Custom Speech 모델의 인식 품질 테스트
Speech Studio에서 Custom Speech 모델의 인식 품질을 검사할 수 있습니다. 업로드된 오디오를 재생하여 제공된 인식 결과가 올바른지 확인할 수 있습니다. 테스트가 성공적으로 생성되면 모델이 오디오 데이터 세트를 어떻게 전사했는지 확인하거나 두 모델의 결과를 나란히 비교할 수 있습니다.
병렬 모델 테스트는 애플리케이션에 가장 적합한 음성 인식 모델의 유효성을 검사하는 데 유용합니다. 대화 기록 데이터 세트 입력이 필요한 정확도의 객관적인 측정값은 정량적으로 모델 테스트를 참조하세요.
Important
테스트할 때 시스템에서 기록을 수행합니다. 서비스 제공 및 구독 수준에 따라 가격이 달라지기 때문에 이 점을 염두에 두어야 합니다. 항상 공식 Azure AI 서비스 가격에서 최신 세부 정보를 참조하세요.
테스트 만들기
지침에 따라 테스트를 만듭니다.
Speech Studio에 로그인합니다.
Speech Studio>Custom speech로 이동하여 목록에서 프로젝트 이름을 선택합니다.
테스트 모델>새 테스트 만들기를 선택합니다.
품질 검사(오디오 전용 데이터)>다음을 선택합니다.
테스트에 사용할 오디오 데이터 세트를 선택하고 다음을 선택합니다. 사용 가능한 데이터 세트가 없으면 설정을 취소한 다음 음성 데이터 세트 메뉴로 이동하여 데이터 세트를 업로드합니다.
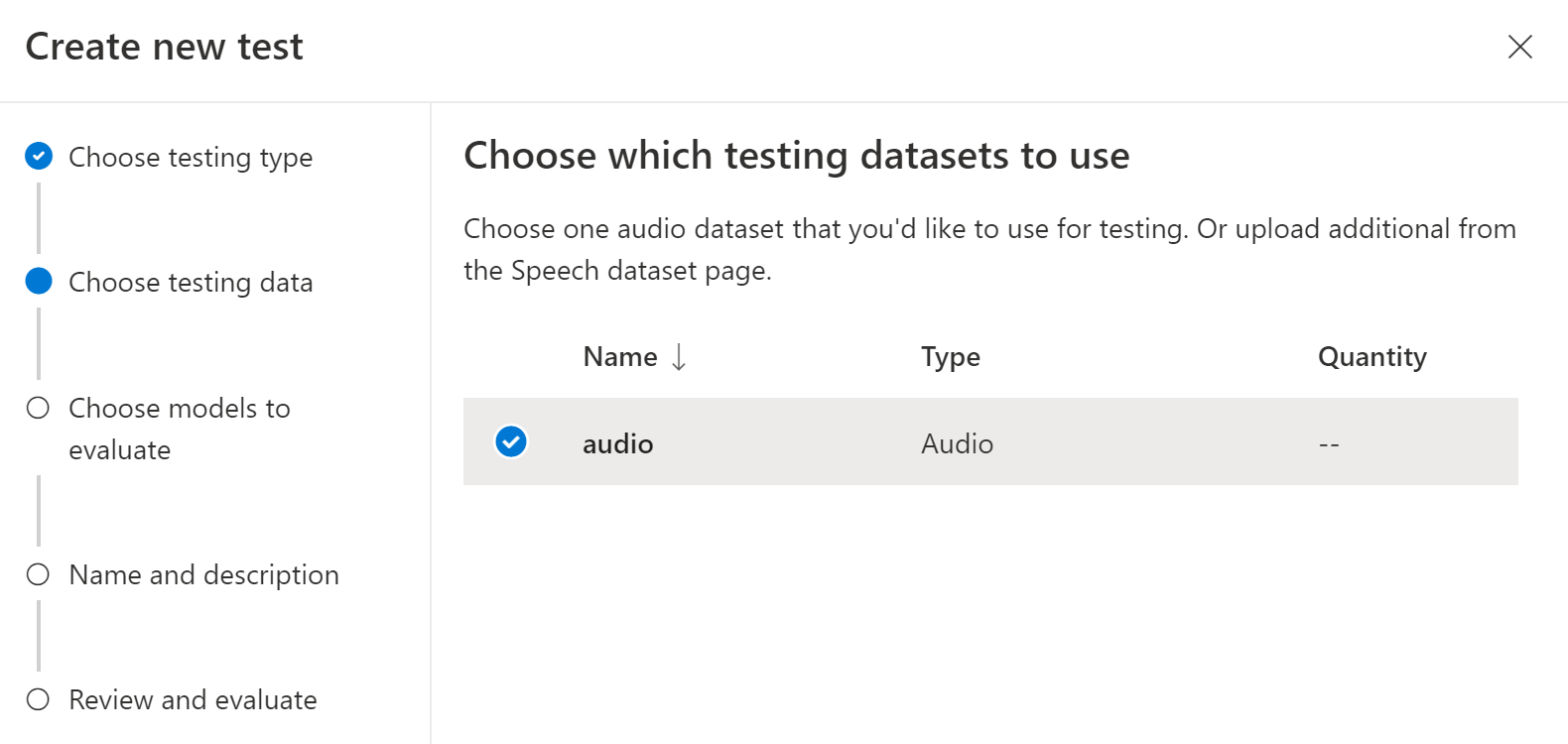
정확도를 평가하고 비교하려면 모델을 하나 또는 두 개 선택합니다.
테스트 이름과 설명을 입력하고 다음을 선택합니다.
설정을 검토한 다음, 저장 후 닫기를 선택합니다.
테스트를 만들려면 spx csr evaluation create 명령을 사용합니다. 다음 지침에 따라 요청 매개 변수를 생성합니다.
project매개 변수를 기존 프로젝트의 ID로 설정합니다. 이 매개 변수는 Speech Studio에서도 테스트를 볼 수 있도록 하기 위해 권장됩니다.spx csr project list명령을 실행하여 사용 가능한 프로젝트를 가져올 수 있습니다.- 필수
model1매개 변수를 테스트하려는 모델의 ID로 설정합니다. - 필수
model2매개 변수를 테스트하려는 다른 모델의 ID로 설정합니다. 두 모델을 비교하지 않으려면model1및model2둘 다에 대해 동일한 모델을 사용합니다. - 필수
dataset매개 변수를 테스트에 사용할 데이터 세트의 ID로 설정합니다. language매개 변수를 설정합니다. 그렇지 않으면 Speech CLI는 기본적으로 "en-US"로 설정됩니다. 이 매개 변수는 데이터 세트 콘텐츠의 로캘이어야 합니다. 로캘은 나중에 변경할 수 없습니다. Speech CLIlanguage매개 변수는 JSON 요청 및 응답의locale속성에 해당합니다.- 필수
name매개 변수를 설정합니다. 이 매개 변수는 Speech Studio에 표시되는 이름입니다. Speech CLIname매개 변수는 JSON 요청 및 응답의displayName속성에 해당합니다.
다음은 테스트를 만드는 Speech CLI 명령의 예입니다.
spx csr evaluation create --api-version v3.2 --project 0198f569-cc11-4099-a0e8-9d55bc3d0c52 --dataset 23b6554d-21f9-4df1-89cb-f84510ac8d23 --model1 13fb305e-09ad-4bce-b3a1-938c9124dda3 --model2 13fb305e-09ad-4bce-b3a1-938c9124dda3 --name "My Inspection" --description "My Inspection Description"
응답 본문은 다음 형식으로 표시되어야 합니다.
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
응답 본문의 최상위 self 속성은 평가의 URI입니다. 이 URI를 사용하여 프로젝트 및 테스트 결과에 대한 세부 정보를 가져옵니다. 또한 이 URI를 사용하여 평가를 업데이트하거나 삭제합니다.
평가에 대한 Speech CLI 도움말을 보려면 다음 명령을 실행합니다.
spx help csr evaluation
테스트를 만들려면 음성 텍스트 변환 REST API의 평가_만들기 작업을 사용하세요. 다음 지침에 따라 요청 본문을 생성합니다.
project속성을 기존 프로젝트의 URI로 설정합니다. 이 속성은 Speech Studio에서도 테스트를 볼 수 있도록 하기 위해 권장됩니다. Projects_List 요청을 수행하여 사용 가능한 프로젝트를 가져올 수 있습니다.- 필수
model1속성을 테스트하려는 모델의 URI로 설정합니다. - 필수
model2속성을 테스트하려는 다른 모델의 URI로 설정합니다. 두 모델을 비교하지 않으려면model1및model2둘 다에 대해 동일한 모델을 사용합니다. - 필수
dataset속성을 테스트에 사용할 데이터 세트의 URI로 설정합니다. - 필수
locale속성을 설정합니다. 이 속성은 데이터 세트 콘텐츠의 로캘이어야 합니다. 로캘은 나중에 변경할 수 없습니다. - 필수
displayName속성을 설정합니다. 이 속성은 Speech Studio에 표시되는 이름입니다.
다음 예제와 같이 URI를 사용하여 HTTP POST 요청을 만듭니다. YourSubscriptionKey를 Speech 리소스 키로 바꾸고, YourServiceRegion을 Speech 리소스 영역으로 바꾸고, 앞에서 설명한 대로 요청 본문 속성을 설정합니다.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"displayName": "My Inspection",
"description": "My Inspection Description",
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations"
응답 본문은 다음 형식으로 표시되어야 합니다.
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
응답 본문의 최상위 self 속성은 평가의 URI입니다. 이 URI를 사용하여 평가의 프로젝트 및 테스트 결과에 대한 세부 정보를 가져옵니다. 또한 이 URI를 사용하여 평가를 업데이트하거나 삭제합니다.
테스트 결과 가져오기
테스트 결과를 가져오고, 각 모델에 대한 대화 기록 결과와 비교하여 오디오 데이터 세트를 검사해야 합니다.
다음 단계에 따라 테스트 결과를 얻습니다.
- Speech Studio에 로그인합니다.
- 사용자 지정 음성> 내 프로젝트 이름 >테스트 모델을 선택합니다.
- 테스트 이름으로 링크를 선택합니다.
- ‘성공’으로 설정된 상태로 테스트가 완료되면 테스트된 각 모델에 대한 WER 번호가 포함된 결과가 표시됩니다.
이 페이지에는 제출된 데이터 세트의 대화 내용 기록과 함께 데이터 세트의 모든 발화와 인식 결과가 나열됩니다. 삽입, 삭제 및 대체를 포함한 다양한 오류 유형을 전환할 수 있습니다. 오디오를 듣고 각 열의 인식 결과를 비교하면 요구 사항을 충족하는 모델 및 더 많은 학습 및 개선이 필요한 모델을 결정할 수 있습니다.
테스트 결과를 얻으려면 spx csr evaluation status 명령을 사용합니다. 다음 지침에 따라 요청 매개 변수를 생성합니다.
- 필수
evaluation매개 변수를 테스트 결과를 가져오려는 평가의 ID로 설정합니다.
테스트 결과를 가져오는 Speech CLI 명령의 예는 다음과 같습니다.
spx csr evaluation status --api-version v3.2 --evaluation 9c06d5b1-213f-4a16-9069-bc86efacdaac
모델, 오디오 데이터 세트, 대화 기록 및 자세한 내용은 응답 본문에 반환됩니다.
응답 본문은 다음 형식으로 표시되어야 합니다.
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
평가에 대한 Speech CLI 도움말을 보려면 다음 명령을 실행합니다.
spx help csr evaluation
테스트 결과를 얻으려면 먼저 음성 텍스트 변환 REST API의 평가_가져오기 작업을 사용하세요.
다음 예제와 같이 URI를 사용하여 HTTP GET 요청을 만듭니다. YourEvaluationId를 평가 ID로 바꾸고, YourSubscriptionKey를 음성 리소스 키로 바꾸고, YourServiceRegion을 음성 리소스 지역으로 바꿉니다.
curl -v -X GET "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/YourEvaluationId" -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey"
모델, 오디오 데이터 세트, 대화 기록 및 자세한 내용은 응답 본문에 반환됩니다.
응답 본문은 다음 형식으로 표시되어야 합니다.
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
대화 기록을 오디오와 비교
테스트된 각 모델의 대화 기록 출력을 오디오 입력 데이터 세트와 비교해서 검사할 수 있습니다. 테스트에 두 모델을 포함하는 경우 대화 기록 품질을 나란히 비교할 수 있습니다.
대화 기록의 품질을 검토하려면:
- Speech Studio에 로그인합니다.
- 사용자 지정 음성> 내 프로젝트 이름 >테스트 모델을 선택합니다.
- 테스트 이름으로 링크를 선택합니다.
- 모델에서 해당 대화 기록을 읽는 동안 오디오 파일을 재생합니다.
테스트 데이터 세트에 여러 오디오 파일이 포함된 경우 테이블에 여러 행이 표시됩니다. 테스트에 두 모델을 포함하면 대화 기록이 나란히 열에 표시됩니다. 모델 간의 대화 기록 차이는 파란색 텍스트 글꼴로 표시됩니다.
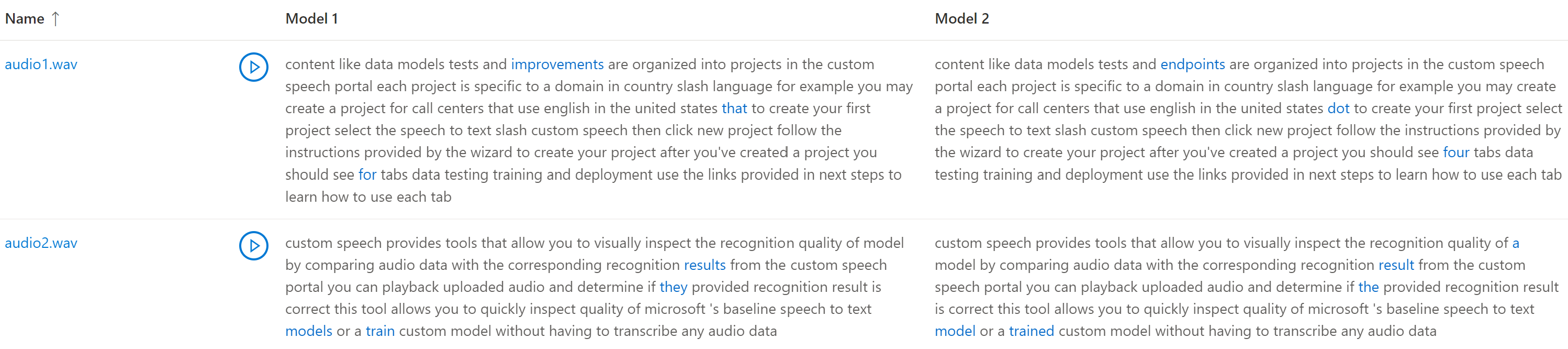
테스트된 오디오 테스트 데이터 세트, 대화 기록 및 모델이 테스트 결과에 반환됩니다. 단일 모델만 테스트한 경우 model1 값이 model2와 일치하고 transcription1 값이 transcription2와 일치합니다.
대화 기록의 품질을 검토하려면:
- 복사본이 아직 없는 경우 오디오 테스트 데이터 세트를 다운로드합니다.
- 출력 대화 기록을 다운로드합니다.
- 모델에서 해당 대화 기록을 읽는 동안 오디오 파일을 재생합니다.
두 모델 간의 품질을 비교하는 경우 각 모델의 대화 기록 간 차이에 특히 주의해야 합니다.
테스트된 오디오 테스트 데이터 세트, 대화 기록 및 모델이 테스트 결과에 반환됩니다. 단일 모델만 테스트한 경우 model1 값이 model2와 일치하고 transcription1 값이 transcription2와 일치합니다.
대화 기록의 품질을 검토하려면:
- 복사본이 아직 없는 경우 오디오 테스트 데이터 세트를 다운로드합니다.
- 출력 대화 기록을 다운로드합니다.
- 모델에서 해당 대화 기록을 읽는 동안 오디오 파일을 재생합니다.
두 모델 간의 품질을 비교하는 경우 각 모델의 대화 기록 간 차이에 특히 주의해야 합니다.