중요합니다
Azure SQL Edge는 2025년 9월 30일부터 사용 중지됩니다. 자세한 내용 및 마이그레이션 옵션은 사용 중지 알림을 참조하세요.
비고
Azure SQL Edge는 더 이상 ARM64 플랫폼을 지원하지 않습니다.
이 자습서에서는 Azure Data Factory를 사용하여 Azure SQL Edge 인스턴스의 테이블에서 Azure Blob 스토리지로 데이터를 증분 방식으로 동기화하는 방법을 보여 줍니다.
시작하기 전 주의 사항:
Azure SQL Edge 배포에서 데이터베이스 또는 테이블을 아직 만들지 않은 경우 다음 방법 중 하나를 사용하여 만듭니다.
SQL Server Management Studio 또는 Azure Data Studio를 사용하여 SQL Edge에 연결합니다. SQL 스크립트를 실행하여 데이터베이스 및 테이블을 만듭니다.
SQL Edge 모듈에 직접 연결하여 sqlcmd를 통해 데이터베이스 및 테이블을 만듭니다. 자세한 내용은 sqlcmd를 사용하여 데이터베이스 엔진에 연결을 참조하세요.
SQLPackage.exe를 사용하여 DAC 패키지 파일을 SQL Edge 컨테이너에 배포합니다. 이 프로세스는 SqlPackage 파일 URI를 모듈의 desired 속성 구성의 일부로 지정하여 자동화할 수 있습니다. SqlPackage.exe 클라이언트 도구를 직접 사용하여 DAC 패키지를 SQL Edge에 배포할 수도 있습니다.
SqlPackage.exe를 다운로드하는 방법에 대한 자세한 내용은 sqlpackage 다운로드 및 설치를 참조하세요. SqlPackage.exe에 대한 몇 가지 샘플 명령은 다음과 같습니다. 자세한 내용은 SqlPackage.exe 설명서를 참조하세요.
DAC 패키지 만들기
sqlpackage /Action:Extract /SourceConnectionString:"Data Source=<Server_Name>,<port>;Initial Catalog=<DB_name>;User ID=<user>;Password=<password>" /TargetFile:<dacpac_file_name>DAC 패키지 적용
sqlpackage /Action:Publish /Sourcefile:<dacpac_file_name> /TargetServerName:<Server_Name>,<port> /TargetDatabaseName:<DB_Name> /TargetUser:<user> /TargetPassword:<password>
워터마크 수준을 저장하고 업데이트하는 SQL 테이블 및 프로시저 만들기
워터마크 테이블은 데이터가 Azure Storage와 이미 동기화된 마지막 타임스탬프를 저장하는 데 사용됩니다. T-SQL(Transact-SQL) 저장 프로시저는 동기화할 때마다 워터마크 테이블을 업데이트하는 데 사용됩니다.
SQL Edge 인스턴스에서 다음 명령을 실행합니다.
CREATE TABLE [dbo].[watermarktable] (
TableName VARCHAR(255),
WatermarkValue DATETIME,
);
GO
CREATE PROCEDURE usp_write_watermark @timestamp DATETIME,
@TableName VARCHAR(50)
AS
BEGIN
UPDATE [dbo].[watermarktable]
SET [WatermarkValue] = @timestamp
WHERE [TableName] = @TableName;
END
GO
Data Factory 파이프라인 만들기
이 섹션에서는 데이터를 Azure SQL Edge의 테이블에서 Azure Blob 스토리지로 동기화하는 Azure Data Factory 파이프라인을 만듭니다.
Data Factory UI를 사용하여 데이터 팩터리 만들기
이 자습서의 지침에 따라 데이터 팩터리를 만듭니다.
Data Factory 파이프라인 만들기
Data Factory UI의 시작 페이지에서 파이프라인 만들기를 선택합니다.

파이프라인에 대한 속성 창의 일반 페이지에서 이름으로 PeriodicSync를 입력합니다.
이전 워터마크 값을 가져오는 조회 작업을 추가합니다. 작업 창에서 일반을 펼치고, 조회 작업을 파이프라인 디자이너 화면으로 끕니다. 작업 이름을 OldWatermark로 변경합니다.
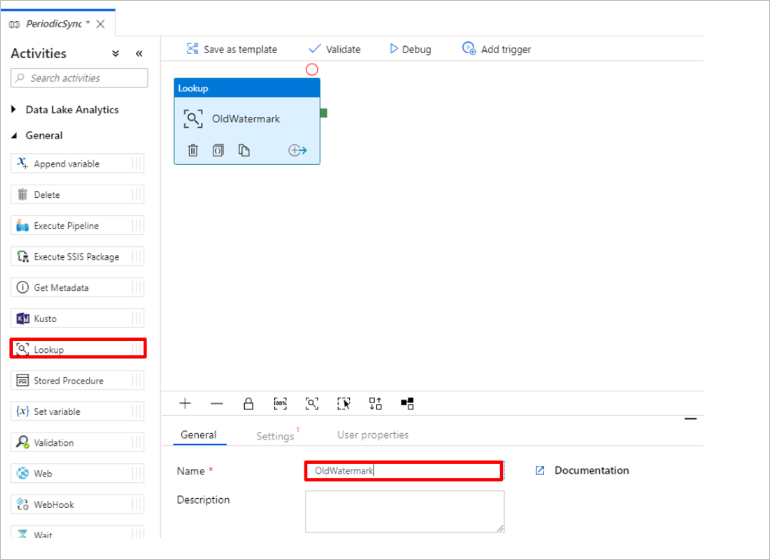
설정 탭으로 전환하고, 원본 데이터 세트에 대해 새로 만들기를 선택합니다. 이제 워터마크 테이블의 데이터를 나타내기 위한 데이터 세트를 만듭니다. 이 테이블에는 이전 복사 작업에서 사용된 이전 워터마크가 포함되어 있습니다.
새 데이터 세트 창에서 Azure SQL Server, 계속을 차례로 선택합니다.
데이터 세트에 대한 속성 설정 창의 이름 아래에서 WatermarkDataset를 입력합니다.
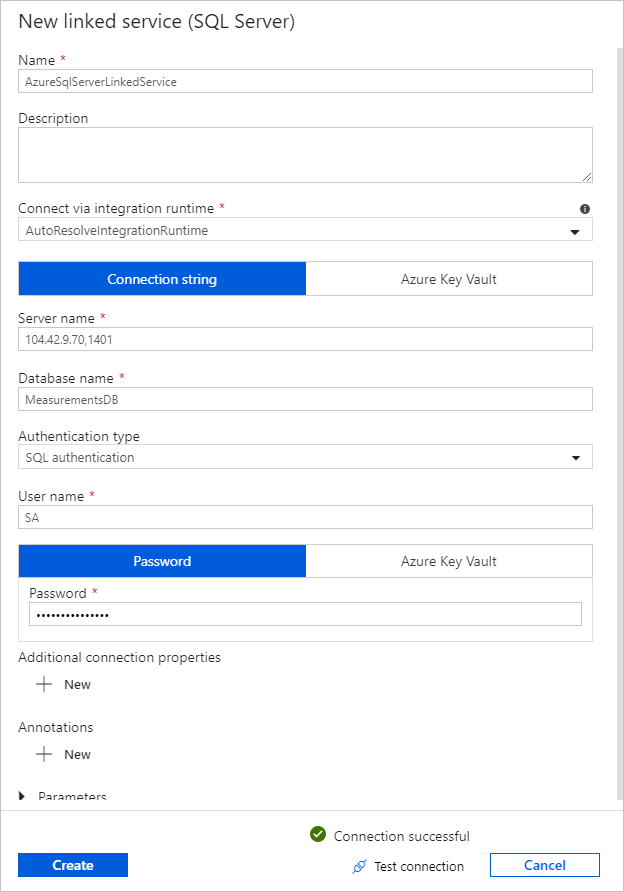
연결된 서비스에 대해 새로 만들기를 선택하고, 다음 단계를 수행합니다.
이름 아래에서 SQLDBEdgeLinkedService를 입력합니다.
서버 이름 아래에서 SQL Edge 서버 세부 정보를 입력합니다.
목록에서 데이터베이스 이름을 선택합니다.
사용자 이름 및 암호를 입력합니다.
SQL Edge 인스턴스에 대한 연결을 테스트하려면 연결 테스트를 선택합니다.
선택하고생성합니다.
확인을 선택합니다.
설정 탭에서 편집을 선택합니다.
연결 탭에서
[dbo].[watermarktable]에 대해 을 선택합니다. 테이블의 데이터를 미리 보려면 데이터 미리 보기를 선택합니다.위쪽의 파이프라인 탭을 선택하거나 왼쪽의 트리 뷰에서 파이프라인 이름을 선택하여 파이프라인 편집기로 전환합니다. 조회 작업에 대한 속성 창의 원본 데이터 세트 목록에 서 WatermarkDataset가 선택되어 있는지 확인합니다.
작업 창에서 일반을 펼치고, 조회 작업을 파이프라인 디자이너 화면으로 끕니다. 속성 창의 일반 탭에서 이름을 NewWatermark로 설정합니다. 이 조회 작업은 대상에 복사할 수 있도록 원본 데이터가 포함된 테이블에서 새 워터마크 값을 가져옵니다.
두 번째 조회 작업에 대한 속성 창에서 설정 탭으로 전환하고, 새로 만들기를 선택하여 새 워터마크 값이 포함된 원본 테이블을 가리키도록 데이터 세트를 만듭니다.
새 데이터 세트 창에서 SQL Edge 인스턴스, 계속을 차례로 선택합니다.
속성 설정 창의 이름 아래에서 SourceDataset를 입력합니다. 연결된 서비스 아래에서 SQLDBEdgeLinkedService를 선택합니다.
테이블 아래에서 동기화하려는 테이블을 선택합니다. 또한 이 자습서의 뒷부분에서 설명한 대로 이 데이터 세트에 대한 쿼리를 지정할 수도 있습니다. 쿼리는 이 단계에서 지정한 테이블보다 우선적으로 적용됩니다.
확인을 선택합니다.
위쪽의 파이프라인 탭을 선택하거나 왼쪽의 트리 뷰에서 파이프라인 이름을 선택하여 파이프라인 편집기로 전환합니다. 조회 작업에 대한 속성 창의 원본 데이터 세트 목록에서 SourceDataset가 선택되어 있는지 확인합니다.
쿼리 사용 아래에서 쿼리를 선택합니다. 다음 쿼리에서 테이블 이름을 업데이트한 다음, 쿼리를 입력합니다. 테이블에서
timestamp의 최댓값만 선택합니다. 첫 번째 행만을 선택해야 합니다.SELECT MAX(timestamp) AS NewWatermarkValue FROM [TableName];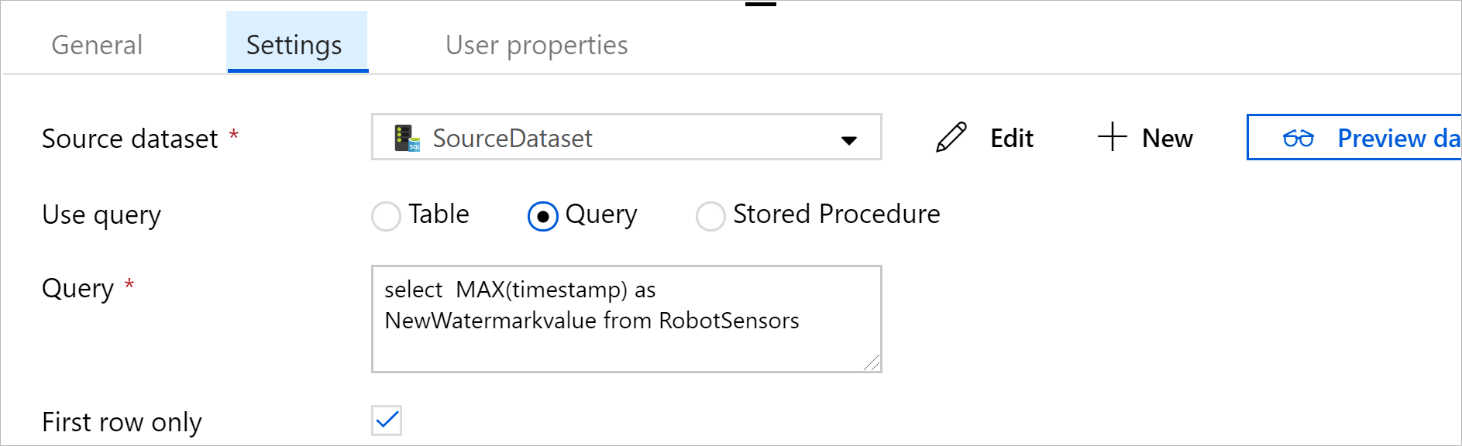
작업 창에서 이동 후 변환을 펼치고, 복사 작업을 작업창에서 디자이너 화면으로 끕니다. 작업 이름을 IncrementalCopy로 설정합니다.
조회 작업에 연결되는 녹색 단추를 [복사] 작업으로 끌어서 두 조회 작업을 복사 작업에 연결합니다. 복사 작업의 테두리 색이 파란색으로 변경되면 마우스 단추를 놓습니다.
복사 작업을 선택하고, 작업에 대한 속성이 속성 창에 표시되는지 확인합니다.
속성 창에서 원본 탭으로 전환하고 다음 단계를 수행합니다.
원본 데이터 세트 상자에서 SourceDataset를 선택합니다.
쿼리 사용 아래에서 쿼리를 선택합니다.
쿼리 상자에서 SQL 쿼리를 입력합니다. 샘플 쿼리는 다음과 같습니다.
SELECT * FROM TemperatureSensor WHERE timestamp > '@{activity(' OldWaterMark ').output.firstRow.WatermarkValue}' AND timestamp <= '@{activity(' NewWaterMark ').output.firstRow.NewWatermarkvalue}';싱크 탭의 싱크 데이터 세트 아래에서 새로 만들기를 선택합니다.
이 자습서에서 싱크 데이터 저장소는 Azure Blob 스토리지 데이터 저장소입니다. 새 데이터 세트 창에서 Azure Blob 스토리지, 계속을 차례로 선택합니다.
형식 선택 창에서 데이터 형식, 계속을 차례로 선택합니다.
속성 설정 창의 이름 아래에 SinkDataset를 입력합니다. 연결된 서비스 아래에서 새로 만들기를 선택합니다. 이제 Azure Blob 스토리지에 대한 연결(연결된 서비스)을 만듭니다.
새 연결된 서비스(Azure Blob 스토리지) 창에서 다음 단계를 수행합니다.
이름 상자에서 AzureStorageLinkedService를 입력합니다.
스토리지 계정 이름 아래에서 Azure 구독에 대한 Azure 스토리지 계정을 선택합니다.
연결을 테스트한 다음, 마침을 선택합니다.
속성 설정 창의 연결된 서비스 아래에서 AzureStorageLinkedService가 선택되어 있는지 확인합니다. 만들기 및 확인을 선택합니다.
싱크 탭에서 편집을 선택합니다.
SinkDataset의 연결 탭으로 이동하여 다음 단계를 수행합니다.
파일 경로에서
asdedatasync/incrementalcopy를 입력합니다. 여기서asdedatasync는 Blob 컨테이너 이름이고incrementalcopy는 폴더 이름입니다. 컨테이너가 없으면 새로 만들거나, 기존 컨테이너의 이름을 사용합니다.incrementalcopy출력 폴더가 없으면 Azure Data Factory에서 자동으로 만듭니다. 또한 파일 경로에 대한 찾아보기 단추를 사용하여 Blob 컨테이너의 폴더로 이동할 수도 있습니다.파일 경로의 파일 부분에서 동적 콘텐츠 추가[Alt+P]를 선택한 다음, 열린 창에서
@CONCAT('Incremental-', pipeline().RunId, '.txt')를 입력합니다. 완료를 선택합니다. 파일 이름은 식을 통해 동적으로 생성됩니다. 각 파이프라인 실행에는 고유한 ID가 있습니다. 복사 작업은 실행 ID를 사용하여 파일 이름을 생성합니다.
위쪽의 파이프라인 탭을 선택하거나 왼쪽의 트리 뷰에서 파이프라인 이름을 선택하여 파이프라인 편집기로 전환합니다.
작업 창에서 일반을 펼치고, 저장 프로시저 작업을 작업 창에서 파이프라인 디자이너 화면으로 끕니다. 복사 작업의 녹색(성공) 출력을 저장 프로시저 작업에 연결합니다.
파이프라인 디자이너에서 저장 프로시저 작업을 선택하고, 이름을
SPtoUpdateWatermarkActivity로 변경합니다.SQL 계정 탭으로 전환하고 연결된 서비스 아래에서 *QLDBEdgeLinkedService를 선택합니다.
저장 프로시저 탭으로 전환하고 다음 단계를 수행합니다.
저장 프로시저 이름에서
[dbo].[usp_write_watermark]를 선택합니다.저장 프로시저 매개 변수에 대한 값을 지정하려면 가져오기 매개 변수를 선택하고, 다음 매개 변수 값을 입력합니다.
이름 유형 가치 LastModifiedTime DateTime @{activity('NewWaterMark').output.firstRow.NewWatermarkvalue}TableName String @{activity('OldWaterMark').output.firstRow.TableName}파이프라인 설정에 대한 유효성을 검사하려면 도구 모음에서 유효성 검사를 선택합니다. 유효성 검사 오류가 없는지 확인합니다. 파이프라인 유효성 검사 보고서 창을 닫으려면 >>를 선택합니다.
모두 게시 단추를 선택하여 엔터티(연결된 서비스, 데이터 세트 및 파이프라인)를 Azure Data Factory 서비스에 게시합니다. 게시 작업이 성공했음을 확인하는 메시지가 표시될 때까지 기다립니다.
일정에 따라 파이프라인 트리거
파이프라인 도구 모음에서 트리거 추가, 새로 만들기/편집, 새로 만들기를 차례로 선택합니다.
트리거 이름을 HourlySync로 지정합니다. 형식 아래에서 일정을 선택합니다. 되풀이를 1시간 간격으로 설정합니다.
확인을 선택합니다.
모두 게시를 선택합니다.
지금 트리거를 선택합니다.
왼쪽의 모니터 탭으로 전환합니다. 수동 트리거로 트리거된 파이프라인 실행 상태를 볼 수 있습니다. 새로 고침을 선택하여 목록을 새로 고칩니다.
## 관련 콘텐츠
- 이 자습서의 Azure Data Factory 파이프라인은 데이터를 SQL Edge 인스턴스의 테이블에서 Azure Blob 스토리지의 위치로 1시간마다 한 번씩 복사합니다. 다른 시나리오에서 Data Factory를 사용하는 방법을 알아보려면 이 자습서를 참조하세요.