새 vFXT 클러스터를 만든 후 첫 번째 작업은 데이터를 Azure의 새 스토리지 볼륨으로 이동하는 것입니다. 그러나 데이터를 이동하는 일반적인 방법으로 한 클라이언트에서 단순 복사 명령을 실행하는 경우 복사 성능이 저하될 수 있습니다. 단일 스레드 복사 옵션은 Avere vFXT 클러스터의 백 엔드 스토리지에 데이터를 복사하는 데 적합하지 않습니다.
Avere vFXT for Azure 클러스터는 스케일링할 수 있는 다중 클라이언트 캐시이므로 데이터를 가장 빠르고 효율적으로 복사하는 방법은 여러 클라이언트를 사용하는 것입니다. 이 기술은 파일과 개체의 수집을 병렬로 처리합니다.
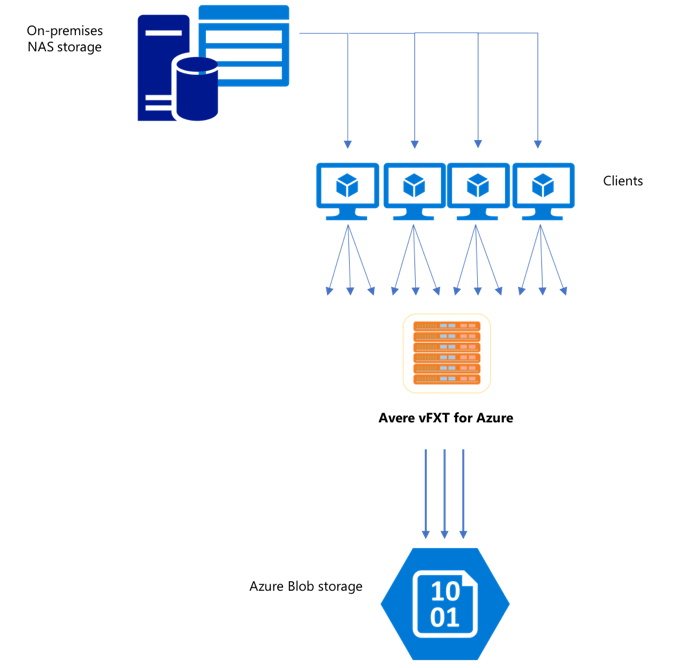
데이터를 한 스토리지 시스템에서 다른 스토리지 시스템으로 전송하는 데 일반적으로 사용되는 cp 또는 copy 명령은 한 번에 하나의 파일만 복사하는 단일 스레드 프로세스입니다. 즉 파일 서버에서 한 번에 하나의 파일만 수집합니다. 이로 인해 클러스터 리소스가 낭비됩니다.
이 문서에서는 데이터를 Avere vFXT 클러스터로 이동하는 다중 클라이언트, 다중 스레드 파일 복사 시스템을 만드는 전략에 대해 설명합니다. 여러 클라이언트와 단순 복사 명령을 사용하여 효율적인 데이터 복사에 사용할 수 있는 파일 전송 개념 및 결정 사항에 대해 설명합니다.
또한 도움이 되는 몇 가지 유틸리티도 설명합니다. msrsync 유틸리티는 데이터 세트를 버킷으로 분할하고 rsync 명령을 사용하는 프로세스를 부분적으로 자동화하는 데 사용할 수 있습니다. parallelcp 스크립트는 원본 디렉터리를 읽고 복사 명령을 자동으로 실행하는 또 다른 유틸리티입니다. 또한 rsync 도구를 사용하면 2단계 방식으로 데이터 일관성을 지원하면서도 더 빠른 복사를 제공할 수 있습니다.
다음 링크를 클릭하여 해당 섹션으로 이동합니다.
- 수동 복사 예제 - 복사 명령 사용에 대한 완전한 설명
- 2단계 rsync 예제
- 부분 자동화(msrsync) 예제
- 병렬 복사 예제
데이터 수집기 VM 템플릿
GitHub에서 Resource Manager 템플릿을 사용하여 이 문서에서 언급한 병렬 데이터 수집 도구를 통해 VM을 자동으로 만들 수 있습니다.
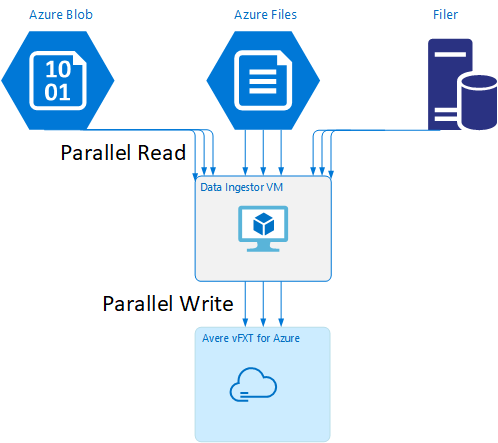
데이터 수집기 VM은 새로 만든 VM에서 Avere vFXT 클러스터를 탑재하고, 클러스터로부터 해당 부트스트랩 스크립트를 다운로드하는 자습서의 일부입니다. 자세한 내용은 데이터 수집기 VM 부트스트랩을 참조하세요.
전략적 계획
데이터를 병렬로 복사하는 전략을 설계할 때는 파일 크기, 파일 수, 디렉터리 깊이의 장단점을 이해해야 합니다.
- 파일이 작은 경우 관심 있는 메트릭은 초당 파일 수입니다.
- 파일이 큰 경우(10MiBi 이상) 관심 있는 메트릭은 초당 바이트 수입니다.
각 복사 프로세스에는 복사 명령의 길이를 타이밍으로 측정하고 파일 크기와 파일 수를 팩터링하여 측정할 수 있는 처리량 속도와 파일 전송 속도가 있습니다. 속도를 측정하는 방법은 이 문서의 범위를 벗어나므로 설명할 수 없지만 처리할 파일 크기가 작은지 큰지를 아는 것은 중요합니다.
수동 복사 예제
미리 정의된 파일 또는 경로 집합에 대해 백그라운드에서 한 번에 둘 이상의 복사 명령을 실행하여 클라이언트에 다중 스레드 복사본을 수동으로 만들 수 있습니다.
cp Linux/UNIX 명령에는 소유권 및 mtime 메타데이터를 유지하기 위해 -p 인수가 포함됩니다. 아래의 명령에 이 인수를 추가하는 것은 선택 사항입니다. (인수를 추가하면 메타데이터를 수정하기 위해 클라이언트에서 대상 파일 시스템으로 보내는 파일 시스템 호출의 수가 증가합니다.)
간단한 다음 예제에서는 두 파일을 병렬로 복사합니다.
cp /mnt/source/file1 /mnt/destination1/ & cp /mnt/source/file2 /mnt/destination1/ &
이 명령이 실행되면 jobs 명령에서 두 개의 스레드가 실행 중임을 표시합니다.
예측 가능한 파일 이름 구조
파일 이름을 예측할 수 있는 경우 식을 사용하여 병렬 복사 스레드를 만들 수 있습니다.
예를 들어 디렉터리에 0001에서 1000까지 순차적으로 번호가 매겨진 1,000개의 파일이 있으면 다음 식을 사용하여 각각 100개의 파일을 복사하는 10개의 병렬 스레드를 만들 수 있습니다.
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination1/ & \
cp /mnt/source/file2* /mnt/destination1/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination1/ & \
cp /mnt/source/file5* /mnt/destination1/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination1/ & \
cp /mnt/source/file8* /mnt/destination1/ & \
cp /mnt/source/file9* /mnt/destination1/
알 수 없는 파일 이름 구조
파일 명명 구조를 예측할 수 없는 경우 파일을 디렉터리 이름별로 그룹화할 수 있습니다.
다음 예제에서는 전체 디렉터리를 수집하여 백그라운드 작업으로 실행되는 cp 명령으로 보냅니다.
/root
|-/dir1
| |-/dir1a
| |-/dir1b
| |-/dir1c
|-/dir1c1
|-/dir1d
파일이 수집되면 병렬 복사 명령을 실행하여 하위 디렉터리와 모든 해당 콘텐츠를 반복적으로 복사할 수 있습니다.
cp /mnt/source/* /mnt/destination/
mkdir -p /mnt/destination/dir1 && cp /mnt/source/dir1/* mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ & # this command copies dir1c1 via recursion
cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
탑재 지점을 추가하는 경우
단일 대상 파일 시스템 탑재 지점에 대해 충분한 병렬 스레드가 있으면 더 많은 스레드를 추가해도 처리량이 늘어나지 않습니다. (처리량은 데이터 형식에 따라 파일 수/초 또는 바이트 수/초로 측정됩니다.) 또는 더 심각한 경우, 과도한 스레딩으로 인해 때로는 처리량이 저하될 수 있습니다.
이 경우 동일한 원격 파일 시스템 탑재 경로를 사용하여 클라이언트 쪽 탑재 지점을 다른 vFXT 클러스터 IP 주소에 추가할 수 있습니다.
10.1.0.100:/nfs on /mnt/sourcetype nfs (rw,vers=3,proto=tcp,addr=10.1.0.100)
10.1.1.101:/nfs on /mnt/destination1type nfs (rw,vers=3,proto=tcp,addr=10.1.1.101)
10.1.1.102:/nfs on /mnt/destination2type nfs (rw,vers=3,proto=tcp,addr=10.1.1.102)
10.1.1.103:/nfs on /mnt/destination3type nfs (rw,vers=3,proto=tcp,addr=10.1.1.103)
클라이언트 쪽 탑재 지점을 추가하면 추가적인 복사 명령을 추가 /mnt/destination[1-3] 탑재 지점으로 포크하여 추가 병렬 처리를 수행할 수 있습니다.
예를 들어, 파일이 매우 큰 경우 고유한 대상 경로를 사용하도록 복사 명령을 정의하여 복사를 수행하는 클라이언트에서 더 많은 명령을 병렬로 보낼 수 있습니다.
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination2/ & \
cp /mnt/source/file2* /mnt/destination3/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination2/ & \
cp /mnt/source/file5* /mnt/destination3/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination2/ & \
cp /mnt/source/file8* /mnt/destination3/ & \
위의 예제에서 클라이언트 파일 복사 프로세스는 세 개의 대상 탑재 지점을 모두 대상으로 합니다.
클라이언트를 추가하는 경우
마지막으로, 클라이언트 기능에 도달한 경우 더 많은 복사 스레드 또는 추가 탑재 지점을 추가해도 추가 파일 수/초 또는 바이트 수/초가 증가하지 않습니다. 이 경우 자체의 파일 복사 프로세스 집합을 실행할 동일한 탑재 지점 집합을 사용하여 다른 클라이언트를 배포할 수 있습니다.
예제:
Client1: cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
Client1: cp -R /mnt/source/dir2/dir2a /mnt/destination/dir2/ &
Client1: cp -R /mnt/source/dir3/dir3a /mnt/destination/dir3/ &
Client2: cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
Client2: cp -R /mnt/source/dir2/dir2b /mnt/destination/dir2/ &
Client2: cp -R /mnt/source/dir3/dir3b /mnt/destination/dir3/ &
Client3: cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ &
Client3: cp -R /mnt/source/dir2/dir2c /mnt/destination/dir2/ &
Client3: cp -R /mnt/source/dir3/dir3c /mnt/destination/dir3/ &
Client4: cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
Client4: cp -R /mnt/source/dir2/dir2d /mnt/destination/dir2/ &
Client4: cp -R /mnt/source/dir3/dir3d /mnt/destination/dir3/ &
매니페스트 파일 만들기
위의 방법(대상당 여러 복사 스레드, 클라이언트당 여러 대상, 네트워크 액세스 가능한 원본 파일 시스템당 여러 클라이언트)을 이해한 후에는 파일 매니페스트를 작성한 다음, 여러 클라이언트에서 복사 명령과 함께 이를 사용하도록 추천하는 권장 사항을 고려합니다.
이 시나리오에서는 find UNIX 명령을 사용하여 파일 또는 디렉터리의 매니페스트를 만듭니다.
user@build:/mnt/source > find . -mindepth 4 -maxdepth 4 -type d
./atj5b55c53be6-01/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-01/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-01/support/trace/rolling
./atj5b55c53be6-03/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-03/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-03/support/trace/rolling
./atj5b55c53be6-02/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-02/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-02/support/trace/rolling
이 결과를 파일로 리디렉션합니다(find . -mindepth 4 -maxdepth 4 -type d > /tmp/foo).
그런 다음, BASH 명령을 통해 매니페스트를 반복하여 파일 수를 계산하고, 하위 디렉터리의 크기를 결정할 수 있습니다.
ben@xlcycl1:/sps/internal/atj5b5ab44b7f > for i in $(cat /tmp/foo); do echo " `find ${i} |wc -l` `du -sh ${i}`"; done
244 3.5M ./atj5b5ab44b7f-02/support/gsi/2018-07-18T00:07:03EDT
9 172K ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.8M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T01:01:00UTC
131 13M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 6.2M ./atj5b5ab44b7f-02/support/gsi/2018-07-20T21:59:41UTC
134 12M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
7 16K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:12:19UTC
8 83K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:17:17UTC
575 7.7M ./atj5b5ab44b7f-02/support/cores/armada_main.2000.1531980253.gsi
33 4.4G ./atj5b5ab44b7f-02/support/trace/rolling
281 6.6M ./atj5b5ab44b7f-01/support/gsi/2018-07-18T00:07:03EDT
15 182K ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-18T05:01:00UTC
244 17M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-19T01:01:01UTC
299 31M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T01:01:00UTC
256 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T21:59:41UTC_partial
889 7.7M ./atj5b5ab44b7f-01/support/gsi/2018-07-20T21:59:41UTC
262 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
11 248K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:12:19UTC
11 88K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:17:17UTC
645 11M ./atj5b5ab44b7f-01/support/cores/armada_main.2019.1531980253.gsi
33 4.0G ./atj5b5ab44b7f-01/support/trace/rolling
244 2.1M ./atj5b5ab44b7f-03/support/gsi/2018-07-18T00:07:03EDT
9 158K ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.3M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T01:01:00UTC
131 12M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 8.4M ./atj5b5ab44b7f-03/support/gsi/2018-07-20T21:59:41UTC
134 14M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T22:25:58UTC_vfxt_catchup
7 159K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:12:19UTC
7 157K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:17:17UTC
576 12M ./atj5b5ab44b7f-03/support/cores/armada_main.2013.1531980253.gsi
33 2.8G ./atj5b5ab44b7f-03/support/trace/rolling
마지막으로, 클라이언트에 실제 파일 복사 명령을 만들어야 합니다.
4개의 클라이언트가 있는 경우 다음 명령을 사용합니다.
for i in 1 2 3 4 ; do sed -n ${i}~4p /tmp/foo > /tmp/client${i}; done
5개의 클라이언트가 있는 경우 다음과 같이 사용합니다.
for i in 1 2 3 4 5; do sed -n ${i}~5p /tmp/foo > /tmp/client${i}; done
그리고 6개가 있는 경우 필요에 따라 추정합니다.
for i in 1 2 3 4 5 6; do sed -n ${i}~6p /tmp/foo > /tmp/client${i}; done
find 명령에서 출력의 일부로 얻은 수준 4 디렉터리에 대한 경로 이름을 가진 N개의 클라이언트 각각에 대해 하나씩 N개의 결과 파일을 받게 됩니다.
각 파일을 사용하여 복사 명령을 작성합니다.
for i in 1 2 3 4 5 6; do for j in $(cat /tmp/client${i}); do echo "cp -p -R /mnt/source/${j} /mnt/destination/${j}" >> /tmp/client${i}_copy_commands ; done; done
위의 명령은 각각 줄당 복사 명령이 포함된 N개의 파일을 제공하며, 클라이언트에서 이 명령을 BASH 스크립트로 실행할 수 있습니다.
목표는 여러 클라이언트에서 동시에 클라이언트마다 이러한 스크립트의 여러 스레드를 병렬로 실행하는 것입니다.
2단계 rsync 프로세스 사용
표준 rsync 유틸리티는 데이터 무결성을 보장하기 위해 많은 수의 파일 만들기 및 이름 바꾸기 작업을 생성하기 때문에 Avere vFXT for Azure 시스템을 통해 클라우드 스토리지를 채우는 데 잘 작동하지 않습니다. 하지만 --inplace 옵션을 rsync와 함께 사용하여 파일 무결성을 확인하는 두 번째 실행이 있는 단계를 따르는 경우 더 신중한 복사 절차를 건너뛰어도 안전할 수 있습니다.
표준 rsync 복사 작업은 임시 파일을 만들어 파일을 데이터로 채웁니다. 데이터 전송이 성공적으로 완료되면 임시 파일의 이름이 원래 파일 이름으로 바뀝니다. 이 방법을 사용하면 복사 중에 파일이 액세스되는 경우에도 일관성을 보장합니다. 하지만 이 방법에서는 더 많은 쓰기 작업을 생성하므로 캐시를 통한 파일 이동 속도가 느려집니다.
--inplace 옵션은 새 파일을 최종 위치에 바로 씁니다. 전송 중에 파일 일관성이 보장되지 않으나 나중에 사용할 스토리지 시스템을 준비하는 경우 이러한 사실은 중요하지 않습니다.
두 번째 rsync 작업은 첫 번째 작업에 대한 일관성 확인 역할을 합니다. 파일이 이미 복사되었기 때문에 두 번째 단계에서는 빠른 검사를 통해 대상의 파일이 원본의 파일과 일치하는지 확인합니다. 파일이 일치하지 않으면 다시 복사됩니다.
두 단계를 다음과 같이 하나의 명령으로 함께 실행할 수 있습니다.
rsync -azh --inplace <source> <destination> && rsync -azh <source> <destination>
이 방법은 내부 디렉터리 관리자가 처리할 수 있는 파일 수까지는 데이터 세트에 간편하며 시간 효율적인 방법입니다. 일반적으로 3노드 클러스터의 경우 2억 개 파일, 6노드 클러스터의 경우 5억 개 파일 등으로 파일 수가 증가합니다.
msrsync 유틸리티 사용
msrsync 도구도 데이터를 Avere 클러스터용 백 엔드 코어 파일러(filer)로 이동하는 데 사용할 수 있습니다. 이 도구는 여러 개의 rsync 병렬 프로세스를 실행하여 대역폭 사용량을 최적화하도록 설계되었습니다. GitHub의 https://github.com/jbd/msrsync에서 사용할 수 있습니다.
msrsync는 원본 디렉터리를 별도의 "버킷"으로 분할한 다음, 각 버킷에서 rsync 프로세스를 개별적으로 실행합니다.
4개 코어 VM을 사용한 예비 테스트에서는 64개의 프로세스를 사용할 때 최고의 효율성을 보였습니다. msrsync 옵션인 -p를 사용하여 프로세스 수를 64로 설정합니다.
msrsync 명령과 함께 --inplace 인수를 사용할 수도 있습니다. 이 옵션을 사용하는 경우 데이터 무결성이 보장되도록 위에 설명된 rsync와 같이 두 번째 명령을 실행하는 것을 고려해 보세요.
msrsync는 로컬 볼륨 간에만 쓸 수 있습니다. 원본 및 대상은 클러스터의 가상 네트워크에서 로컬 탑재로 액세스할 수 있어야 합니다.
msrsync를 사용하여 Azure 클라우드 볼륨을 Avere 클러스터로 채우려면 다음 지침을 따르세요.
msrsync및 해당 필수 구성 요소(rsync 및 Python 2.6 이상)를 설치합니다.복사할 파일 및 디렉터리의 총 수를 결정합니다.
예를 들어
prime.py --directory /path/to/some/directory인수와 함께prime.pyAvere 유틸리티(URL https://github.com/Azure/Avere/blob/master/src/clientapps/dataingestor/prime.py에서 다운로드하여 사용 가능)를 사용합니다.prime.py를 사용하지 않는 경우 다음과 같이 GNUfind도구를 사용하여 항목 수를 계산할 수 있습니다.find <path> -type f |wc -l # (counts files) find <path> -type d |wc -l # (counts directories) find <path> |wc -l # (counts both)항목 수를 64로 나누어 프로세스당 항목 수를 결정합니다. 명령을 실행할 때
-f옵션에 이 숫자를 사용하여 버킷의 크기를 설정합니다.msrsync명령을 실행하여 파일을 복사합니다.msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>--inplace를 사용하는 경우 데이터가 올바르게 복사되었는지 확인하는 옵션 없이 두 번째 실행을 추가합니다.msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv --inplace" <SOURCE_PATH> <DESTINATION_PATH> && msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>예를 들어 이 명령은 64개 프로세스의 11,000개 파일을 /test/source-repository에서 /mnt/vfxt/repository로 이동하도록 설계되었습니다.
msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository && msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository
병렬 복사 스크립트 사용
parallelcp 스크립트도 데이터를 vFXT 클러스터의 백 엔드 스토리지로 이동하는 데 유용할 수 있습니다.
아래 스크립트는 parallelcp 실행 파일을 추가합니다. (이 스크립트는 Ubuntu에서 사용하도록 설계되었으므로, 다른 배포판을 사용하는 경우 parallel을 별도로 설치해야 합니다.)
sudo touch /usr/bin/parallelcp && sudo chmod 755 /usr/bin/parallelcp && sudo sh -c "/bin/cat >/usr/bin/parallelcp" <<EOM
#!/bin/bash
display_usage() {
echo -e "\nUsage: \$0 SOURCE_DIR DEST_DIR\n"
}
if [ \$# -le 1 ] ; then
display_usage
exit 1
fi
if [[ ( \$# == "--help") || \$# == "-h" ]] ; then
display_usage
exit 0
fi
SOURCE_DIR="\$1"
DEST_DIR="\$2"
if [ ! -d "\$SOURCE_DIR" ] ; then
echo "Source directory \$SOURCE_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -d "\$DEST_DIR" ] && ! mkdir -p \$DEST_DIR ; then
echo "Destination directory \$DEST_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -w "\$DEST_DIR" ] ; then
echo "Destination directory \$DEST_DIR is not writeable, or is not a directory"
display_usage
exit 3
fi
if ! which parallel > /dev/null ; then
sudo apt-get update && sudo apt install -y parallel
fi
DIRJOBS=225
JOBS=225
find \$SOURCE_DIR -mindepth 1 -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$DIRJOBS -0 "mkdir -p \$DEST_DIR/{}"
find \$SOURCE_DIR -mindepth 1 ! -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$JOBS -0 "cp -P \$SOURCE_DIR/{} \$DEST_DIR/{}"
EOM
병렬 복사 예제
다음 예제에서는 Avere 클러스터의 원본 파일을 사용하여 glibc를 컴파일하는 병렬 복사 스크립트를 사용합니다.
원본 파일은 Avere 클러스터 탑재 지점에 저장되고, 개체 파일은 로컬 하드 드라이브에 저장됩니다.
이 스크립트는 위의 병렬 복사 스크립트를 사용합니다. -j 옵션은 parallelcp 및 make과 함께 사용하여 병렬 처리를 수행합니다.
sudo apt-get update
sudo apt install -y gcc bison gcc binutils make parallel
cd
wget https://mirrors.kernel.org/gnu/libc/glibc-2.27.tar.bz2
tar jxf glibc-2.27.tar.bz2
ln -s /nfs/node1 avere
time parallelcp glibc-2.27 avere/glibc-2.27
cd
mkdir obj
mkdir usr
cd obj
/home/azureuser/avere/glibc-2.27/configure --prefix=/home/azureuser/usr
time make -j