명
기타 고려 사항은 다음과 같습니다.
오디오 파일에서 음성을 인식하려면
--microphone대신--file을 사용합니다. MP4와 같은 압축 오디오 파일의 경우 GStreamer를 설치하고--format을 사용합니다. 자세한 내용은 압축 입력 오디오 사용 방법을 참조하세요.spx recognize --file YourAudioFile.wav spx recognize --file YourAudioFile.mp4 --format any특정 단어 또는 발화의 인식 정확도를 높이려면 구 목록을 사용합니다.
recognize명령과 함께 인라인으로 또는 텍스트 파일을 사용해서 구 목록을 포함할 수 있습니다.spx recognize --microphone --phrases "Contoso;Jessie;Rehaan;" spx recognize --microphone --phrases @phrases.txt음성 인식 언어를 변경하려면
en-US를 다른 지원되는 언어로 바꿉니다. 예를 들어 스페인어(스페인)의 경우es-ES를 사용합니다. 값을 지정하지 않으면 기본값이en-US로 설정됩니다.spx recognize --microphone --source es-ES30초보다 긴 오디오를 지속적으로 인식하려면
--continuous를 추가합니다.spx recognize --microphone --source es-ES --continuous파일 입력 및 출력과 같은 추가 음성 인식 옵션에 대한 정보를 보려면 이 명령을 실행합니다.
spx help recognize
리소스 정리
Azure Portal 또는 Azure CLI(명령줄 인터페이스)를 사용하여 생성된 음성 리소스를 제거할 수 있습니다.