모델 테스트
모델이 성공적으로 학습하면 번역을 사용하여 모델의 품질을 평가할 수 있습니다. 표준 모델 또는 사용자 지정 모델을 사용할지 여부에 대한 정보에 입각한 결정을 내리려면 사용자 지정 모델 BLEU 점수와 표준 모델 기준 BLEU 간의 델타를 평가해야 합니다. 모델이 좁은 도메인 내에서 학습되고 학습 데이터가 테스트 데이터와 일치하는 경우 높은 BLEU 점수를 기대할 수 있습니다.
BLEU 점수
BLEU(Bilingual Evaluation Understudy)는 한 언어에서 다른 언어로 기계 번역된 텍스트의 정밀성 또는 정확도를 평가하기 위한 알고리즘입니다. Custom Translator는 번역 정확도를 전달하는 한 가지 방법으로 BLEU 메트릭을 사용합니다.
BLEU 점수는 0~100의 숫자입니다. 0의 점수는 번역에서 참조와 일치하는 항목이 전혀 없는 저품질 번역을 나타냅니다. 100의 점수는 참조와 번역이 완전히 동일함을 나타냅니다. 100점을 획득할 필요는 없습니다. 40~60의 BLEU 점수는 고품질 번역을 나타냅니다.
모델 세부 정보
모델 세부 정보 블레이드를 선택합니다.
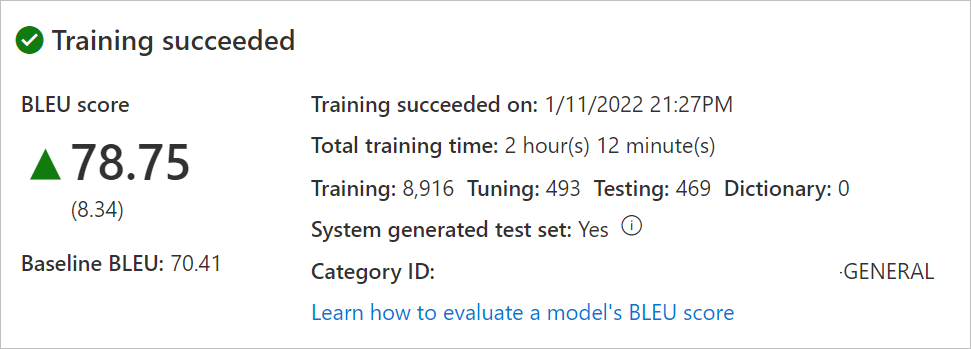
모델 이름을 선택합니다. 학습 날짜/시간, 총 학습 시간, 학습, 튜닝, 테스트 및 사전에 사용되는 문장 수를 검토합니다. 시스템에서 테스트 및 튜닝 집합을 생성했는지 확인합니다.
Category ID을(를) 사용하여 번역을 요청합니다.모델 BLEU 점수를 평가합니다. 테스트 집합 검토: BLEU 점수는 사용자 지정 모델 점수이고 기준 BLEU는 사용자 지정에 사용되는 미리 학습된 기준 모델입니다. BLEU 점수가 높을수록 사용자 지정 모델을 사용하는 번역 품질이 높아질 수 있습니다.
모델 번역 품질 테스트
테스트 모델 블레이드를 선택합니다.
모델 이름을 선택합니다.
사람이 참조(테스트 집합의 대상 번역)에 대해 사용자 지정 모델 및 기준 모델(사용자 지정에 사용되는 미리 학습된 기준)의 번역을 평가합니다.
학습 결과가 만족스러운 경우 학습된 모델에 대한 배포 요청을 배치합니다.
다음 단계
- 사용자 지정 모델을 게시/배포하는 방법을 알아봅니다.
- 사용자 지정 모델을 사용하여 문서를 번역하는 방법을 알아봅니다.