Azure Managed Redis
캐싱은 시스템의 성능 및 확장성을 개선하는 데 목표를 두는 일반적인 기술입니다. 자주 액세스하는 데이터를 애플리케이션 가까이에 있는 빠른 스토리지에 일시적으로 복사하여 데이터를 캐시합니다. 이 빠른 데이터 스토리지가 원래 원본보다 애플리케이션에 가까이 위치하는 경우 캐싱은 데이터를 보다 신속하게 이용하여 클라이언트 애플리케이션에 대한 응답 시간을 훨씬 향상할 수 있습니다.
캐싱은 클라이언트 인스턴스가 동일한 데이터를 반복적으로 읽는 경우에 가장 효과적입니다. 특히 다음 조건이 모두 원래 데이터 저장소에 적용되는 경우 가장 효과적입니다.
- 상대적으로 정적으로 유지됩니다.
- 캐시 속도와 비교하여 느립니다.
- 높은 수준의 경합이 발생하기 쉽습니다.
- 클라이언트와의 거리가 멀어서 네트워크 지연 시간이 상당히 큽니다.
분산 애플리케이션에서 캐싱
분산 애플리케이션은 일반적으로 데이터를 캐싱할 때 다음 전략 중 하나 또는 둘 다를 구현합니다.
- 애플리케이션 또는 서비스의 인스턴스를 실행하는 컴퓨터에서 데이터가 로컬로 유지되는 프라이빗 캐시를 사용합니다.
- 공유 캐시를 사용하며 여러 프로세스와 컴퓨터에서 액세스할 수 있는 공통 소스 역할을 합니다.
두 경우 모두 캐싱은 클라이언트 쪽 및 서버 쪽에서 수행할 수 있습니다. 클라이언트 쪽 캐싱은 웹 브라우저 또는 데스크톱 애플리케이션과 같은 시스템에 대한 사용자 인터페이스를 제공하는 프로세스에 의해 수행됩니다. 서버 쪽 캐싱은 원격으로 실행되는 비즈니스 서비스를 제공하는 프로세스에 의해 수행됩니다.
프라이빗 캐싱
가장 기본적인 캐시 유형은 메모리 내 저장소입니다. 단일 프로세스의 주소 공간에 보관되고 해당 프로세스에서 실행되는 코드에 의해 직접 액세스됩니다. 이 유형의 캐시는 빠르게 액세스할 수 있습니다. 또한 적당한 양의 정적 데이터를 저장하는 효과적인 수단을 제공할 수도 있습니다. 캐시의 크기는 일반적으로 프로세스를 호스트하는 컴퓨터에서 사용할 수 있는 메모리 양에 의해 제한됩니다.
메모리에서 물리적으로 가능한 것보다 더 많은 정보를 캐시해야 하는 경우 캐시된 데이터를 로컬 파일 시스템에 쓸 수 있습니다. 이 프로세스는 메모리에 저장된 데이터보다 액세스 속도가 느리지만 네트워크를 통해 데이터를 검색하는 것보다 더 빠르고 안정적이어야 합니다.
이 모델을 동시에 실행하는 애플리케이션 인스턴스가 여러 개 있는 경우 각 애플리케이션 인스턴스에는 자체 데이터 복사본을 보유하는 자체 독립 캐시가 있습니다.
캐시를 과거의 특정 시점에 원래 데이터의 스냅샷으로 간주합니다. 이 데이터가 정적이지 않은 경우 다른 애플리케이션 인스턴스가 캐시에 다른 버전의 데이터를 보유할 가능성이 높습니다. 따라서 이러한 인스턴스에서 수행하는 동일한 쿼리는 그림 1과 같이 다른 결과를 반환할 수 있습니다.

그림 1: 애플리케이션의 여러 인스턴스에서 메모리 내 캐시 사용
공유 캐싱
공유 캐시를 사용하는 경우 메모리 내 캐싱에서 발생할 수 있는 각 캐시에서 데이터가 다를 수 있다는 우려를 완화하는 데 도움이 될 수 있습니다. 공유 캐싱은 다른 애플리케이션 인스턴스가 캐시된 데이터의 동일한 보기를 볼 수 있도록 합니다. 그림 2와 같이 일반적으로 별도의 서비스의 일부로 호스트되는 별도의 위치에서 캐시를 찾습니다.
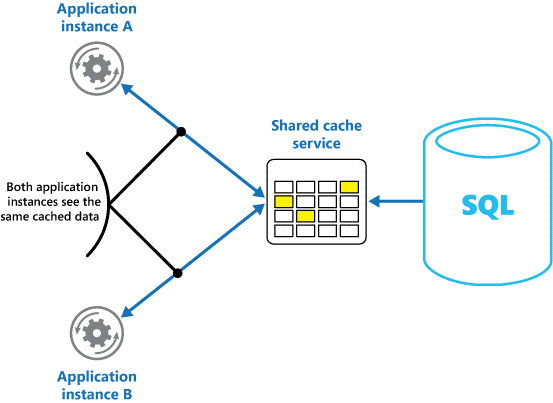
그림 2: 공유 캐시 사용
공유 캐싱 접근 방식의 중요한 이점은 이 방법이 제공하는 확장성입니다. 많은 공유 캐시 서비스는 서버 클러스터를 사용하여 구현되고 소프트웨어를 사용하여 클러스터 전체에 데이터를 투명하게 배포합니다. 애플리케이션 인스턴스는 캐시 서비스에 요청을 보냅니다. 기본 인프라는 클러스터에서 캐시된 데이터의 위치를 결정합니다. 서버를 더 추가하여 캐시 크기를 쉽게 조정할 수 있습니다.
공유 캐싱 방법의 두 가지 주요 단점은 다음과 같습니다.
- 캐시는 더 이상 각 애플리케이션 인스턴스에 로컬로 유지되지 않으므로 액세스 속도가 느립니다.
- 별도의 캐시 서비스를 구현해야 하는 요구 사항은 솔루션에 복잡성을 더할 수 있습니다.
캐싱 사용에 대한 고려 사항
다음 섹션에서는 캐시 디자인 및 사용에 대한 고려 사항을 자세히 설명합니다.
데이터를 캐시할 시기 결정
캐싱은 성능, 확장성 및 가용성을 크게 향상시킬 수 있습니다. 데이터가 많을수록 이 데이터에 액세스해야 하는 사용자 수가 많을수록 캐싱의 이점이 커집니다. 캐싱은 원래 데이터 저장소에서 대량의 동시 요청을 처리하는 것과 관련된 대기 시간 및 경합을 줄입니다.
예를 들어 데이터베이스는 제한된 수의 동시 연결을 지원할 수 있습니다. 그러나 기본 데이터베이스가 아닌 공유 캐시에서 데이터를 검색하면 사용 가능한 연결 수가 현재 소진된 경우에도 클라이언트 애플리케이션에서 이 데이터에 액세스할 수 있습니다. 또한 데이터베이스를 사용할 수 없게 되면 클라이언트 애플리케이션은 캐시에 저장된 데이터를 사용하여 계속할 수 있습니다.
자주 읽지만 자주 수정되지 않는 데이터(예: 쓰기 작업보다 읽기 작업의 비율이 높은 데이터)를 캐싱하는 것이 좋습니다. 그러나 중요한 정보의 신뢰할 수 있는 저장소로 캐시를 사용하지 않는 것이 좋습니다. 대신 애플리케이션에서 잃을 수 없는 모든 변경 내용이 항상 영구 데이터 저장소에 저장되도록 합니다. 캐시를 사용할 수 없는 경우 애플리케이션은 데이터 저장소를 사용하여 계속 작동할 수 있으며 중요한 정보는 손실되지 않습니다.
데이터를 효과적으로 캐시하는 방법 결정
캐시를 효과적으로 사용하는 열쇠는 캐시에 가장 적합한 데이터를 결정하고 적절한 시간에 캐시하는 것입니다. 애플리케이션에서 데이터를 처음 검색할 때 요청 시 캐시에 데이터를 추가할 수 있습니다. 애플리케이션은 데이터 저장소에서 한 번만 데이터를 가져와야 하며, 캐시를 사용하여 후속 액세스를 충족할 수 있습니다.
또는 일반적으로 애플리케이션이 시작될 때(시드라고 하는 접근 방식) 캐시를 미리 부분적으로 또는 완전히 데이터로 채울 수 있습니다. 그러나 이 방법은 애플리케이션이 실행되기 시작할 때 원래 데이터 저장소에 갑자기 높은 부하를 부과할 수 있으므로 큰 캐시에 대한 시드를 구현하는 것이 바람직하지 않을 수 있습니다.
종종 사용 패턴을 분석하면 캐시를 완전히 또는 부분적으로 미리 채울지 여부를 결정하고 캐시할 데이터를 선택하는 데 도움이 될 수 있습니다. 예를 들어 정기적으로(아마도 매일) 애플리케이션을 사용하는 고객을 위해 정적 사용자 프로필 데이터를 사용하여 캐시를 시드할 수 있지만, 애플리케이션을 일주일에 한 번만 사용하는 고객은 시드할 수 없습니다.
캐싱은 일반적으로 변경할 수 없거나 자주 변경되지 않는 데이터에서 잘 작동합니다. 전자 상거래 애플리케이션의 제품 및 가격 정보와 같은 참조 정보 또는 생성 비용이 많이 드는 공유 정적 리소스를 예로 들 수 있습니다. 리소스에 대한 수요를 최소화하고 성능을 향상시키기 위해 애플리케이션 시작 시 이 데이터의 일부 또는 전체를 캐시에 로드할 수 있습니다. 캐시의 참조 데이터를 주기적으로 업데이트하여 up-to-date인지 확인하는 백그라운드 프로세스가 있을 수도 있습니다. 또는 참조 데이터가 변경되면 백그라운드 프로세스가 캐시를 새로 고칠 수 있습니다.
캐싱은 동적 데이터에 덜 유용하지만 이 고려 사항에는 몇 가지 예외가 있습니다. 자세한 내용은 이 문서의 뒷부분에 있는 매우 동적 데이터 캐시 섹션을 참조하세요. 원래 데이터가 정기적으로 변경되면 캐시된 정보가 빠르게 부실해지거나 캐시를 원래 데이터 저장소와 동기화하는 오버헤드로 인해 캐싱의 효과가 줄어듭니다.
캐시는 엔터티에 대한 전체 데이터를 포함할 필요가 없습니다. 예를 들어 데이터 항목이 이름, 주소 및 계좌 잔액이 있는 은행 고객과 같은 다중값 개체를 나타내는 경우 이러한 요소 중 일부는 이름 및 주소와 같은 정적 상태로 유지될 수 있습니다. 계정 잔액과 같은 다른 요소는 더 동적일 수 있습니다. 이러한 상황에서는 데이터의 정적 부분을 캐시하고 필요한 경우 나머지 정보만 검색(또는 계산)하는 것이 유용할 수 있습니다.
성능 테스트 및 사용량 분석을 수행하여 캐시의 미리 채우거나 주문형 로드 또는 둘의 조합이 적절한지 확인하는 것이 좋습니다. 결정은 데이터의 변동성 및 사용 패턴에 따라 결정되어야 합니다. 캐시 사용률 및 성능 분석은 부하가 많은 애플리케이션에서 중요하며 확장성이 뛰어나야 합니다. 예를 들어 확장성이 뛰어난 시나리오에서는 캐시를 시드하여 사용량이 많은 시간에 데이터 저장소의 부하를 줄일 수 있습니다.
캐싱을 사용하여 애플리케이션이 실행되는 동안 계산이 반복되지 않도록 할 수도 있습니다. 작업이 데이터를 변환하거나 복잡한 계산을 수행하는 경우 작업 결과를 캐시에 저장할 수 있습니다. 나중에 동일한 계산이 필요한 경우 애플리케이션은 캐시에서 결과를 검색할 수 있습니다.
애플리케이션은 캐시에 저장된 데이터를 수정할 수 있습니다. 그러나 캐시는 언제든지 사라질 수 있는 일시적인 데이터 저장소로 생각하는 것이 좋습니다. 캐시에만 중요한 데이터를 저장하지 마세요. 원본 데이터 저장소의 정보도 유지 관리해야 합니다. 즉, 캐시를 사용할 수 없게 되면 데이터 손실 가능성을 최소화할 수 있습니다.
매우 동적 데이터 캐시
빠르게 변화하는 정보를 영구 데이터 저장소에 저장하면 시스템에 오버헤드가 발생할 수 있습니다. 예를 들어 상태 또는 다른 측정값을 지속적으로 보고하는 디바이스를 고려해 보세요. 애플리케이션이 캐시된 정보가 일반적으로 오래되었다는 이유로 이 데이터를 캐시하지 않도록 선택하는 경우 데이터 저장소에서 이 정보를 저장하고 검색할 때도 동일한 고려 사항이 적용됩니다. 이 데이터를 저장하고 가져오는 데 걸리는 시간에 변경될 수 있습니다.
이와 같은 상황에서는 동적 정보를 영구 데이터 저장소 대신 캐시에 직접 저장하는 이점을 고려합니다. 데이터가 중요하지 않고 감사가 필요하지 않은 경우 가끔 변경 내용이 손실되는지는 중요하지 않습니다.
캐시에서 데이터 만료 관리
대부분의 경우 캐시에 보관되는 데이터는 원래 데이터 저장소에 보관된 데이터의 복사본입니다. 원래 데이터 저장소의 데이터는 캐시된 후 변경되어 캐시된 데이터가 부실해질 수 있습니다. 많은 캐싱 시스템을 사용하면 데이터를 만료하도록 캐시를 구성하고 데이터가 만료될 수 있는 기간을 줄일 수 있습니다.
만료된 캐시된 데이터는 캐시에서 제거되고 애플리케이션은 원래 데이터 저장소에서 데이터를 검색해야 합니다(새로 가져온 정보를 캐시에 다시 넣을 수 있습니다). 캐시를 구성할 때 기본 만료 정책을 설정할 수 있습니다. 많은 캐시 서비스에서는 캐시에 프로그래밍 방식으로 저장할 때 개별 개체의 만료 기간을 규정할 수도 있습니다. 일부 캐시를 사용하면 만료 기간을 절대 값으로 지정하거나 지정된 시간 내에 액세스하지 않을 경우 항목이 캐시에서 제거되도록 하는 슬라이딩 값으로 지정할 수 있습니다. 이 설정은 지정된 개체에 대해서만 캐시 전체 만료 정책을 재정의합니다.
Note
캐시의 만료 기간과 캐시에 포함된 개체를 신중하게 고려합니다. 너무 짧게 만들면 개체가 너무 빨리 만료되고 캐시 사용의 이점을 줄일 수 있습니다. 기간을 너무 길게 만들면 데이터가 부실해질 위험이 있습니다.
데이터가 오랫동안 상주하도록 허용된 경우 캐시가 채워질 수도 있습니다. 이 경우 캐시에 새 항목을 추가하라는 요청이 있으면 제거라고 하는 프로세스에서 일부 항목이 강제로 제거될 수 있습니다. 캐시 서비스는 일반적으로 LRU(최소 사용) 기준으로 데이터를 제거하지만 일반적으로 이 정책을 재정의하고 항목이 제거되지 않도록 할 수 있습니다. 그러나 이 방법을 채택하는 경우 캐시에서 사용할 수 있는 메모리를 초과할 위험이 있습니다. 캐시에 항목을 추가하려고 시도하는 애플리케이션은 예외로 실패합니다.
일부 캐싱 구현은 다른 제거 정책을 제공할 수 있습니다. 몇 가지 유형의 제거 정책이 있습니다. 여기에는 다음이 포함됩니다.
- 가장 최근에 사용한 정책입니다(데이터가 다시 필요하지 않을 것으로 예상됨).
- 선점 정책(가장 오래된 데이터는 먼저 제거됨).
- 트리거된 이벤트(예: 수정 중인 데이터)를 기반으로 하는 명시적 제거 정책입니다.
클라이언트 쪽 캐시에서 데이터 무효화
클라이언트 쪽 캐시에 저장된 데이터는 일반적으로 클라이언트에 데이터를 제공하는 서비스의 후원을 벗어난 것으로 간주됩니다. 서비스는 클라이언트 쪽 캐시에서 정보를 추가하거나 제거하도록 클라이언트에 직접 강제 적용할 수 없습니다.
즉, 잘못 구성된 캐시를 사용하는 클라이언트가 오래된 정보를 계속 사용할 수 있습니다. 예를 들어 캐시의 만료 정책이 제대로 구현되지 않은 경우 클라이언트는 원래 데이터 원본의 정보가 변경될 때 로컬로 캐시된 오래된 정보를 사용할 수 있습니다.
HTTP 연결을 통해 데이터를 제공하는 웹 애플리케이션을 빌드하는 경우 웹 클라이언트(예: 브라우저 또는 웹 프록시)가 가장 최근 정보를 가져오도록 암시적으로 강제 적용할 수 있습니다. 리소스가 해당 리소스의 URI 변경으로 업데이트되는 경우 이 작업을 수행할 수 있습니다. 웹 클라이언트는 일반적으로 리소스의 URI를 클라이언트 쪽 캐시의 키로 사용하므로 URI가 변경되면 웹 클라이언트는 이전에 캐시된 리소스 버전을 무시하고 대신 새 버전을 가져옵니다.
캐시에서 동시성 관리
종종 캐시는 애플리케이션의 여러 인스턴스에서 공유되도록 설계되었습니다. 각 애플리케이션 인스턴스는 캐시의 데이터를 읽고 수정할 수 있으므로 공유 데이터 저장소에서 발생하는 동일한 동시성 문제도 캐시에 적용됩니다. 애플리케이션이 캐시에 저장된 데이터를 수정해야 하는 경우 애플리케이션의 한 인스턴스에서 수행한 업데이트가 다른 인스턴스의 변경 내용을 덮어쓰지 않도록 해야 할 수 있습니다.
데이터의 특성 및 충돌 가능성에 따라 동시성에 대한 두 가지 방법 중 하나를 채택할 수 있습니다.
- Optimistic. 애플리케이션이 데이터를 업데이트하기 전에 캐시의 데이터가 검색된 이후 변경되었는지 여부를 확인합니다. 데이터가 여전히 같으면 변경할 수 있습니다. 그렇지 않으면 애플리케이션이 업데이트할지 여부를 결정해야 합니다. (이 결정을 이끄는 비즈니스 논리는 애플리케이션에 따라 다릅니다.) 이 방법은 업데이트가 드물거나 충돌이 발생할 가능성이 없는 상황에 적합합니다.
- Pessimistic. 데이터를 검색할 때 애플리케이션은 다른 인스턴스가 데이터를 변경하지 못하도록 캐시에 잠깁니다. 이 프로세스는 충돌이 발생할 수 없도록 하지만 동일한 데이터를 처리해야 하는 다른 인스턴스도 차단할 수 있습니다. 비관적 동시성은 솔루션의 확장성에 영향을 줄 수 있으며 단기 작업에만 권장됩니다. 이 방법은 특히 애플리케이션이 캐시의 여러 항목을 업데이트하고 이러한 변경 내용이 일관되게 적용되도록 해야 하는 경우 충돌이 발생할 가능성이 더 큰 상황에 적합할 수 있습니다.
고가용성 및 확장성 구현 및 성능 향상
캐시를 데이터의 기본 리포지토리로 사용하지 마세요. 캐시가 채워진 원래 데이터 저장소의 역할입니다. 원래 데이터 저장소는 데이터의 지속성을 보장합니다.
솔루션에 공유 캐시 서비스의 가용성에 중요한 종속성을 도입하지 않도록 주의하세요. 공유 캐시를 제공하는 서비스를 사용할 수 없는 경우 애플리케이션이 계속 작동할 수 있어야 합니다. 캐시 서비스가 다시 시작될 때까지 기다리는 동안 애플리케이션이 응답하지 않거나 실패하면 안 됩니다.
따라서 캐시 서비스의 가용성을 검색하고 캐시에 액세스할 수 없는 경우 원래 데이터 저장소로 대체하도록 애플리케이션을 준비해야 합니다. Circuit-Breaker 패턴은 이 시나리오를 처리하는 데 유용합니다. 캐시를 제공하는 서비스를 복구할 수 있으며, 캐시를 사용할 수 있게 되면 캐시 배제 패턴과 같은 전략에 따라 원래 데이터 저장소에서 데이터를 읽을 때 캐시를 다시 채울 수 있습니다.
그러나 캐시를 일시적으로 사용할 수 없을 때 애플리케이션이 원래 데이터 저장소로 되돌아가는 경우 시스템 확장성이 영향을 받을 수 있습니다. 데이터 저장소가 복구되는 동안 원래 데이터 저장소는 데이터 요청으로 인해 시간 초과 및 연결 실패로 인해 늪에 빠질 수 있습니다.
모든 애플리케이션 인스턴스가 액세스하는 공유 캐시와 함께 애플리케이션의 각 인스턴스에 로컬 프라이빗 캐시를 구현하는 것이 좋습니다. 애플리케이션에서 항목을 검색할 때 먼저 로컬 캐시, 공유 캐시 및 원래 데이터 저장소에서 확인할 수 있습니다. 공유 캐시의 데이터를 사용하거나 공유 캐시를 사용할 수 없는 경우 데이터베이스에서 로컬 캐시를 채울 수 있습니다.
이 방법을 사용하려면 로컬 캐시가 공유 캐시와 관련하여 너무 오래되지 않도록 주의 깊게 구성해야 합니다. 그러나 공유 캐시에 연결할 수 없는 경우 로컬 캐시는 버퍼 역할을 합니다. 그림 3은 이 구조를 보여줍니다.
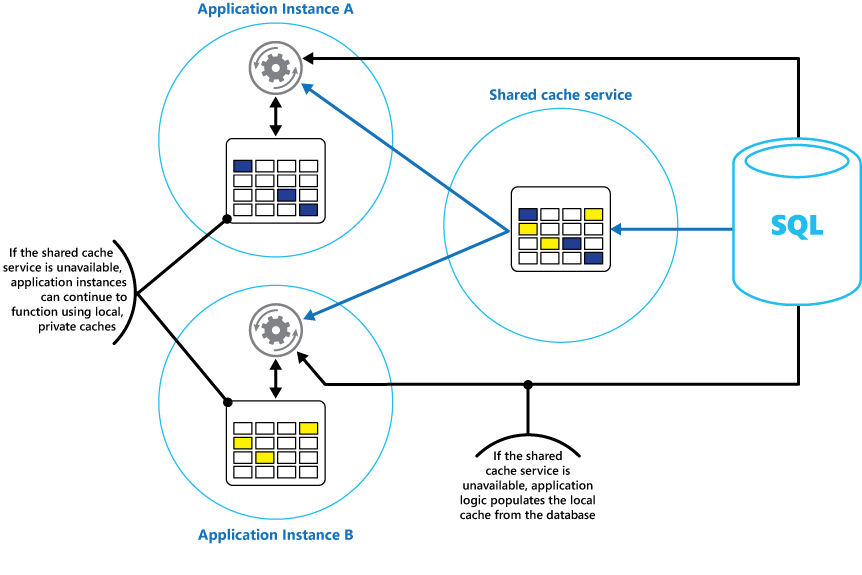
그림 3: 공유 캐시와 함께 로컬 프라이빗 캐시 사용
상대적으로 수명이 긴 데이터를 보유하는 큰 캐시를 지원하기 위해 일부 캐시 서비스는 캐시를 사용할 수 없게 되면 자동 장애 조치를 구현하는 고가용성 옵션을 제공합니다. 이 방법은 일반적으로 주 캐시 서버에 저장된 캐시된 데이터를 보조 캐시 서버로 복제하고 주 서버가 실패하거나 연결이 끊어지면 보조 서버로 전환하는 것을 포함합니다.
여러 대상에 대한 쓰기와 관련된 대기 시간을 줄이기 위해 주 서버의 캐시에 데이터를 쓸 때 보조 서버에 대한 복제가 비동기적으로 발생할 수 있습니다. 이 방법을 사용하면 오류가 발생할 경우 일부 캐시된 정보가 손실될 수 있지만 이 데이터의 비율은 캐시의 전체 크기에 비해 작아야 합니다.
공유 캐시가 큰 경우 경합 가능성을 줄이고 확장성을 개선하기 위해 노드 간에 캐시된 데이터를 분할하는 것이 유용할 수 있습니다. 많은 공유 캐시는 노드를 동적으로 추가(및 제거)하고 파티션 간에 데이터의 균형을 다시 조정하는 기능을 지원합니다. 이 방법에는 노드 컬렉션이 클라이언트 애플리케이션에 단일 캐시로 표시되는 클러스터링이 포함될 수 있습니다. 그러나 내부적으로 데이터는 부하를 균등하게 분산하는 미리 정의된 배포 전략에 따라 노드 간에 분산됩니다. 자세한 내용은 분할 패턴을 참조하세요.
클러스터링을 사용하면 캐시의 가용성도 높아질 수 있습니다. 노드가 실패하면 나머지 캐시에 계속 액세스할 수 있습니다. 클러스터링은 복제 및 페일오버와 함께 자주 사용됩니다. 각 노드를 복제할 수 있으며 노드가 실패하면 복제본을 신속하게 온라인 상태로 만들 수 있습니다.
많은 읽기 및 쓰기 작업에는 단일 데이터 값 또는 개체가 포함될 수 있습니다. 그러나 대용량 데이터를 신속하게 저장하거나 검색해야 하는 경우도 있습니다. 예를 들어 캐시 시드에는 캐시에 수백 또는 수천 개의 항목을 쓰는 작업이 포함될 수 있습니다. 애플리케이션은 동일한 요청의 일부로 캐시에서 많은 수의 관련 항목을 검색해야 할 수도 있습니다.
많은 대규모 캐시는 이러한 용도로 일괄 처리 작업을 제공합니다. 이렇게 하면 클라이언트 애플리케이션이 대량의 항목을 단일 요청으로 패키지하고 많은 수의 작은 요청을 수행하는 것과 관련된 오버헤드를 줄일 수 있습니다.
캐싱 및 최종 일관성
캐시 배제 패턴이 작동하려면 캐시를 채우는 애플리케이션 인스턴스가 가장 최근의 일관된 데이터 버전에 액세스할 수 있어야 합니다. 최종 일관성(예: 복제된 데이터 저장소)을 구현하는 시스템에서는 그렇지 않을 수 있습니다.
애플리케이션의 한 인스턴스는 데이터 항목을 수정하고 해당 항목의 캐시된 버전을 무효화할 수 있습니다. 애플리케이션의 다른 인스턴스는 캐시에서 이 항목을 읽으려고 시도할 수 있으므로 캐시 누락이 발생하므로 데이터 저장소에서 데이터를 읽고 캐시에 추가합니다. 그러나 데이터 저장소가 다른 복제본과 완전히 동기화되지 않은 경우 애플리케이션 인스턴스는 캐시를 읽고 이전 값으로 채울 수 있습니다.
분산 캐시는 이 문제에 또 다른 계층을 도입합니다. CAP 정리는 분산 시스템이 일관성, 가용성 및 파티션 허용 오차의 세 가지 보장 중 최대 두 가지를 제공할 수 있다고 명시합니다. 네트워크 파티션은 클라우드 환경에서 피할 수 없으므로 일관성과 가용성 중에서 선택해야 합니다. Redis를 포함한 대부분의 분산 캐시는 강력한 일관성보다 가용성 및 파티션 허용 오차의 우선 순위를 지정합니다. 즉, 캐시 복제본에서 읽는 경우 네트워크 파티션 중에 또는 다른 노드에 대한 쓰기 직후에 부실 데이터를 반환할 수 있습니다. 캐싱 전략을 설계할 때 애플리케이션에서 허용할 수 있는 오래됨을 결정하고 이에 따라 TTL을 설정합니다. 최신이어야 하는 데이터의 경우 더 짧은 TTL을 사용하거나 캐시를 완전히 무시하고 원본 데이터 저장소에서 읽습니다.
분산 시스템에서 데이터 일관성을 처리하는 방법에 대한 자세한 내용은 마이크로 서비스에 대한 데이터 고려 사항을 참조하세요.
캐시된 데이터 보호
사용하는 캐시 서비스에 관계없이 캐시에 저장된 데이터를 무단 액세스로부터 보호하는 방법을 고려합니다. 두 가지 주요 문제가 있습니다.
- 캐시에 있는 데이터의 개인 정보입니다.
- 캐시와 캐시를 사용하는 애플리케이션 간에 흐르는 데이터의 개인 정보입니다.
캐시의 데이터를 보호하기 위해 캐시 서비스는 애플리케이션에서 다음 세부 정보를 지정해야 하는 인증 메커니즘을 구현할 수 있습니다.
- 캐시의 데이터에 액세스할 수 있는 ID입니다.
- 이러한 ID가 수행할 수 있는 작업(읽기 및 쓰기)입니다.
데이터 읽기 및 쓰기와 관련된 오버헤드를 줄이기 위해 ID에 캐시에 대한 쓰기 또는 읽기 액세스 권한이 부여된 후 해당 ID는 캐시의 모든 데이터를 사용할 수 있습니다.
캐시된 데이터의 하위 집합에 대한 액세스를 제한해야 하는 경우 다음 방법 중 하나를 수행할 수 있습니다.
- 다른 캐시 서버를 사용하여 캐시를 파티션으로 분할하고 사용할 수 있어야 하는 파티션의 ID에 대한 액세스 권한만 부여합니다.
- 서로 다른 키를 사용하여 각 하위 집합의 데이터를 암호화하고 각 하위 집합에 대한 액세스 권한이 있어야 하는 ID에만 암호화 키를 제공합니다. 클라이언트 애플리케이션은 캐시의 모든 데이터를 검색할 수 있지만 키가 있는 데이터만 암호 해독할 수 있습니다.
또한 캐시 내/외부로 흐르는 데이터를 보호해야 합니다. 이렇게 하려면 클라이언트 애플리케이션이 캐시에 연결하는 데 사용하는 네트워크 인프라에서 제공하는 보안 기능에 따라 달라집니다. 클라이언트 애플리케이션을 호스트하는 동일한 조직 내의 사이트 서버를 사용하여 캐시를 구현하는 경우 네트워크 자체를 격리하기 위해 더 많은 단계를 수행하지 않아도 될 수 있습니다. 캐시가 원격으로 위치하고 공용 네트워크(예: 인터넷)를 통해 TCP 또는 HTTP 연결이 필요한 경우 SSL을 구현하는 것이 좋습니다.
Azure Managed Redis를 사용하여 캐싱 구현
이 문서의 나머지 섹션에서는 Azure Managed Redis를 사용하여 위에서 설명한 캐싱 패턴을 구현하는 방법을 설명합니다. Azure Managed Redis는 애플리케이션 인스턴스에서 공유 캐시로 사용할 수 있는 관리형 Redis 서비스입니다. 키-값 캐싱, 집합, 정렬된 집합 및 목록과 같은 데이터 구조 및 다시 시작 시 내구성을 위한 선택적 지속성을 지원합니다.
사용 가능한 계층, 용량 계획, 네트워킹 및 기능 세부 정보에 대한 자세한 내용은 Azure Managed Redis 설명서를 참조하세요.
클라이언트 애플리케이션 연결 및 구성
Redis는 많은 프로그래밍 언어의 클라이언트 애플리케이션을 지원합니다. .NET 애플리케이션의 경우 각각 다른 Redis 워크로드에 적합한 여러 클라이언트 라이브러리를 사용할 수 있습니다. 적절한 라이브러리를 선택하는 것은 Redis가 엄격하게 캐시로 사용되는지 아니면 다중 모델 데이터 플랫폼으로 사용되는지에 따라 달라집니다.
Redis 서버에 연결하려면 클래스의 정적 Connect 메서드를 ConnectionMultiplexer 사용합니다. 이 메서드가 만드는 연결은 클라이언트 애플리케이션의 수명 동안 사용할 수 있도록 빌드됩니다. 여러 동시 스레드에서 동일한 연결을 사용할 수 있습니다. Redis 작업을 수행할 때마다 다시 연결하고 연결을 끊지 마세요. 성능이 저하될 수 있기 때문입니다.
언어별 연결 예제는 Azure Managed Redis에 연결을 참조하세요.
.NET 클라이언트 라이브러리 선택
캐싱에 Azure Managed Redis를 사용하는 경우 권장되는 .NET 라이브러리는 다음과 같습니다.
- StackExchange.Redis: 성능이 높은 하위 수준 Redis 클라이언트입니다. Redis 명령, 원자성 작업, 트랜잭션, 파이프라인 또는 Lua 스크립팅에 직접 액세스해야 하는 경우 사용합니다.
-
Microsoft.Extensions.Caching.StackExchangeRedis: ASP.NET Core에 대한 통합을
IDistributedCache제공합니다. 값이 불투명 바이트 배열로 저장되는 간단한 키-값 캐싱에 사용합니다. 이 추상화는 고급 Redis 데이터 구조를 노출하지 않습니다.
이러한 라이브러리는 일반적인 캐싱 패턴을 빌드하는 데 필요한 기본 형식을 제공하지만 애플리케이션은 캐싱 논리 자체를 구현해야 합니다.
캐싱 패턴 구현
캐싱에 Redis를 사용하는 가장 간단한 방법은 키-값 모델을 사용하여 키 아래에 값을 저장하는 것입니다. 값은 임의의 길이의 문자열 또는 이진 데이터일 수 있으므로 Redis는 직렬화된 개체, 구성 데이터, 세션 상태 또는 미리 계산된 결과를 캐싱하는 데 적합합니다.
키스페이스를 신중하게 설계하고 간결하지만 의미 있는 키를 사용합니다. 예를 들어 ID가 100인 고객의 키를 나타내려면 구조화된 키 customer:100 (예: 단순한 100키 대신)를 사용합니다. 이 체계를 사용하면 서로 다른 데이터 형식을 저장하는 값을 구분할 수 있습니다. 예를 들어 키를 orders:100 사용하여 ID가 100인 순서의 키를 나타낼 수도 있습니다.
문자열은 가장 일반적인 캐싱 방법이지만 Redis는 해시, 목록, 집합, 정렬된 집합 및 스트림과 같은 다양한 네이티브 데이터 형식 집합을 지원하므로 보다 유연한 캐싱 패턴을 사용할 수 있습니다. Redis 데이터 형식에 대한 자세한 내용은 데이터 형식에 대한 Redis 설명서를 참조 하세요.
캐시 배제 패턴 구현
데이터를 효과적으로 캐시하는 방법 결정에서 설명한 대로 일반적인 방법은 요청 시 캐시에 데이터를 로드하는 것입니다. 다음 예제에서는 캐시를 먼저 확인하고, 누락된 경우 데이터 원본에서 가져오고, 후속 요청에 대한 결과를 저장합니다.
var config = new ConfigurationOptions();
// ... configure endpoint, credentials, SSL, etc.
ConnectionMultiplexer redisHostConnection = ConnectionMultiplexer.Connect(config);
IDatabase db = redisHostConnection.GetDatabase();
async Task<string> RetrieveItemAsync(string itemKey)
{
// Attempt to retrieve the item from the Redis cache
string itemValue = await db.StringGetAsync(itemKey);
// If the value returned is null, the item was not found in the cache
// So retrieve the item from the data source and add it to the cache
if (itemValue is null)
{
itemValue = await GetItemFromDataSourceAsync(itemKey);
await db.StringSetAsync(itemKey, itemValue);
}
return itemValue;
}
원자성 및 일괄 처리 작업 수행
여러 클라이언트 또는 애플리케이션 인스턴스가 캐시를 공유하는 경우 동시 업데이트로 인해 데이터가 손상되지 않도록 해야 합니다. 일반적인 동시성 전략은 이 문서의 앞부분에 있는 캐시의 동시성 관리에 설명되어 있습니다. Redis는 이러한 전략을 구현하는 몇 가지 메커니즘을 제공합니다.
원자성 단일 키 작업입니다. 명령어로 INCR, INCRBY, DECR, DECRBY, 및 GETSET가 있으며, 이들은 단일 단계에서 값을 업데이트하여, GET와 SET가 별도로 실행될 때 발생하는 경합 조건을 방지합니다. 예시들:
INCR,INCRBY,DECRDECRBY숫자 값을 원자 단위로 증가 또는 감소합니다. StackExchange.Redis에서 사용IDatabase.StringIncrementAsync및IDatabase.StringDecrementAsync. 이는 여러 클라이언트가 동일한 키를 동시에 업데이트하는 카운터, 속도 제한기 및 할당량 추적에 유용합니다.GETSET키를 원자적으로 새 값으로 설정하고 이전 값을 반환하는 기능입니다. StackExchange.Redis에서 다음을 사용합니다IDatabase.StringGetSetAsync.string oldValue = await cache.StringGetSetAsync("data:counter", 0);
다중 키 작업.
MGET 및 MSET은 단일 왕복으로 여러 문자열 값을 읽거나 쓸 수 있어 여러 키를 동시에 처리할 때 네트워크 오버헤드를 줄여줍니다.
IDatabase.StringGetAsync 및 IDatabase.StringSetAsync 메서드는 이 기능을 지원하기 위해 오버로드됩니다.
// Create a list of key-value pairs
var keysAndValues =
new KeyValuePair<RedisKey, RedisValue>[]
{
new("data:key1", "value1"),
new("data:key99", "value2"),
new("data:key322", "value3")
};
// Store the list of key-value pairs in the cache
await cache.StringSetAsync(keysAndValues);
...
// Find all values that match a list of keys
RedisKey[] keys = ["data:key1", "data:key99", "data:key322"];
// values should contain { "value1", "value2", "value3" }
RedisValue[] values = await cache.StringGetAsync(keys);
트랜잭션(낙관적 동시성).
WATCH 명령을 사용하여 트랜잭션을 시작하기 전에 하나 이상의 키를 모니터링할 수 있습니다MULTI/EXEC. 트랜잭션이 시작되기 전에 감시된 키가 변경되면 Redis는 트랜잭션을 삭제하고 클라이언트는 다시 시도할 수 있습니다. StackExchange 라이브러리는 인터페이스를 통해 ITransaction 트랜잭션을 지원합니다.
ITransaction 객체는 IDatabase.CreateTransaction 메서드를 사용하여 생성됩니다. 개체에서 제공하는 메서드를 사용하여 트랜잭션에 명령을 호출합니다 ITransaction .
인터페이스는 ITransaction 모든 메서드가 비동기적이라는 점을 제외하고 인터페이스에서 IDatabase 액세스하는 메서드와 유사한 메서드 집합에 대한 액세스를 제공합니다. 즉, 메서드가 호출될 때만 그것이 ITransaction.Execute 수행됩니다. 메서드에서 반환 ITransaction.Execute 되는 값은 트랜잭션이 성공적으로 만들어졌는지(true) 또는 실패한 경우(false)를 나타냅니다.
다음 코드 조각은 동일한 트랜잭션의 일부로 두 개의 카운터를 증가시키고 감소시키는 예제를 보여 줍니다.
ITransaction transaction = cache.CreateTransaction();
var tx1 = transaction.StringIncrementAsync("data:counter1");
var tx2 = transaction.StringDecrementAsync("data:counter2");
bool result = await transaction.ExecuteAsync();
Console.WriteLine($"Transaction {(result ? "succeeded" : "failed")}");
if (result)
{
long increment = await tx1;
long decrement = await tx2;
Console.WriteLine($"Result of increment: {increment}");
Console.WriteLine($"Result of decrement: {decrement}");
}
Redis 트랜잭션은 관계형 데이터베이스의 트랜잭션과 다릅니다. 메서드는 Execute 실행할 트랜잭션을 구성하는 모든 명령을 큐에 넣고, 명령이 유효하지 않으면 트랜잭션이 중지됩니다. 모든 명령이 성공적으로 큐에 대기된 경우 각 명령은 비동기적으로 실행됩니다. 명령이 실패하면 다른 명령은 계속 처리됩니다. 명령이 성공적으로 완료되었는지 확인해야 하는 경우 이전 예제와 같이 해당 작업의 Result 속성을 사용하여 결과를 가져옵니다.
Lua 스크립팅. 여러 키에서 원자성이어야 하는 다단계 업데이트의 경우 서버에서 Lua 스크립트를 실행할 수 있습니다. Redis는 다른 명령을 인터리빙하지 않고 전체 스크립트를 단일 작업으로 실행합니다.
Note
클러스터형 배포에서 트랜잭션 또는 Lua 스크립트와 관련된 모든 키는 동일한 해시 슬롯에 있어야 합니다. 해시 태그(예: customer:{123}:name 및 customer:{123}:email)를 사용하여 관련 키를 배열합니다.
실행 및 캐시 잊기 작업 수행
캐시 업데이트가 보기 카운터 증가 또는 중요하지 않은 통계 새로 고침과 같은 애플리케이션 정확성에 영향을 주지 않는 경우 서버의 응답 대기를 건너뛸 수 있습니다. Redis는 명령 플래그를 통해 "fire-and-forget" 작업을 지원하여 클라이언트의 왕복 지연 시간을 줄입니다.
await cache.StringSetAsync("data:key1", 99);
...
cache.StringIncrement("data:key1", flags: CommandFlags.FireAndForget);
자동으로 만료 키 지정
캐시의 데이터 만료 관리에 설명된 만료 전략은 키별 TTL을 통해 Redis에서 구현됩니다. Redis 캐시에 항목을 저장하는 경우 항목이 자동으로 제거되는 시간 제한을 지정할 수 있습니다. 명령을 사용하여 TTL 키가 만료되기까지의 시간을 쿼리할 수도 있습니다. StackExchange 애플리케이션에서는 IDatabase.KeyTimeToLive 메서드를 사용하여 이 명령을 사용할 수 있습니다.
다음 코드 조각은 키의 만료 시간을 20초로 설정하고 키의 나머지 수명을 쿼리하는 방법을 보여 주는 코드 조각입니다.
// Add a key with an expiration time of 20 seconds
await cache.StringSetAsync("data:key1", 99, TimeSpan.FromSeconds(20));
...
// Query how much time a key has left to live
// If the key has already expired, the KeyTimeToLive function returns null
TimeSpan? expiry = cache.KeyTimeToLive("data:key1");
또한 StackExchange 라이브러리에서 매개 변수가 있는 메서드로 EXPIREAT 사용할 수 있는 명령을 사용하여 KeyExpireAsync 만료를 특정 날짜 및 DateTime 시간으로 설정할 수도 있습니다.
await cache.StringSetAsync("data:key1", 99);
await cache.KeyExpireAsync("data:key1",
new DateTime(2026, 6, 1, 0, 0, 0, DateTimeKind.Utc));
Tip
StackExchange 라이브러리를 통해 메서드로 IDatabase.KeyDeleteAsync 사용할 수 있는 DEL 명령을 사용하여 캐시에서 항목을 수동으로 제거할 수 있습니다.
Redis가 메모리 제한에 도달하면 구성된 제거 정책에 따라 키를 제거합니다. 기본 정책은 TTL이 설정된 가장 덜 최근에 사용한 키를 제거하는 정책입니다 volatile-lru. 다른 정책으로는 allkeys-lru, volatile-random, 및 noeviction가 있으며, 이는 메모리가 가득 차면 쓰기 작업이 실패하게 만듭니다. 애플리케이션에서 TTL을 일관되게 사용하는지 여부와 만료가 없는 키를 보호하려는지 여부에 따라 제거 정책을 선택합니다. 자세한 내용은 메모리 관리를 참조하세요.
캐시된 항목 상호 상관 관계
관련 항목을 캐시할 때 기본 키만 사용하는 것이 아니라 관계별로 찾아야 하는 경우가 많습니다. 예를 들어 블로그 게시물을 캐시하고 "어떤 게시물이 태그 Y를 공유합니까?" 또는 "게시 X에 속하는 태그"와 같은 쿼리에 응답해야 할 수 있습니다.
Azure Managed Redis에서 권장되는 방법은 RedisJSON 및 RediSearch를 사용하는 것입니다. 캐시된 각 항목을 메타데이터와 함께 JSON 문서로 저장한 다음 쿼리해야 하는 필드에 RediSearch 인덱스를 만듭니다. RediSearch는 애플리케이션이 별도의 인덱스 구조를 유지 관리할 필요 없이 역방향 조회, 태그 기반 필터링, 범위 쿼리 및 전체 텍스트 검색을 처리합니다.
더 간단한 시나리오의 경우 Redis Sets를 사용하여 앞으로 빌드하고 인덱스를 수동으로 역방향으로 만들 수도 있습니다. 게시물당 집합(태그 포함) 및 태그당 집합(게시물 ID 포함)을 저장합니다.
foreach (BlogPost post in posts)
{
string postTagsKey = $"blog:posts:{post.Id}:tags";
await cache.SetAddAsync(
postTagsKey, post.Tags.Select(s => (RedisValue)s).ToArray());
foreach (var tag in post.Tags)
{
await cache.SetAddAsync($"tag:{tag}:blog:posts", post.Id);
}
}
그런 다음 SetMembersAsync의 태그를 쿼리하여 게시물에 사용할 수 있으며, 여러 게시물에서 SetCombineAsync(SetOperation.Intersect, ...) 공통 태그를 찾거나, 특정 태그에 대한 모든 게시물을 찾을 수 있습니다. 단점은 관계 수가 증가함에 따라 복잡성을 더하는 정방향 및 역방향 집합을 모두 애플리케이션에서 유지해야 한다는 것입니다.
최근에 액세스한 항목 찾기
대부분의 애플리케이션은 가장 최근에 액세스하거나 본 항목을 추적해야 합니다. 예를 들어 블로깅 사이트는 가장 최근에 읽은 게시물을 반환하는 방문자에게 표시할 수 있습니다. Redis 목록은 최신성 기반 캐싱 패턴들을 구현하는 효율적인 방법으로 사용할 수 있습니다. 항목을 목록의 어느 쪽 끝으로 LPUSH 또는 RPUSH를 사용하여 푸시할 수 있으며, LPOP 또는 RPOP를 사용하여 제거할 수 있습니다. 목록 길이를 제한하고 바인딩되지 않은 메모리 증가를 방지하는 데 사용합니다 LTRIM .
순위표 구현
ZSET(Redis Sorted Sets)는 각 요소를 숫자 점수와 연결하여 정렬된 순위를 유지 관리합니다. Redis는 자동으로 순서를 유지합니다.
ZADD 는 O(log N) 및 범위 쿼리(예: ZRANGEZREVRANGE O(log N + M)입니다. 여기서 M은 반환되는 요소의 수이므로 정렬된 집합은 큰 항목 개수에도 효율적으로 유지됩니다.
순위표에 항목 추가
다음 예제에서는 ZADD 명령을 사용하여 SortedSetAddAsync 순위표에 블로그 게시물 및 해당 점수를 추가하는 방법을 보여 줍니다.
var db = connection.GetDatabase();
string redisKey = "blog:post_rankings";
BlogPost blogPost = ...; // The blog post being ranked
await db.SortedSetAddAsync(redisKey, blogPost.Title, blogPost.Score);
순위가 지정된 항목 검색
SortedSetRangeByRankWithScoresAsync을 사용하여 항목을 점수 오름차순으로 가져올 수 있습니다.
var entries = await db.SortedSetRangeByRankWithScoresAsync(redisKey);
foreach (var entry in entries)
{
Console.WriteLine($"{entry.Element}: {entry.Score}");
}
Note
SortedSetRangeByRankAsync 는 점수가 아닌 멤버 값만 반환합니다.
상위 N개 항목 검색
상위 10개 게시물과 같이 점수가 가장 높은 항목을 가져오려면 내림차순을 사용합니다.
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(
redisKey, 0, 9, Order.Descending))
{
Console.WriteLine(post);
}
점수 범위별로 항목 검색
순위가 아닌 점수 경계를 기준으로 항목을 쿼리할 수도 있습니다.
foreach (var post in await cache.SortedSetRangeByScoreWithScoresAsync(
redisKey, 5000, 100000))
{
Console.WriteLine(post);
}
순위표가 무기한 증가하지 않도록 하려면 시간 범위 키(예: 매일 또는 매주 순위표)를 사용하여 SortedSetRemoveRangeByRankAsync 이전 항목을 제거하거나 사용합니다.
SortedSetIncrementAsync (ZINCRBY)를 사용하여 점수를 원자적으로 업데이트할 수 있습니다.
캐싱 세션 상태 및 HTML 출력
Azure Managed Redis를 사용하여 ASP.NET Core 및 ASP.NET 애플리케이션에 대한 세션 상태 및 출력 캐시 데이터를 저장할 수 있습니다. 세션 데이터와 렌더링된 출력을 공유 Redis 기반 캐시에 유지하면 Azure App Service, AKS(Azure Kubernetes Service), Azure Container Apps 또는 가상 머신 확장 집합과 같은 여러 인스턴스에서 실행되는 애플리케이션은 서버 선호도 없이 일관된 사용자 환경을 유지할 수 있습니다.
Tip
최상의 성능을 위해 애플리케이션 및 Azure Managed Redis 인스턴스를 동일한 Azure 지역에 배포합니다.
ASP.NET Core
ASP.NET Core 애플리케이션은 추상화 및 세션 미들웨어를 사용합니다 IDistributedCache . Azure Managed Redis는 IDistributedCache와 Microsoft.Extensions.Caching.StackExchangeRedis 패키지를 통해 통합됩니다.
builder.Services.AddStackExchangeRedisCache(options =>
{
options.Configuration = "<your-cache-name>.<region>.redis.azure.net:10000";
options.InstanceName = "app-cache:";
});
builder.Services.AddSession();
ASP.NET Core 출력 캐싱 미들웨어는 Redis를 분산 백업 저장소로 사용하여 애플리케이션이 렌더링된 조각 또는 페이지를 모든 인스턴스에서 공유할 수 있도록 합니다. 자세한 내용은 ASP.NET Core 출력 캐시 공급자 for Redis를 참조하세요.
.NET Aspire 통합
.NET Aspire 애플리케이션은 패키지를 사용하여 Aspire.Hosting.Azure.Redis 앱 호스트에서 Azure Managed Redis 리소스를 선언할 수 있습니다. 사용 중인 프로젝트는 종속성 주입을 통해 자동으로 연결 구성을 수신하므로 서비스 간 수동 연결 문자열 관리가 제거됩니다.
// App host: declare the Azure Managed Redis resource
var cache = builder.AddAzureManagedRedis("cache");
builder.AddProject<Projects.ProductService>()
.WithReference(cache);
서비스를 사용하는 경우 다른 IDistributedCache 공급자와 동일한 방식으로 분산 캐시를 등록합니다. 자세한 내용은 Redis 통합 시작을 참조하세요.
고가용성, 확장성 및 분할
각 Azure Managed Redis 인스턴스는 주/복제본 복제를 사용합니다. 서비스는 노드 상태를 모니터링하고 주 복제본이 실패할 경우 복제본을 자동으로 승격합니다. 복제는 비동기이므로 예기치 않은 장애 조치(failover) 중에 최근에 작성된 적은 양의 데이터가 손실될 수 있습니다. 복제, 장애 조치(failover) 및 계층화된 캐싱에 대한 일반적인 전략은 이 문서의 앞부분에서 고가용성 및 확장성 구현 및 성능 향상 을 참조하세요.
로컬 메모리 내 캐시를 Azure Managed Redis와 결합하여 대기 시간을 줄이고 공유 캐시에 일시적으로 연결할 수 없는 경우 대체를 제공할 수 있습니다. Circuit-Breaker 패턴 및 캐시 배제 패턴은 이 계층화된 접근 방식을 관리하는 데 도움이 될 수 있습니다.
단일 노드의 용량을 초과하는 워크로드의 경우 Azure Managed Redis는 여러 Redis 노드에서 데이터 분할(분할)을 지원합니다. 두 클러스터링 방법을 모두 사용하면 데이터가 해시에 따른 자동 샤드 분할로 노드 간에 자동으로 분산되고, 자동 장애 조치 및 다시 동기화와 온라인 샤드 재분할(확장 및 축소)이 가능합니다. Azure Managed Redis는 다음 두 가지 클러스터링 정책을 지원합니다.
OSS 클러스터링 정책(기본값): 클라이언트는 적절한 분할된 데이터베이스와 직접 통신하고 MOVED 및 ASK 리디렉션을 비롯한 OSS Redis 클러스터 의미 체계를 따릅니다. StackExchange.Redis와 같은 클러스터 인식 클라이언트는 이러한 리디렉션을 자동으로 처리합니다. 이 정책은 가장 낮은 라우팅 오버헤드를 제공합니다.
Redis Enterprise 클러스터링 정책: 프록시는 단일 엔드포인트를 통해 투명한 라우팅을 제공합니다. 클라이언트는 클러스터 인식 논리를 구현하거나 MOVED/ASK 응답을 처리할 필요가 없습니다. 이 정책은 더 간단한 클라이언트 통합을 제공하지만 라우팅 오버헤드가 적습니다.
Azure Managed Redis는 분할 없이 단일 주/복제본 쌍을 사용하는 비클러스터형 모드도 지원합니다. 이 모드는 수평 스케일 아웃이 필요하지 않은 더 작은 워크로드에 적합합니다.
Note
사용자 지정 분할 모델(예: 클라이언트 쪽 해시 또는 타사 프록시)은 일반적으로 VM 또는 Kubernetes의 자체 관리형 Redis 배포에서만 필요합니다. Azure Managed Redis 클러스터링이 라우팅, 장애 복구 및 리샤딩을 자동으로 처리합니다.
활성 지리적 복제
다중 지역 가용성의 경우 Azure Managed Redis는 활성 지역 복제를 지원하여 Azure 지역의 인스턴스를 단일 복제 그룹으로 연결합니다. 각 인스턴스는 읽기 및 쓰기를 처리하고 변경 내용이 자동으로 동기화됩니다. 애플리케이션은 지역별 오류 발생 시 트래픽을 정상 인스턴스로 리디렉션해야 합니다. 자세한 내용은 활성 지역 복제를 참조하세요.
데이터 지속성
기본적으로 Azure Managed Redis의 캐시된 데이터는 메모리에 저장되며 노드가 다시 시작되거나 장애 조치(fails over)되는 경우 손실될 수 있습니다. 원본 데이터 저장소에서 캐시를 다시 빌드하는 속도가 느리거나 비용이 많이 드는 워크로드의 경우 Azure Managed Redis는 선택적 데이터 지속성을 지원합니다.
- RDB 스냅샷은 관리 디스크에 저장된 정기적인 지정 시간 스냅샷을 만듭니다. RDB는 정상 작업 중에 성능에 미치는 영향을 최소화하지만 마지막 스냅샷 이후 작성된 데이터는 손실될 수 있습니다.
- AOF(Append-Only 파일) 는 모든 쓰기 작업을 디스크에 기록합니다. AOF는 잠재적인 데이터 손실을 약 1초의 쓰기로 줄이지만 더 큰 파일을 생성하고 쓰기 처리량을 줄일 수 있습니다.
RDB와 AOF를 함께 사용하도록 설정할 수 있습니다. Redis는 시작 시 RDB 스냅샷을 로드한 다음 거의 완료된 복구를 위해 AOF 로그를 재생합니다.
중요합니다
지속성은 노드 오류에 대한 내구성을 향상하지만 백업 또는 재해 복구 메커니즘은 아닙니다. 중요한 데이터의 경우 항상 원본 데이터 저장소에서 신뢰할 수 있는 복사본을 유지하고 캐시 배제 패턴을 사용하여 캐시를 다시 채점합니다.
구성 세부 정보는 데이터 지속성 구성을 참조하세요.
Azure Managed Redis에서 캐시된 데이터 보호
캐시된 데이터 보호의 지침에서는 액세스 제어 및 전송 중인 데이터 문제를 설명합니다. Azure Managed Redis는 다음을 해결합니다.
- 기본 액세스 제어 메커니즘으로 Microsoft Entra ID 인증 을 사용하고 액세스 권한을 부여할 때 최소 권한 원칙을 따릅니다.
- 프라이빗 엔드포인트를 사용하여 트래픽이 공용 인터넷을 트래버스하지 않도록 네트워크 액세스를 제한합니다.
- Azure Managed Redis는 TLS를 사용하여 전송 중인 데이터를 암호화하고 미사용 데이터를 암호화합니다.
직렬화 고려 사항
.NET 개체를 Redis에 문자열 값으로 저장하는 경우 직렬화해야 합니다. 직렬화 형식을 선택할 때 성능, 상호 운용성, 버전 관리 및 페이로드 크기 간의 장단칭을 고려합니다. 모든 시나리오에 가장 빠른 직렬 변환기는 하나도 없습니다. 벤치마크는 컨텍스트에 크게 의존하며 실제 워크로드를 반영하지 않을 수 있습니다.
Azure Managed Redis 계층에서 RedisJSON을 지원하는 경우 개체를 네이티브 JSON 문서로 저장하고 전체 값을 역직렬화하지 않고 개별 필드를 쿼리할 수 있습니다.
public static class RedisJsonExtensions
{
public static async Task<T?> GetAsync<T>(
this IDatabase cache,
string key,
string path = "$")
{
var result = await cache.ExecuteAsync("JSON.GET", key, path);
if (result.IsNull)
return default;
return JsonSerializer.Deserialize<T>(result!);
}
public static async Task SetAsync<T>(
this IDatabase cache,
string key,
T value,
TimeSpan? expiry = null,
string path = "$")
{
var json = JsonSerializer.Serialize(value);
// Store JSON document
await cache.ExecuteAsync("JSON.SET", key, path, json);
// Apply TTL if provided
if (expiry.HasValue)
{
await cache.KeyExpireAsync(key, expiry);
}
}
public static async Task<bool> ExpireAsync(
this IDatabase cache,
string key,
TimeSpan expiry)
{
return await cache.KeyExpireAsync(key, expiry);
}
}
대신 값을 Redis 문자열로 직렬화하는 경우 일반적인 형식 옵션은 다음과 같습니다.
JSON - 사람이 읽을 수 있는 광범위한 플랫폼 간 지원. 가장 압축된 형식은 아니지만 캐시된 항목이 추가 역직렬화 및 다시 직렬화 단계를 방지하므로 HTTP 클라이언트에 직접 반환되는 경우에 적합합니다.
MessagePack - 스키마 요구 사항이 없는 컴팩트한 이진 형식입니다. 직렬화 오버헤드가 낮은 JSON보다 더 작은 페이로드를 생성합니다.
프로토콜 버퍼 (protobuf) - 압축 페이로드를 생성하는 스키마 기반 이진 형식입니다.
.proto언어별 코드를 생성하려면 정의 파일과 컴파일 단계가 필요합니다.BSON - 날짜 및 원시 이진 데이터와 같은 추가 형식으로 JSON을 확장하는 이진 형식입니다. 페이로드는 JSON과 크기가 비슷합니다. 애플리케이션이 MongoDB와 같은 다른 곳에서 이미 BSON을 사용하는 경우의 실용적인 선택입니다.
다음 단계
관련 리소스
다음 패턴은 애플리케이션에서 캐싱을 구현할 때 시나리오와도 관련이 있을 수 있습니다.