Azure Portal에서 단일 데이터베이스를 만들려면 다음을 수행합니다.
aka.ms/azuresqlhub Azure SQL 허브로 이동합니다.
Azure SQL Database 하이퍼스케일 창에서 만들기를 선택합니다.

SQL 데이터베이스 만들기 양식의 기본 탭에 있는 프로젝트 세부 정보 아래에서 원하는 Azure 구독을 선택합니다.
리소스 그룹의 경우 새로 만들기를 선택하고, myResourceGroup을 입력하고, 확인을 선택합니다.
데이터베이스 이름에 mySampleDatabase를 입력합니다.
서버에 대해 새로 만들기를 선택하고 새 서버 양식을 다음 값으로 입력합니다.
-
서버 이름: mysqlserver를 입력하고 고유하게 유지하기 위한 일부 문자를 추가합니다. 서버 이름은 구독 내에서 고유한 것이 아니라 Azure의 모든 서버에 대해 전역적으로 고유해야 하므로 사용할 정확한 서버 이름을 제공할 수 없습니다.
mysqlserver12345와 같은 이름을 입력하면 포털에서 사용할 수 있는지 알 수 있습니다.
-
서버 관리자 로그인: azureuser를 입력합니다.
-
암호: 요구 사항을 충족하는 암호를 입력하고, 암호 확인 필드에서 다시 입력합니다.
-
위치: 드롭다운 목록에서 위치를 선택합니다.
중요합니다
서버 관리자 로그인 이름 필드에 개인 정보, 중요한 정보 또는 기밀 정보를 포함하지 마세요. 이 필드에 입력된 데이터는 고객 데이터로 간주되지 않습니다.
확인을 선택합니다.
컴퓨팅 + 스토리지에서 데이터베이스 구성을 선택합니다.
이 빠른 시작에서는 하이퍼스케일 데이터베이스를 만듭니다.
서비스 계층의 경우 하이퍼스케일을 선택합니다.

컴퓨팅 하드웨어에서 구성 변경을 선택합니다. 사용 가능한 하드웨어 구성을 검토하고 데이터베이스에 가장 적합한 구성을 선택합니다. 이 예제에서는 표준 시리즈(Gen5) 구성을 선택합니다.
확인을 선택하여 하드웨어 생성을 확인합니다.
필요에 따라 데이터베이스의 vCore 수를 늘리려면 vCore 슬라이더를 조정합니다. 이 예제에서는 2 vCores를 선택합니다.
고가용성 보조 복제본 슬라이더를 조정하여 HA(고가용성) 복제본 하나를 만듭니다.
적용을 선택합니다.
하이퍼스케일 데이터베이스를 만들 때 백업 스토리지 중복도에 대한 구성 옵션을 신중하게 고려합니다. 스토리지 중복성은 하이퍼스케일 데이터베이스에 대한 데이터베이스 만들기 프로세스 중에만 지정할 수 있습니다. 로컬 중복, 영역 중복 또는 지역 중복 스토리지를 선택할 수 있습니다. 선택한 스토리지 중복도 옵션은 데이터 스토리지 중복도 및 백업 스토리지 중복도 모두에 대해 데이터베이스 수명 동안 사용됩니다. 기존 데이터베이스는 데이터베이스 복사 또는 특정 시점 복원을 사용하여 다른 스토리지 중복도로 마이그레이션할 수 있습니다.

페이지 하단에서 다음: 네트워킹을 선택합니다.
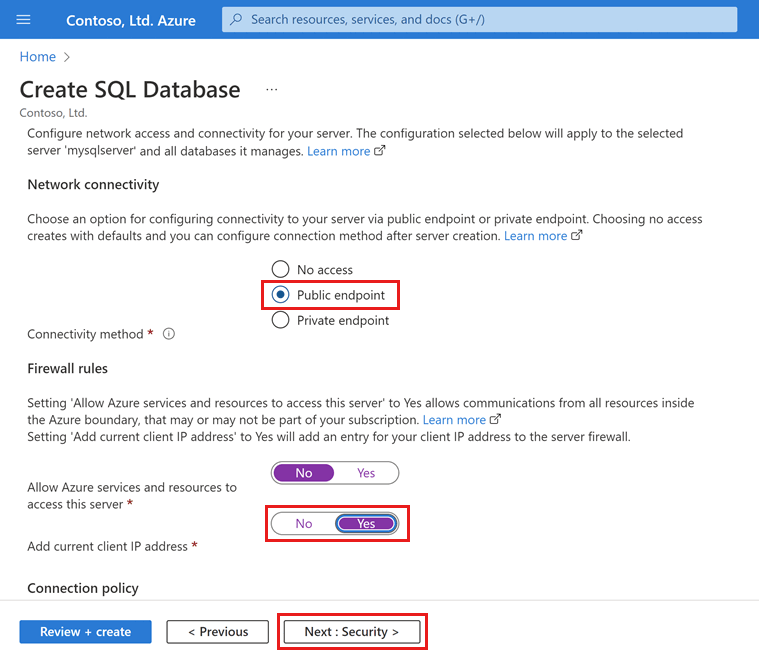
네트워킹 탭에서 연결 방법에 대해 퍼블릭 엔드포인트를 선택합니다.
방화벽 규칙의 경우 현재 클라이언트 IP 주소 추가를 예로 설정합니다.
Azure 서비스 및 리소스가 이 서버에 액세스할 수 있도록 허용을 아니요로 설정된 상태로 둡니다.
페이지 하단에서 다음: 보안을 선택합니다.
필요에 따라 Microsoft Defender for SQL을 사용하도록 설정합니다.
페이지 하단의 다음: 추가 설정을 선택합니다.
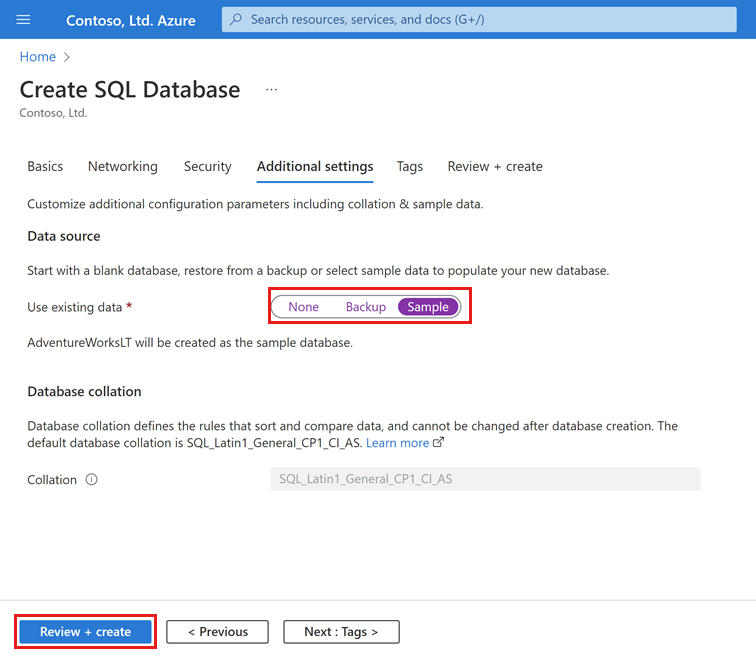
추가 설정 탭의 데이터 원본 섹션에서 기존 데이터 사용에 대해 샘플을 선택합니다. 이렇게 하면 AdventureWorksLT 샘플 데이터베이스가 만들어지므로 비어 있는 빈 데이터베이스와는 달리 쿼리 및 실험을 위한 몇 가지 테이블과 데이터가 있습니다.
페이지 아래쪽에서 검토 + 만들기를 선택합니다.
검토 + 만들기 페이지에서 검토 후 만들기를 선택합니다.
이 섹션에서 Azure CLI 코드 블록은 서버에 액세스하기 위한 리소스 그룹, 서버, 단일 데이터베이스 및 서버 수준 IP 방화벽 규칙을 만듭니다. 생성된 리소스 그룹과 서버 이름을 기록하여 나중에 이러한 리소스를 관리할 수 있도록 합니다.
Azure를 구독하고 있지 않다면 시작하기 전에 Azure 체험 계정을 만드세요.
Azure CLI에 대한 환경 준비
Azure Cloud Shell 시작
Azure Cloud Shell은 이 문서의 단계를 실행하는 데 무료로 사용할 수 있는 대화형 셸입니다. 공용 Azure 도구가 사전 설치되어 계정에서 사용하도록 구성되어 있습니다.
Cloud Shell을 열려면 코드 블록의 오른쪽 위 모서리에 있는 사용해 보세요를 선택합니다. 또한 https://shell.azure.com 로 이동하여 별도의 브라우저 탭에서 Cloud Shell을 시작할 수 있습니다.
Cloud Shell이 열리면 환경에 대해 Bash가 선택되어 있는지 확인합니다. 후속 세션에서는 Bash 환경에서 Azure CLI를 사용합니다.
복사를 선택하여 코드 블록을 복사하여 Cloud Shell에 붙여넣고, Enter 키를 눌러 실행합니다.
Azure에 로그인
Cloud Shell은 로그인한 초기 계정에서 자동으로 인증됩니다. 다음 스크립트를 통해 다른 구독을 사용하여 로그인하고 <Subscription ID>를 Azure 구독 ID로 바꿉니다.
Azure를 구독하고 있지 않다면 시작하기 전에 Azure 체험 계정을 만드세요.
subscription="<subscriptionId>" # add subscription here
az account set -s $subscription # ...or use 'az login'
자세한 내용은 활성 구독 설정 또는 대화형으로 로그인을 참조하세요.
매개 변수 값 설정
다음 값은 데이터베이스와 필요한 리소스를 만드는 후속 명령에 사용됩니다. 서버 이름은 모든 Azure에서 전역적으로 고유해야 하므로 $RANDOM 함수를 사용하여 서버 이름을 만듭니다.
샘플 코드를 실행하기 전에 location을(를) 환경에 맞게 변경합니다.
0.0.0.0을 특정 환경과 일치하도록 IP 주소 범위로 바꿉니다. 사용 중인 컴퓨터의 공용 IP 주소를 사용하여 서버에 대한 액세스를 사용자의 IP 주소로만 제한합니다.
# <FullScript>
# Create a single database and configure a firewall rule
# <SetParameterValues>
# Variable block
let "randomIdentifier=$RANDOM*$RANDOM"
location="East US"
resourceGroup="msdocs-azuresql-rg-$randomIdentifier"
tag="create-and-configure-database"
server="msdocs-azuresql-server-$randomIdentifier"
database="msdocsazuresqldb$randomIdentifier"
login="azureuser"
password="Pa$$w0rD-$randomIdentifier"
# Specify appropriate IP address values for your environment
# to limit access to the SQL Database server
startIp=0.0.0.0
let "randomIdentifier=$RANDOM*$RANDOM"
location="East US"
resourceGroupName="myResourceGroup"
tag="create-and-configure-database"
serverName="mysqlserver-$randomIdentifier"
databaseName="mySampleDatabase"
login="azureuser"
password="<password>-$randomIdentifier"
# Specify appropriate IP address values for your environment
# to limit access to the SQL Database server
startIp=0.0.0.0
endIp=0.0.0.0
echo "Using resource group $resourceGroupName with login: $login, password: $password..."
중요합니다
서버 관리자 로그인 이름 필드에 개인 정보, 중요한 정보 또는 기밀 정보를 포함하지 마세요. 이 필드에 입력된 데이터는 고객 데이터로 간주되지 않습니다.
리소스 그룹 만들기
az group create 명령을 사용하여 리소스 그룹을 만듭니다. Azure 리소스 그룹은 Azure 리소스가 배포 및 관리되는 논리적 컨테이너입니다. 다음 예제에서는 이전 단계의 location 매개 변수에 대해 지정된 위치에 리소스 그룹을 만듭니다.
echo "Creating $resourceGroupName in $location..."
az group create --name $resourceGroupName --location "$location" --tag $tag
서버 만들기
az sql server create 명령으로 논리 서버를 만듭니다.
echo "Creating $serverName in $location..."
az sql server create --name $serverName --resource-group $resourceGroupName --location "$location" --admin-user $login --admin-password $password
az sql server firewall-rule create 명령을 사용하여 방화벽 규칙을 만듭니다.
echo "Configuring firewall..."
az sql server firewall-rule create --resource-group $resourceGroupName --server $serverName -n AllowYourIp --start-ip-address $startIp --end-ip-address $endIp
단일 데이터베이스 만들기
az sql db create 명령으로 하이퍼스케일 서비스 계층에 데이터베이스를 만듭니다.
하이퍼스케일 데이터베이스를 만들 때는 backup-storage-redundancy에 대한 설정을 신중하게 고려합니다. 스토리지 중복성은 하이퍼스케일 데이터베이스에 대한 데이터베이스 만들기 프로세스 중에만 지정할 수 있습니다. 로컬 중복, 영역 중복 또는 지역 중복 스토리지를 선택할 수 있습니다. 선택한 스토리지 중복도 옵션은 데이터 스토리지 중복도 및 백업 스토리지 중복도 모두에 대해 데이터베이스 수명 동안 사용됩니다. 기존 데이터베이스는 데이터베이스 복사 또는 특정 시점 복원을 사용하여 다른 스토리지 중복도로 마이그레이션할 수 있습니다.
backup-storage-redundancy 매개 변수에 허용되는 값은 Local, Zone 및 Geo입니다. 명시적으로 지정되지 않은 한 데이터베이스는 지역 중복 백업 스토리지를 사용하도록 구성됩니다.
다음 명령을 실행하여 AdventureWorksLT 샘플 데이터로 채워진 하이퍼스케일 데이터베이스를 만듭니다. 데이터베이스는 2개의 vCore가 있는 표준 시리즈(Gen5) 하드웨어를 사용합니다. 지역 중복 백업 스토리지는 데이터베이스에 사용됩니다. 또한 이 명령은 HA(고가용성) 복제본을 하나 만듭니다.
az sql db create \
--resource-group $resourceGroupName \
--server $serverName \
--name $databaseName \3
--sample-name AdventureWorksLT \
--edition Hyperscale \
--compute-model Provisioned \
--family Gen5 \
--capacity 2 \
--backup-storage-redundancy Geo \
--ha-replicas 1
Azure PowerShell을 사용하여 리소스 그룹, 서버 및 단일 데이터베이스를 만들 수 있습니다.
Azure Cloud Shell 시작
Azure Cloud Shell은 이 문서의 단계를 실행하는 데 무료로 사용할 수 있는 대화형 셸입니다. 공용 Azure 도구가 사전 설치되어 계정에서 사용하도록 구성되어 있습니다.
Cloud Shell을 열려면 코드 블록의 오른쪽 위 모서리에 있는 사용해 보세요를 선택합니다. 또한 https://shell.azure.com 로 이동하여 별도의 브라우저 탭에서 Cloud Shell을 시작할 수 있습니다.
Cloud Shell이 열리면 환경에 대해 PowerShell이 선택되어 있는지 확인합니다. 후속 세션은 PowerShell 환경에서 Azure CLI를 사용합니다.
복사를 선택하여 코드 블록을 복사하여 Cloud Shell에 붙여넣고, Enter 키를 눌러 실행합니다.
매개 변수 값 설정
다음 값은 데이터베이스와 필요한 리소스를 만드는 후속 명령에 사용됩니다. 서버 이름은 모든 Azure에서 전역적으로 고유해야 하므로 Get-Random cmdlet을 사용하여 서버 이름을 만듭니다.
샘플 코드를 실행하기 전에 location을(를) 환경에 맞게 변경합니다.
0.0.0.0을 특정 환경과 일치하도록 IP 주소 범위로 바꿉니다. 사용 중인 컴퓨터의 공용 IP 주소를 사용하여 서버에 대한 액세스를 사용자의 IP 주소로만 제한합니다.
# Set variables for your server and database
$resourceGroupName = "myResourceGroup"
$location = "eastus"
$adminLogin = "azureuser"
$password = "<password>-$(Get-Random)"
$serverName = "mysqlserver-$(Get-Random)"
$databaseName = "mySampleDatabase"
# The ip address range that you want to allow to access your server
$startIp = "0.0.0.0"
$endIp = "0.0.0.0"
# Show randomized variables
Write-host "Resource group name is" $resourceGroupName
Write-host "Server name is" $serverName
Write-host "Password is" $password
중요합니다
서버 관리자 로그인 이름 필드에 개인 정보, 중요한 정보 또는 기밀 정보를 포함하지 마세요. 이 필드에 입력된 데이터는 고객 데이터로 간주되지 않습니다.
리소스 그룹 만들기
New-AzResourceGroup을 사용하여 Azure 리소스 그룹을 만듭니다. 리소스 그룹은 Azure 리소스가 배포 및 관리되는 논리적 컨테이너입니다.
Write-host "Creating resource group..."
$resourceGroup = New-AzResourceGroup -Name $resourceGroupName -Location $location -Tag @{Owner="SQLDB-Samples"}
$resourceGroup
서버 만들기
New-AzSqlServer cmdlet을 사용하여 서버를 만듭니다.
Write-host "Creating primary server..."
$server = New-AzSqlServer -ResourceGroupName $resourceGroupName `
-ServerName $serverName `
-Location $location `
-SqlAdministratorCredentials $(New-Object -TypeName System.Management.Automation.PSCredential `
-ArgumentList $adminLogin, $(ConvertTo-SecureString -String $password -AsPlainText -Force))
$server
방화벽 규칙을 만들기
New-AzSqlServerFirewallRule cmdlet을 사용하여 서버 방화벽 규칙을 만듭니다.
Write-host "Configuring server firewall rule..."
$serverFirewallRule = New-AzSqlServerFirewallRule -ResourceGroupName $resourceGroupName `
-ServerName $serverName `
-FirewallRuleName "AllowedIPs" -StartIpAddress $startIp -EndIpAddress $endIp
$serverFirewallRule
단일 데이터베이스 만들기
New-AzSqlDatabase cmdlet을 사용하여 단일 데이터베이스를 만듭니다.
하이퍼스케일 데이터베이스를 만들 때는 BackupStorageRedundancy에 대한 설정을 신중하게 고려합니다. 스토리지 중복성은 하이퍼스케일 데이터베이스에 대한 데이터베이스 만들기 프로세스 중에만 지정할 수 있습니다. 로컬 중복, 영역 중복 또는 지역 중복 스토리지를 선택할 수 있습니다. 선택한 스토리지 중복도 옵션은 데이터 스토리지 중복도 및 백업 스토리지 중복도 모두에 대해 데이터베이스 수명 동안 사용됩니다. 기존 데이터베이스는 데이터베이스 복사 또는 특정 시점 복원을 사용하여 다른 스토리지 중복도로 마이그레이션할 수 있습니다.
BackupStorageRedundancy 매개 변수에 허용되는 값은 Local, Zone 및 Geo입니다. 명시적으로 지정되지 않은 한 데이터베이스는 지역 중복 백업 스토리지를 사용하도록 구성됩니다.
다음 명령을 실행하여 AdventureWorksLT 샘플 데이터로 채워진 하이퍼스케일 데이터베이스를 만듭니다. 데이터베이스는 2개의 vCore가 있는 표준 시리즈(Gen5) 하드웨어를 사용합니다. 지역 중복 백업 스토리지는 데이터베이스에 사용됩니다. 또한 이 명령은 HA(고가용성) 복제본을 하나 만듭니다.
Write-host "Creating a standard-series (Gen5) 2 vCore Hyperscale database..."
$database = New-AzSqlDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName `
-DatabaseName $databaseName `
-Edition Hyperscale `
-ComputeModel Provisioned `
-ComputeGeneration Gen5 `
-VCore 2 `
-MinimumCapacity 2 `
-SampleName "AdventureWorksLT" `
-BackupStorageRedundancy Geo `
-HighAvailabilityReplicaCount 1
$database
Transact-SQL을 사용하여 하이퍼스케일 데이터베이스를 만들려면 먼저 Azure에서 기존 논리 서버에 대한 연결 정보를 만들거나 식별해야 합니다.
master
SSMS(SQL Server Management Studio) 또는 선택한 클라이언트를 사용하여 데이터베이스에 연결하여 Transact-SQL 명령(sqlcmd 등)을 실행합니다.
하이퍼스케일 데이터베이스를 만들 때는 BACKUP_STORAGE_REDUNDANCY에 대한 설정을 신중하게 고려합니다. 스토리지 중복성은 하이퍼스케일 데이터베이스에 대한 데이터베이스 만들기 프로세스 중에만 지정할 수 있습니다. 로컬 중복, 영역 중복 또는 지역 중복 스토리지를 선택할 수 있습니다. 선택한 스토리지 중복도 옵션은 데이터 스토리지 중복도 및 백업 스토리지 중복도 모두에 대해 데이터베이스 수명 동안 사용됩니다. 기존 데이터베이스는 데이터베이스 복사 또는 특정 시점 복원을 사용하여 다른 스토리지 중복도로 마이그레이션할 수 있습니다.
BackupStorageRedundancy 매개 변수에 허용되는 값은 LOCAL, ZONE 및 GEO입니다. 명시적으로 지정되지 않은 한 데이터베이스는 지역 중복 백업 스토리지를 사용하도록 구성됩니다.
다음 Transact-SQL 명령을 실행하여 Gen 5 하드웨어, 2 vCore 및 지역 중복 백업 스토리지를 사용하여 새 하이퍼스케일 데이터베이스를 만듭니다.
CREATE DATABASE 문에 버전 및 서비스 목표를 둘 다 지정해야 합니다. 유효한 서비스 목표 목록(예: )은 HS_Gen5_2을 참조하세요.
이 예제 코드는 빈 데이터베이스를 만듭니다. 샘플 데이터를 사용하여 데이터베이스를 만들려면 이 빠른 시작에서 Azure Portal, Azure CLI 또는 PowerShell 예제를 사용합니다.
CREATE DATABASE [myHyperscaleDatabase]
(EDITION = 'Hyperscale', SERVICE_OBJECTIVE = 'HS_Gen5_2') WITH BACKUP_STORAGE_REDUNDANCY= 'LOCAL';
GO
더 많은 매개 변수 및 옵션은 데이터베이스 만들기(Transact-SQL)를 참조하세요.
하나 이상의 HA(고가용성) 복제본을 데이터베이스에 추가하려면 Azure Portal의 데이터베이스에 대한 컴퓨팅 및 스토리지 창, Set-AzSqlDatabase PowerShell 명령 또는 az sql db update Azure CLI 명령을 사용합니다.
리소스 그룹, 서버 및 단일 데이터베이스를 유지하여 다음 단계로 이동하고, 다양한 방법으로 데이터베이스에 연결하고 쿼리하는 방법을 알아봅니다.
이러한 리소스의 사용을 마친 후에는 만든 리소스 그룹을 삭제할 수 있습니다. 그러면 해당 리소스 그룹 내에서 서버 및 단일 데이터베이스도 삭제됩니다.
다음 문서에서 하이퍼스케일 데이터베이스에 대해 자세히 알아봅니다.









