고급 네트워크 가시성이란?
고급 네트워크 가시성 기능은 고급 컨테이너 네트워킹 서비스 도구 모음의 첫 번째 기능입니다. 컨테이너화된 워크로드에 대한 탁월한 표시 여부를 제공하는 차세대 모니터링 및 진단 도구를 제공합니다. 이러한 도구를 사용하면 네트워크 문제를 쉽게 찾아내고 해결할 수 있어 애플리케이션에 대한 최적의 성능을 보장할 수 있습니다.
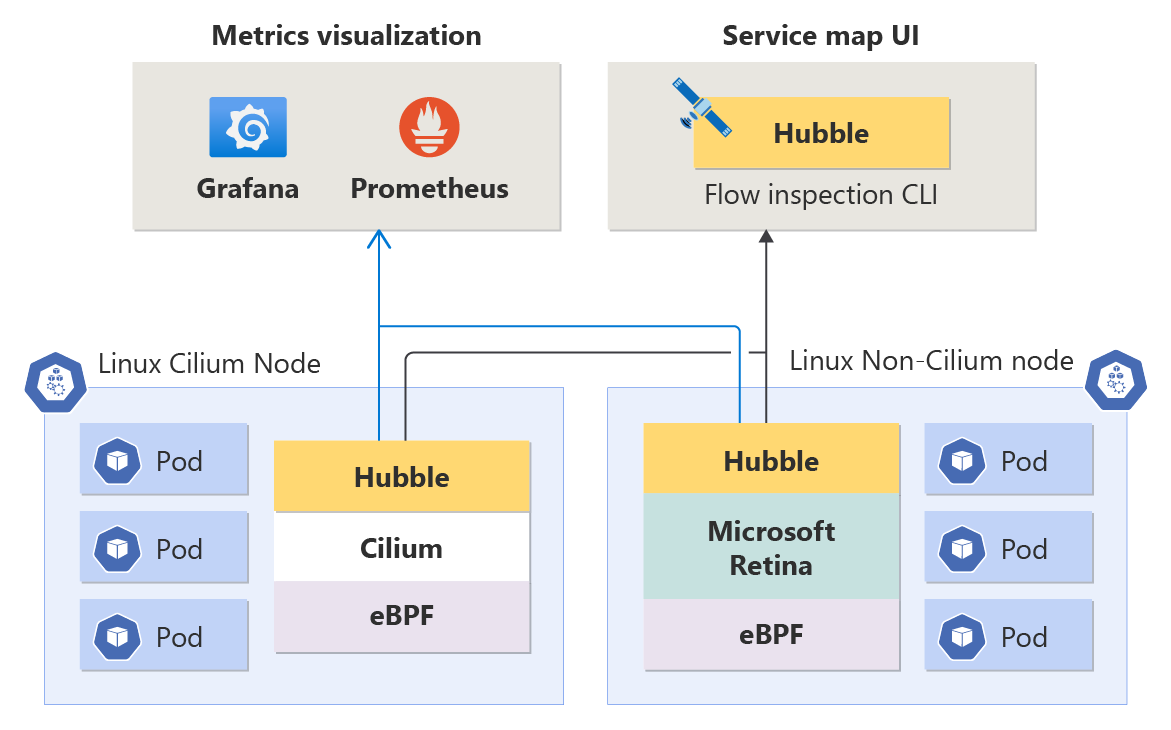
고급 네트워크 가시성은 기본 데이터 평면이 Cilium인지 비 Cilium인지에 관계없이(둘 다 지원됨) Hubble과 원활하게 통합되는 모든 Linux 워크로드와 호환되므로 컨테이너 네트워킹 요구 사항에 대한 유연성을 보장합니다.
참고 항목
Cilium 데이터 평면 시나리오의 경우 Kubernetes 버전 1.29부터 고급 네트워크 가시성 기능을 사용할 수 있습니다. 비 Cilium 데이터 평면 시나리오의 경우 버전 2.0부터 Azure Linux를 포함한 모든 Linux 배포판에서 고급 네트워크 가시성 기능이 지원됩니다.
고급 네트워크 가시성의 기능
고급 네트워크 가시성은 클러스터의 네트워크 관련 문제를 모니터링하기 위해 다음과 같은 기능을 제공합니다.
노드 수준 메트릭: 최적의 애플리케이션 성능을 유지하려면 노드 수준에서 컨테이너 네트워크의 상태를 이해해야 합니다. 이러한 메트릭은 노드별 트래픽 볼륨, 삭제된 패킷, 연결 수 등에 대한 인사이트를 제공합니다. 메트릭은 Prometheus 형식으로 저장되므로 Grafana에서 볼 수 있습니다.
Hubble 메트릭(DNS 및 Pod 수준 메트릭): 이러한 Prometheus 메트릭에는 원본 및 대상 Pod 정보가 포함되어 있어 세부적인 수준에서 네트워크 관련 문제를 정확히 찾아낼 수 있습니다. 메트릭에는 트래픽 볼륨, 삭제된 패킷, TCP 초기화, L4/L7 패킷 흐름 등이 포함됩니다. DNS 오류 및 DNS 요청 누락 응답을 다루는 DNS 메트릭(현재는 비 Cilium 데이터 평면에만 해당)도 있습니다.
Hubble 흐름 로그: 흐름 로그는 클러스터의 네트워크 활동에 대한 심층적인 표시 여부를 제공합니다. Pod와의 모든 통신이 기록되므로 시간 경과에 따른 연결 문제를 조사할 수 있습니다. 흐름 로그에서 다음과 같은 질문에 대한 답을 얻을 수 있습니다. 서버가 클라이언트의 요청을 받았나요? 클라이언트 요청과 서버 응답 간의 왕복 대기 시간은 얼마인가요?
Hubble CLI: Hubble CLI(명령줄 인터페이스)는 사용자 지정 가능한 필터링 및 서식을 사용하여 전체 클러스터에서 흐름 로그를 검색할 수 있습니다.
Hubble UI: Hubble UI는 클러스터 네트워크 활동을 탐색하기 위한 사용자 친화적인 브라우저 기반 인터페이스입니다. 흐름 로그를 기반으로 서비스 연결 그래프를 만들고, 선택한 네임스페이스에 대한 흐름 로그를 표시합니다. 사용자는 Hubble UI를 실행하는 데 필요한 인프라를 프로비전하고 관리할 책임이 있습니다.
고급 네트워크 가시성의 주요 혜택
CNI 독립적: kubenet을 포함한 모든 Azure CNI 변형에서 지원됩니다.
Cilium 및 비 Cilium: Cilium 및 비 Cilium 데이터 평면 모두에서 균일하고 원활한 환경을 제공합니다.
eBPF 기반 네트워크 가시성: 성능 및 확장성을 위해 eBPF(확장 버클리 패킷 필터)를 활용하여 애플리케이션 성능에 영향을 미치기 전에 잠재적인 병목 현상 및 정체 문제를 식별합니다. 트래픽 볼륨, 손실된 패킷, 연결 정보 등 주요 네트워크 상태 표시기에 대한 인사이트를 얻습니다.
네트워크 활동에 대한 심층적인 표시 여부: 상세한 네트워크 흐름 로그를 통해 애플리케이션이 서로 통신하는 방식을 이해합니다.
간소화된 메트릭 저장 및 시각화 옵션: 다음 중에서 선택합니다.
- Azure 관리형 Prometheus 및 Grafana: Azure는 인프라와 유지 관리를 관리하므로 사용자는 메트릭 구성 및 메트릭 시각화에 집중할 수 있습니다.
- BYO(Bring Your Own) Prometheus 및 Grafana: 사용자는 고유의 인스턴스를 배포 및 구성하고 기본 인프라를 관리합니다.
메트릭
노드 수준 메트릭
다음 메트릭은 노드별로 집계됩니다. 모든 메트릭에는 레이블이 포함됩니다.
clusterinstance(노드 이름)
비 Cilium 데이터 평면 시나리오의 경우 고급 네트워크 가시성은 Linux 및 Windows 운영 체제 모두에 대한 메트릭을 제공합니다. 아래 표에는 생성된 다양한 메트릭이 요약되어 있습니다.
| 메트릭 이름 | 설명 | 추가 레이블 | Linux | Windows |
|---|---|---|---|---|
| networkobservability_forward_count | 전달된 총 패킷 수 | direction |
✅ | ✅ |
| networkobservability_forward_bytes | 전달된 총 바이트 수 | direction |
✅ | ✅ |
| networkobservability_drop_count | 총 삭제된 패킷 수 | direction, reason |
✅ | ✅ |
| networkobservability_drop_bytes | 총 삭제 바이트 수 | direction, reason |
✅ | ✅ |
| networkobservability_tcp_state | TCP 상태에 따른 TCP 현재 활성 소켓 수입니다. | state |
✅ | ✅ |
| networkobservability_tcp_connection_remote | 원격 IP/포트별 TCP 현재 활성 소켓 수입니다. | address(IP), port |
✅ | ❌ |
| networkobservability_tcp_connection_stats | TCP 연결 통계 (예: 지연된 ACK, TCP KeepAlive, TCP Sack 실패) | statistic |
✅ | ✅ |
| networkobservability_tcp_flag_counters | 플래그별로 계산되는 TCP 패킷 | flag |
❌ | ✅ |
| networkobservability_ip_connection_stats | IP 연결 통계 | statistic |
✅ | ❌ |
| networkobservability_udp_connection_stats | UDP 연결 통계 | statistic |
✅ | ❌ |
| networkobservability_udp_active_sockets | UDP 현재 활성 소켓 수 | ✅ | ❌ | |
| networkobservability_interface_stats | 인터페이스 통계 | InterfaceName, statistic |
✅ | ✅ |
Pod 수준 메트릭(Hubble 메트릭)
다음 메트릭은 Pod별로 집계됩니다(노드 정보는 보존됨). 모든 메트릭에는 레이블이 포함됩니다.
clusterinstance(노드 이름)source또는destination
발신 트래픽의 경우 원본 Pod 네임스페이스/이름이 포함된 source 레이블이 있습니다.
수신 트래픽의 경우 대상 Pod 네임스페이스/이름이 포함된 destination 레이블이 있습니다.
| 메트릭 이름 | 설명 | 추가 레이블 | Linux | Windows |
|---|---|---|---|---|
| hubble_dns_queries_total | 쿼리별 총 DNS 요청 | source 또는 destination, query, qtypes(쿼리 형식) |
✅ | ❌ |
| hubble_dns_responses_total | 쿼리/응답별 총 DNS 응답 | source 또는 destination, query, qtypes(쿼리 형식), rcode(반환 코드), ips_returned(IP 수) |
✅ | ❌ |
| hubble_drop_total | 총 삭제된 패킷 수 | source 또는 destination, protocol, reason |
✅ | ❌ |
| hubble_tcp_flags_total | 플래그별 총 TCP 패킷 수입니다. | source 또는 destination, flag |
✅ | ❌ |
| hubble_flows_processed_total | 처리된 총 네트워크 흐름(L4/L7 트래픽) | source 또는 destination, protocol, verdict, type, subtype |
✅ | ❌ |
제한 사항
- Pod 수준 메트릭은 Linux에서만 사용할 수 있습니다.
- Cilium 데이터 평면은 Kubernetes 버전 1.29부터 지원됩니다.
- 메트릭 레이블은 Cilium 클러스터와 비 Cilium 클러스터 간에 미묘한 차이가 있을 수 있습니다.
- Cilium 데이터 평면은 현재 DNS 메트릭을 지원하지 않습니다.
확장
Azure 관리형 Prometheus 및 Grafana는 서비스별 규모 제한 사항을 적용합니다. 자세한 내용은 Azure Monitor에서 대규모 Prometheus 메트릭 스크랩을 참조하세요.
다음 단계
AKS(Azure Kubernetes Service)용 고급 컨테이너 네트워킹 서비스에 대한 자세한 내용은 AKS(Azure Kubernetes Service)용 고급 컨테이너 네트워킹 서비스란?을 참조하세요.
고급 네트워크 가시성 기능과 Azure 관리형 Prometheus 및 Grafana를 사용하여 AKS 클러스터를 만들려면 AKS(Azure Kubernetes Service) Azure 관리형 Prometheus 및 Grafana에 대한 고급 네트워크 가시성 기능 설정을 참조하세요.
고급 네트워크 가시성 기능과 BYO Prometheus 및 Grafana를 사용하여 AKS 클러스터를 만들려면 AKS(Azure Kubernetes Service) BYO Prometheus 및 Grafana에 대한 고급 네트워크 가시성 기능 설정을 참조하세요.

Azure Kubernetes Service
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기