이 문서에서는 Azure Monitor 플랫폼 메트릭 및 사용자 지정 메트릭을 지원하는 시계열 데이터베이스의 메트릭 집계에 대해 설명합니다. 이 문서는 표준 Application Insights 메트릭에도 적용됩니다.
이 문서의 이 정보는 복잡하며 메트릭 시스템에 대해 자세히 알아보려는 사용자를 위해 제공된 것입니다. Azure Monitor 메트릭을 효과적으로 사용하기 위해 이 내용을 이해할 필요는 없습니다.
개요 및 용어
차트에 메트릭을 추가하면 메트릭 탐색기는 기본 집계를 자동으로 미리 선택합니다. 기본값이 기본 시나리오에서는 의미가 있지만 다른 집계를 사용하면 메트릭에 대해 더 많은 인사이트를 얻을 수 있습니다. 차트에서 다른 집계를 보려면 메트릭 탐색기에서 집계가 처리되는 방식을 이해해야 합니다.
우선 몇 가지 용어를 명확하게 정의해보겠습니다.
- 메트릭 값 – 특정 리소스에 대해 수집된 단일 측정 값입니다.
- 시계열 데이터베이스 -값 및 값에 해당하는 타임스탬프를 포함하는 데이터 요소를 저장하고 검색하는 데 최적화된 데이터베이스입니다.
- 기간 – 일반적인 기간입니다.
- 시간 간격 – 두 메트릭 값을 수집한 시간 사이의 간격입니다.
- 시간 범위 – 차트에 표시되는 기간입니다. 일반적인 기본값은 24시간입니다. 특정 범위만 사용할 수 있습니다.
- 시간 단위 또는 시간 조직 – 차트에 표시할 수 있도록 값을 함께 집계하는 데 사용되는 기간입니다. 특정 범위만 사용할 수 있습니다. 현재 최솟값은 1분입니다. 시간 단위 값이 유용하려면 선택한 시간 범위보다 작아야 합니다. 그렇지 않으면 전체 차트에 값이 하나만 표시됩니다.
- 집계 유형 – 여러 메트릭 값에서 계산되는 통계의 유형입니다.
- 집계 – 여러 입력 값을 가져온 다음, 그 값을 사용하여 집계 유형으로 정의된 규칙을 통해 단일 출력 값을 생성하는 프로세스입니다. 예를 들어 여러 값의 평균을 내는 경우가 있습니다.
프로세스 요약
메트릭은 타임스탬프와 함께 저장되는 일련의 값입니다. Azure에서 대부분의 메트릭은 Azure 메트릭 시계열 데이터베이스에 저장됩니다. 차트를 그리면 선택한 메트릭의 값이 데이터베이스에서 검색된 다음, 선택한 시간 단위(다른 이름: 시간 조직)에 따라 개별적으로 집계됩니다. 시간 단위의 크기는 메트릭 탐색기의 시간 선택기를 사용하여 선택합니다. 명시적으로 선택하지 않으면 현재 선택한 시간 범위에 따라 시간 세분성이 자동으로 선택됩니다. 일단 선택되면, 각 시간 단위 간격 중에 캡처된 메트릭 값이 집계되어 차트에 배치됩니다(간격 당 하나의 데이터 요소).
집계 형식
메트릭 탐색기에는 5가지 기본 집계 형식이 있습니다. 메트릭 탐색기는 관련성이 없고 지정된 메트릭에 사용할 수 없는 집계를 숨깁니다.
- 합계 – 집계 간격 동안 캡처된 모든 값의 합계입니다. 총 집계라고 하는 경우도 있습니다.
- 개수 – 집계 간격 동안 캡처된 측정 수입니다. 개수는 측정 값이 아니라 레코드 수만 확인합니다.
- 평균 – 집계 간격 동안 캡처된 메트릭 값의 평균입니다. 대부분의 메트릭에서 이 값은 합계/개수입니다.
- 최소 – 집계 간격 동안 캡처된 가장 작은 값입니다.
- 최대 – 집계 간격 동안 캡처된 가장 큰 값입니다.
예를 들어 차트가 지난 24시간 동안의 SUM 집계를 사용하여 VM에 대한 전체 네트워크 출력 메트릭을 표시한다고 가정합니다. 시간 범위와 단위는 차트의 오른쪽 상단에서 변경할 수 있습니다. 다음 스크린샷을 참조하세요.
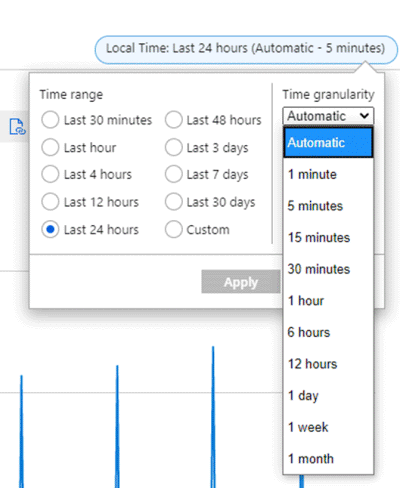
시간 단위 = 30분 및 시간 범위 = 24시간인 경우:
- 차트는 48개의 데이터 요소로 그려집니다. 즉, 24시간 동안 매 시간 60분/30분 간격으로 수집된 데이터 요소 2개가 모여 1-분 간격의 데이터 요소로 집계됩니다.
- 꺾은선형 차트는 차트 그림 영역에서 48개의 점을 연결합니다.
- 각 데이터 요소는 관련된 30분이라는 기간 동안 전송된 모든 네트워크 출력 바이트의 합계를 나타냅니다.

이 섹션의 이미지를 클릭하면 더 큰 버전을 볼 수 있습니다.
시간 단위를 15분으로 전환하면 집계 데이터 요소 96개로 차트가 그려집니다. 즉, 60분/15분 = 시간당 데이터 요소 4개 x 24시간입니다.

시간 단위가 5분이면 24 x (60/5) = 288개 점이 표시됩니다.
시간 단위가 1분(차트에서 가능한 최소 단위)이면 24 x 60/1 = 1440개 점이 표시됩니다.

이러한 요약에 대한 차트는 이전 스크린샷과는 다르게 보입니다. 나머지 기간에 비해 이 VM은 짧은 기간에 많은 출력이 있는 것을 볼 수 있습니다.
시간 단위를 사용하면 차트에서 "신호 대 노이즈" 비율을 조정할 수 있습니다. 집계 수가 많을수록 노이즈가 제거되고 급증이 평활하게 됩니다. 하단 1분 차트의 변동이 세분화된 값으로 갈수록 어떻게 부드럽게 변하는지 볼 수 있습니다.
이러한 평활 동작은 이 데이터를 다른 시스템(예: 경고)에 보낼 때 중요합니다. 보통은 CPU 시간이 90%를 넘긴 짧은 순간에는 경고를 원하지 않습니다. 하지만 CPU가 5분 동안 90%로 유지된다면 중요할 수 있습니다. CPU(또는 다른 메트릭)에 대한 경고 규칙을 설정하는 경우, 시간 단위를 더 크게 설정할수록 잘못된 경고를 받는 횟수를 줄일 수 있습니다.
가장 적합한 시간 간격을 파악하려면 워크로드에 대해 "보통"을 설정하는 것이 중요합니다. 이것은 동적 경고의 이점 중 하나이며, 여기에서는 다루지 않는 다른 주제입니다.
시스템이 메트릭을 수집하는 방식
데이터 수집은 메트릭에 따라 다릅니다.
비고
아래 예제는 설명을 위해 단순화했으며, 각 집계에 포함된 실제 지표 데이터는 평가가 발생할 때 사용 가능한 데이터의 영향을 받습니다.
측정값 수집 빈도
수집 기간에는 두 가지 유형이 있습니다.
정기 - 변하지 않는 일관된 시간 간격으로 메트릭이 수집됩니다.
활동 기반 - 특정 유형의 트랜잭션이 발생하는 시점을 기반으로 메트릭이 수집됩니다. 각 트랜잭션에는 메트릭 항목과 타임스탬프가 있습니다. 정기적인 간격으로 수집되지 않기 때문에 주어진 기간 동안 다양한 수의 레코드가 있습니다.
세분성
최소 시간 단위는 1분이지만 내부 시스템은 메트릭에 따라 데이터를 더 빠르게 캡처할 수 있습니다. 예를 들어 Azure VM의 CPU 백분율은 15초 간격으로 캡처됩니다. HTTP 오류는 트랜잭션으로 추적되기 때문에 분당 1회 이상을 쉽게 초과할 수 있습니다. SQL Storage와 같은 기타 메트릭은 20분 간격으로 캡처됩니다. 이런 선택은 개별 리소스 공급자 및 유형에 달려 있습니다. 대부분 가능한 최소 시간 간격을 제공하려고 합니다.
차원, 분할 및 필터링
메트릭은 각 개별 리소스에 대해 캡처됩니다. 하지만 메트릭이 수집, 저장 및 차트로 작성될 수 있는 수준은 다를 수 있습니다. 이 수준은 메트릭 차원에서 사용할 수 있는 다른 메트릭으로 표시됩니다. 각 개별 리소스 공급자는 수집하는 데이터의 상세한 정도를 정의합니다. Azure Monitor는 그러한 세부 정보를 표시하고 저장하는 방식만 정의합니다.
메트릭 탐색기에서 메트릭을 차트로 작성할 때 차원별로 차트를 "분할"하는 옵션이 있습니다. 차트를 분할하면 내부 데이터에서 보다 자세한 정보를 살펴보고 이러한 데이터가 메트릭 탐색기에서 차트로 작성되거나 필터링되는 것을 볼 수 있습니다.
예를 들어 Microsoft.ApiManagement/service에는 여러 메트릭에 대한 차원으로 위치(Location)가 있습니다.
용량은 그러한 메트릭 중 하나입니다. 위치(Location) 차원이 있다는 것은 내부 시스템이 메트릭 레코드를 총량에 대해 하나만 저장하는 게 아니라 각 위치의 용량에 대해 저장한다는 의미입니다. 그러면 해당 정보를 메트릭 차트에서 검색하거나 분할할 수 있습니다.
게이트웨이 요청의 전체 지속 시간을 살펴보면 위치(Location)와 호스트 이름(Hostname)이라는 두 가지 차원이 있습니다. 이를 통해 지속 시간의 위치와 요청을 보낸 호스트 이름을 알 수 있습니다.
보다 유연한 메트릭 중 하나인 요청에는 7가지 다른 차원이 있습니다.
Azure Monitor 문서를 통해 지원되는 메트릭에서 각 메트릭 및 사용 가능한 차원에 대한 세부 정보를 확인합니다. 또한 각 리소스 공급자와 유형에 대한 설명서에는 차원 및 측정 항목에 대한 추가 정보가 제공될 수 있습니다.
분할과 필터링을 함께 사용하여 문제를 자세히 알아볼 수 있습니다. 다음은 리소스 그룹의 VM 그룹에 대한 평균 디스크 쓰기 바이트(Avg Disk Write Bytes)를 보여주는 그래픽의 예입니다. 이 메트릭을 사용하는 모든 VM의 롤업이 있지만 오전 6시경 정점의 원인을 알아보고 싶을 수 있습니다. 동일한 머신인가요? 얼마나 많은 머신이 관련되어 있나요?

이 섹션의 이미지를 클릭하면 더 큰 버전을 볼 수 있습니다.
분할을 적용하면 내부 데이터를 볼 수 있지만 약간 엉망인 상태입니다. 위의 차트로 집계되는 VM은 20개입니다. 이 경우 오전 6시 큰 정점을 마우스로 가리키면 CH-DCVM11이 원인임을 알려줍니다. 하지만 이 VM과 연결된 나머지 데이터를 보기가 어렵습니다. 다른 VM 때문에 차트가 복잡하기 때문입니다.

필터링을 사용하면 차트를 정리하여 실제로 무슨 일이 일어나고 있는지 볼 수 있습니다. 보려는 VM을 선택하거나 선택 취소할 수 있습니다. 점선이 있는 것을 확인하세요. 이 내용은 이후 섹션에 설명되어 있습니다.

메트릭 탐색기 차트에 분할 차원 데이터를 표시하는 방법에 대한 자세한 내용은 차원 필터 및 분할 사용을 참조하세요.
NULL 및 0 값
시스템에 리소스의 메트릭 데이터가 필요한데 받지 못하면 NULL 값이 기록됩니다. NULL은 0 값과 다르며, 집계 및 차트 계산에서 중요합니다. NULL 값은 유효한 측정값으로 계산되지 않습니다.
Null은 차트마다 다르게 표시됩니다. 산점도는 차트에 점이 표시되지 않습니다. 가로 막대형 차트에는 막대가 표시되지 않습니다. 꺾은선형 차트에서 NULL은 점선 또는 파선으로 나타날 수 있습니다. 이전 섹션의 스크린샷을 참조하십시오. NULL이 포함된 평균을 계산하는 경우, 평균을 구하는 데이터 요소가 줄어듭니다. 값이 0으로 변환되어 유효한 데이터 요소로 사용되는 경우 보다는 적지만 이런 동작으로 인해 차트의 값이 예기치 않게 떨어질 수 있습니다.
사용자 지정 메트릭은 데이터를 받지 못하면 항상 NULL을 사용합니다. 플랫폼 메트릭을 사용하는 경우 주어진 메트릭에 무엇이 가장 적합할지를 기반으로 0 또는 NULL 중에 무엇을 사용할지를 각 리소스 공급자가 결정합니다.
Azure Monitor 경고는 리소스 공급자가 메트릭 데이터베이스에 기록하는 값을 사용하기 때문에 데이터를 먼저 확인하여 리소스 공급자가 NULL을 처리하는 방식을 알고 있어야 합니다.
집계 원리
이전 시스템의 메트릭 차트는 다양한 유형의 집계 데이터를 보여줍니다. 시스템은 데이터를 사전 집계하여 반복 계산을 많이 하지 않고 요청된 차트가 더 빨리 표시될 수 있도록 합니다.
이 예제에서:
- HTTP 오류라는 가상의 트랜잭션 메트릭을 수집
- 서버는 HTTP 오류 메트릭의 차원입니다.
- 서버 A, B, C라는 3개의 서버가 있습니다.
간단한 설명을 위해 SUM 집계 유형으로만 시작하겠습니다.
1분 미만 항목을 1-분으로 집계
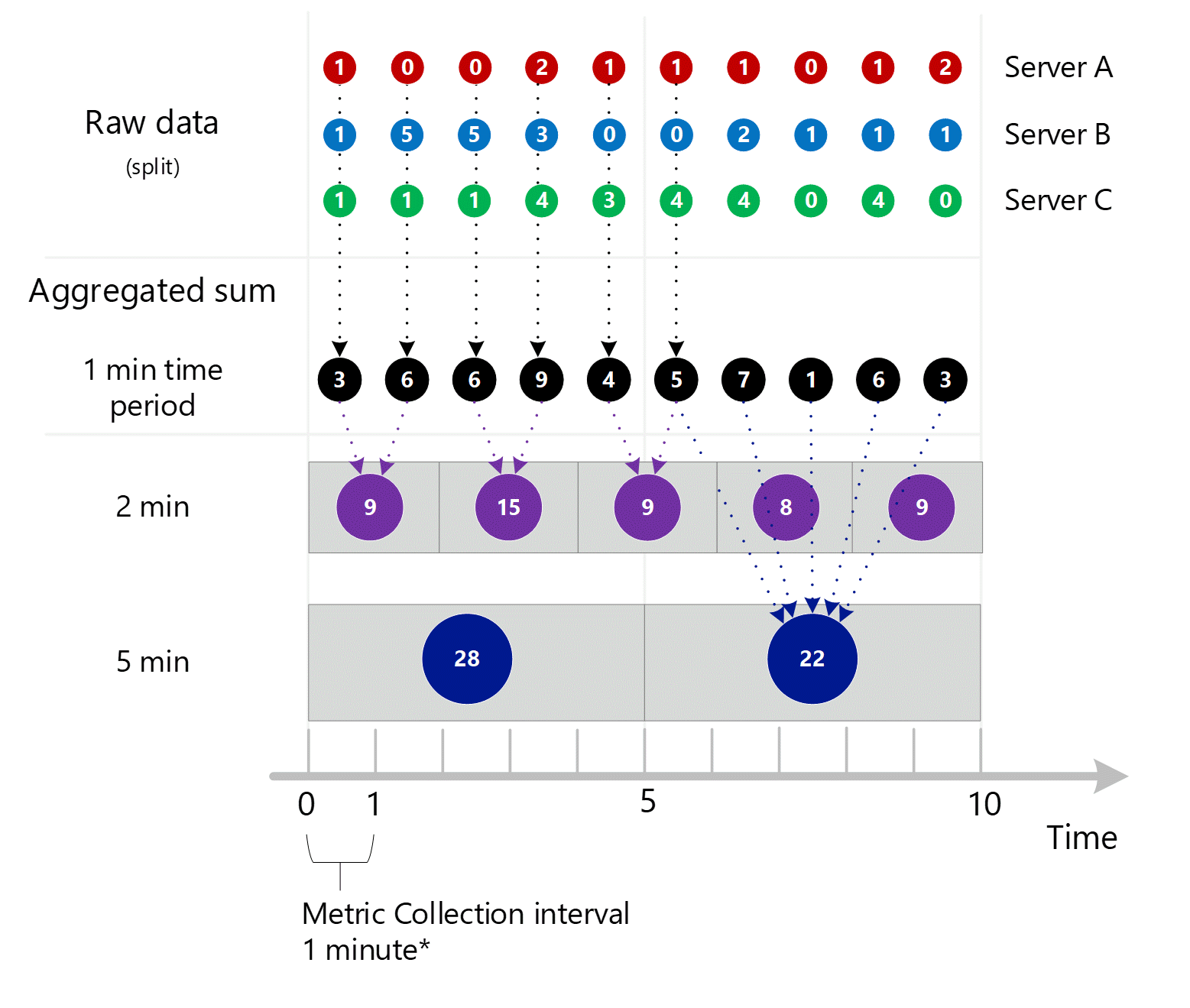
첫 번째 원시 메트릭 데이터가 수집되어 Azure Monitor 메트릭 데이터베이스에 저장됩니다. 이 경우 각 서버에는 타임스탬프와 함께 저장된 트랜잭션 레코드가 있습니다. 서버는 차원이기 때문입니다. 고객이 볼 수 있는 최소 기간이 1분이라는 점을 감안하여, 타임스탬프는 먼저 각 개별 서버에 대한 1-분 메트릭 값으로 집계됩니다. 서버 B에 대한 집계 프로세스는 아래 그림에 나와 있습니다. 서버 A와 C는 동일한 방식으로 수행되며 다른 데이터를 포함합니다.
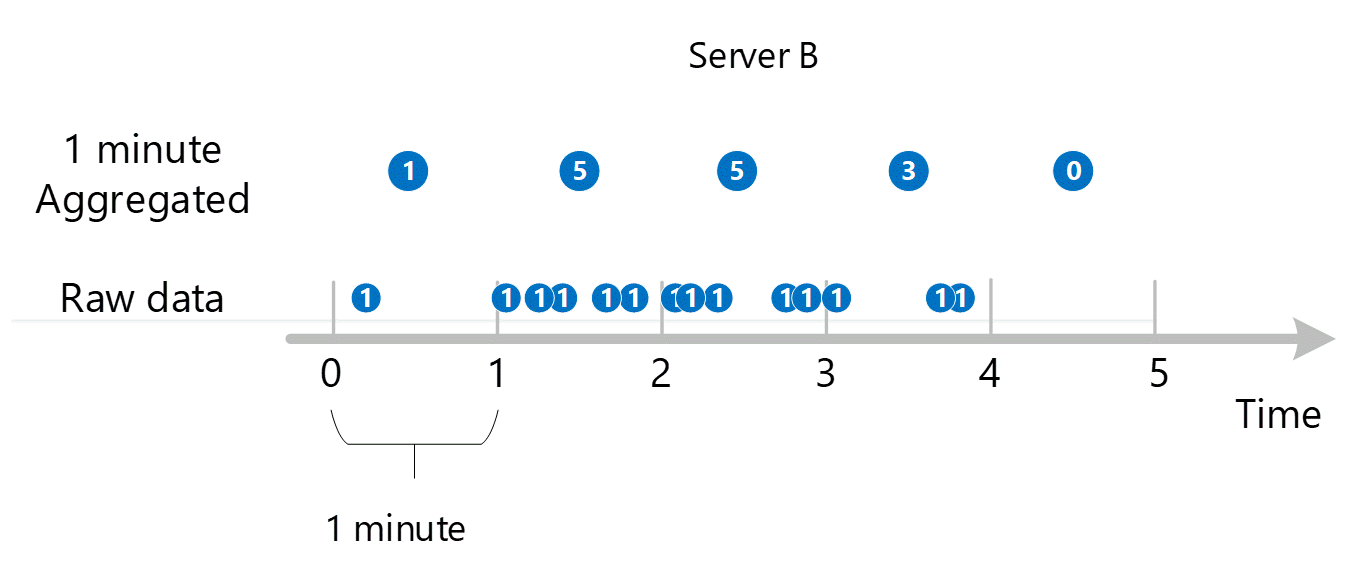
결과 1-분 집계 값은 메트릭 데이터베이스에 새 항목으로 저장되므로 나중에 계산을 위해 수집할 수 있습니다.
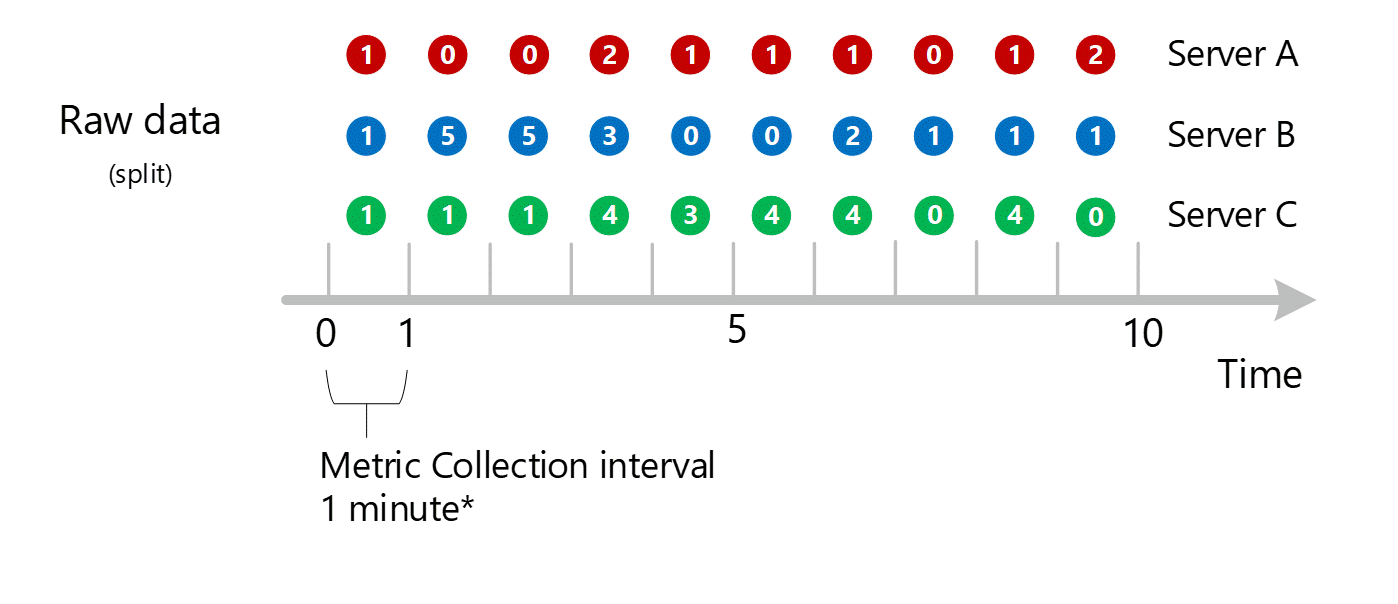
차원 집계
1-분 계산은 차원별로 축소되고 다시 개별 레코드로 저장됩니다. 이 경우 모든 개별 서버의 모든 데이터는 1-분 간격 메트릭에 집계되고 나중에 집계에 사용할 수 있도록 메트릭 데이터베이스에 저장됩니다.
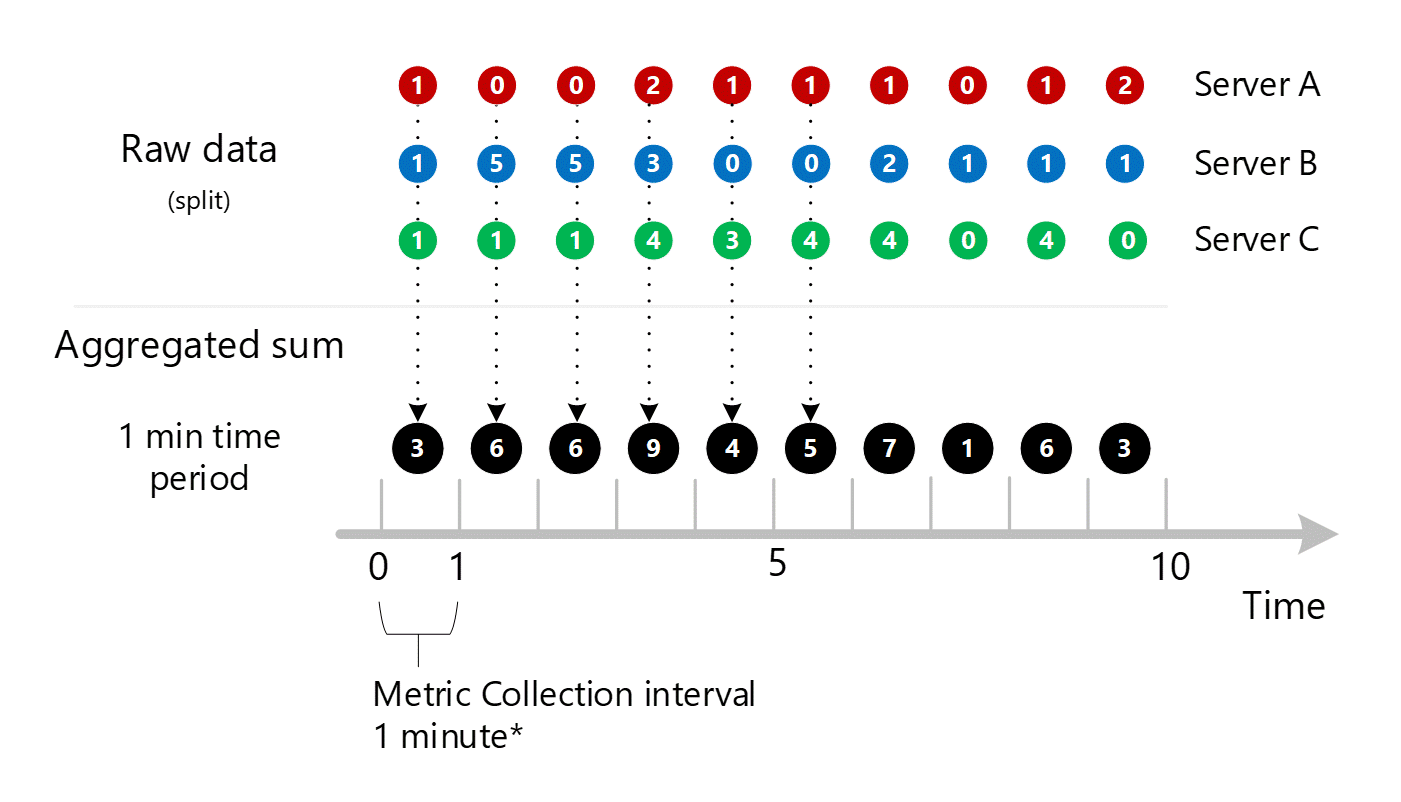
명확하게 하기 위해, 다음 표에서 집계 방법을 참조하세요.
| 기간 | 서버 A | 서버 B | 서버 C | 합계(A+B+C) |
|---|---|---|---|---|
| 분 1 | 1 | 1 | 1 | 3 |
| 2분 | 0 | 5 | 1 | 6 |
| 분 3 | 0 | 5 | 1 | 6 |
| 분 4 | 2 | 3 | 4 | 9 |
| 분 5 | 1 | 0 | 3 | 4 |
| 분 6 | 1 | 0 | 4 | 5 |
| 분 7 | 1 | 2 | 4 | 7 |
| 분 8 | 0 | 1 | 0 | 1 |
| 분 9 | 1 | 1 | 4 | 6 |
| 분 10 | 2 | 1 | 0 | 3 |
위에는 차원이 하나만 표시되어 있지만, 동일한 집계 및 스토리지 프로세스가 메트릭이 지원하는 모든 차원에 대해 발생합니다.
- 해당 차원별 1-분 집계 집합으로 값을 수집합니다. 이러한 값을 저장합니다.
- 차원을 1-분 집계 SUM으로 축소합니다. 이러한 값을 저장합니다.
NetworkAdapter라는 HTTP 오류의 또 다른 차원을 소개하겠습니다. 서버당 어댑터 수가 다양하다고 가정해보겠습니다.
- 서버 A에는 어댑터가 1개 있습니다.
- 서버 B에는 어댑터가 2개 있습니다.
- 서버 C에는 어댑터가 3개 있습니다.
다음 트랜잭션에 대한 데이터를 별도로 수집합니다. 다음과 같이 표시됩니다.
- 시간
- 값
- 트랜잭션이 발생한 서버
- 트랜잭션이 발생한 어댑터
각각의 1분 미만 스트림은 1-분 시계열 값으로 집계되고 Azure Monitor 메트릭 데이터베이스에 저장됩니다.
- 서버 A, 어댑터 1
- 서버 B, 어댑터 1
- 서버 B, 어댑터 2
- 서버 C, 어댑터 1
- 서버 C, 어댑터 2
- 서버 C, 어댑터 3
또한 다음과 같은 축소된 집계도 저장됩니다.
- 서버 A, 어댑터 1(축소할 항목이 없으므로 다시 저장됨)
- 서버 B, 어댑터 1 + 2
- 서버 C, 어댑터 1 + 2 + 3
- 서버 모두, 어댑터 모두
이를 통해, 메트릭의 차원 수가 많을수록 집계 수가 많다는 것을 알 수 있습니다. 모든 순열을 파악할 필요는 없으며 원리만 이해하면 됩니다. 시스템은 모든 차트에 액세스하는 빠른 검색을 위해 개별 데이터와 집계 데이터를 모두 저장하려고 합니다. 표시하도록 선택한 항목에 따라 시스템은 가장 관련성이 높은 저장된 집계 데이터 또는 내부 원시 데이터를 선택합니다.
차원이 없는 집계
이 메트릭에는 서버라는 차원이 있으므로, 이 문서 앞부분에서 설명한 대로 분할 및 필터링을 통해 위의 서버 A, B, C에 대한 내부 데이터를 가져올 수 있습니다. 메트릭에 서버라는 차원이 없으면 고객은 집계된 1-분 합계(다이어그램에 검은 색으로 표시됨)에만 액세스할 수 있습니다. 즉, 3, 6, 6, 9 등의 값을 말합니다. 또한 시스템은 분할 값을 집계하기 위한 내부 작업을 수행하지 않으며 해당 값을 메트릭 탐색기에서 사용하거나 메트릭 REST API를 통해 전송하지 않습니다.
1분 이상 세분 시간 보기
메트릭을 더 큰 단위로 요청하면 시스템은 1-분 집계의 합계를 사용하여 더 큰 시간 단위의 합계를 계산합니다. 아래 점선은 2-분 및 5-분 시간 단위를 위한 합계 방법을 보여줍니다. 여기서는 간단하게 SUM 집계 유형만 보여줍니다.
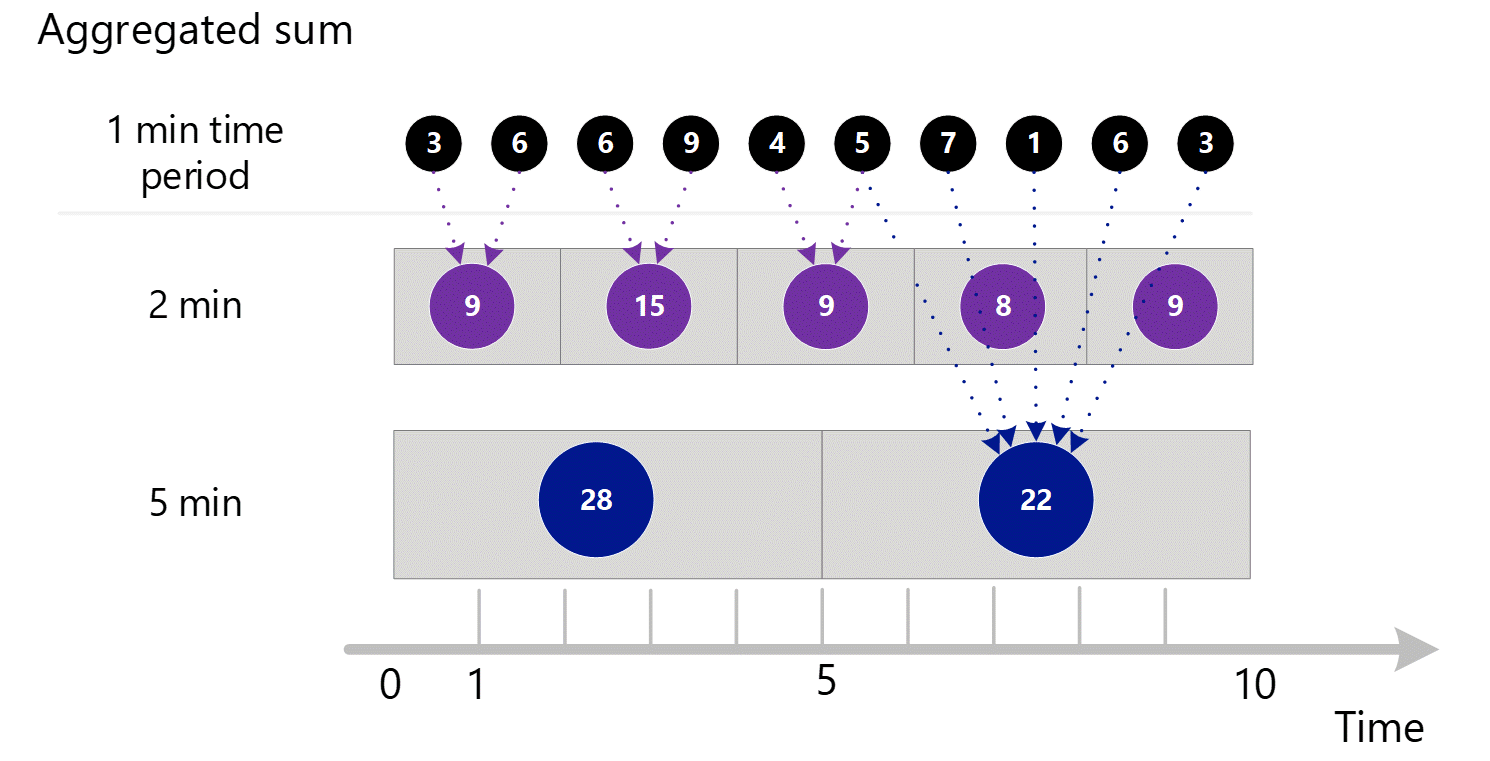
2-분 시간 단위는 다음과 같습니다.
| 기간 | 합계 |
|---|---|
| 분 1 및 2 | (3 + 6) = 9 |
| 분 3 및 4 | (6 + 9) = 15 |
| 분 4 및 5 | (4 + 5) = 9 |
| 분 6 및 7 | (7 + 1) = 8 |
| 분 8 및 9 | (6 + 3) = 9 |
5분 단위의 시간 정밀도를 위해서입니다.
| 기간 | 합계 |
|---|---|
| 분 1에서 5까지 | 3 + 6 + 6 + 9 + 4 = 28 |
| 분 6에서 10까지 | 5 + 7 + 1 + 6 + 3 = 22 |
시스템은 최적의 성능을 제공하는 저장된 집계 데이터를 사용합니다.
아래는 위의 1-분 집계 프로세스에 대한 더 큰 다이어그램이며, 가독성을 높이기 위해 일부 화살표는 생략했습니다.
더 복잡한 예제
다음은 HTTP 응답 시간(밀리초)이라는 가상의 메트릭 값을 사용하는 더 큰 예제입니다. 여기서는 다른 수준의 복잡성을 소개합니다.
- 합계, 개수, 최소 및 최대에 대한 집계와 평균에 대한 계산을 보여줍니다.
- NULL 값 및 이 값이 계산에 미치는 영향을 보여줍니다.
다음 예제를 고려해 보세요. 상자와 화살표는 값이 집계되고 계산되는 방식의 예를 보여줍니다.
이전 섹션에서 설명한 것과 동일한 1-분 사전 집계 프로세스가 합계, 개수, 최소 및 최대에 대해 발생합니다. 그러나 평균은 사전 집계되지 않습니다. 계산 오류를 방지하기 위해 집계된 데이터를 사용하여 다시 계산됩니다.

위를 살펴보면 1-분 집계의 분 6이 강조 표시되어 있습니다. 이 분은 서버 B가 오프라인 상태가 되어 데이터 보고를 중지한 시점입니다(재부팅 때문일 수 있음).
6분부터 계산된 1분 집계 유형은 다음과 같습니다.
| 집계 유형 | 가치 | 비고 |
|---|---|---|
| 합계 | 53+20=73 | |
| 수량 | 2 | Null의 효과를 보여줍니다. 서버가 온라인 상태였다면 값은 3이 됩니다. |
| 최소 | 20 | |
| 최대 | 53 | |
| 평균 | 73 / 2 | 언제나 합계를 개수로 나눈 값입니다. 저장되는 경우가 없으며, 간격에 맞게 집계된 숫자를 사용하여 각 시간 간격에 대해 항상 다시 계산됩니다. 5-분 및 10-분 시간 단위에 대한 다시 계산이 위에 강조 표시되어 있습니다. |
빨간색 문자 색상은 정상 범위를 벗어났다고 간주될 수 있는 값을 나타내며, 시간이 더 세부적으로 구분될수록 그 값이 어떻게 전파되거나 전파에 실패하는지를 보여줍니다. 최소 및 최대는 내부적인 이상이 있음을 나타내며 평균 및 합계는 시간 단위가 올라갈수록 해당 정보를 잃게 됩니다.
또한, NULL은 0이 대신 사용된 경우보다 평균을 계산하는 데 유리한 것을 볼 수 있습니다.
비고
이 예의 경우는 아니지만 메트릭이 항상 값 1로 캡처되는 경우 개수와 합계가 같습니다. 이런 경우는 메트릭이 트랜잭션 이벤트의 발생을 추적하는 경우에 일반적입니다(예: 이 문서의 이전 예제에서 언급한 HTTP 오류 수).