Azure Monitor에서 Prometheus 메트릭 컬렉션 문제 해결
이 문서의 단계에 따라 Prometheus 메트릭이 Azure Monitor에서 예상대로 수집되지 않는 원인을 확인합니다.
복제본 Pod는 kube-state-metrics, ama-metrics-prometheus-config 구성맵의 사용자 지정 스크랩 대상 및 사용자 지정 리소스에 정의된 사용자 지정 스크랩 대상에서 메트릭을 긁습니다. DaemonSet Pod는 해당 노드의 대상 kubelet, cAdvisor, node-exporter 및 ama-metrics-prometheus-config-node configmap의 사용자 지정 스크랩 대상에서 메트릭을 스크래핑합니다. 로그 및 Prometheus UI를 보려는 Pod는 조사 중인 스크랩 대상에 따라 달라집니다.
PowerShell 스크립트를 사용하여 문제 해결
AKS 클러스터에 대한 모니터링을 사용하도록 설정하는 동안 오류가 발생하는 경우 다음 지침에 따라 문제 해결 스크립트를 실행하세요. 이 스크립트는 클러스터의 구성 문제에 대한 기본 진단을 수행하도록 설계되었으며, 지원 사례에 대한 빠른 해결을 위한 지원 요청을 만드는 동안 생성된 파일을 첨부할 수 있습니다.
메트릭 제한
Azure Monitor Prometheus용 관리 서비스에는 수집에 대한 기본 제한 및 할당량이 있습니다. 수집 제한에 도달하면 제한이 발생할 수 있습니다. 이러한 한도의 증가를 요청할 수 있습니다. Prometheus 메트릭 제한에 대한 자세한 내용은 Azure Monitor 서비스 제한을 참조하세요.
Azure Portal에서 Azure Monitor 작업 영역으로 이동합니다. 로 Metrics이동하여 메트릭 Active Time Series % Utilization Events Per Minute Received % Utilization을 선택하고 . 둘 다 100% 미만인지 확인합니다.
수집 메트릭에 대한 모니터링 및 경고에 대한 자세한 내용은 Azure Monitor 작업 영역 메트릭 수집 모니터링을 참조하세요.
메트릭 데이터 수집의 간헐적 간격
노드 업데이트 중에 클러스터 수준 수집기에서 수집된 메트릭의 메트릭 데이터에 1~2분 간격이 표시될 수 있습니다. 이 간격은 실행되는 노드가 일반 업데이트 프로세스의 일부로 업데이트되기 때문에 나타납니다. 이 문제는 지정된 kube-state-metrics 및 사용자 지정 애플리케이션 대상과 같은 클러스터 전체 대상에 영향을 줍니다. 또한 클러스터가 수동으로 업데이트되거나 자동 업데이트를 통해 업데이트되는 경우에 발생합니다. 이 동작은 예상되는 것이며 업데이트될 때 실행되는 노드로 인해 발생합니다. 권장되는 경고 규칙은 이 동작의 영향을 받지 않습니다.
Pod 상태
다음 명령을 사용하여 Pod 상태를 확인합니다.
kubectl get pods -n kube-system | grep ama-metrics
서비스가 올바르게 실행되면 형식 ama-metrics-xxxxxxxxxx-xxxxx 의 다음 Pod 목록이 반환됩니다.
ama-metrics-operator-targets-*ama-metrics-ksm-*ama-metrics-node-*클러스터의 각 노드에 대한 Pod입니다.
각 Pod 상태는 Running 적용된 구성맵 변경 횟수와 동일한 수의 다시 시작이 있어야 합니다. ama-metrics-operator-targets-* Pod는 시작 부분에 추가 다시 시작이 있을 수 있으며, 이는 다음과 같습니다.

각 Pod 상태가 Running이지만 하나 이상의 Pod가 다시 시작되면 다음 명령을 실행합니다.
kubectl describe pod <ama-metrics pod name> -n kube-system
- 이 명령은 다시 시작되는 이유를 제공합니다. configmap이 변경된 경우 Pod가 다시 시작됩니다. 다시 시작 이유가
OOMKilled인 경우 Pod는 메트릭 볼륨을 따라갈 수 없습니다. 메트릭 볼륨에 대한 확장 권장 사항을 참조하세요.
Pod가 예상대로 실행되는 경우 다음으로 확인할 위치는 컨테이너 로그입니다.
구성 레이블 재지정 확인
메트릭이 누락된 경우 레이블 재지정 구성이 있는지 확인할 수도 있습니다. 레이블 다시 지정 구성을 사용하면 레이블이 대상을 필터링하지 않고 구성된 레이블이 대상과 올바르게 일치하는지 확인합니다. 자세한 내용은 Prometheus relabel 구성 설명서를 참조 하세요.
컨테이너 로그
다음 명령을 사용하여 컨테이너 로그를 봅니다.
kubectl logs <ama-metrics pod name> -n kube-system -c prometheus-collector
시작할 때 초기 오류는 빨간색으로, 경고는 노란색으로 인쇄됩니다. (색이 지정된 로그를 보려면 PowerShell 버전 7 이상 또는 Linux 배포판이 필요합니다.)
- 인증 토큰을 가져오는 데 문제가 있는지 확인합니다.
- AKS 리소스에 대한 구성 없음 메시지가 5분마다 기록됩니다.
- Pod는 15분마다 다시 시작하여 AKS 리소스에 대한 구성이 없음 오류와 함께 다시 시도합니다.
- 이 경우 리소스 그룹에 데이터 수집 규칙 및 데이터 수집 엔드포인트가 있는지 확인합니다.
- 또한 Azure Monitor 작업 영역이 있는지도 확인합니다.
- 프라이빗 AKS 클러스터가 없고 다른 서비스에 대한 Azure Monitor Private Link 범위에 연결되어 있지 않은지 확인합니다. 이 시나리오는 현재 지원되지 않습니다.
구성 처리
다음 명령을 사용하여 컨테이너 로그를 봅니다.
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c config-reader
- Prometheus 구성을 구문 분석하고, 사용하도록 설정된 기본 스크랩 대상과 병합하고, 전체 구성의 유효성을 검사하는 데 오류가 없는지 확인합니다.
- 사용자 지정 Prometheus 구성을 포함했다면 로그에서 인식되는지 확인합니다. 같이 않으면
kube-system네임스페이스에서 configmap에 올바른 이름ama-metrics-prometheus-config가 있는지 확인합니다.- configmap에서 Prometheus 구성이 아래와 같이
data아래의prometheus-config섹션에 있는지 확인합니다.kind: ConfigMap apiVersion: v1 metadata: name: ama-metrics-prometheus-config namespace: kube-system data: prometheus-config: |- scrape_configs: - job_name: <your scrape job here>
- 사용자 지정 리소스를 만든 경우 Pod/서비스 모니터를 만드는 동안 유효성 검사 오류가 발생했어야 합니다. 대상의 메트릭이 여전히 표시되지 않는 경우 로그에 오류가 표시되지 않도록 합니다.
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c targetallocator
- Azure Monitor 작업 영역 인증과 관련하여
MetricsExtension의 오류가 없는지 확인합니다. - 대상 스크래핑에 대한
OpenTelemetry collector의 오류가 없는지 확인합니다.
다음 명령을 실행합니다.
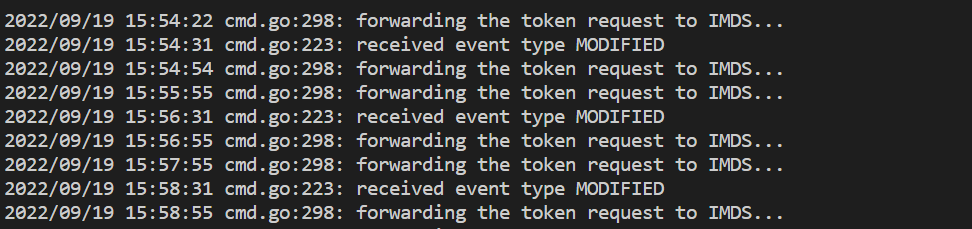
kubectl logs <ama-metrics pod name> -n kube-system -c addon-token-adapter
- 이 명령은 Azure Monitor 작업 영역을 사용하여 인증하는 데 문제가 있는 경우 오류를 표시합니다. 아래 예제에서는 문제 없이 로그를 보여 줍니다.

로그에 오류가 없으면 디버깅에 Prometheus 인터페이스를 사용하여 예상되는 구성 및 스크래핑되는 대상을 확인할 수 있습니다.
Prometheus 인터페이스
모든 ama-metrics-* Pod에는 포트 9090에서 사용할 수 있는 Prometheus 에이전트 모드 사용자 인터페이스가 있습니다.
사용자 지정 구성 및 사용자 지정 리소스 대상은 ama-metrics-* Pod 및 ama-metrics-node-* Pod에 의해 노드 대상에 의해 스크래핑됩니다.
여기에 설명된 대로 구성, 서비스 검색 및 대상 엔드포인트를 확인하기 위해 복제본 Pod 또는 디먼 집합 Pod 중 하나로 포트 전달하여 사용자 지정 구성이 올바른지, 각 작업에 대해 의도한 대상이 검색되었는지, 특정 대상을 스크래핑하는 데 오류가 없는지 확인합니다.
kubectl port-forward <ama-metrics pod> -n kube-system 9090 명령을 실행합니다.
주소
127.0.0.1:9090/config에 대한 브라우저를 엽니다. 이 사용자 인터페이스에는 전체 스크래핑 구성이 있습니다. 모든 작업이 구성에 포함되어 있는지 확인합니다.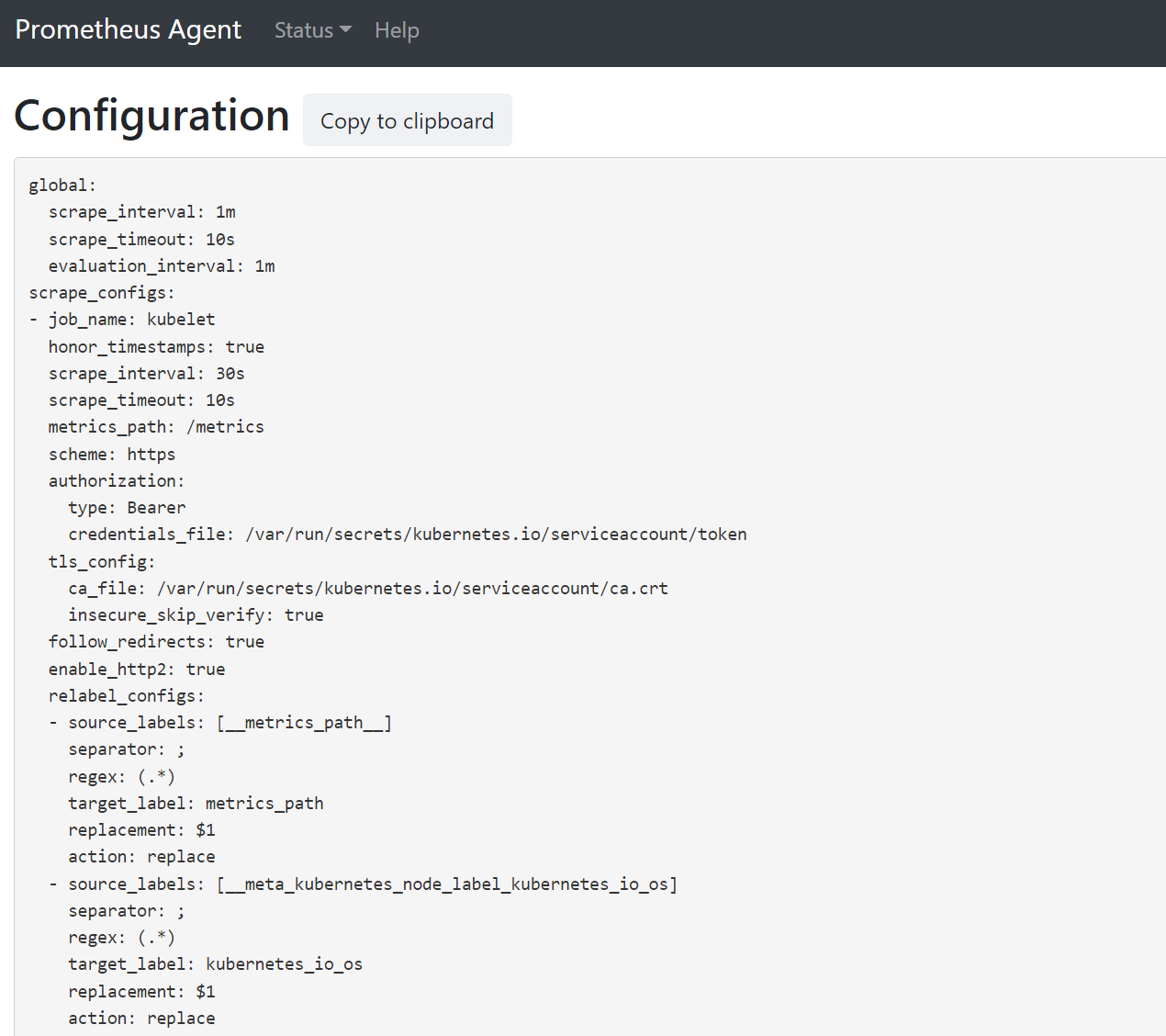
127.0.0.1:9090/service-discovery로 이동하여 지정된 서비스 검색 개체에 의해 검색된 대상과 대상을 필터링한 relabel_configs를 확인합니다. 예를 들어 특정 Pod에서 메트릭이 누락된 경우 해당 Pod가 검색되었는지 여부와 해당 URI가 무엇인지 확인할 수 있습니다. 그런 다음 대상을 볼 때 이 URI를 사용하여 스크래핑 오류가 있는지 확인할 수 있습니다.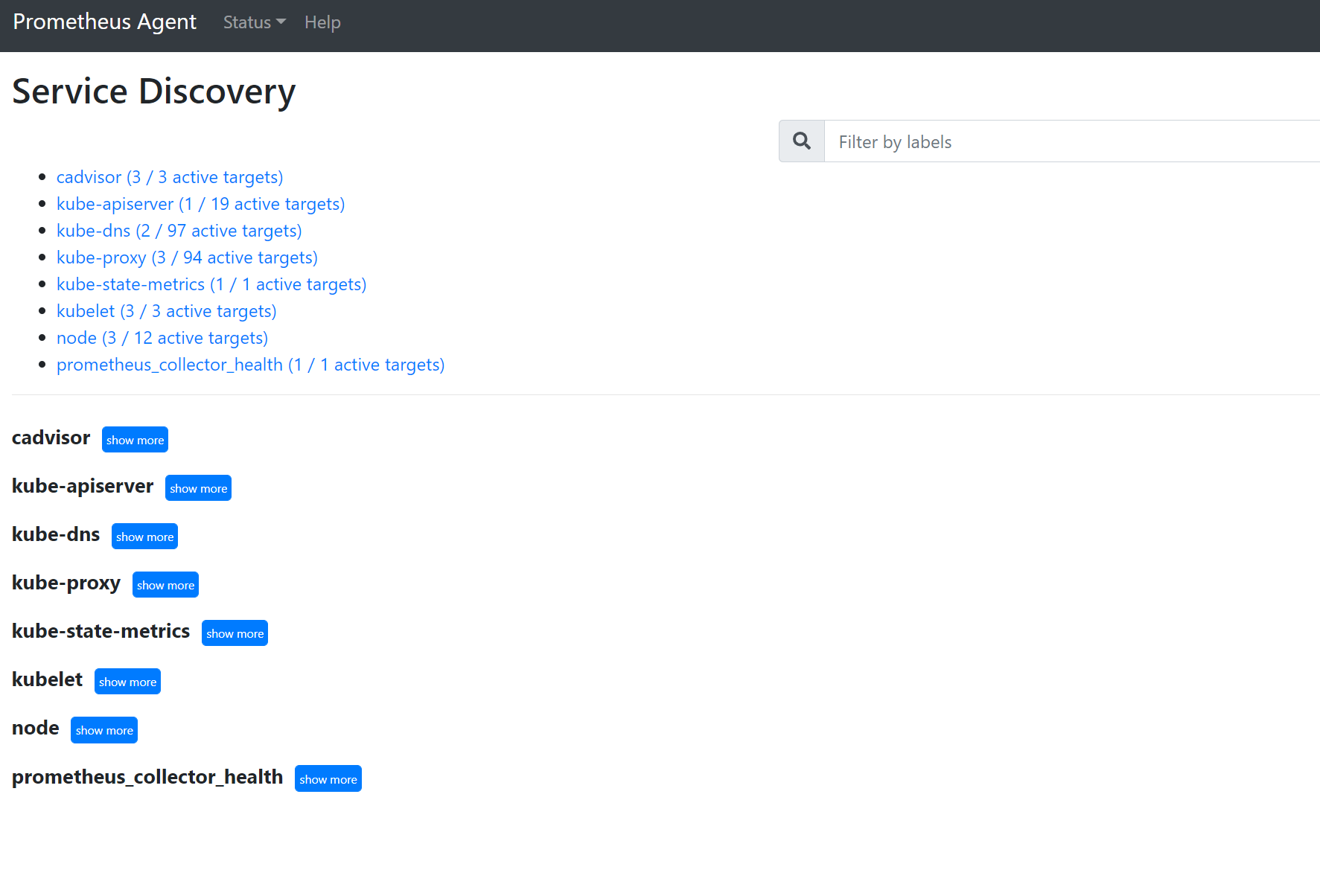
127.0.0.1:9090/targets로 이동하여 모든 작업, 해당 작업의 엔드포인트가 마지막으로 스크래핑된 시간 및 모든 오류를 확인합니다.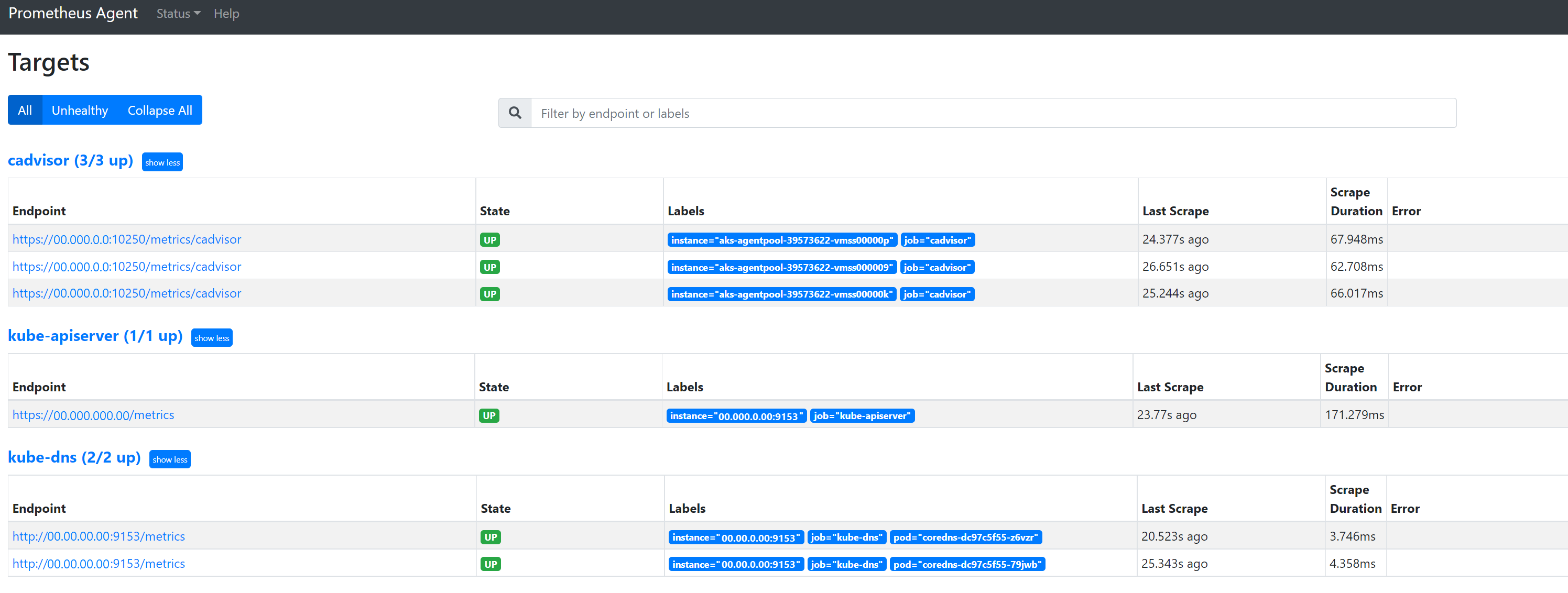



사용자 지정 리소스
- 사용자 지정 리소스를 포함했다면 구성, 서비스 검색 및 대상에서 표시되는지 확인합니다.
구성

서비스 검색

대상

문제가 없고 의도한 대상이 스크래핑되는 경우 디버그 모드를 사용하도록 설정하여 스크래핑되는 정확한 메트릭을 볼 수 있습니다.
디버그 모드
Warning
이 모드는 성능에 영향을 줄 수 있으며 디버깅 목적으로 짧은 시간 동안만 사용하도록 설정해야 합니다.
여기의 지침에 따라 debug-mode 아래의 configmap 설정 enabled을 true로 변경하여 디버그 모드에서 실행되도록 메트릭 추가 기능을 구성할 수 있습니다.
사용하도록 설정하면 스크래핑된 모든 Prometheus 메트릭이 포트 9091에서 호스트됩니다. 다음 명령을 실행합니다.
kubectl port-forward <ama-metrics pod name> -n kube-system 9091
브라우저에서 127.0.0.1:9091/metrics로 이동하여 메트릭이 OpenTelemetry 수집기에서 스크래핑되었는지 확인합니다. 이 사용자 인터페이스는 모든 ama-metrics-* Pod에 대해 액세스할 수 있습니다. 메트릭이 없으면 메트릭 또는 레이블 이름 길이나 레이블 수에 문제가 있을 수 있습니다. 또한 이 문서에 지정된 대로 Prometheus 메트릭에 대한 수집 할당량을 초과하는지 확인합니다.
메트릭 이름, 레이블 이름 및 레이블 값
메트릭 스크래핑에는 현재 다음 표와 같은 제한 사항이 있습니다.
| 속성 | 제한 |
|---|---|
| 레이블 이름 길이 | 511자 이하. 작업의 시계열에 대해 이 제한이 초과되면 전체 스크래핑 작업이 실패하고 수집 전에 해당 작업에서 메트릭이 삭제됩니다. 해당 작업에 대해 up=0을 볼 수 있으며 대상 Ux는 up=0에 대한 이유를 표시합니다. |
| 레이블 값 길이 | 1023자 이하. 작업의 시계열에 대해 이 제한이 초과되면 전체 스크래핑이 실패하고 수집 전에 해당 작업에서 메트릭이 삭제됩니다. 해당 작업에 대해 up=0을 볼 수 있으며 대상 Ux는 up=0에 대한 이유를 표시합니다. |
| 시계열당 레이블 수 | 63개 이하. 작업의 시계열에 대해 이 제한이 초과되면 전체 스크래핑 작업이 실패하고 수집 전에 해당 작업에서 메트릭이 삭제됩니다. 해당 작업에 대해 up=0을 볼 수 있으며 대상 Ux는 up=0에 대한 이유를 표시합니다. |
| 메트릭 이름 길이 | 511자 이하. 작업의 시계열에 대해 이 제한이 초과되면 해당 특정 열만 삭제됩니다. MetricextensionConsoleDebugLog에는 삭제된 메트릭에 대한 추적이 있습니다. |
| 대/소문자가 다른 레이블 이름 | 동일한 메트릭 샘플 내에 있는 대/소문자가 다른 두 레이블은 중복 레이블로 처리되고 수집될 때 삭제됩니다. 예를 들어, ExampleLabel 및 examplelabel이 동일한 레이블 이름으로 표시되므로 중복 레이블로 인해 시계열 my_metric{ExampleLabel="label_value_0", examplelabel="label_value_1}이 삭제됩니다. |
Azure Monitor 작업 영역에서 수집 할당량 확인
메트릭이 누락된 경우 먼저 Azure Monitor 작업 영역에 대한 수집 제한을 초과하는지 확인할 수 있습니다. Azure Portal에서 Azure Monitor 작업 영역에 대한 현재 사용량을 확인할 수 있습니다. Azure Monitor 작업 영역의 Metrics 메뉴에서 현재 사용 현황 메트릭을 볼 수 있습니다. 다음 사용 현황 메트릭은 각 Azure Monitor 작업 영역에 대한 표준 메트릭으로 사용할 수 있습니다.
- 활성 시계열 - 이전 12시간 동안 작업 영역으로 최근에 수집된 고유한 시계열 수
- 활성 시계열 제한 - 작업 영역에 적극적으로 수집할 수 있는 고유한 시계열 수에 대한 제한
- 활성 시계열 사용률(%) - 현재 사용 중인 활성 시계열의 백분율
- 수집된 분당 이벤트 - 최근에 받은 분당 이벤트(샘플) 수
- 수집된 분당 이벤트 제한 - 제한되기 전에 수집할 수 있는 분당 최대 이벤트 수
- 수집된 분당 이벤트 사용률(%) - 사용 중인 현재 메트릭 수집 속도 제한의 백분율
메트릭 수집 제한을 방지하려면 수집 제한에 대한 경고를 모니터링하고 설정할 수 있습니다. 모니터링 수집 제한을 참조하세요.
기본 할당량에 대한 서비스 할당량 및 제한을 참조하고 사용량에 따라 늘릴 수 있는 항목도 이해합니다. Azure Monitor 작업 영역의 Support Request 메뉴를 사용하여 Azure Monitor 작업 영역에 대한 할당량 증가를 요청할 수 있습니다. Azure Portal의 Azure Monitor 작업 영역에 대한 '속성' 메뉴에서 찾을 수 있는 지원 요청에 Azure Monitor 작업 영역에 대한 ID, 내부 ID 및 위치/지역을 포함해야 합니다.
Azure Policy 평가로 인해 Azure Monitor 작업 영역을 만들지 못했습니다.
"리소스 'resource-name-xyz' 정책이 허용되지 않음"이라는 오류와 함께 Azure Monitor 작업 영역을 만드는 데 실패하면 리소스를 만들지 못하게 하는 Azure 정책이 있을 수 있습니다. Azure 리소스 또는 리소스 그룹에 대한 명명 규칙을 적용하는 정책이 있는 경우 Azure Monitor 작업 영역을 만들기 위한 명명 규칙에 대한 예외를 만들어야 합니다.
Azure Monitor 작업 영역을 만들 때 기본적으로 "azure-monitor-workspace-name" 형식의 데이터 수집 규칙 및 데이터 수집 엔드포인트는 "MA_azure-monitor-workspace-name_location_managed" 형식의 리소스 그룹에 자동으로 만들어집니다. 현재 이러한 리소스의 이름을 변경할 수 있는 방법은 없으며 위의 리소스를 정책 평가에서 제외하려면 Azure Policy에 대한 예외를 설정해야 합니다. Azure Policy 예외 구조를 참조하세요.