솔루션 아이디어
이 문서는 솔루션 아이디어입니다. 잠재적인 사용 사례, 대체 서비스, 구현 고려 사항 또는 가격 책정 지침과 같은 추가 정보로 콘텐츠를 확장하려면 GitHub 피드백을 제공하여 알려주세요.
Azure에서 사용자 지정 NLP(자연어 처리) 솔루션을 구현합니다. 주제 및 감정 감지 및 분석과 같은 작업에 Spark NLP를 사용합니다.
Apache®, Apache Spark 및 불꽃 로고는 미국 및/또는 기타 국가에서 Apache Software Foundation의 등록 상표 또는 상표입니다. 이러한 표시의 사용은 Apache Software Foundation에 의한 보증을 암시하지 않습니다.
아키텍처

이 아키텍처의 Visio 파일을 다운로드합니다.
워크플로
- Azure Event Hubs, Azure Data Factory 또는 두 서비스 모두 문서 또는 비정형 텍스트 데이터를 받습니다.
- Event Hubs 및 Data Factory는 데이터를 파일 형식으로 Azure Data Lake Storage에 저장합니다. 비즈니스 요구 사항을 준수하는 디렉터리 구조를 설정하는 것이 좋습니다.
- Azure Computer Vision API는 OCR(광학 문자 인식) 기능을 사용하여 데이터를 사용합니다. 그런 다음, API는 데이터를 Bronze 계층에 씁니다. 이 사용량 플랫폼은 레이크하우스 아키텍처를 사용합니다.
- Bronze 계층에서 다양한 Spark NLP 기능은 텍스트를 전처리합니다. 예를 들어 분할, 맞춤법 수정, 정리 및 문법 이해가 있습니다. Bronze 계층에서 문서 분류를 실행한 다음, 결과를 Silver 계층에 쓰는 것이 좋습니다.
- Silver 계층에서 고급 Spark NLP 기능은 명명된 엔터티 인식, 요약 및 정보 검색과 같은 문서 분석 작업을 수행합니다. 일부 아키텍처에서는 결과가 Gold 계층에 기록됩니다.
- Gold 계층에서 Spark NLP는 텍스트 데이터에 대한 다양한 언어적 시각적 분석을 실행합니다. 이러한 분석은 언어 종속성에 대한 인사이트를 제공하고 NER 레이블의 시각화에 도움이 됩니다.
- 사용자는 Gold 계층 텍스트 데이터를 데이터 프레임으로 쿼리하고 Power BI 또는 웹앱에서 결과를 봅니다.
처리 단계에서 Azure Databricks, Azure Synapse Analytics 및 Azure HDInsight는 Spark NLP와 함께 사용되어 NLP 기능을 제공합니다.
구성 요소
- Data Lake Storage는 통합 계층 구조 네임스페이스와 Azure Blob Storage의 대규모 확장 및 경제성이 있는 Hadoop 호환 파일 시스템입니다.
- Azure Synapse Analytics는 데이터 웨어하우스 및 빅 데이터 시스템을 위한 분석 서비스입니다.
- Azure Databricks는 사용하기 쉽고 협업을 용이하게 하며 Apache Spark를 기반으로 하는 빅 데이터에 대한 분석 서비스입니다. Azure Databricks는 데이터 과학 및 데이터 엔지니어링을 위해 설계되었습니다.
- Event Hubs는 클라이언트 애플리케이션에서 생성하는 데이터 스트림을 수집합니다. Event Hubs는 스트리밍 데이터를 저장하고 수신된 이벤트의 시퀀스를 유지합니다. 소비자는 허브 엔드포인트에 연결하여 처리할 메시지를 검색할 수 있습니다. Event Hubs는 이 솔루션에서와 같이 Data Lake Storage와 통합됩니다.
- Azure HDInsight는 엔터프라이즈용 클라우드의 전체 범위 관리형 오픈 소스 분석 서비스입니다. Hadoop, Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Storm 및 R과 같은 Azure HDInsight와 함께 오픈 소스 프레임워크를 사용할 수 있습니다.
- Data Factory는 보안 수준이 서로 다른 스토리지 계정 간에 데이터를 자동으로 이동하여 업무를 분리합니다.
- Computer Vision는 텍스트 인식 API를 사용하여 이미지의 텍스트를 인식하고 해당 정보를 추출합니다. 읽기 API는 최신 인식 모델을 사용하며 텍스트가 많은 대형 문서 및 시끄러운 이미지에 최적화되어 있습니다. OCR API는 큰 문서에 최적화되지 않지만 읽기 API보다 더 많은 언어를 지원합니다. 이 솔루션은 OCR을 사용하여 hOCR 형식으로 데이터를 생성합니다.
시나리오 정보
NLP(자연어 처리)는 감정 분석, 토픽 감지, 언어 감지, 핵심 구 추출 및 문서 분류 등 다양한 용도로 사용됩니다.
Apache Spark는 메모리 내 처리를 지원하여 NLP와 같은 빅 데이터 분석 애플리케이션의 성능을 향상시키는 병렬 처리 프레임워크입니다. Azure Synapse Analytics, Azure HDInsight 및 Azure Databricks는 Spark에 대한 액세스를 제공하고 그 처리 능력을 활용합니다.
사용자 지정된 NLP 워크로드의 경우 오픈 소스 라이브러리 Spark NLP는 많은 양의 텍스트를 처리하기 위한 효율적인 프레임워크 역할을 합니다. 이 문서에서는 Azure의 대규모 사용자 지정 NLP에 대한 솔루션을 제공합니다. 솔루션은 Spark NLP 기능을 사용하여 텍스트를 처리하고 분석합니다. Spark NLP에 대한 자세한 내용은 이 문서의 뒷부분에 있는 Spark NLP 기능 및 파이프라인을 참조하세요.
잠재적인 사용 사례
문서 분류: Spark NLP는 텍스트 분류를 위한 몇 가지 옵션을 제공합니다.
- Spark NLP의 텍스트 전처리 및 Spark ML을 기반으로 하는 기계 학습 알고리즘
- Spark NLP의 텍스트 전처리 및 단어 포함 및 GloVe, BERT 및 ELMo와 같은 기계 학습 알고리즘
- Spark NLP 및 기계 학습 알고리즘 및 모델(예: 유니버설 문장 인코더)에 텍스트 전처리 및 문장 포함
- ClassifierDL 주석을 사용하고 TensorFlow를 기반으로 하는 Spark NLP의 텍스트 전처리 및 분류
NER(이름 엔터티 추출): Spark NLP에서 몇 줄의 코드를 사용하여 BERT를 사용하는 NER 모델을 학습시킬 수 있으며 최첨단 정확도를 달성할 수 있습니다. NER은 정보 추출의 하위 작업입니다. NER은 비정형 텍스트에서 명명된 엔터티를 찾아 사람 이름, 조직, 위치, 의료 코드, 시간 식, 수량, 통화 값 및 백분율과 같은 미리 정의된 범주로 분류합니다. Spark NLP는 BERT와 함께 최첨단 NER 모델을 사용합니다. 모델은 이전 NER 모델인 양방향 LSTM-CNN에서 영감을 얻었습니다. 이전 모델은 단어 수준 및 문자 수준 기능을 자동으로 검색하는 새로운 신경망 아키텍처를 사용합니다. 이를 위해 모델은 하이브리드 양방향 LSTM 및 CNN 아키텍처를 사용하므로 대부분의 기능 엔지니어링이 필요하지 않습니다.
감정 및 정서 감지: Spark NLP는 언어의 긍정, 부정 및 중립 측면을 자동으로 감지할 수 있습니다.
POS(음성 부분): 이 기능은 입력 텍스트의 각 토큰에 문법 레이블을 할당합니다.
SD(문장 검색): SD는 텍스트 내의 문장을 식별하는 문장 경계 검색을 위한 범용 신경망 모델을 기반으로 합니다. 많은 NLP 작업은 문장을 입력 단위로 사용합니다. 이러한 작업의 예제로는 POS 태그 지정, 종속성 구문 분석, 명명된 엔터티 인식 및 기계 번역이 있습니다.
Spark NLP 기능 및 파이프라인
Spark NLP는 spaCy, NLTK, Stanford CoreNLP 및 Open NLP와 같은 기존 NLP 라이브러리의 전체 기능을 제공하는 Python, Java 및 Scala 라이브러리를 제공합니다. Spark NLP는 맞춤법 검사, 감정 분석 및 문서 분류와 같은 기능도 제공합니다. Spark NLP는 최첨단 정확도, 속도 및 확장성을 제공하여 이전의 노력을 개선합니다.
Spark NLP는 현재까지 가장 빠른 오픈 소스 NLP 라이브러리입니다. 최근 공개 벤치마크에서는 Spark NLP가 spaCy보다 38배, 80배 더 빠른 것으로 나타나며, 사용자 지정 모델 학습과 비교할 만한 정확도를 제공합니다. Spark NLP는 분산 Spark 클러스터를 사용할 수 있는 유일한 오픈 소스 라이브러리입니다. Spark NLP는 데이터 프레임에서 직접 작동하는 Spark ML의 네이티브 확장입니다. 결과적으로 클러스터의 속도 향상은 성능 향상으로 이어집니다. 모든 Spark NLP 파이프라인은 Spark ML 파이프라인이므로 Spark NLP는 문서 분류, 위험 예측 및 추천 파이프라인과 같은 통합 NLP 및 기계 학습 파이프라인을 빌드하는 데 적합합니다.
뛰어난 성능 외에도 Spark NLP는 점점 더 많은 NLP 작업에 대한 최첨단 정확도를 제공합니다. Spark NLP 팀은 최신 관련 학술 논문을 정기적으로 읽고 최첨단 모델을 구현합니다.
NLP 파이프라인의 실행 순서에 대해 Spark NLP는 기존 Spark 기계 학습 모델과 동일한 개발 개념을 따릅니다. 그러나 Spark NLP는 NLP 기술을 적용합니다. 다음 다이어그램은 Spark NLP 파이프라인의 핵심 구성 요소를 보여 줍니다.
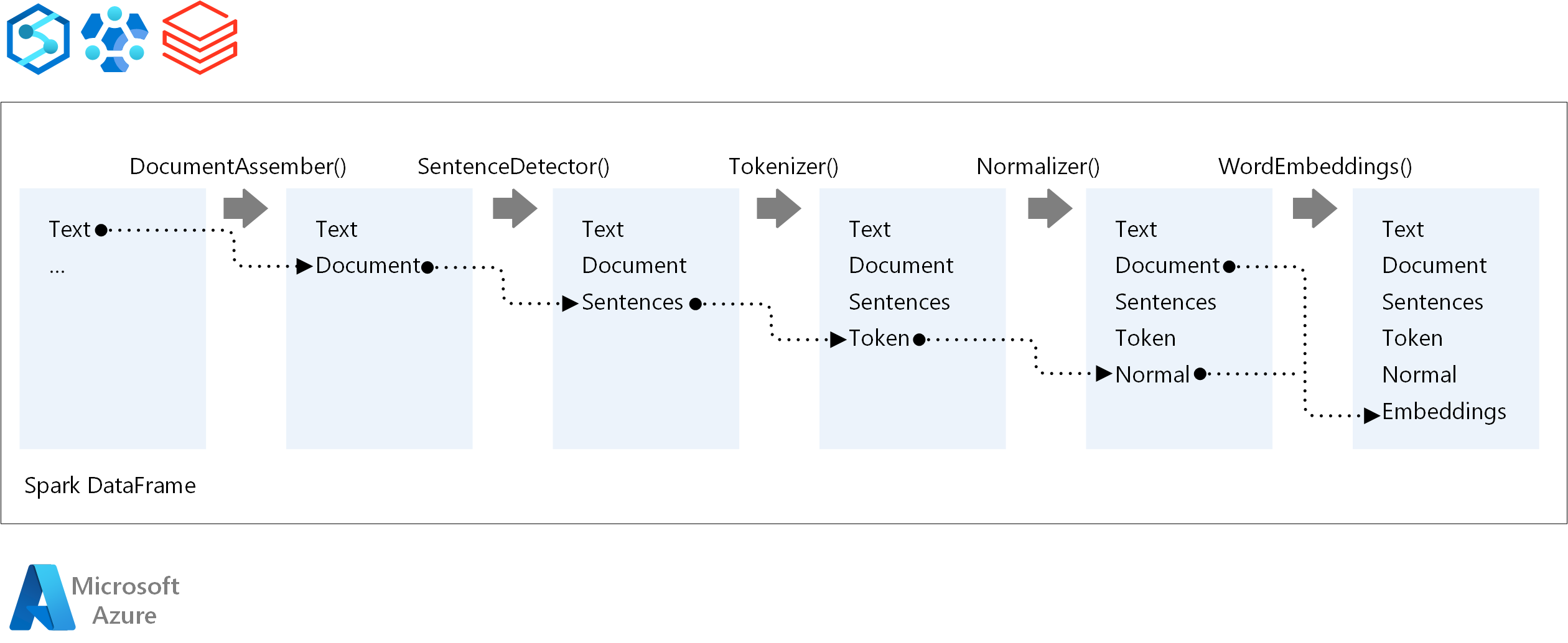
참가자
Microsoft에서 이 문서를 유지 관리합니다. 원래 다음 기여자가 작성했습니다.
보안 주체 작성자:
- Moritz Steller | 선임 클라우드 솔루션 설계자
다음 단계
Spark NLP 설명서:
Azure 구성 요소: